在风起云涌的AI江湖,NVIDIA凭借其CUDA生态和优秀的硬件大杀四方,立下赫赫战功,而另一家公司AMD也不甘示弱,带着他的生态解决方案ROCm开始了与不世出的NVIDA的正面硬钢,"ROCm is the answer to CUDA", AMD官网如是说。ROCm全称是Radeon Open Compute,从功能上,它是AMD提供的一套用于支持异构计算和GPU加速计算的开发工具和平台。
根据ROCm的官方介绍,这套框架不但支持AMD专业的计算卡,也支持AMD消费级的电脑显卡,之前有搭建过N卡CUDA的学习平台,这里尝试基于AMDGPU,搭建一个ROCm的学习平台。
平台信息
基于Ubuntu 20.04.6 LTS x86_64,显卡为AMD Ryzen 5 5600G with Radeon Graphics集显,应该是VEGA系列,支持VULKAN,OPENCL,当然,不支持CUDA。

搭建步骤
执行如下命令序列,添加用户组和安装ROCm一步到位:
sudo apt update && sudo apt dist-upgrade
sudo apt-get install wget gnupg2
sudo usermod -a -G video $LOGNAME
sudo usermod -a -G render $LOGNAME
echo 'ADD_EXTRA_GROUPS=1' | sudo tee -a /etc/adduser.conf
echo 'EXTRA_GROUPS=video' | sudo tee -a /etc/adduser.conf
echo 'EXTRA_GROUPS=render' | sudo tee -a /etc/adduser.conf
sudo wget https://repo.radeon.com/amdgpu-install/22.10/ubuntu/focal/amdgpu-install_22.10.50100-1_all.deb
sudo apt-get install ./amdgpu-install_22.10.50100-1_all.deb
