目录
引入:
例1:二叉树的前序遍历:
例2: N叉树的前序遍历:
例3:二叉树的最大深度:
例4:二叉树的最小深度
例5:N叉树的最大深度:
例6:左叶子之和:
例7:翻转二叉树:
例8: 路径总和:
例9:路径总和II:
例10:二叉树展开为链表:
引入:
递归是一种在函数定义中使用函数自身的方法。它是一种常见的编程技巧,用于解决可以被分解为相同问题的子问题的问题。递归函数通常包含两个部分:基本情况和递归情况。
基本情况是指递归函数停止调用自身的条件。当满足基本情况时,递归函数将不再调用自身,而是返回一个特定的值或执行特定的操作。
递归情况是指递归函数调用自身解决更小规模的子问题。通过不断地调用自身,递归函数可以将原始问题分解为更小的子问题,直到达到基本情况。
让我们再看二叉树的遍历,其实它的结构大概是这样(基本框架):
public void traverse(TreeNode root) {
//前序遍历的位置
traverse(root.left);
//中序遍历的位置
traverse(root.right);
//后续遍历的位置
}你或许会认为前中后续遍历不过就是要操作的代码位于这三个不同的位置而已,其实不然。我们抛开操作代码不谈,就只看这段代码,你就会发现他的主要遍历过程是这样:
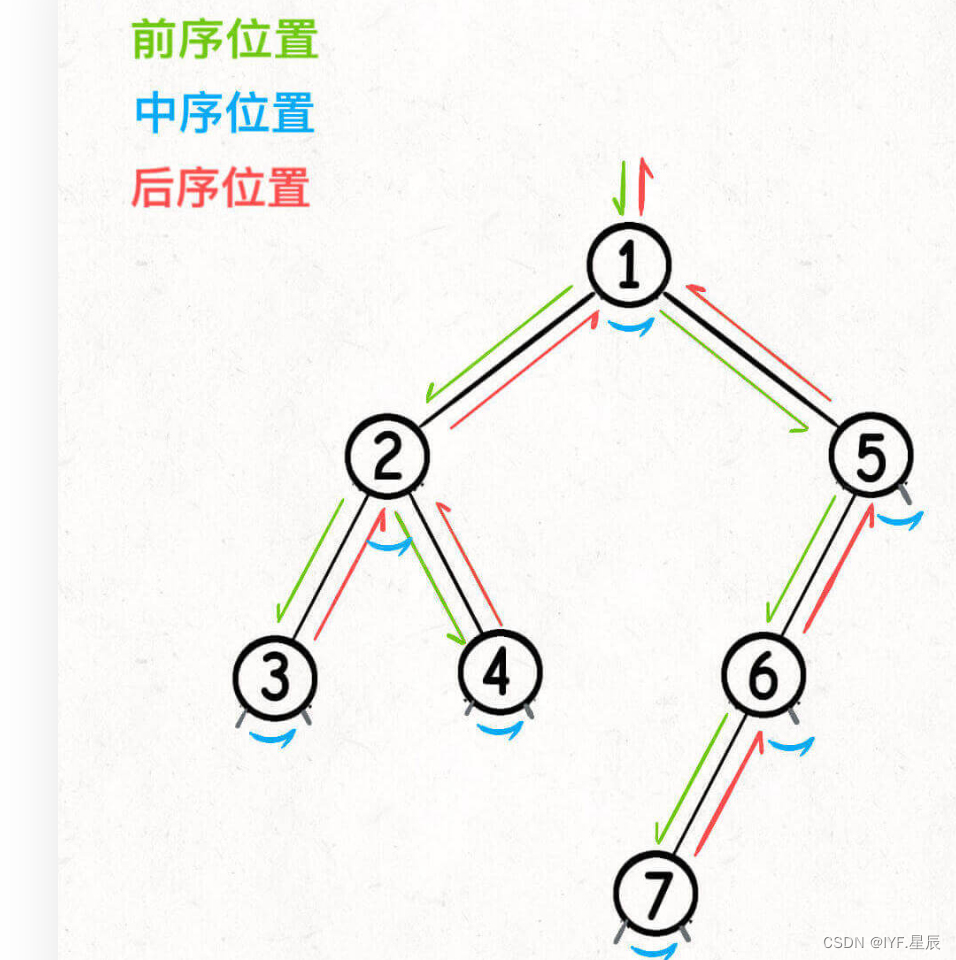
只不过我们在其遍历的过程中对某个节点进行了不同的操作罢了。如前序遍历,我们按照这个过程进入二叉树的遍历(绿->蓝->红),由于我们是在遍历前加入不同的操作,也就是按照:
①->②->③->④->⑤->⑥->⑦分别进行各项操作,前中后序是遍历二叉树过程中处理每一个节点的三个特殊时间点。 二叉树的问题,大致就是让你在这三个不同的时间节点注入巧妙的代码逻辑,来达成各项操作。关键要注意我们要在每个节点做什么,实施怎样的操作来完成我们的目标。通过递归将一个大的二叉树问题转化为一个个子树问题,直到不可再分就结束。
前序位置的代码在刚刚进入一个二叉树节点的时候执行;
后序位置的代码在将要离开一个二叉树节点的时候执行;
中序位置的代码在一个二叉树节点左子树都遍历完,即将开始遍历右子树的时候执行。
例1:二叉树的前序遍历:
题目:给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
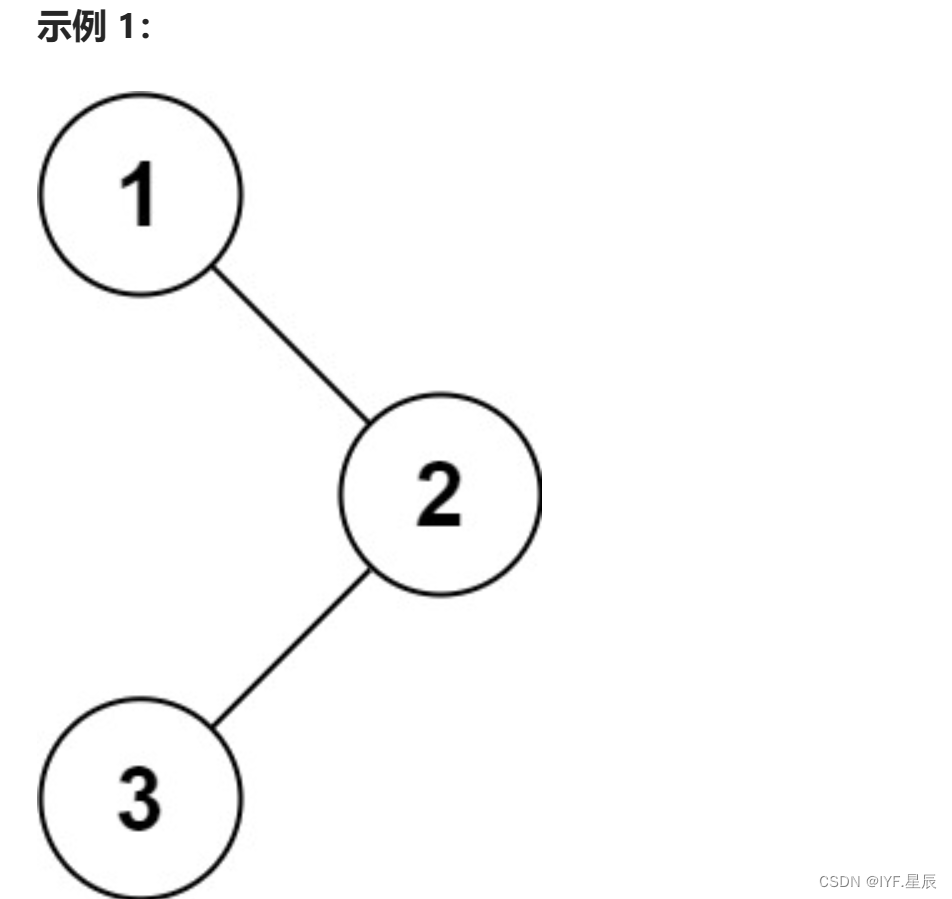
输入:root = [1,null,2,3] 输出:[1,2,3]
