文章目录
- 注意力机制
- 原理介绍
- 注意力机制的各种变式
- 注意力机制的特点
- Transformer结构
- 概述
- Transformer整体结构
- 输入层
- byte pair encoding
- positional encoding
- Transformer Block
- Encoder Block
- Multi-Head Attention
- Decoder Block
- 其他tricks
- 总结
- 预训练语言模型
- 语言建模概述
- 预训练语言模型(PLM)介绍
- GPT
- BERT
- transformers使用
- pipeline接口
- 常用API
- Tokenization
- Demo讲解
- 加载数据集
- tokenization
- fine-tune模型
对应视频P21-P40
注意力机制
原理介绍
RNN的问题:信息瓶颈
例子:
decoder端需要从encoder端最后表示的向量来输出完整的句子,这就需要最后这个向量应该包括整个句子的所有信息。
但是,最后这个向量真的可以表示完整信息吗?否定的
注意力机制就是为了解决信息瓶颈的问题。
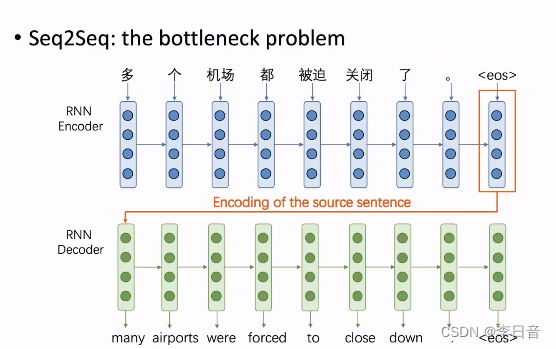
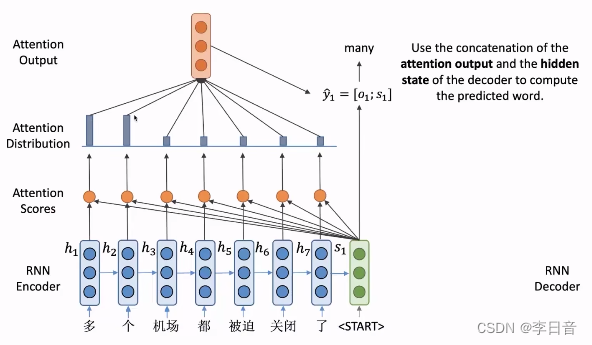
注意力机制的核心思想:在decoder的每一步都把encoder端所有向量输入进去,decoder根据自己所需选择向量
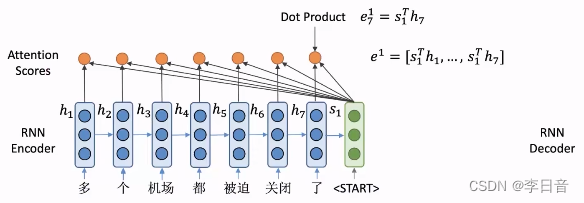
- 计算注意力分数:将
s
1
s_1
s1 点乘每个位置的隐向量,得到
e
1
e^1
e1 。注意力分数表示了
s
1
s_1
s1与对应隐向量
h
i
h_i
hi的相似程度,相似程度越高,注意力分数也会越高。
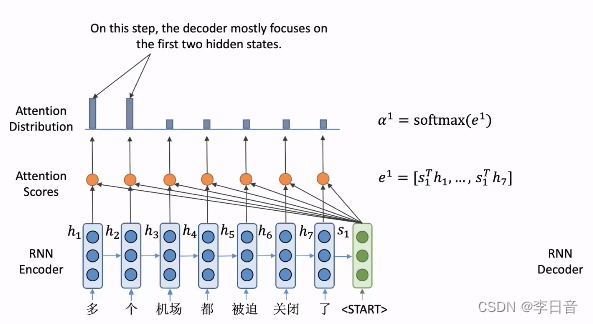
- 将注意力分数变为概率分布,即
s
o
f
t
m
a
x
softmax
softmax操作
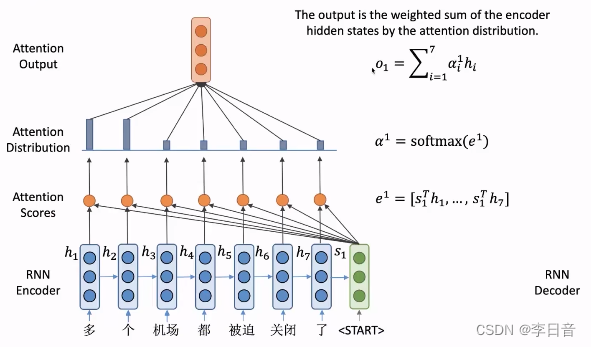
- 根据注意力分布对隐向量加权求和,得到
o
1
o_1
o1,包含了encoder端所有隐向量的信息
- 将
o
1
o_1
o1与
s
1
s_1
s1进行拼接,得到
y
1
y_1