sudo amdgpu-install --usecase=dkms
amdgpu-install -y --usecase=rocm
echo 'export PATH=$PATH:/opt/rocm/bin:/opt/rocm/profiler/bin:/opt/rocm/opencl/bin' | sudo tee -a /etc/profile.d/rocm.sh
安装结束后,ROCm开发SDK将会出现在/opt目录下, 包括LLVM编译器, opencl, profile, tools等开发工具,便于用户开发自己的基于AMDGPU加速的应用程序。总的来说, ROCm SDK提供了完整的栈支持,包括运行时、编译器、调试器、性能分析工具等,以满足不同开发和优化需求。

AMDGPU编译器目录

测试环境
执行rocm-smi获取显卡设备信息,执行时发现在获取SCLK和功耗两个参数时报错,可能是SDK和显卡兼容方面的问题,不过没有影响后面的简单测试,所以也就没有理会。

AMD一直提倡一种混合异构架构(HSA),这种架构下CPU和GPU乃至各种异构算力被一视同仁,被纳入统一的编程模型开发,从rocminfo工具的输出可以看到这一点,每一个异构算力被认为是一个agent:
$ sudo /opt/rocm/bin/rocminfo我的计算平台有两个AGENT,分别是CPU和GPU,CPU是通用算例,有12个compute unit,对应的是6核12线程SMT。
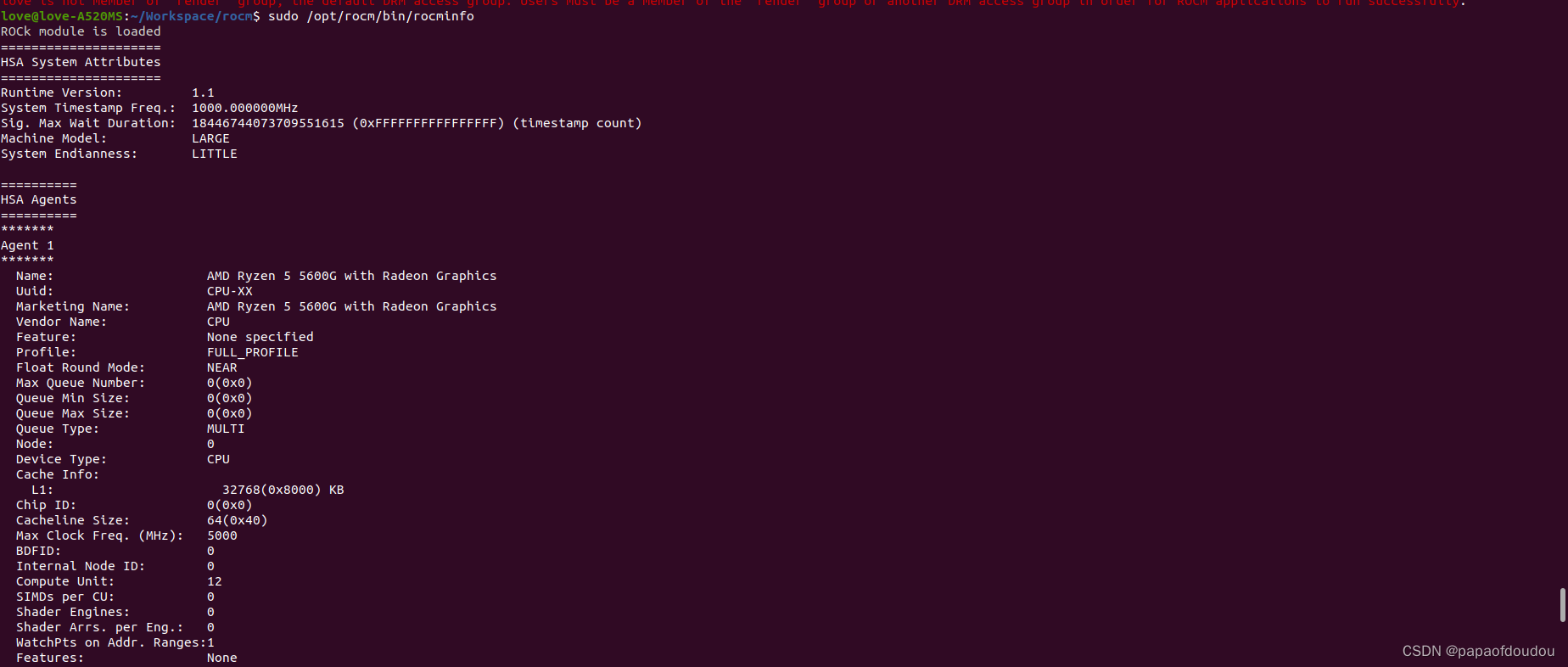
GPU Agent信息,计算单元数量,计算最大的TENSOR维数信息,QUEUE数量,WAVE(Warpper)大小等信息:

opencl支持信息
ROCm不直接支持CUDA,但是 support another GPU programming mode opencl,通过clinfo查看:
/opt/rocm/opencl/bin/clinfo
docker容器运行测试
下载pytorch环境的docker:
sudo docker run -it -v $HOME:/data --privileged --rm --device=/dev/kfd --device=/dev/dri --group-add video --name pytorch rocm/pytorch:latest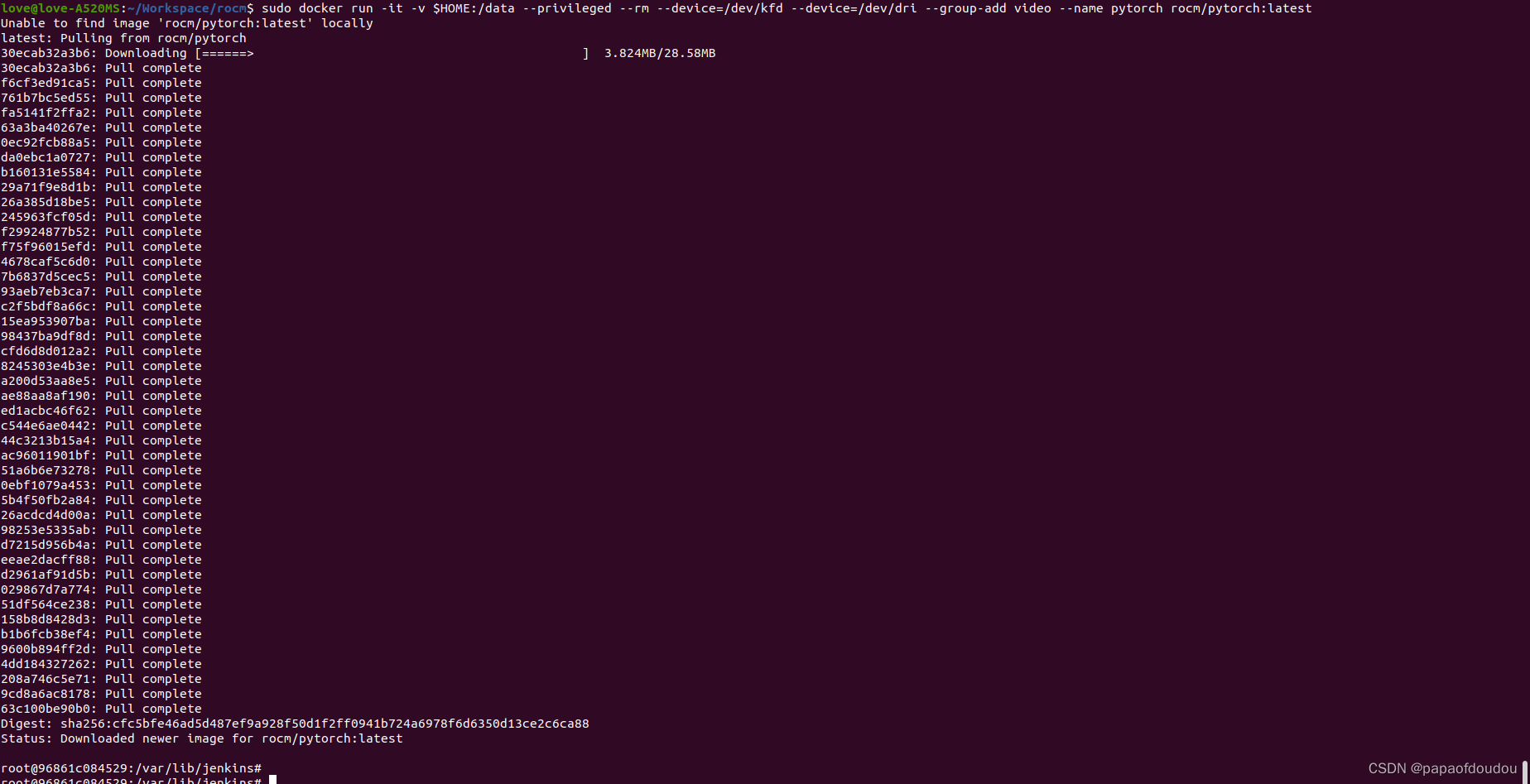
之后,在docker终端中执行如下命令,验证对CUDA的支持(猜测是利用CUDA的生态,底层是CUDA转OpenCL的算子实现):
>>> import torch
>>> torch.cuda.is_available()
输出为TRUE,说明AMDGPU的硬件加速平台搭建成功了。
简单分析
细心的同学可能注意到,在启动docker的测试命令中,传入了一个设备参数--device=/dev/kfd给到DOCKER环境,这个非常重要,kfd本身就是代表AMDGPU异构计算的GPU设备驱动(KMD)的设备节点,它是用户操作GPU的基础。

架构上,AMDKFD驱动程序是Radeon GPU计算软件栈的Linux内核代码,也是该公司ROCm产品的一部分,从 功能上可以理解为在 DRM 子系统中提供了 CPU 与 GPU 沟通的快速通道,使得两者可以平等的访问内存资源而无需额外拷贝。
我们可以在运行上面的测试时,简单追踪以下对KFD内核驱动的调用,以验证加速环境确实使用的AMDGPU显卡,KFD是一个字符设备,所以可以追踪其中的几个FOPS调用,不出所料,在docker中执行如上命令后,内核中则追踪到了如下对KFD的调用栈:
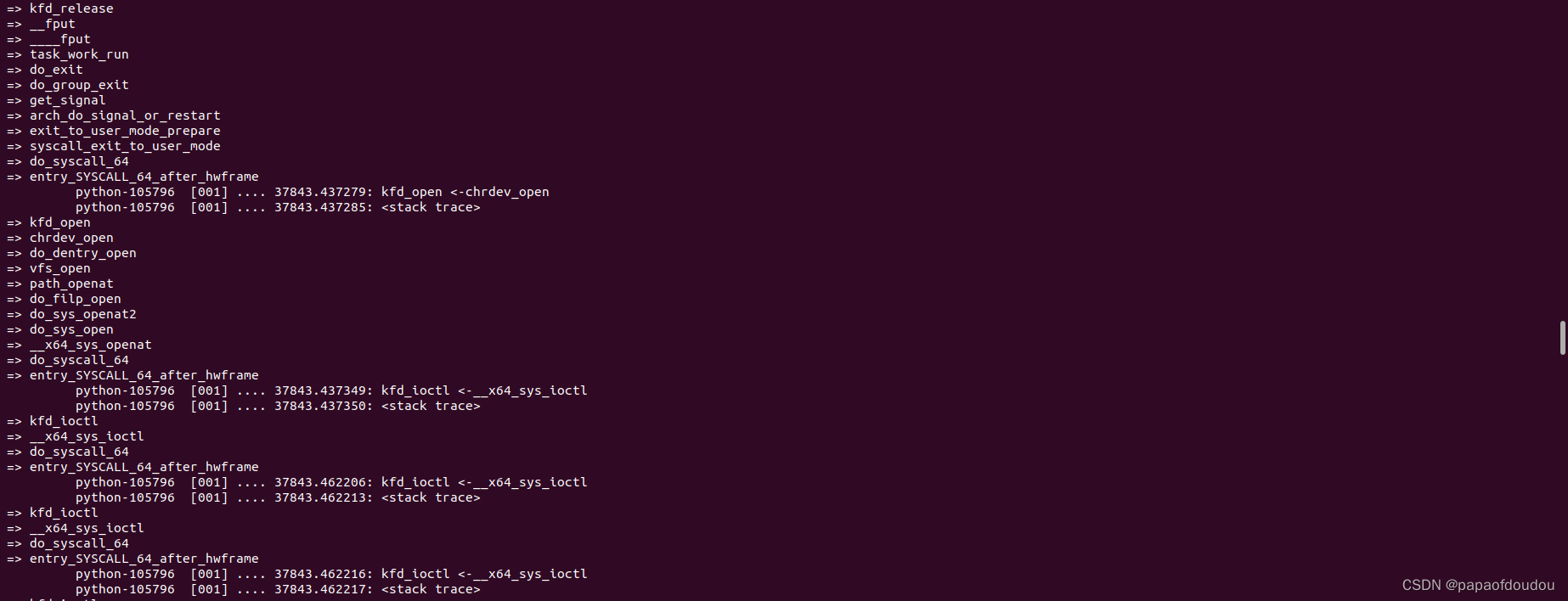
这个例子说明了ROCm穿上了CUDA的外衣,摇身一变实现了对TF框架的支持,但是核心引擎仍然用的是AMDGPU自己的加速实现,包括AMD的编译器,AMD的底层KMD KFD,数学加速库等等实现。
ROCm和CUDA编程模型对比
1.NVIDIA和AMD都支持OpenCL,毕竟CL是个开放标准。
2.OpenACC对标OpenMP,网上有很多例子.