题目链接:144. 二叉树的前序遍历 - 力扣(LeetCode)
题解:通过联系二叉树的遍历过程,前序遍历就是让我们在框架前将该节点加入到list中
class Solution {
List<Integer> list = new LinkedList<>();//用于存储遍历的信息
public List<Integer> preorderTraversal(TreeNode root) {
//递归的结束条件
if(root == null){
return list;
}
list.add(root.val);//根据框架,我们将该节点加入到list中
preorderTraversal(root.left);
preorderTraversal(root.right);
return list;
}
}二叉树的中后序遍历也是一样,将list分别放到框架中间和后面
例2: N叉树的前序遍历:
注:由于N叉树(不止包含左右子节点,可能有多个)的特性,其没有中序遍历,其大致框架是:
public void traverse(TreeNode root){
if(root == null){
return ;
}
//前序遍历的位置
for(Node child : root.children){
traverse(child);
}
//后序遍历的位置
}题目:
给定一个 n 叉树的根节点 root ,返回 其节点值的 前序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。
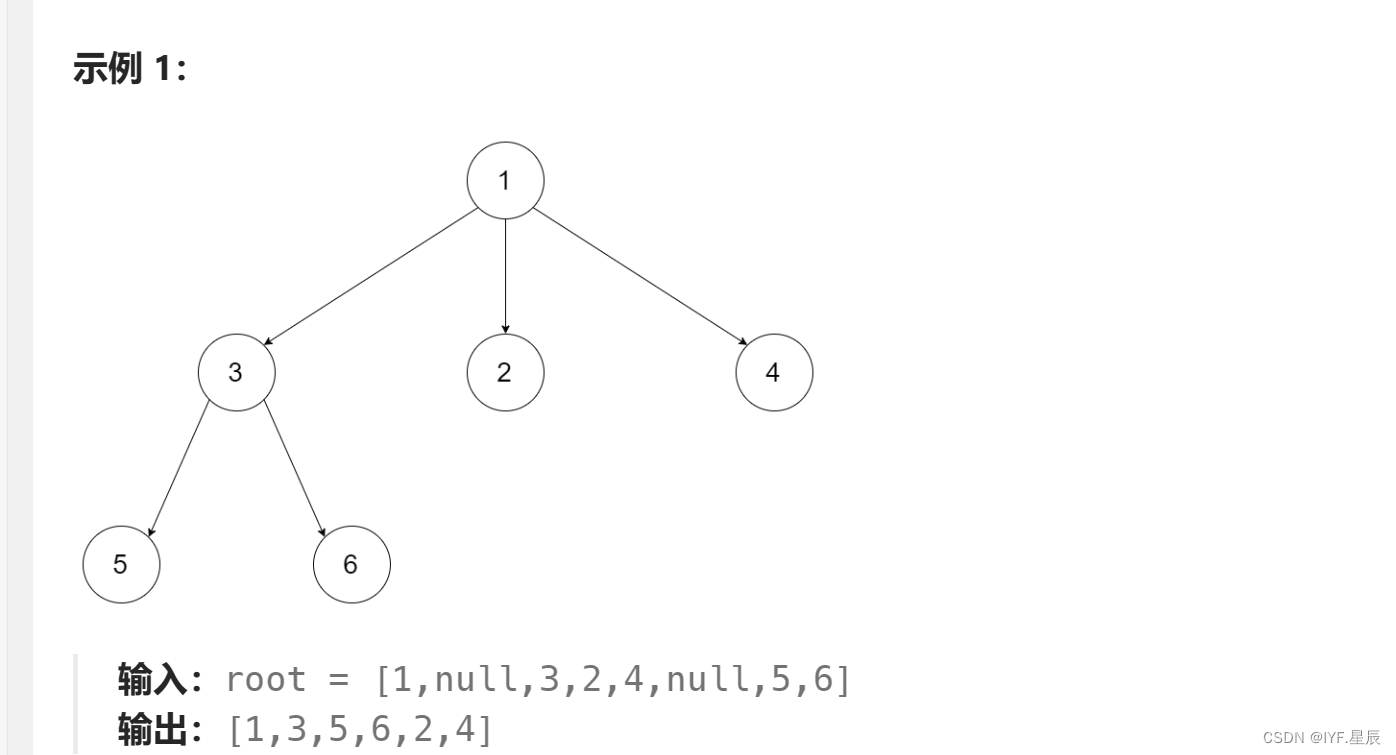
题目链接:589. N 叉树的前序遍历 - 力扣(LeetCode)
题解:
class Solution {
List<Integer> res = new LinkedList<Integer>();//用于存储二叉树的节点信息
public List<Integer> preorder(Node root) {
traverse(root);
return res;
}
void traverse(Node root){
if(root == null){
return ;
}
res.add(root.val);
for(Node child : root.children){
traverse(child);
}
}
}例3:二叉树的最大深度:
题目:
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