y1,用这个向量来预测生成的单词
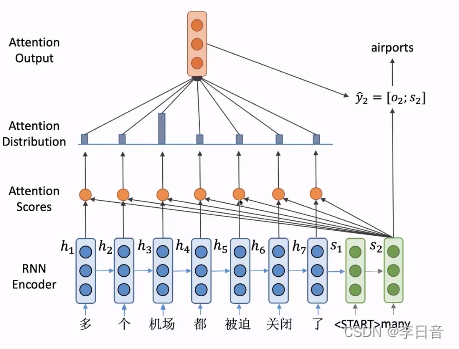
- 生成的单词many输入decoder端得到
s
2
s_2
s2,重复刚才的过程
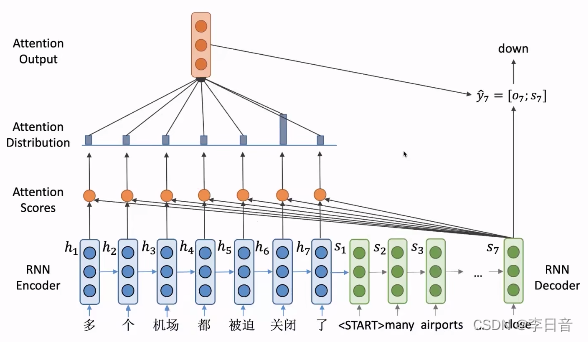
这样每次都可以关注到decoder端不同位置的隐向量,并预测出新的单词
公式化总结:



注意力机制的各种变式
变体1:如果
s
s
s和
h
h
h这两个向量维度不一样,就需要在中间乘上权重矩阵
W
W
W

变体2:Additive attention,将
h
h
h和
s
s
s输入到一层前馈神经网络获得标量

注意力机制的特点
- 解决信息瓶颈问题,可以关注每个位置的信息
- 缓解RNN传播过长造成梯度消失的问题
- 给神经网络这个黑盒模型提供了一定的可解释性,翻译的单词会对相对应的词语权重更高
Transformer结构
概述
回顾:
典型的两层LSTM模型
缺点:必须顺序执行,浪费GPU并行设备的性能
是否可以摒弃RNN结构呢?
Transformer整体结构
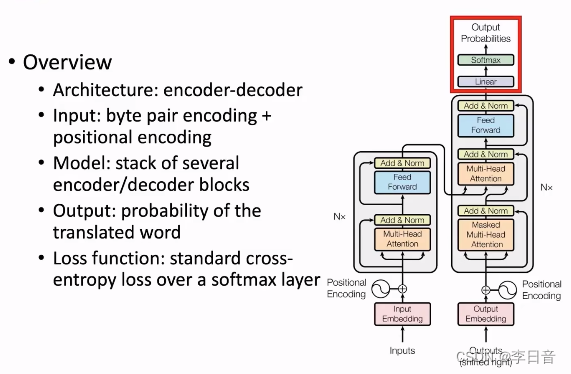
-
输入层:将文本切分为token(byte pair encoding),并添加位置向量(positional encodeing)。
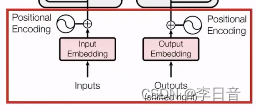
-
模型层:多个encoder和decoder的Transformer block堆叠而成,不同层的block结构相同,参数不同。通过堆叠block得到更深的模型
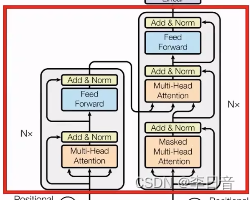
-
输出层:线性层和softmax获得词表的概率分布

-
损失函数:通过在词表的维度计算交叉熵来计算loss,从而更新模型参数
输入层
byte pair encoding
将句子切分为单词。
在RNN时,就根据空格切分单词。但是这样存在一些问题,如词表会很大、单词的不同形式被当做不同的词来处理。
全新的切分方式:byte pair encoding(BPE)
语料库中的单词切分为字母,统计每个字母出现的数量,将频度最高的byte gram(连续两个相邻字母的组合)作为词添加进词表中,然后扩充词表,直到到达需要的数量。
例子:
最开始的词表:所有的字母组成