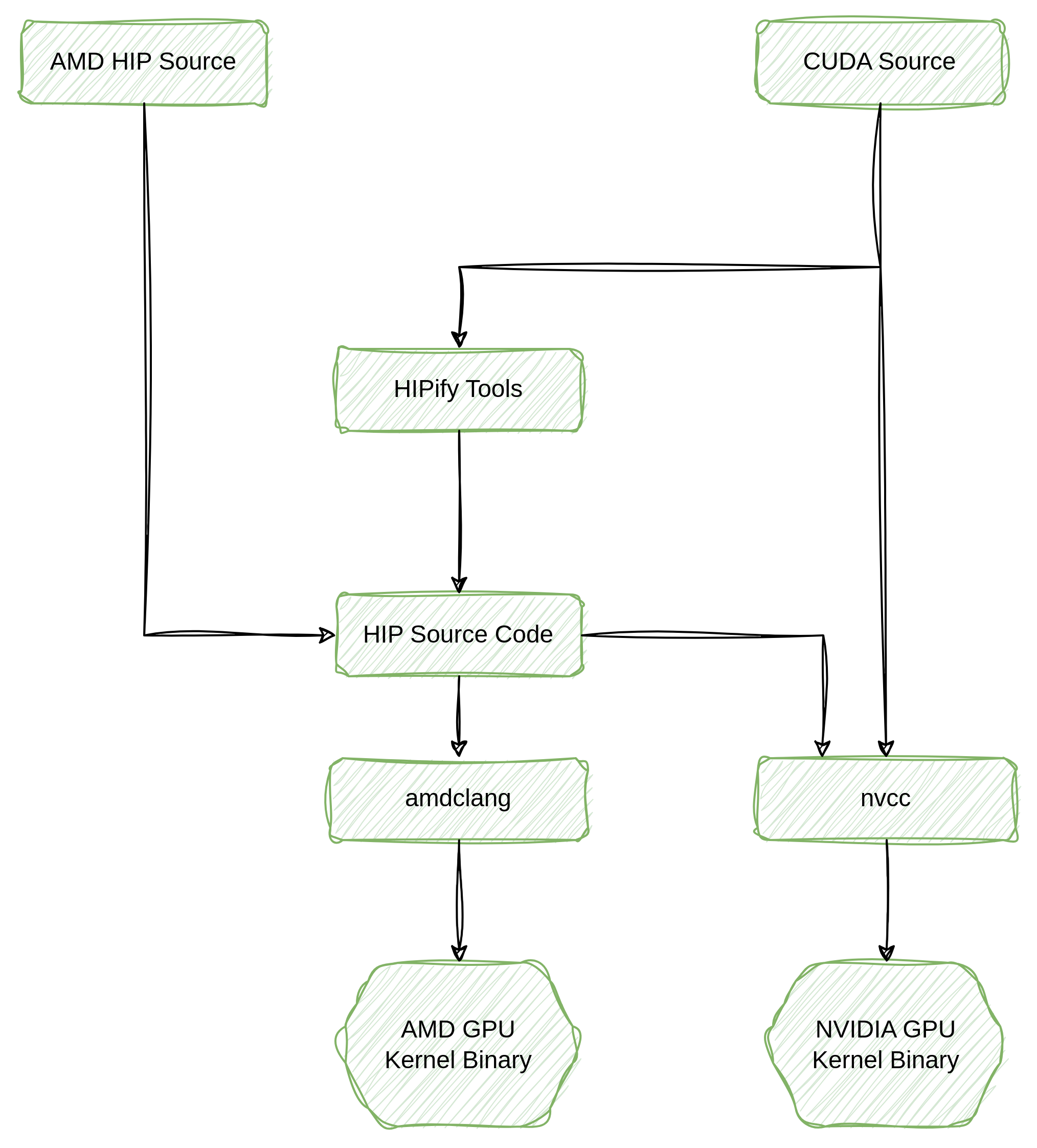
3.HIP对标Cuda,Cuda Source可以翻译为 HIP,然后由ROCm编译为AMDGPU上可运行的代码。
大概意思针对异构计算,深度系学习场景,双方各自都有底牌,目前OpenCL打个平手,HIP和CUDA相比较生态弱一些,OpenACC和OpenMP旗鼓相当。

AMDGPU对CUDA支持方式的分析
以下内容来源于网上的资料和自己不负责任的分析,基于一个原理,计算机中的任何问题都可以通过增加一个中间层来解决:

实现方式是针对hip api(Heterogeneous-Computing Interface for Portability)做CUDA的接口套壳,即将cuda的API接口作为标准接口,用AMD ROCm实现cuda的API(目的就是保证对外的API与CUDA完全相同),但实际调用 HIP+ROCm 的相关接口实现(即实际在A卡上运行),编译生成动态库libcuda*.so,并替换cuda相关动态库,从而完成适配,达到兼容CUDA生态的接口的目的。ROCm也提供了HIPIFY工具,用于将CUDA源代码转换为HIP源代码,实现CUDA代码到HIP的移植。
ROCm API libraries — ROCm Documentation
Hipify工具
HIP是 CUDA API 的”山寨克隆“版。除了一些不常用的功能(e.g. managed memory)外,几乎全盘拷贝 CUDA API,是 CUDA 的一个子集。HIP让开发人员能够使用HIPIFY将CUDA应用程序移植到ROCm,HIPIFY会自动转换CUDA应用程序成为HIP内核语言和运行时API,使用NVIDIA的CUDA编译器或AMDCLANG编译为目标GPU的运行代码。
基于AMDGPU如何运行OpenCL测试用例
参考网络上基于CPU算例的OpenCL的例子,写一个cl的helloworld demo,这个并不太难,因为OpenCL是开源机构Khronos Group定义的标准,在这个标准下所有的头文件,运行时标准等等都是定义好的,所以源码级没有太多改动,基本上拷贝过来就能跑。重点是分析其基于AMDGPU的执行机制。
下面是一份简单的opencl的代码,基本上和C没有什么差别,除了需要提供device端的代码,没有也没有关系,简单的测试用例可以只在主机上跑。
#include <stdio.h>
#include <stdlib.h>
#include <alloca.h>
#include <CL/cl.h>
void displayPlatformInfo(cl_platform_id id,
cl_platform_info param_name,
const char* paramNameAsStr)
{
cl_int error = 0;
size_t paramSize = 0;
error = clGetPlatformInfo( id, param_name, 0, NULL, ¶mSize );
char* moreInfo = (char*)alloca( sizeof(char) * paramSize);
error = clGetPlatformInfo( id, param_name, paramSize, moreInfo, NULL );
if (error != CL_SUCCESS ) {
perror("Unable to find any OpenCL platform information");
return;
}
printf("%s: %s\n", paramNameAsStr, moreInfo);
}
int main(void) {
/* OpenCL 1.1 data structures */
cl_platform_id* platforms;
/* OpenCL 1.1 scalar data types */
cl_uint numOfPlatforms;
cl_int error;
/*
Get the number of platforms
Remember that for each vendor's SDK installed on the computer,
the number of available platform also increased.
*/
error = clGetPlatformIDs(0, NULL, &numOfPlatforms);
if(error != CL_SUCCESS) {
perror("Unable to find any OpenCL platforms");
exit(1);
}
// Allocate memory for the number of installed platforms.