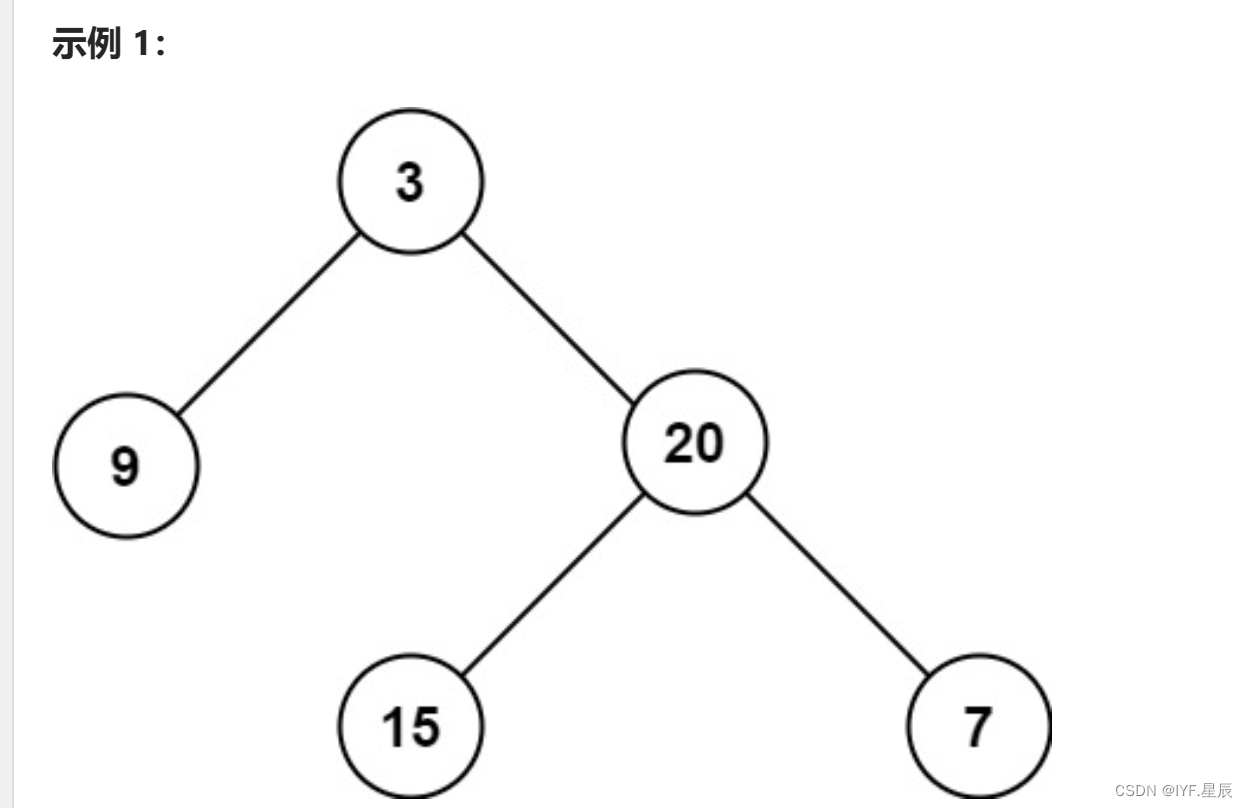
输入:root = [3,9,20,null,null,15,7] 输出:3
题目链接:104. 二叉树的最大深度 - 力扣(LeetCode)
法一:通过二叉树的遍历将其转化为左右子树的最大深度+1(自身)的方式进行求解:
class Solution {
public int maxDepth(TreeNode root) {
if(root == null){
return 0;
}
int leftMax = maxDepth(root.left);//得到左树的最大深度
int rightMax = maxDepth(root.right);//得到右树的最大深度
return 1 + Math.max(leftMax,rightMax);//返回左右子树中的最大深度+1
}
}我们不进入递归理解,而是从该函数的定义出发,maxDepth这个方法就是求树的最大深度,那是不是按照上面的思路我们照搬,先求左子树的最大深度,在求左子树的最大深度,然后从中去最大+1就行了。 或者按照上述的二叉树遍历过程理解:将这颗树不断分解(后序遍历),直到其分解成叶子节点,当它为空时,返回左右子树中的最大+1,在从最小的子树出发,不断往上进行比较,求最值+1---》最终得到我们的结果
法二:迭代思想,通过前序遍历记录最大深度,后续遍历来减少最大深度,同时不断记录最大深度的值:
class Solution {
int ret = 0;//不断刷新最大深度的值
int depth = 0;//记录深度
public void traverse(TreeNode root){
if(root == null){
return ;
}
depth++;//在前序遍历时记录深度不断增加
ret = Math.max(depth,ret);//同时刷新最大值
traverse(root.left);
traverse(root.right);
depth--;//后续遍历时记录深度减少
}
public int maxDepth(TreeNode root) {
traverse(root);
return ret;
}
}例4:二叉树的最小深度
题目:
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。说明:叶子节点是指没有子节点的节点。
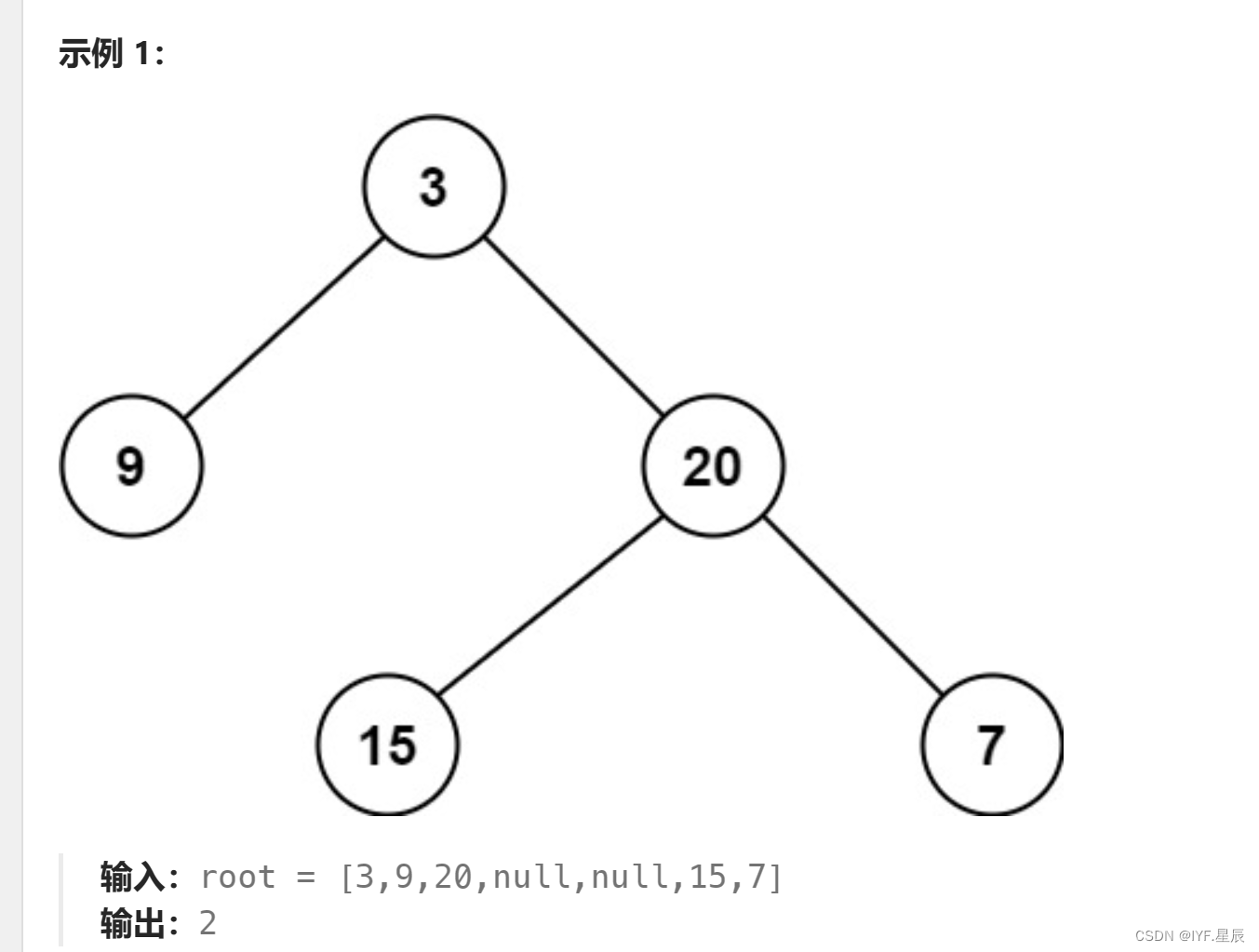