es频度最高,拼接为一个新的单词加入词表中。拼接后s不再单独出现,所以在词表中删除s
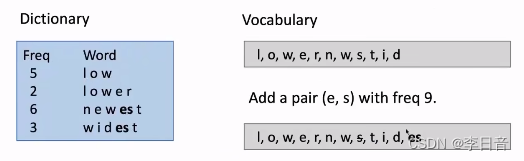
在新的词表中,est出现频度最高,所以拼接est并添加进词表中

BPE解决的问题:
- 解决OOV(out of vocabulary)问题,即在输入的文本中,出现了词表中没有出现过的词,模型就无法理解新的单词的含义,也就无法找到向量来表示,这时就只能用特殊符号UNK(unknown words)来代替,这个问题在空格切分处理时非常常见。
- BPE通过将文本序列变成sub word这样更小的单元,在面对没有见过的单词时,可以将其分解为一个一个见过的sub word来表示,这样就可以表示更多的单词。如lowest就可以分解为low和est
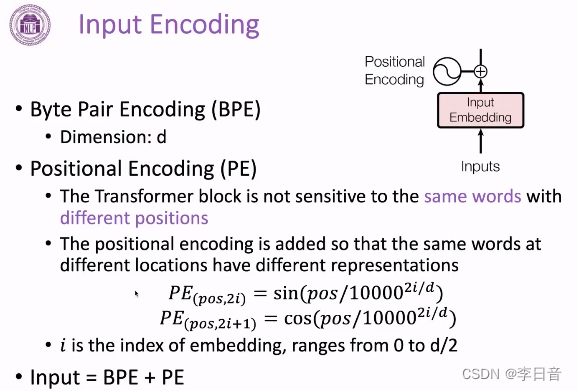
positional encoding
出现的原因:Transformer无法像RNN那样根据单词出现的先后顺序来建模每个单词的位置关系。这样Transformer就无法区分不同位置的相同单词
处理方法:显式的加上位置向量进行区分,基于三角函数的方法来得到位置向量
特性:一一对应,有界,差别取决于相对位置
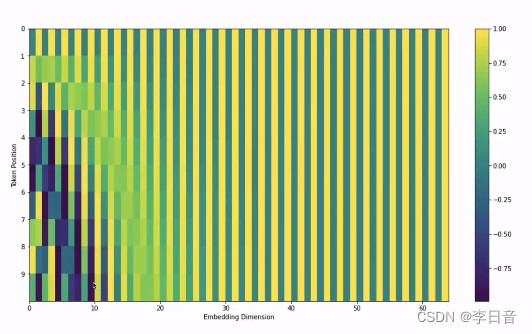
可视化:
展示了一个长度为10个token,维度为64的一个编码向量
相同维度,即每个竖线,是一个周期的正弦或者余弦函数
相同位置,即每个横线,对应不同周期的正弦或者余弦函数
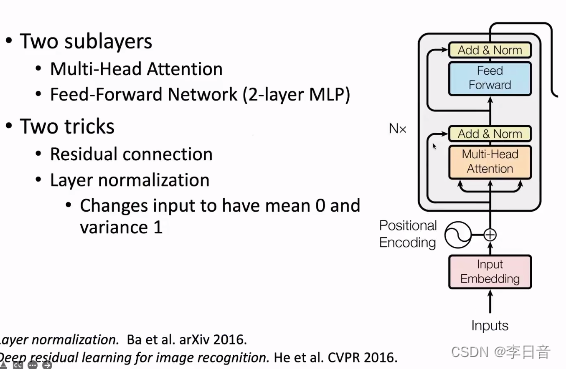
Transformer Block
Encoder Block
网络:多头注意力+两层全连接
trick:残差网络+正则化(隐向量维度),解决层数过深导致的梯度消失和梯度爆炸问题
Multi-Head Attention
q的计算互不干扰,可以并行计算

图解:
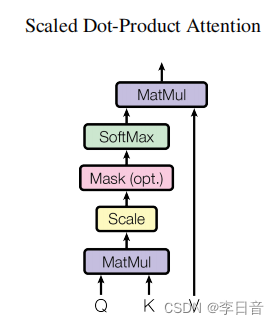
其中Q为Query、K为Key、V为Value。可以简单理解为Q与K进行相似度匹配,匹配后取得的结果就是V。举个例子我们在某宝上搜索东西,输入的搜索关键词就是Q,商品对应的描述就是K,Q与K匹配成功后搜索出来的商品就是V。
那Q、K、V是怎么来的呢?这里其实是通过对输入矩阵X进行线性变换得到的,用公式可以简单写成以下:
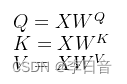
图片可以表示为:
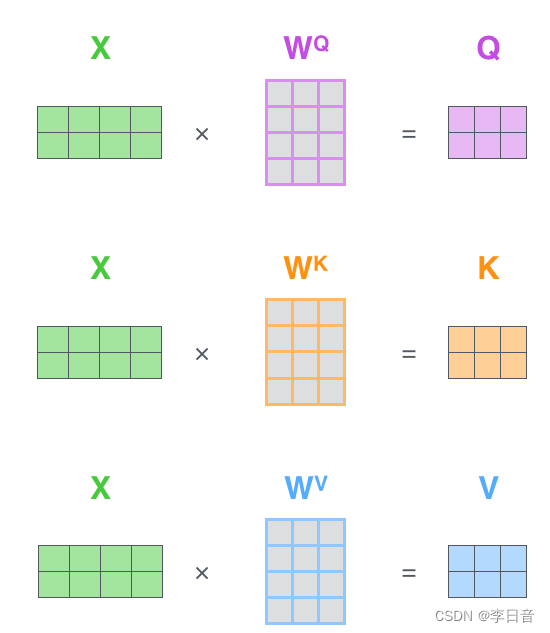
其中,
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV是三个可训练的参数矩阵,输入矩阵X分别与这三个矩阵参数相乘得到
Q
Q
Q、
K
K
K、
V
V
V
接着,矩阵
Q
Q
Q、
K
T
K^T
KT相乘,得到注意力分数,通过
s
o
f
t
m
a
x
softmax
softmax转化为概率分布,再乘
V
V
V得到输出
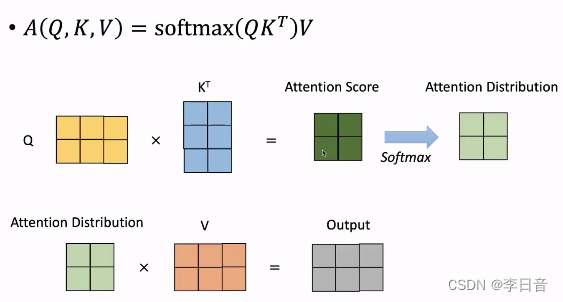
进一步的,需要加入Scale系数。除以
d
K
\sqrt{d_K}
dK,可以让注意力分数的方差为1
如果没有Scale的话,Q和K的点积得到标量的方差会随着d_K的增加而变大,在softmax后概率分布会变得尖锐,某个位置为1,其他位置接近于0,这样以后的梯度变得很小,不利于参数的更新。

多头注意力机制:多个结构相同但是参数不同的网络组成多头注意力机制,每个头的
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV不同
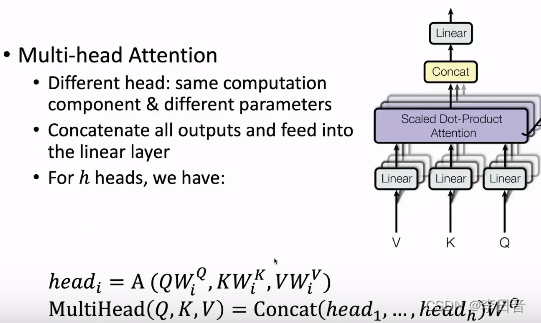
每个head关注的子空间不一定是一样的,那么这个多头的机制能够联合来自不同head部分学习到的信息,这就使得模型具有更强的认识能力。
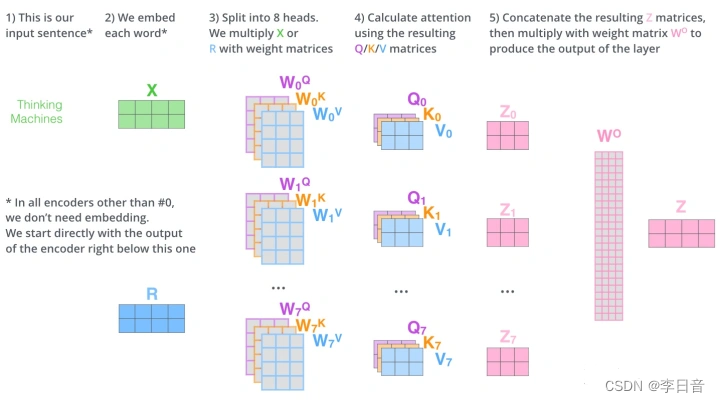
Decoder Block
大体上与Encoder Block一致,做了两个修改:
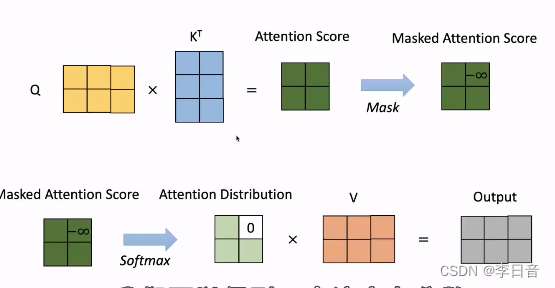
- 修改1:Masked self-attention
masked限制Q和K相乘得到的注意力分数的上三角部分(右上角)为负无穷大,这样经过softmax操作后概率就会变为0,使模型输出时看不到后面的单词,只能看到过去的单词,确保了文本的顺序生成 - 修改2:Q来源于decoder,然而K和V来源于Encoder最后一层的输出
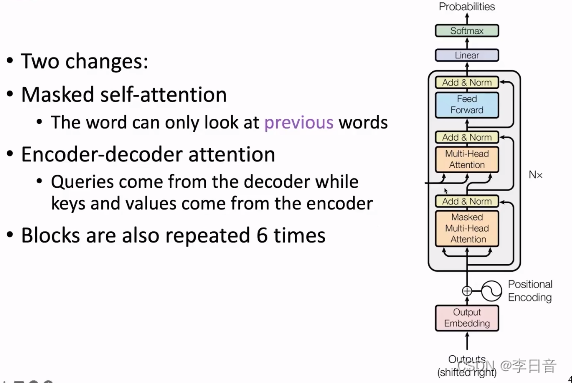