// alloca(...) occupies some stack space but is automatically freed on return
platforms = (cl_platform_id*) alloca(sizeof(cl_platform_id) * numOfPlatforms);
printf("Number of OpenCL platforms found: %d\n", numOfPlatforms);
error = clGetPlatformIDs(numOfPlatforms, platforms, NULL);
if(error != CL_SUCCESS) {
perror("Unable to find any OpenCL platforms");
exit(1);
}
// We invoke the API 'clPlatformInfo' twice for each parameter we're trying to extract
// and we use the return value to create temporary data structures (on the stack) to store
// the returned information on the second invocation.
for(cl_uint i = 0; i < numOfPlatforms; ++i) {
displayPlatformInfo( platforms[i], CL_PLATFORM_PROFILE, "CL_PLATFORM_PROFILE" );
displayPlatformInfo( platforms[i], CL_PLATFORM_VERSION, "CL_PLATFORM_VERSION" );
displayPlatformInfo( platforms[i], CL_PLATFORM_NAME, "CL_PLATFORM_NAME" );
displayPlatformInfo( platforms[i], CL_PLATFORM_VENDOR, "CL_PLATFORM_VENDOR" );
displayPlatformInfo( platforms[i], CL_PLATFORM_EXTENSIONS, "CL_PLATFORM_EXTENSIONS" );
}
return 0;
}编译
ROCm环境安装了OpenCL开发所需要的编译器,OpenCL运行时环境,以及标准的Khronos Group头文件,使用如下命令编译:
/opt/rocm/llvm/bin/clang opencl.c -I/opt/rocm/opencl/include -L/opt/rocm/opencl/lib -lOpenCL编译,运行测试没有问题

strace追踪系统调用,发现opencl的测试用例确实打开了/dev/kfd设备节点,并对GPU进行IOCTL操作:
strace -tt -T -f -e trace=file,close,openat,ioctl -o strace.log ./a.out
这个用例比较简单,调用的IOCTL 列表如下:
开发OpenCL Kernel测试用例
前面的例子只有主机侧的代码,没有GPU运行的代码,实际上没有调用AMDGPU的异构计算能力,参考网上的代码,写一个实现两个一维向量加和的kernel,投到AMDGPU上得到计算结果:
#include <stdio.h>
#include <stdlib.h>
#include <alloca.h>
#include <CL/cl.h>
#pragma warning( disable : 4996 )
int main() {
cl_int error;
cl_platform_id platforms;
cl_device_id devices;
cl_context context;
FILE *program_handle;
size_t program_size;
char *program_buffer;
cl_program program;
size_t log_size;
char *program_log;
char kernel_name[] = "createBuffer";
cl_kernel kernel;
cl_command_queue queue;
//获取平台
error = clGetPlatformIDs(1, &platforms, NULL);
if (error != 0) {
printf("Get platform failed!");
return -1;
}
//获取设备
error = clGetDeviceIDs(platforms, CL_DEVICE_TYPE_GPU, 1, &devices, NULL);
if (error != 0) {
printf("Get device failed!");
return -1;
}
//创建上下文
context = clCreateContext(NULL,1,&devices,NULL,NULL,&error);
if (error != 0) {
printf("Creat context failed!");
return -1;
}
//创建程序;注意要用"rb"
program_handle = fopen("kernel.cl","rb");
if (program_handle == NULL) {
printf("The kernle can not be opened!");
return -1;
}
fseek(program_handle,0,SEEK_END);
program_size = ftell(program_handle);
rewind(program_handle);
program_buffer = (char *)malloc(program_size+1);
program_buffer[program_size] = '\0';
error=fread(program_buffer,sizeof(char),program_size,program_handle);
if (error == 0) {
printf("Read kernel failed!");
return -1;
}
fclose(program_handle);
program = clCreateProgramWithSource(context,1,(const char **)&program_buffer,
&program_size,&error);
if (error < 0) {
printf("Couldn't create the program!");
return -1;
}
//编译程序
error = clBuildProgram(program,1,&devices,NULL,NULL,NULL);
if (error < 0) {
//确定日志文件的大小
clGetProgramBuildInfo(program,devices,CL_PROGRAM_BUILD_LOG,0,NULL,&log_size);
program_log = (char *)malloc(log_size+1);
program_log[log_size] = '\0';
//读取日志
clGetProgramBuildInfo(program, devices, CL_PROGRAM_BUILD_LOG,
log_size+1, program_log, NULL);
printf("%s\n",program_log);
free(program_log);
return -1;
}
free(program_buffer);
//创建命令队列
queue = clCreateCommandQueue(context, devices, CL_QUEUE_PROFILING_ENABLE, &error);
if (error < 0) {
printf("Coudn't create the command queue");
return -1;
}
//创建内核
kernel = clCreateKernel(program,kernel_name,&error);
if (kernel==NULL) {
printf("Couldn't create kernel!\n");
return -1;
}
//初始化参数
float result[100];
float a_in[100];
float b_in[100];
for (int i = 0; i < 100; i++) {
a_in[i] = i;
b_in[i] = i*2.0;
}
//创建缓存对象
cl_mem memObject1 = clCreateBuffer(context,CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR,sizeof(float)*100,a_in,&error);
if (error < 0) {
printf("Creat memObject1 failed!\n");
return -1;
}
cl_mem memObject2 = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float) * 100, b_in, &error);
if (error < 0) {
printf("Creat memObject2 failed!\n");
return -1;
}
cl_mem memObject3 = clCreateBuffer(context, CL_MEM_WRITE_ONLY ,
sizeof(float) * 100, NULL, &error);
if (error < 0) {
printf("Creat memObject3 failed!\n");
return -1;
}
//设置内核参数
error = clSetKernelArg(kernel,0,sizeof(cl_mem),&memObject1);
error|= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObject2);
error |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObject3);
if (error != CL_SUCCESS) {
printf("Error setting kernel arguments!\n");
return -1;
}
//执行内核
size_t globalWorkSize[1] = {100};
size_t localWorkSize[1] = {1};
error = clEnqueueNDRangeKernel(queue,kernel,1,NULL,globalWorkSize,
localWorkSize,0,NULL,NULL);
if (error != CL_SUCCESS) {
printf("Error queuing kernel for execution!\n");
return -1;
}
//读取执行结果
error = clEnqueueReadBuffer(queue,memObject3,CL_TRUE,0,100*sizeof(float),
result,0,NULL,NULL);
if (error != CL_SUCCESS) {
printf("Error reading result buffer!\n");
return -1;
}
//显示结果
for (int i = 0; i < 100; i++) {
printf("%f ",result[i]);
}
printf("\n");
//释放资源
clReleaseDevice(devices);
clReleaseContext(context);
clReleaseCommandQueue(queue);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseMemObject(memObject1);
clReleaseMemObject(memObject2);
clReleaseMemObject(memObject3);
return 0;
}设备端代码:
__kernel void createBuffer(__global const float *a_in,
__global const float *b_in,
__global float *result) {
int gid = get_global_id(0);
result[gid] = a_in[gid] + b_in[gid];
}编译命令不变,kernel.cl会被主文件读入,然后被ROCm动态编译为GPU端指令,通过ROCm runtime加载道GPU端运行,得到计算结果,计算结果符合预期:


作为驱动开发者,实际上最关心的是KFD端的调用序列,通过追踪可以看到,此时由于加入了设备端计算的功能,KFD的IOCTL调用序列明显比前面长了好多,其中包括了COMMAND QUEUE创建的IOCTL也被调用到,因为设备端代码要通过COMMAND QUEUE传递给AMDGPU去执行。
完整的KFD调用序列记录如下,方便以后分析:
5684 00:08:54.545211 ioctl(5, AMDKFD_IOC_GET_VERSION, 0x7ffe0edc1e00) = 0 <0.000005>
5684 00:08:54.549152 ioctl(5, AMDKFD_IOC_GET_PROCESS_APERTURES_NEW, 0x7ffe0edc1ab0) = 0 <0.000005>