题目链接:111. 二叉树的最小深度 - 力扣(LeetCode)
题解:
法一:分解问题,不断求左右子树最小值:
// 「分解问题」的递归思路
class Solution2 {
public int minDepth(TreeNode root) {
// 基本情况:如果节点为空,返回深度为0
if (root == null) {
return 0;
}
// 递归计算左子树的最小深度
int leftDepth = minDepth(root.left);
// 递归计算右子树的最小深度
int rightDepth = minDepth(root.right);
// 特殊情况处理:如果左子树为空,返回右子树的深度加1
if (leftDepth == 0) {
return rightDepth + 1;
}
// 特殊情况处理:如果右子树为空,返回左子树的深度加1
if (rightDepth == 0) {
return leftDepth + 1;
}
// 计算并返回最小深度:左右子树深度的最小值加1
return Math.min(leftDepth, rightDepth) + 1;
}
}法二:迭代思想:与最小深度类似,但这里需要多一个判断是否是叶子节点,是叶子节点是我们才刷新最小值,不然开始就是最小值后续不会在改变,小细节,开始就定义一个极大值,为后续的找最小值做准备
class Solution {
int depth = 0;
int res = Integer.MAX_VALUE;
public void traverse(TreeNode root){
if(root == null){
return ;
}
depth++;
if(root.left == null && root.right == null){
res = Math.min(res,depth);
}
traverse(root.left);
traverse(root.right);
depth--;
}
public int minDepth(TreeNode root) {
if(root == null){
return 0;
}
traverse(root);
return res;
}
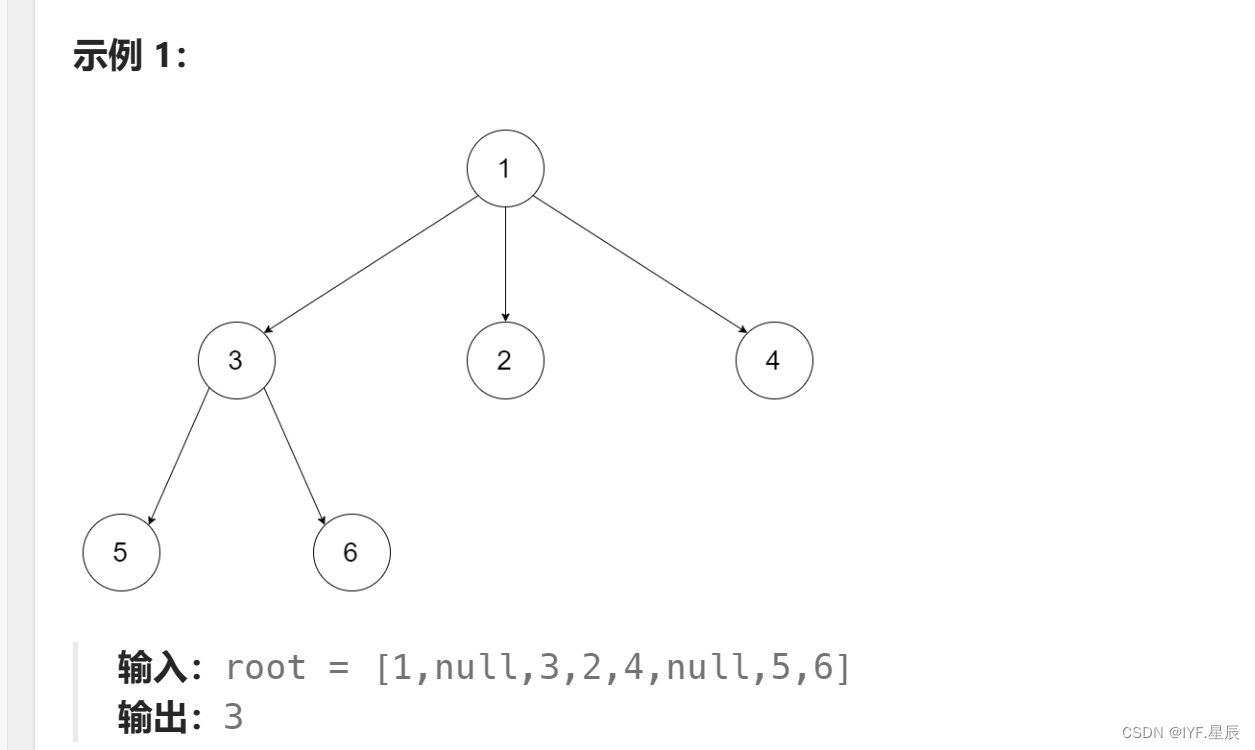
}例5:N叉树的最大深度:
题目:
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
N 叉树输入按层序遍历序列化表示,每组子节点由空值分隔(请参见示例)。