图解:
其他tricks
训练过程

总结
优点:Transformer是具有很强表示能力的模型,适合并行运算。通过Attention的可视化可以发现注意力模块很好的建模了句子中token之间的关系。给预训练语言模型很多启发。
缺点:参数敏感,优化器选择、超参数选择对训练有很大影响。复杂度
O
(
n
2
)
O(n^2)
O(n2),对长文本束手无策,目前文本长度在512以下。
预训练语言模型
语言建模概述
语言模型的定义:给定前一个词预测下一个词(文字接龙)
可以建模为条件概率
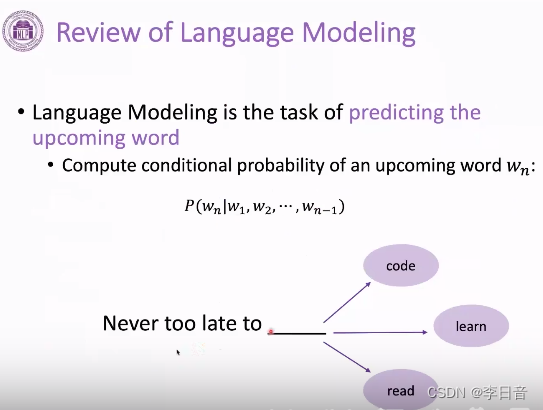
语言模型需要学习到语法知识和事实知识,只需要纯文本就可以训练,不需要人工标注。在训练后可以迁移到别的任务上
发展脉络:
-
word2vec(Transformer之前,NLP模型采用词向量作为输入)
根据前面的1 到 N-1个词预测下一个词,将过程变得简单和高效

-
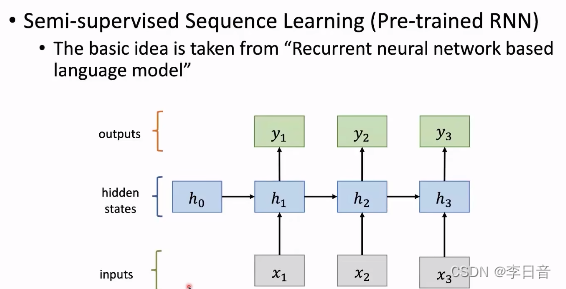
Pre-trained RNN
模型的上限不高,效果一般
-
GPT&BERT
基于transformer
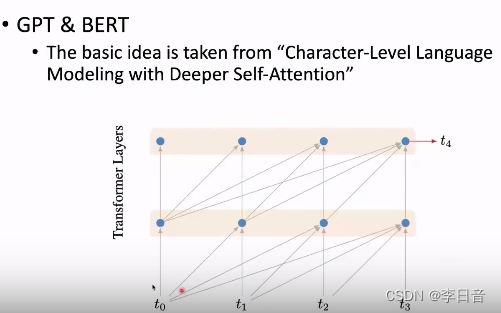
预训练语言模型(PLM)介绍
预训练语言模型的好处在于训练后可以很容易迁移到下游的应用任务上,当前大部分都是基于transformer。
具有两种范式,
第一种是feature的提取器,比较有代表性的是word2vec和ElMo,预训练的参数作为下游任务的输入
第二种是fine-tuning方式,会对整个模型的参数进行更新,如BERT和GPT
GPT
GPT-1:方式非常简单,只训练transformer的decoder,用自回归的方式训练一个语言模型。具体来讲使用12层的transformer的decoder
GPT-2:提升了transformer的参数量、训练的文本量(40GB),训练不同规模的GPT大小
BERT
2019年
成为NLP的一个基础架构,下游任务中很多用到BERT
双向生成会产生信息泄露的问题,因此,BERT提出了Masked LM
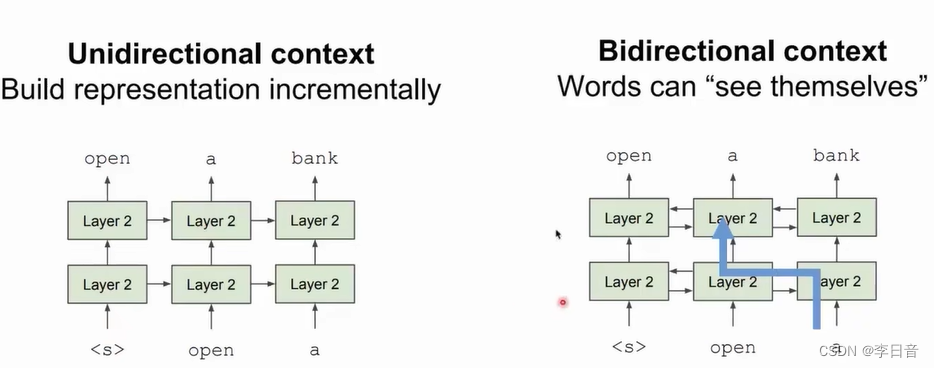
masked掉15%的信息

但在下游任务时不会出现完形填空,即masked会带来预训练和fine-tuning阶段的差异,导致模型效果变差。