5684 00:08:54.549169 ioctl(5, AMDKFD_IOC_ACQUIRE_VM, 0x7ffe0edc1ab0) = 0 <0.000033>
5684 00:08:54.549262 ioctl(5, AMDKFD_IOC_SET_MEMORY_POLICY, 0x7ffe0edc1ab0) = 0 <0.000004>
5684 00:08:54.549301 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1970) = 0 <0.000007>
5684 00:08:54.549333 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1990) = 0 <0.000091>
5684 00:08:54.581556 ioctl(5, AMDKFD_IOC_GET_CLOCK_COUNTERS, 0x7ffe0edc1a40) = 0 <0.000006>
5684 00:08:54.581583 ioctl(5, AMDKFD_IOC_GET_CLOCK_COUNTERS, 0x7ffe0edc1e30) = 0 <0.000004>
5684 00:08:54.581626 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1b90) = 0 <0.000012>
5684 00:08:54.581677 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1c60) = 0 <0.000239>
5684 00:08:54.581933 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1db0) = 0 <0.000014>
5684 00:08:54.582012 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1ad0) = 0 <0.000022>
5684 00:08:54.582043 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1b00) = 0 <0.000029>
5684 00:08:54.582084 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1ca0) = 0 <0.000004>
5684 00:08:54.582259 ioctl(5, AMDKFD_IOC_SET_SCRATCH_BACKING_VA, 0x7ffe0edc1d40) = 0 <0.000002>
5684 00:08:54.582322 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1750) = 0 <0.000010>
5684 00:08:54.582342 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1780) = 0 <0.000031>
5684 00:08:54.582388 ioctl(5, AMDKFD_IOC_SET_TRAP_HANDLER, 0x7ffe0edc1e10) = 0 <0.000006>
5687 00:08:54.582511 ioctl(5, AMDKFD_IOC_WAIT_EVENTS <unfinished ...>
5684 00:08:54.587645 ioctl(5, AMDKFD_IOC_GET_TILE_CONFIG, 0x7ffe0edc1310) = 0 <0.000005>
5684 00:08:54.587777 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc19d0) = 0 <0.000153>
5684 00:08:54.587945 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc19e0) = 0 <0.000246>
5684 00:08:54.588269 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc19d0) = 0 <0.000146>
5684 00:08:54.588429 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc19e0) = 0 <0.000035>
5684 00:08:54.588477 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1be0) = 0 <0.000007>
5689 00:08:54.650506 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef744e0) = 0 <0.000028>
5689 00:08:54.650547 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74510) = 0 <0.000222>
5689 00:08:54.650832 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74490) = 0 <0.000009>
5689 00:08:54.650851 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef744c0) = 0 <0.000035>
5689 00:08:54.650897 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74700) = 0 <0.000006>
5689 00:08:54.650964 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74240) = 0 <0.000008>
5689 00:08:54.650982 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef742b0) = 0 <0.000034>
5689 00:08:54.651053 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74200) = 0 <0.000008>
5689 00:08:54.651090 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef742b0) = 0 <0.000036>
5689 00:08:54.651186 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74240) = 0 <0.000376>
5689 00:08:54.651573 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef742b0) = 0 <0.000114>
5689 00:08:54.651697 ioctl(5, AMDKFD_IOC_CREATE_QUEUE, 0x7fae7ef74420) = 0 <0.000177>
5689 00:08:54.651914 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef742c0) = 0 <0.000008>
5689 00:08:54.651945 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74330) = 0 <0.000025>
5689 00:08:54.651981 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7fae7ef74710) = 0 <0.000007>
5689 00:08:54.652000 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7fae7ef74710) = 0 <0.000006>
5689 00:08:54.652067 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74510) = 0 <0.000010>
5689 00:08:54.652086 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74540) = 0 <0.000024>
5689 00:08:54.652175 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef745f0) = 0 <0.000009>
5689 00:08:54.652196 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74620) = 0 <0.000028>
5687 00:08:54.652231 ioctl(5, AMDKFD_IOC_WAIT_EVENTS, 0x7fae7f7e8c20) = 0 <0.000008>
5687 00:08:54.652251 ioctl(5, AMDKFD_IOC_WAIT_EVENTS <unfinished ...>
5689 00:08:54.652295 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef745a0) = 0 <0.000048>
5689 00:08:54.652353 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef745d0) = 0 <0.000029>
5689 00:08:54.652446 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74350) = 0 <0.000010>
5689 00:08:54.652467 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef743c0) = 0 <0.000024>
5689 00:08:54.652531 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74310) = 0 <0.000008>
5689 00:08:54.652565 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef743c0) = 0 <0.000030>
5689 00:08:54.652654 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74350) = 0 <0.000390>
5689 00:08:54.653057 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef743c0) = 0 <0.000119>
5689 00:08:54.653190 ioctl(5, AMDKFD_IOC_CREATE_QUEUE, 0x7fae7ef74530) = 0 <0.000068>
5689 00:08:54.653271 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7fae7ef74820) = 0 <0.000007>
5689 00:08:54.653290 ioctl(5, AMDKFD_IOC_SET_EVENT <unfinished ...>
5689 00:08:54.653366 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74620) = 0 <0.000010>
5689 00:08:54.653386 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74650) = 0 <0.000025>
5689 00:08:54.653480 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU <unfinished ...>
5687 00:08:54.653532 ioctl(5, AMDKFD_IOC_WAIT_EVENTS, 0x7fae7f7e8c20) = 0 <0.000005>
5687 00:08:54.653551 ioctl(5, AMDKFD_IOC_WAIT_EVENTS <unfinished ...>
5689 00:08:54.653590 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74a30) = 0 <0.000025>
5689 00:08:54.836246 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef73c80) = 0 <0.000022>
5689 00:08:54.836303 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef73cf0) = 0 <0.000049>
5689 00:08:54.836417 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef73da0) = 0 <0.000019>