题目链接:559. N 叉树的最大深度 - 力扣(LeetCode)
题解:与二叉树的最大深度基本一致,就是要遍历所有子树:
class Solution {
int res = 0;//记录最大值
int depth = 0;//记录深度
public int maxDepth(Node root) {
if(root == null){
return 0;
}
traverse(root);
return res;
}
public void traverse(Node root){
depth++;
res = Math.max(res,depth);
for(Node child : root.children){
traverse(child);
}
depth--;
}
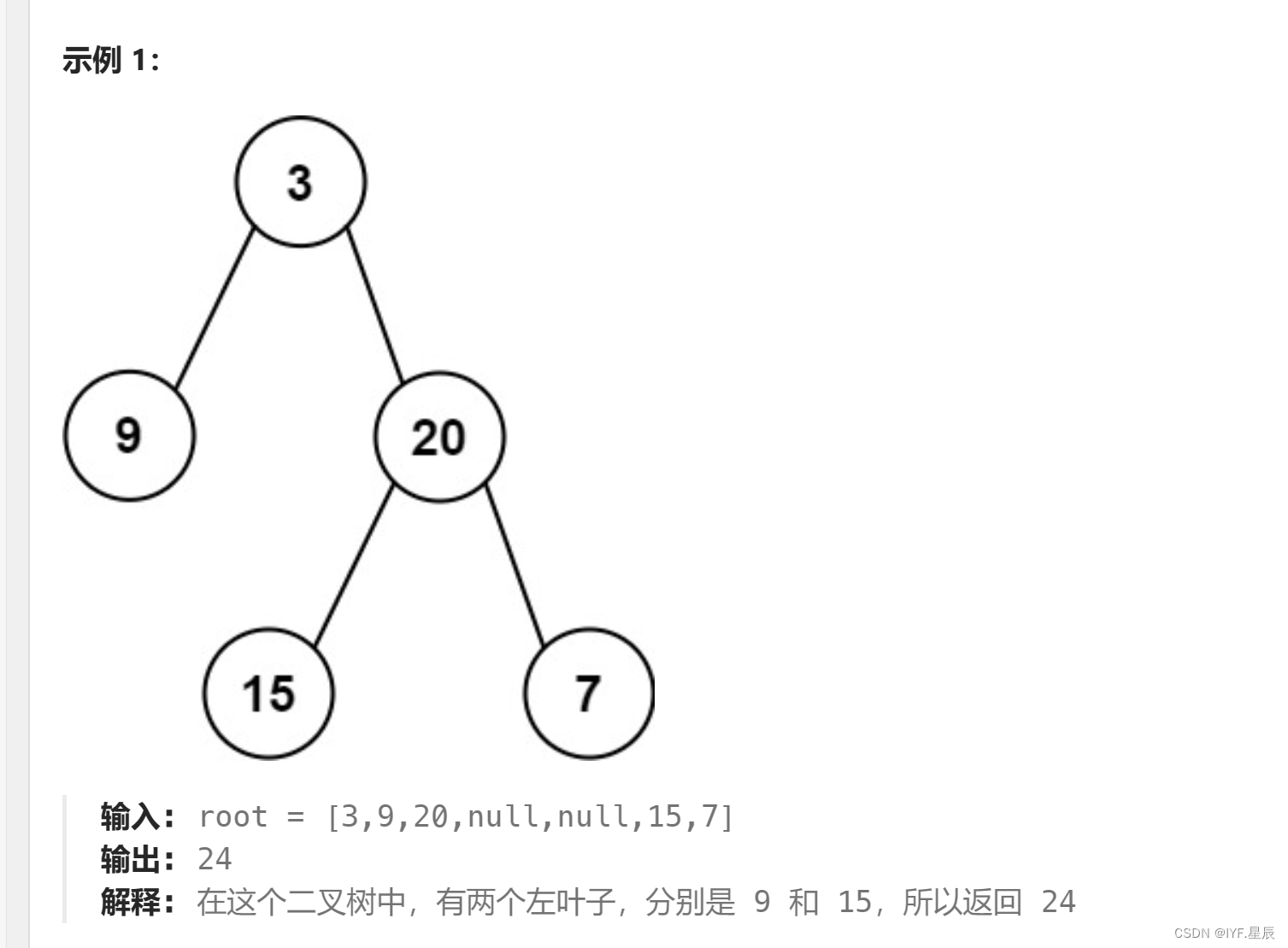
}例6:左叶子之和:
题目:给定二叉树的根节点 root ,返回所有左叶子之和。
题目链接:404. 左叶子之和 - 力扣(LeetCode)
题解:通过给函数传一个boolean值通过二叉树的遍历来判断是否是左叶子节点。然后将是左叶子节点的值相加
class Solution {
int res = 0;
public void dfs(TreeNode root,boolean isLeft){
if(root == null){
return ;
}
//判断是否是左叶子节点,是就加上
if(root.left == null && root.right == null && isLeft){
res += root.val;
}
dfs(root.left,true);
dfs(root.right,false);
}
public int sumOfLeftLeaves(TreeNode root) {
dfs(root,false);
return res;
}
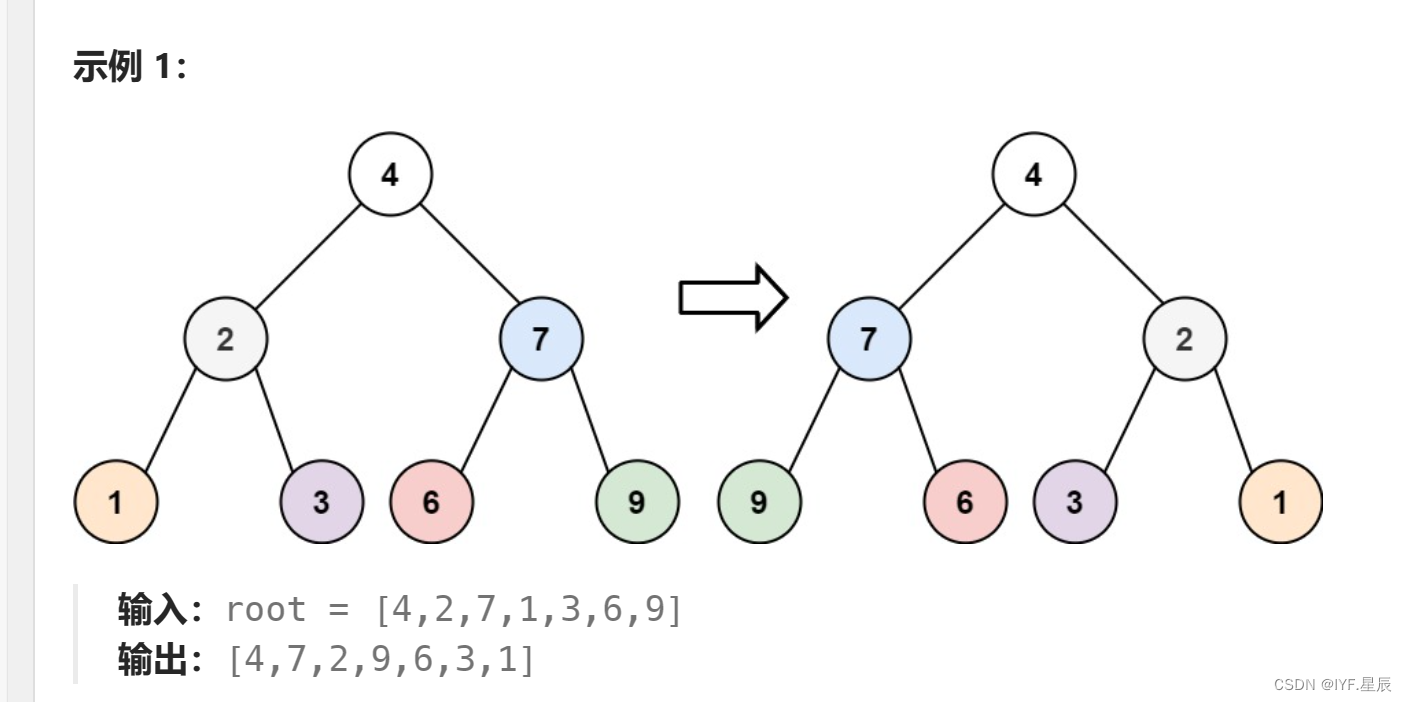
}例7:翻转二叉树:
题目:
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
题目链接:226. 翻转二叉树 - 力扣(LeetCode)
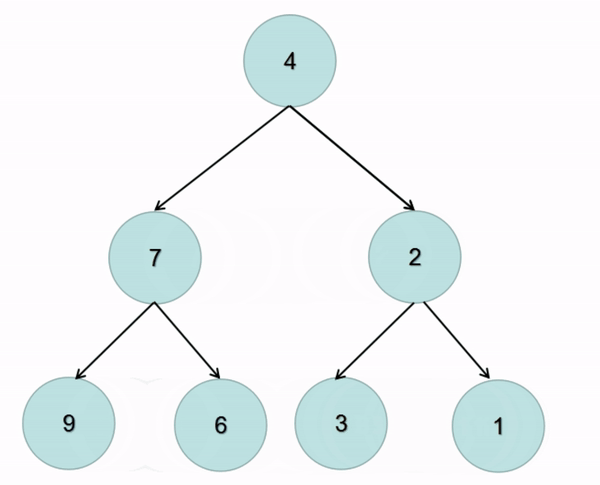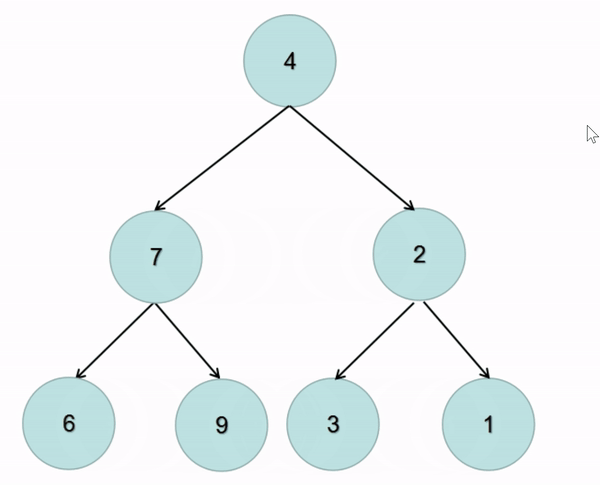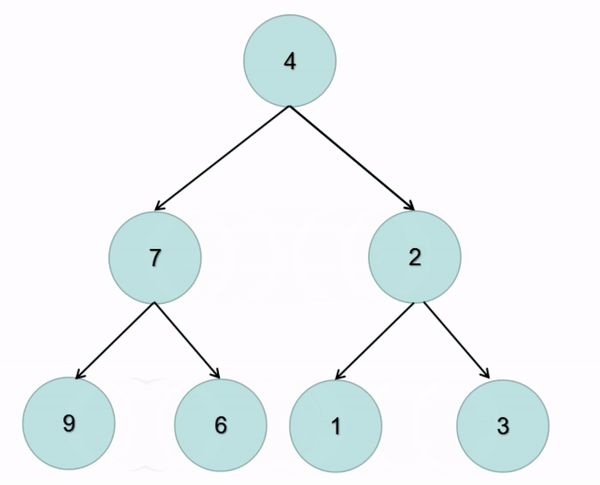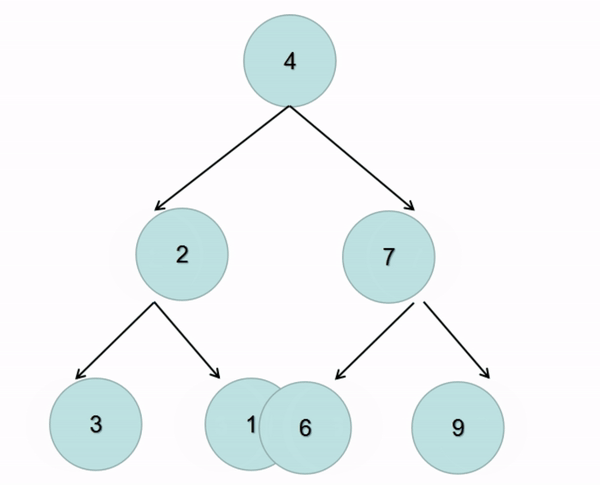