解决方式如下:

输入:基于transformer的encoder

问题:masked导致预训练和fine-tuning之间的差异;效率低,每次只有15%的词得到训练
改进:动态masked;next sentence prediction是否有必要存在;使用小模型生成masked词,再判断是否被替换
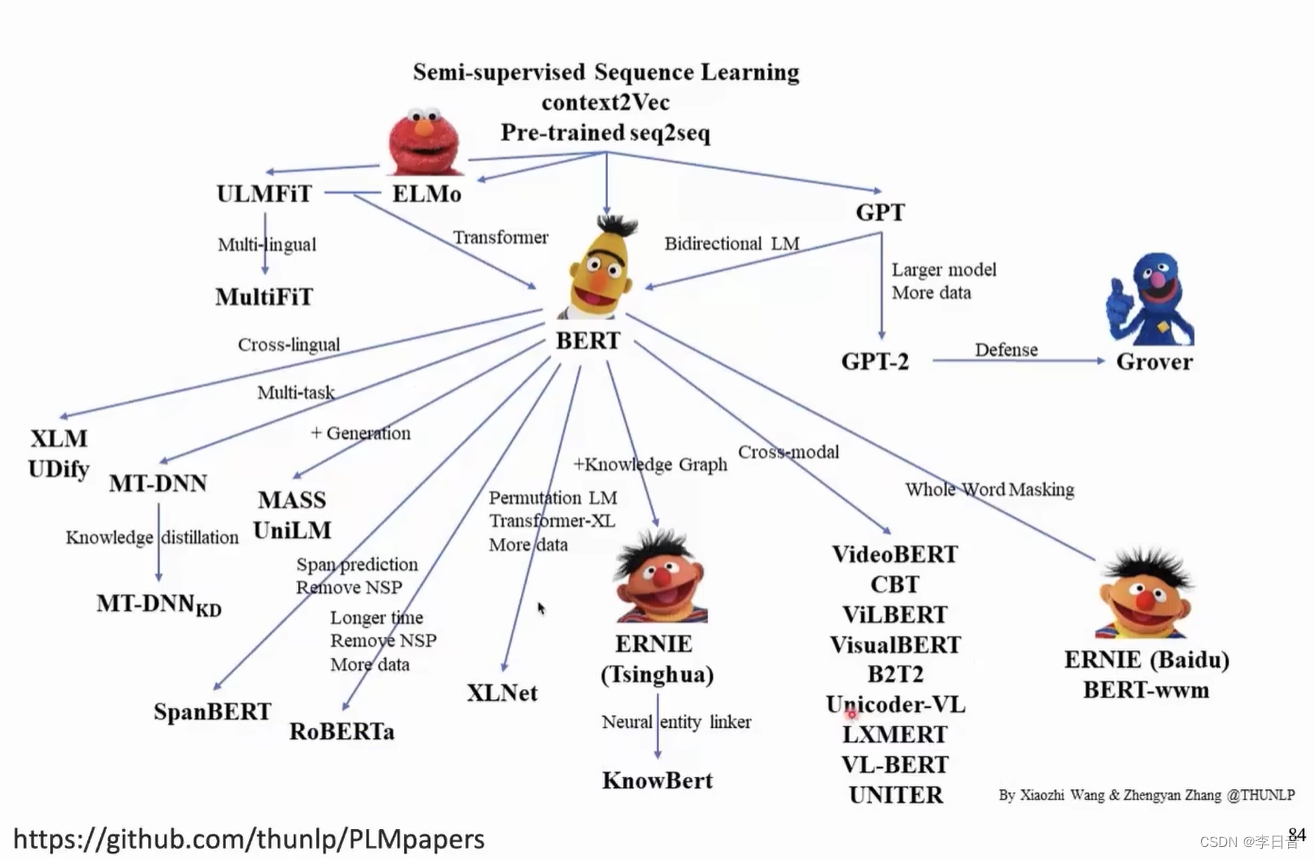
-
预训练语言模型的代表工作
-
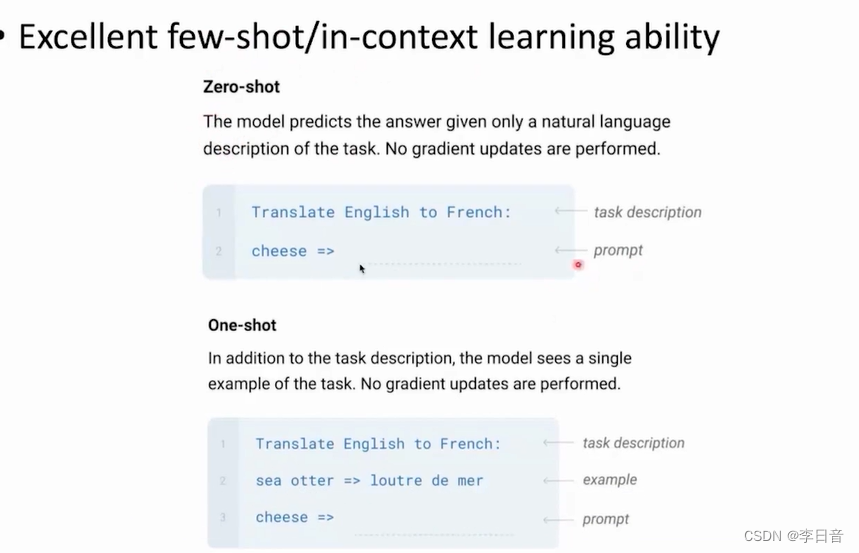
前沿工作:GPT3
– zero shot:不给任何示例,只给出要求,就可以完成任务
– one-shot:给一个示例就可以完成任务
以in-context learning方式学习
-
前沿工作:T5
输入:任务描述,拼接任务内容
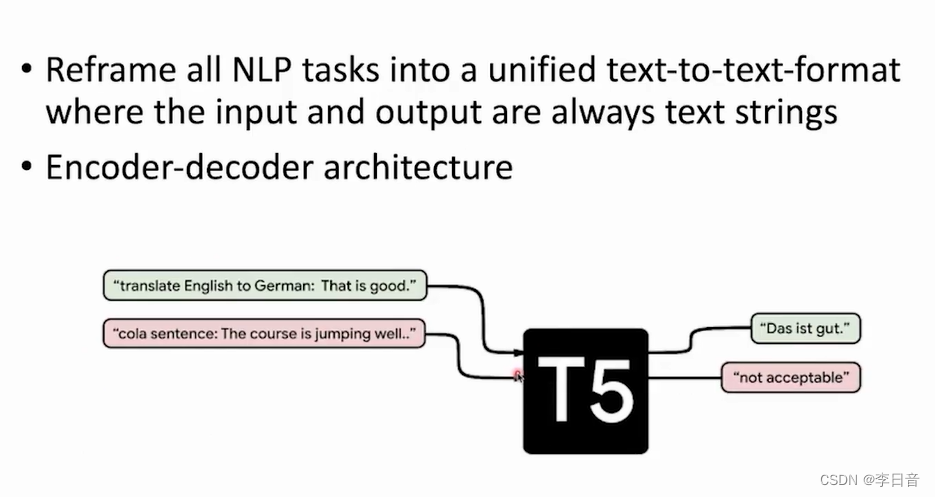
-
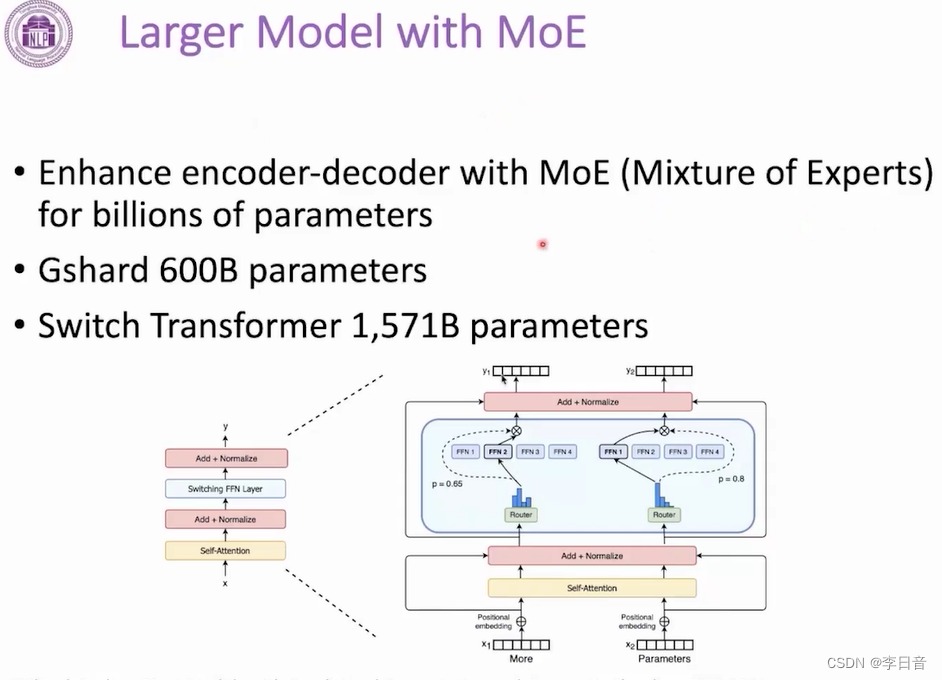
前沿工作:MoE
组合小模型成大模型,使用到哪个部分就调用哪个部分参与计算
transformers使用
预训练语言模型效果大大超过了RNN这类的神经网络模型。在BERT之后,预训练语言模型如雨后春笋般爆发,但对于工程师而言,从头实现各个模型非常耗费时间和精力。
Huggingface公司提出了transformers库,提供了非常多的模型,一两行代码即可加载模型,并支持主流框架(pytorch、TensorFlow、Jax),并支持音频和视频的预训练模型。
只需要几个接口就可以实现预训练模型的加载、fine-tune。
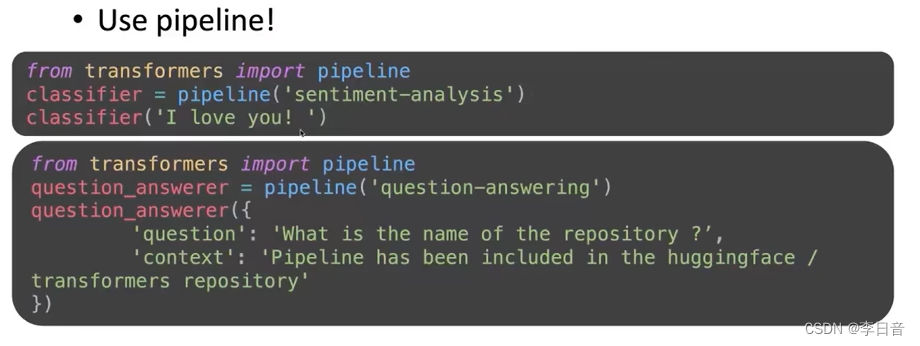
pipeline接口
使用训练好的模型直接完成下游任务
如情感分析、问答
常用API
Tokenization
不同模型的tokenization方式不一样,但是huggingface可以根据模型的名字自动选择tokenization的方式



Demo讲解
加载数据集
在datasets这个package中,囊括了许多目前主流的数据集,通过一行命令(load_dataset)就可以完成数据集的下载与加载,且能够加载该数据集对应的metric以便计算(load_metric)