5689 00:08:54.836447 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef73dd0) = 0 <0.000031>
5689 00:08:54.836509 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74690) = 0 <0.000007>
5689 00:08:54.836582 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74590) = 0 <0.000010>
5689 00:08:54.836603 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef745c0) = 0 <0.000029>
5689 00:08:54.836696 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74140) = 0 <0.000007>
5689 00:08:54.836714 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74170) = 0 <0.000023>
5689 00:08:54.836800 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74140) = 0 <0.000007>
5689 00:08:54.836818 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74170) = 0 <0.000027>
5689 00:08:54.837235 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74140) = 0 <0.000018>
5689 00:08:54.837266 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74170) = 0 <0.000085>
5689 00:08:54.837497 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74840) = 0 <0.000009>
5689 00:08:54.837519 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74840) = 0 <0.000025>
5689 00:08:54.837558 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000007>
5689 00:08:54.837577 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000005>
5689 00:08:54.837599 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000007>
5689 00:08:54.837618 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837632 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837647 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837662 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837676 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837691 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837705 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000008>
5689 00:08:54.837723 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837738 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837752 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837766 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000004>
5689 00:08:54.837835 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef748b0) = 0 <0.000011>
5689 00:08:54.837857 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef748e0) = 0 <0.000080>
5689 00:08:54.837951 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.837971 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000009>
5689 00:08:54.837999 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000009>
5689 00:08:54.838024 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838046 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838067 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838088 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838109 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838130 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838151 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838172 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838193 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838214 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838236 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838257 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838278 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838299 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5689 00:08:54.838321 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74b50) = 0 <0.000006>
5684 00:08:54.838720 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc14a0) = 0 <0.000020>
5684 00:08:54.838757 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc14d0) = 0 <0.000032>
5684 00:08:54.838963 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1840) = 0 <0.000014>
5684 00:08:54.838994 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1870) = 0 <0.000032>
5684 00:08:54.839099 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc17f0) = 0 <0.000044>
5684 00:08:54.839154 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1820) = 0 <0.000024>
5684 00:08:54.839247 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc15a0) = 0 <0.000008>
5684 00:08:54.839266 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1610) = 0 <0.000027>
5684 00:08:54.839331 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1560) = 0 <0.000007>
5684 00:08:54.839366 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1610) = 0 <0.000032>
5684 00:08:54.839457 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc15a0) = 0 <0.000281>
5684 00:08:54.839754 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1610) = 0 <0.000104>
5684 00:08:54.839873 ioctl(5, AMDKFD_IOC_CREATE_QUEUE, 0x7ffe0edc1780) = 0 <0.000162>
5684 00:08:54.840049 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7ffe0edc1a70) = 0 <0.000006>
5684 00:08:54.840071 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7ffe0edc1a70) = 0 <0.000003>
5684 00:08:54.840148 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1870) = 0 <0.000010>
5684 00:08:54.840169 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc18a0) = 0 <0.000032>
5684 00:08:54.840267 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU <unfinished ...>
5687 00:08:54.840306 ioctl(5, AMDKFD_IOC_WAIT_EVENTS, 0x7fae7f7e8c20) = 0 <0.000007>
5687 00:08:54.840324 ioctl(5, AMDKFD_IOC_WAIT_EVENTS <unfinished ...>
5684 00:08:54.840351 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1c80) = 0 <0.000033>
5684 00:08:54.840433 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc1a90) = 0 <0.000007>
5684 00:08:54.840452 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1a90) = 0 <0.000024>
5684 00:08:54.840489 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000005>