题解:在前序遍历的基础上交换左右子树即可(图解):
class Solution {
public TreeNode invertTree(TreeNode root) {
if(root == null){
return null;
}
//交换左右子树
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invertTree(root.left);
invertTree(root.right);
return root;
}
}例8: 路径总和:
题目:给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
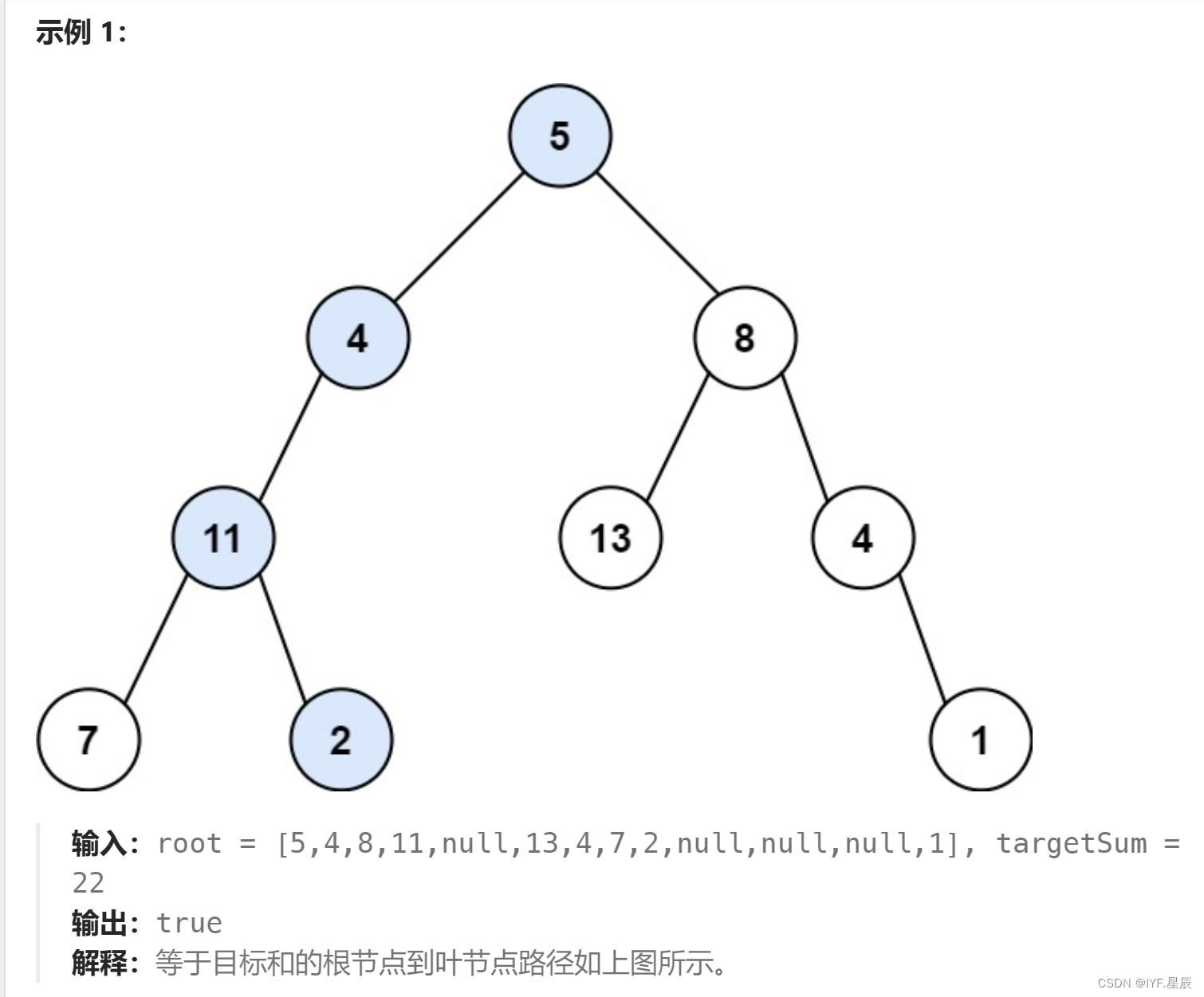
题目链接:112. 路径总和 - 力扣(LeetCode)
题解:法一:在前序遍历位置记录路径的和(节点的val值累加),后序遍历的位置删除路径的和(节点的val值减少):
class Solution {
boolean found = false;
int curSum = 0;
int target;
public void traverse(TreeNode root){
if(root == null){
return ;
}
//前序遍历不断加入节点的和
curSum += root.val;
//判断是否是叶子节点,是就和target值比较
if(root.left == null && root.right == null){
if(curSum == target){
found = true;
}
}
traverse(root.left);
traverse(root.right);
//后序遍历删除节点的值
curSum -= root.val;
}
public boolean hasPathSum(TreeNode root, int targetSum) {
if(root == null){
return false;
}
this.target = targetSum;
traverse(root);
return found;
}
}法二:将路径和不断分解为子树的路径和:
lass Solution {
/* 解法一、分解问题的思路 */
// 定义:输入一个根节点,返回该根节点到叶子节点是否存在一条和为 targetSum 的路径