from datasets import load_dataset, load_metric
dataset = load_dataset("glue", 'sst2')
metric = load_metric('glue', 'sst2')
tokenization
预训练模型并不直接接受文本作为输入,每个预训练模型有自己的tokenization方式以及自己的词表。
我们在使用某一模型时,需要:
使用该模型的tokenization方式对数据进行tokenization
使用该模型的词表,将tokenize之后的每个token转化成对应的id。
from transformers import AutoTokenizer
# 利用tokenizer处理数据集
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def preprocess_function(examples):
return tokenizer(examples['sentence'], truncation=True, max_length=512)
# 用preprocess_function来处理整个数据集
encoded_dataset = dataset.map(preprocess_function, batched=True)
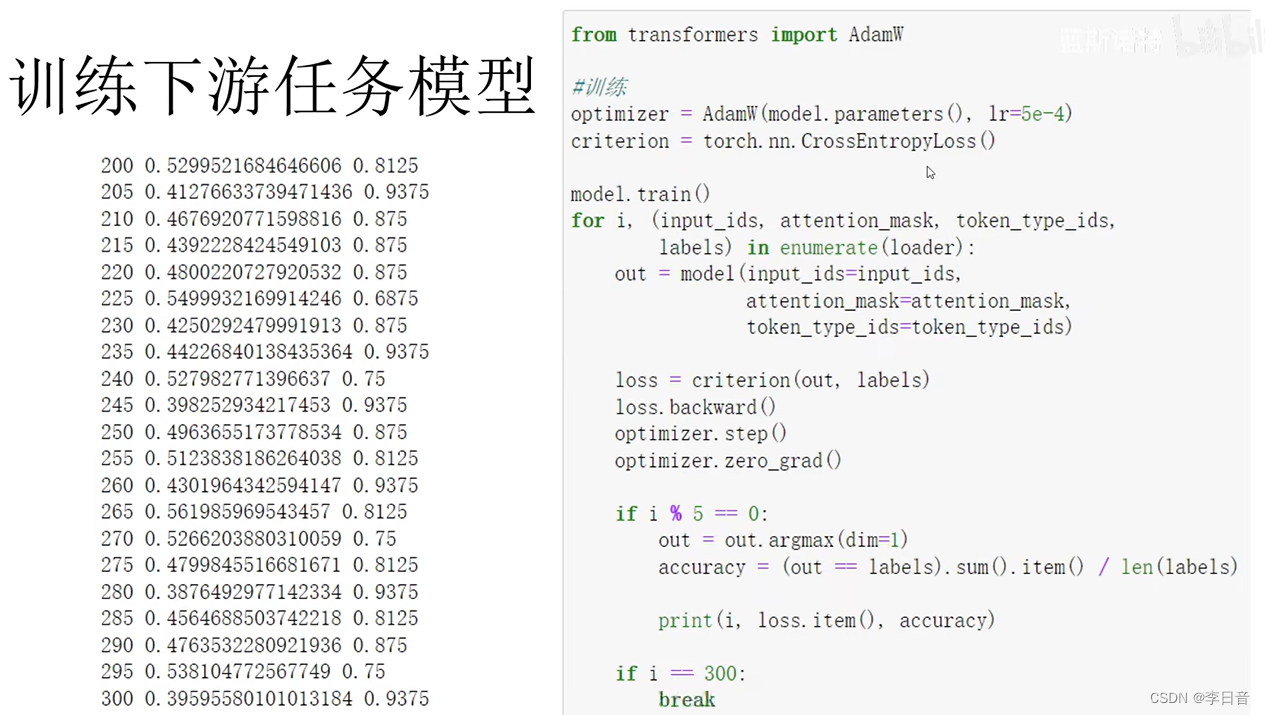
fine-tune模型
首先,我们需要利用transformers把预训练模型下载下来以便加载,这一过程也可以通过以下一行代码实现。其中,由于SST-2的标签种类只有2种(positive, negative),因此我们指定num_labels=2。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
接下来,我们将使用Huggingface提供的Trainer类来进行模型的fine-tune。首先,我们设置Trainer的各种参数如下
from transformers import TrainingArguments
batch_size=16
args = TrainingArguments(
"bert-base-uncased-finetuned-sst2",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=5,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model="accuracy"
