Cuda elementwise - Add
- 一、简介
- 1.1、ElementWise Add
- 1.2、 float4 - 向量化访存
- 二、实践
- 2.1、如何使用向量化访存
- 2.1、简单的逐点相加核函数
- 2.2、ElementWise Add + float4(向量化访存)
- 2.3、完整代码
一、简介
1.1、ElementWise Add
Element-wise 操作是最基础,最简单的一种核函数的类型,它的计算特点很符合GPU的工作方式:对于每个元素单独做一个算术操作,然后直接输出。
Add 函数 :逐点相加
- 传入 数组 a,b,c
- 传入 数据数量 N
- 传出结果 数组c
1.2、 float4 - 向量化访存
所谓向量化访存,就是一次性读 4 个 float,而不是单单 1 个
要点:
- 小数据规模情况下,可以不考虑向量化访存的优化方式
- 大规模数据情况下,考虑使用向量化访存,且最好是缩小grid的维度为原来的1/4,避免影响Occupancy
- float4 向量化访存只对数据规模大的时候有加速效果,数据规模小的时候没有加速效果
float4的性能提升主要在于访存指令减少了(同样的数据规模,以前需要4条指令,现在只需1/4的指令),指令cache里就能存下更多指令,提高指令cache的命中率。
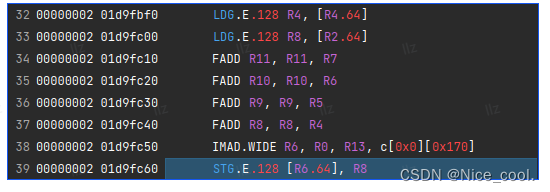
判断是否用上了向量化访存,是在 nsight compute 看生成的SASS代码里会有没有LDG.E.128 Rx, [Rx.64]或STG.E.128 [R6.64], Rx这些指令的存在。有则向量化成功,没有则向量化失败。
官方参考链接1
官方参考链接2
二、实践
2.1、如何使用向量化访存
c :
#define FLOAT4(value) *(float4*)(&(value))
宏解释:
对于一个值,先对他取地址,然后再把这个地址解释成 float4
对于这个 float4的指针,对它再取一个值
这样编译器就可以一次读四个 float
c++ :
#define FLOAT4(value) (reinterpret_cast<float4*>(&(value))[0])
2.1、简单的逐点相加核函数
__global__ void elementwise_add(float* a, float* b, float* c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) c[idx] = a[idx] + b[idx];
}
2.2、ElementWise Add + float4(向量化访存)
__global__ void elementwise_add_float4(float* a, float* b, float *c, int N)
{
int idx = (blockDim.x * blockIdx.x + threadIdx.x) * 4;
if(idx < N ){
float4 tmp_a = FLOAT4(a[idx]);
float4 tmp_b = FLOAT4(b[idx]);
float4 tmp_c;
tmp_c.x = tmp_a.x + tmp_b.x;
tmp_c.y = tmp_a.y + tmp_b.y;
tmp_c.z = tmp_a.z + tmp_b.z;
tmp_c.w = tmp_a.w + tmp_b.w;
FLOAT4(c[idx]) = tmp_c;
}
}
将核函数写成 float4 的形式的时候,首先要先使用宏定义(参考1.3),其次要注意线程数的变化。
线程数变化原因:因为一个线程可以处理4个float了,所以要减少 四倍的线程。
2.3、完整代码
elementwise_add.cu
#include <stdio.h>
#include <stdlib.h>
#include <float.h>
#include <vector>
#include<assert.h>
#include <algorithm>
#include <cublas_v2.h>
#include <cuda_runtime.h>
#define FLOAT4(value) *(float4*)(&(value))
#define checkCudaErrors(func) \
{ \
cudaError_t e = (func); \
if(e != cudaSuccess) \
printf ("%s %d CUDA: %s\n", __FILE__, __LINE__, cudaGetErrorString(e)); \
}
// ElementWise Add
// elementwise_add<<<CeilDiv(N, block_size), block_size>>>(d_A, d_B, d_C, N);
// a: Nx1, b: Nx1, c: Nx1, c = elementwise_add(a, b)
__global__ void elementwise_add(float* a, float* b, float* c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) c[idx] = a[idx] + b[idx];
}
__global__ void elementwise_add_float4(float* a, float* b, float *c, int N)
{
int idx = (blockDim.x * blockIdx.x + threadIdx.x) * 4;
if(idx < N ){
float4 tmp_a = FLOAT4(a[idx]);
float4 tmp_b = FLOAT4(b[idx]);
float4 tmp_c;
tmp_c.x = tmp_a.x + tmp_b.x;
tmp_c.y = tmp_a.y + tmp_b.y;
tmp_c.z = tmp_a.z + tmp_b.z;
tmp_c.w = tmp_a.w + tmp_b.w;
FLOAT4(c[idx]) = tmp_c;
}
}
template <typename T>
inline T CeilDiv(const T& a, const T& b) {
return (a + b - 1) / b;
}
int main(){
size_t block_size = 128;
size_t N = 32 * 1024 * 1024;
size_t bytes_A = sizeof(float) * N;
size_t bytes_B = sizeof(float) * N;
size_t bytes_C = sizeof(float) * N;
float* h_A = (float*)malloc(bytes_A);
float* h_B = (float*)malloc(bytes_B);
float* h_C = (float*)malloc(bytes_C);
for( int i = 0; i < N; i++ ){
h_A[i] = i / 666;
}
for( int i = 0; i < N; i++ ) {
h_B[i] = i % 666;
}
float* d_A;
float* d_B;
float* d_C;
checkCudaErrors(cudaMalloc(&d_A, bytes_A));
checkCudaErrors(cudaMalloc(&d_B, bytes_B));
checkCudaErrors(cudaMalloc(&d_C, bytes_C));
checkCudaErrors(cudaMemcpy( d_A, h_A, bytes_A, cudaMemcpyHostToDevice));
checkCudaErrors(cudaMemcpy( d_B, h_B, bytes_B, cudaMemcpyHostToDevice));
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
float msec = 0;
int iteration = 1;
checkCudaErrors(cudaEventRecord(start));
for(int i = 0; i < iteration; i++)
{
elementwise_add<<<CeilDiv(N, block_size), block_size>>>(d_A, d_B, d_C, N);
//elementwise_add_float4<<<CeilDiv(N, block_size), block_size/4>>>(d_A, d_B, d_C, N);
//elementwise_add_float4<<<CeilDiv(N/4, block_size), block_size>>>(d_A, d_B, d_C, N);
}
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&msec, start, stop));
printf("elementwise add takes %.5f msec\n", msec/iteration);
checkCudaErrors(cudaMemcpy(h_C, d_C, bytes_C, cudaMemcpyDeviceToHost));
for(int i = 0; i < N; i++){
double err = fabs(h_C[i] - (h_A[i] + h_B[i]));
if(err > 1.e-6) {
printf("wrong answer!\n");
break;
}
}
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}
编译和运行:
nvcc -o elementwise_add elementwise_add.cu
./elementwise_add





![[机器视觉]halcon应用实例 边缘检测](https://img-blog.csdnimg.cn/direct/d4a9c60c66eb40c196b22e1aa24eaacb.png)