5684 00:08:54.840506 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840520 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840534 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840548 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840562 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840576 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840589 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840603 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840617 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840630 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840644 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840658 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840672 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840686 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840700 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840714 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840728 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840741 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840755 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840769 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840782 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840796 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840810 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840824 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840837 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840854 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840869 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840883 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000009>
5684 00:08:54.840902 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000004>
5684 00:08:54.840916 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840930 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1da0) = 0 <0.000003>
5684 00:08:54.840998 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc19b0) = 0 <0.000130>
5684 00:08:54.841144 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc19e0) = 0 <0.000119>
5684 00:08:54.841363 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7ffe0edc16e0) = 0 <0.000008>
5684 00:08:54.841382 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7ffe0edc1750) = 0 <0.000023>
5684 00:08:54.841416 ioctl(5, AMDKFD_IOC_CREATE_QUEUE, 0x7ffe0edc18c0) = 0 <0.000025>
5684 00:08:54.841452 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1b60) = 0 <0.000004>
5684 00:08:54.841466 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7ffe0edc1b60) = 0 <0.000004>
5689 00:08:54.841551 ioctl(5, AMDKFD_IOC_GET_CLOCK_COUNTERS, 0x7fae7ef748a0) = 0 <0.000007>
5689 00:08:54.841637 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef745d0) = 0 <0.000150>
5689 00:08:54.841800 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74600) = 0 <0.000090>
5689 00:08:54.841996 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef74300) = 0 <0.000010>
5689 00:08:54.842018 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74370) = 0 <0.000024>
5689 00:08:54.842054 ioctl(5, AMDKFD_IOC_CREATE_QUEUE, 0x7fae7ef744e0) = 0 <0.000033>
5689 00:08:54.842099 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74780) = 0 <0.000005>
5689 00:08:54.842172 ioctl(5, AMDKFD_IOC_ALLOC_MEMORY_OF_GPU, 0x7fae7ef744e0) = 0 <0.000011>
5689 00:08:54.842194 ioctl(5, AMDKFD_IOC_MAP_MEMORY_TO_GPU, 0x7fae7ef74510) = 0 <0.000029>
5689 00:08:54.842235 ioctl(5, AMDKFD_IOC_CREATE_EVENT, 0x7fae7ef74780) = 0 <0.000004>
5689 00:08:54.842440 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7fae7ef74c30) = 0 <0.000011>
5689 00:08:54.842468 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7fae7ef74c70) = 0 <0.000011>
5689 00:08:54.842517 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7fae7ef74bf0) = 0 <0.000006>
5689 00:08:54.842536 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7fae7ef74c40) = 0 <0.000010>
5689 00:08:54.842603 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7fae7ef74d10) = 0 <0.000006>
5687 00:08:54.842634 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7fae7f7e8da0) = 0 <0.000007>
5689 00:08:54.842654 ioctl(5, AMDKFD_IOC_DESTROY_QUEUE <unfinished ...>
5687 00:08:54.842660 ioctl(5, AMDKFD_IOC_SET_EVENT, 0x7fae7f7e8df0) = 0 <0.000007>
5689 00:08:54.842752 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7fae7ef74c30) = 0 <0.000007>
5689 00:08:54.842770 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7fae7ef74c80) = 0 <0.000006>
5689 00:08:54.842841 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU <unfinished ...>
5687 00:08:54.842879 ioctl(5, AMDKFD_IOC_WAIT_EVENTS <unfinished ...>
5689 00:08:54.842899 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU <unfinished ...>
5687 00:08:54.842906 ioctl(5, AMDKFD_IOC_WAIT_EVENTS <unfinished ...>
5689 00:08:54.843095 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7fae7ef74c50) = 0 <0.000006>
5689 00:08:54.843114 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7fae7ef74ca0) = 0 <0.000007>
5689 00:08:54.843151 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7fae7ef74ba0) = 0 <0.000006>
5689 00:08:54.843167 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7fae7ef74bf0) = 0 <0.000007>
5689 00:08:54.843220 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7fae7ef74bc0) = 0 <0.000006>
5689 00:08:54.843239 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7fae7ef74c10) = 0 <0.000006>
5689 00:08:54.843279 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7fae7ef74bc0) = 0 <0.000006>
5689 00:08:54.843295 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7fae7ef74c10) = 0 <0.000007>
5684 00:08:54.843339 ioctl(5, AMDKFD_IOC_UNMAP_MEMORY_FROM_GPU, 0x7ffe0edc1f60) = 0 <0.000007>
5684 00:08:54.843355 ioctl(5, AMDKFD_IOC_FREE_MEMORY_OF_GPU, 0x7ffe0edc1fb0) = 0 <0.000008>
runtime arch

参考资料
百度安全验证
AMD的ROCM平台是什么? - 知乎
https://cgmb-rocm-docs.readthedocs.io/_/downloads/en/latest/pdf/
OpenCL编程详细解析与实例 - 知乎
第1章 简介异构计算 - OpenCL 2.0 异构计算 - 开发文档 - 文江博客
HIP-ROCM架构概述 - 知乎
ROCm兼容cuda方案和验证 - 知乎
ROCm API libraries — ROCm Documentation
源码编译安装ROCm以运行tensorflow-rocm(适用于Ubuntu 23.04) - 小蓝博客
AMD 推出 HIP SDK:拓展 ROCm 方案,为 CUDA 应用程序提供支持_腾讯新闻
https://dev.to/shawonashraf/setting-up-your-amd-gpu-for-tensorflow-in-ubuntu-20-04-31f5
GPU memory — ROCm Documentation
Index of /amdgpu-install/
https://www.cnblogs.com/lllzhuang/articles/16083003.html