)
每个参数的含义:
第一个参数:本次训练的名称
evaluation_strategy=“epoch”:在每个epoch结束的时候在validation集上测试模型效果
save_strategy=“epoch”:在每个epoch结束的时候保存一个checkpoint
learning_rate=2e-5:优化的学习率
per_device_train_batch_size=batch_size:训练时每个gpu上的batch_size
per_device_eval_batch_size=batch_size:测试时每个gpu上的batch_size
num_train_epochs=5:训练5个epoch
weight_decay=0.01:优化时采用的weight_decay
load_best_model_at_end=True:在训练结束后,加载训练过程中最好的参数
metric_for_best_model=“accuracy”:以准确率作为指标
另外,我们还需要定义一个函数,告诉Trainer怎么计算指标
def compute_metrics(eval_pred):
logits, labels = eval_pred # predictions: [batch_size,num_labels], labels:[batch_size,]
predictions = np.argmax(logits, axis=1) # 将概率最大的类别作为预测结果
return metric.compute(predictions=predictions, references=labels)
然后我们可以定义出Trainer类了
from transformers import Trainer
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
紧接着,调用trainer的train方法,我们就能够开始训练了
trainer.train()


![[算法沉淀记录] 排序算法 —— 堆排序](https://img-blog.csdnimg.cn/direct/69d12166b20b4e33807a075770a4e279.png)