public boolean hasPathSum(TreeNode root, int targetSum) {
// base case
if (root == null) {
return false;
}
// root.left == root.right 等同于 root.left == null && root.right == null
if (root.left == root.right && root.val == targetSum) {
return true;
}
return hasPathSum(root.left, targetSum - root.val)
|| hasPathSum(root.right, targetSum - root.val);
}
例9:路径总和II:
题目:
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
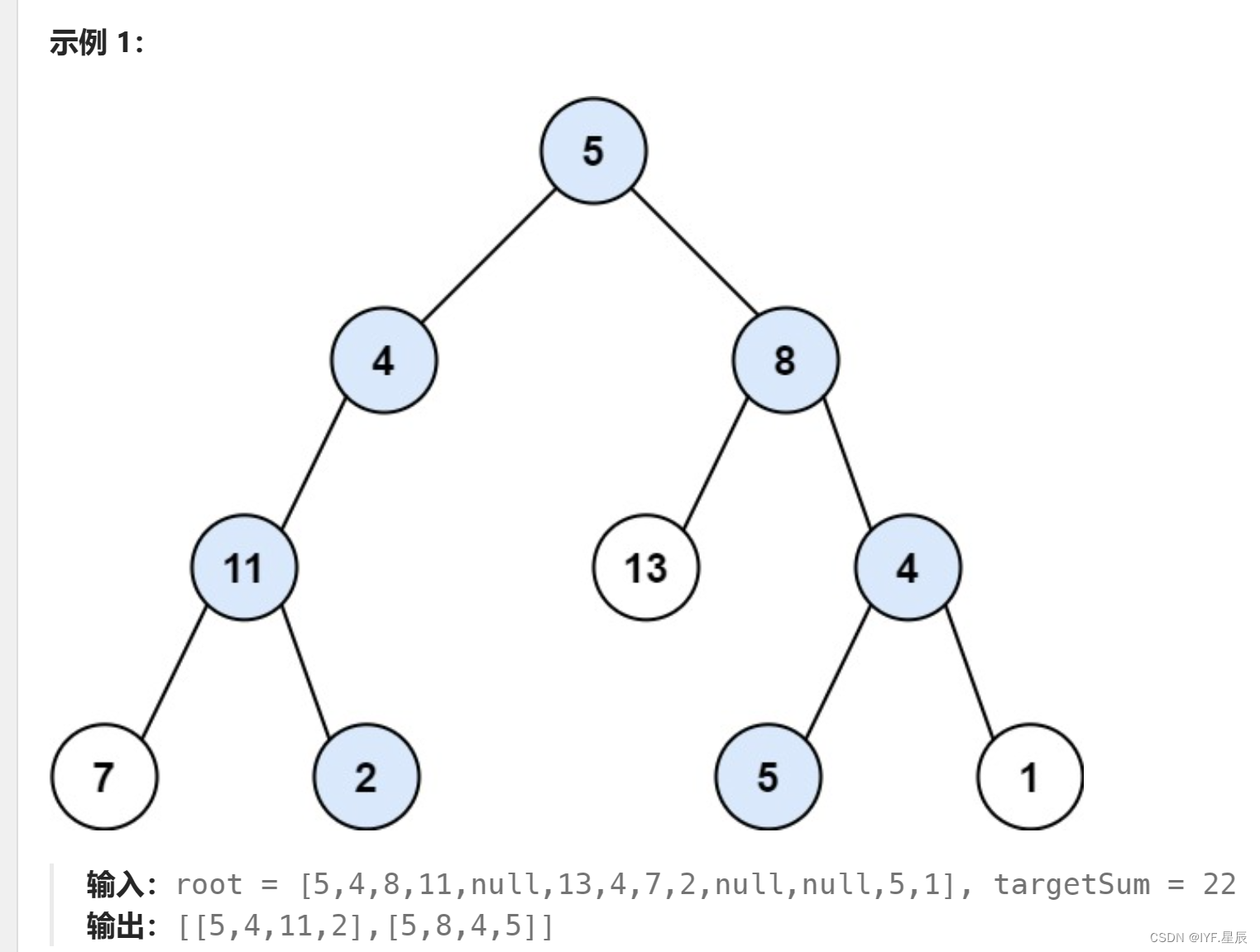
题目链接:113. 路径总和 II - 力扣(LeetCode)
题解:遍历一遍二叉树,就可以把所有符合条件的路径找出来。为了维护经过的路径,在进入递归的时候要在 path 列表添加节点,结束递归的时候删除节点。
class Solution {
List<List<Integer>> res = new LinkedList<>();
public List<List<Integer>> pathSum(TreeNode root, int sum) {
if (root == null) return res;
traverse(root, sum, new LinkedList<>());
return res;
}
// 遍历二叉树
private void traverse(TreeNode root, int sum, LinkedList<Integer> path) {
if (root == null) return;
int remain = sum - root.val;
if (root.left == null && root.right == null) {
if (remain == 0) {
// 找到一条路径
path.addLast(root.val);
res.add(new LinkedList<>(path));
path.removeLast();
}
return;
}
// 维护路径列表
path.addLast(root.val);
traverse(root.left, remain, path);
path.removeLast();
path.addLast(root.val);
traverse(root.right, remain, path);
path.removeLast();
}
}例10:二叉树展开为链表:
题目:
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
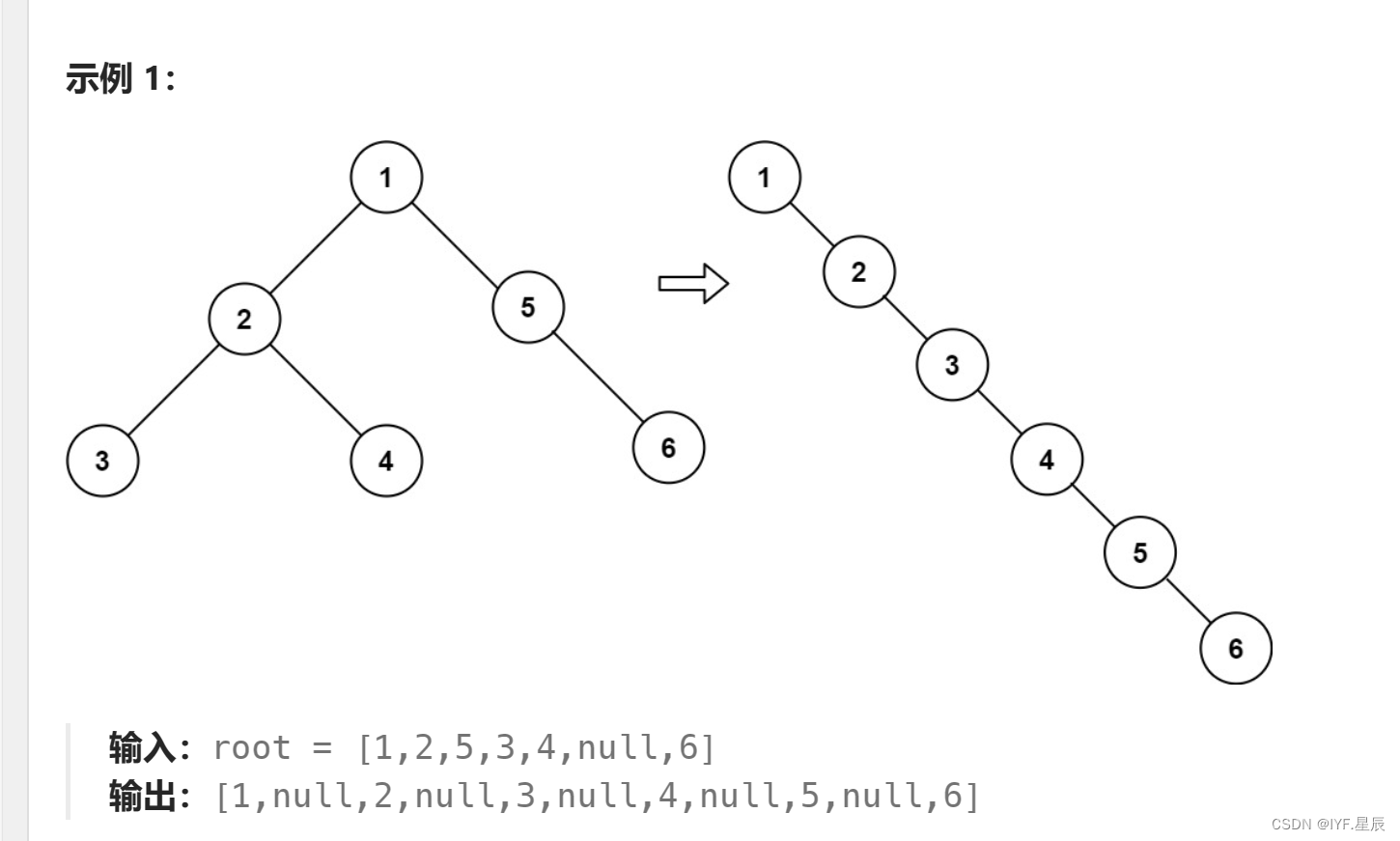
题目链接:114. 二叉树展开为链表 - 力扣(LeetCode)
题解:只要运用二叉树的递归遍历框架即可;后者的关键在于明确递归函数的定义,然后利用这个定义,这题就属于后者,flatten 函数的定义如下:给 flatten 函数输入一个节点 root,那么以 root 为根的二叉树就会被拉平为一条链表。流程:
1、将 root 的左子树和右子树拉平。
2、将 root 的右子树接到左子树下方,然后将整个左子树作为右子树。
class Solution {
// 定义:将以 root 为根的树拉平为链表
public void flatten(TreeNode root) {
// base case
if (root == null) return;
// 先递归拉平左右子树
flatten(root.left);
flatten(root.right);
/****后序遍历位置****/
// 1、左右子树已经被拉平成一条链表
TreeNode left = root.left;
TreeNode right = root.right;
// 2、将左子树作为右子树
root.left = null;
root.right = left;
// 3、将原先的右子树接到当前右子树的末端
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
}
结语: 写博客不仅仅是为了分享学习经历,同时这也有利于我巩固自己的知识点,总结该知识点,由于作者水平有限,对文章有任何问题的还请指出,接受大家的批评,让我改进。同时也希望读者们不吝啬你们的点赞+关注+收藏,你们的鼓励是我创作的最大动力!





![[LWC] Work with Data + Error Handling](https://img-blog.csdnimg.cn/direct/d68d13d6f04a4c3c94aca12b3b551b3b.png)