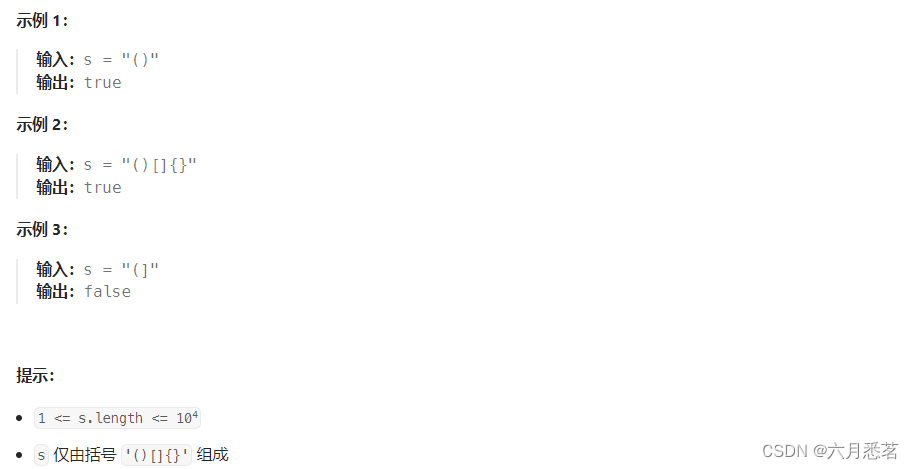全网公开的大模型评测数据集整理。

开源大模型评测排行榜
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
其数据是由其后端lm-evaluation-harness平台提供。
数据集
英文测试
MMLU
https://paperswithcode.com/dataset/mmlu
MMLU(大规模多任务语言理解)是一种新的基准测试,旨在通过仅在零样本和少样本设置中评估模型来衡量预训练期间获得的知识。这使得基准更具挑战性,并且更类似于我们评估人类的方式。该基准涵盖 STEM、人文、社会科学等领域的 57 个学科。它的难度从初级到高级专业水平不等,它既考验世界知识,也考验解决问题的能力。科目范围从数学和历史等传统领域到法律和伦理学等更专业的领域。主题的粒度和广度使基准测试成为识别模型盲点的理想选择。
MMLU 是一个包含了 57 个子任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,有效地衡量了人文、社科和理工等多个大类的综合知识能力。
GSM8K
https://github.com/OFA-Sys/gsm8k-ScRel
https://huggingface.co/datasets/gsm8k
GSM8K(小学数学 8K)是一个包含 8.5K 高质量语言多样化小学数学单词问题的数据集。创建该数据集是为了支持对需要多步骤推理的基本数学问题进行问答的任务。
GSM8K 是一个高质量的英文小学数学问题测试集,包含 7.5K 训练数据和 1K 测试数据。这些问题通常需要 2-8 步才能解决,有效评估了数学与逻辑能力。
winogrande
https://github.com/allenai/winogrande
https://huggingface.co/datasets/winogrande
WinoGrande 是 44k 问题的新集合,受 Winograd Schema Challenge(Levesque、Davis 和 Morgenstern 2011)的启发,进行了调整以提高针对数据集特定偏差的规模和鲁棒性。表述为带有二元选项的填空任务,目标是为需要常识推理的给定句子选择正确的选项。
MATH
https://github.com/hendrycks/math
MATH 是一个由数学竞赛问题组成的评测集,由 AMC 10、AMC 12 和 AIME 等组成,包含 7.5K 训练数据和 5K 测试数据。
HumanEval
HumanEval 是由 OpenAI 发布的 164 个手写的编程问题,包括模型语言理解、推理、算法和简单数学等任务
BBH
https://huggingface.co/datasets/lukaemon/bbh
布尔类型的表达式推理判断
MBPP
https://huggingface.co/datasets/mbpp
该基准测试由大约 1,000 个众包 Python 编程问题组成,旨在由入门级程序员解决,涵盖编程基础知识、标准库功能等。每个问题都由任务描述、代码解决方案和 3 个自动化测试用例组成。
AI2 ARC
https://huggingface.co/datasets/ai2_arc
一个由7,787个真正的小学水平的多项选择科学问题组成的新数据集,旨在鼓励对高级问答的研究。数据集分为挑战集和简单集,其中前者仅包含由基于检索的算法和单词共现算法错误回答的问题。我们还包括一个包含超过 1400 万个与该任务相关的科学句子的语料库,以及该数据集的三个神经基线模型的实现。我们将ARC视为对社区的挑战。
中文测试
C-Eval
中文数据集:https://cevalbenchmark.com/
使用教程:https://github.com/hkust-nlp/ceval/blob/main/README_zh.md
C-Eval是一个全面的中文基础模型评测数据集,它包含了 13948 个多项选择题,涵盖了 52 个学科和四个难度级别。
通常你可以直接从模型的生成中使用正则表达式提取出答案选项(A,B,C,D)。在少样本测试中,模型通常会遵循少样本给出的固定格式,所以提取答案很简单。然而有时候,特别是零样本测试和面对没有做过指令微调的模型时,模型可能无法很好的理解指令,甚至有时不会回答问题。这种情况下我们推荐直接计算下一个预测token等于"A", “B”, “C”, "D"的概率,然后以概率最大的选项作为答案 – 这是一种受限解码生成的方法,MMLU的官方测试代码中是使用了这种方法进行测试。注意这种概率方法对思维链的测试不适用。更加详细的评测教程。
CMMLU
https://github.com/haonan-li/CMMLU
CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。
涉及一些不是常见标准化考试类型的题目,例如食物,中国驾驶规范等。
CMMLU 是一个包含了 67 个主题的中文评测数据集,涉及自然科学、社会科学、工程、人文、以及常识等,有效地评估了大模型在中文知识储备和语言理解上的能力。
SuperCLUE
https://github.com/CLUEbenchmark/SuperCLUE
SuperCLUE是一个综合性大模型评测基准,本次评测主要聚焦于大模型的四个能力象限,包括语言理解与生成、专业技能与知识、Agent智能体和安全性,进而细化为12项基础能力。
GAOKAO-Bench
https://github.com/OpenLMLab/GAOKAO-Bench
Gaokao 是一个中国高考题目的数据集,旨在直观且高效地测评大模型语言理解能力、逻辑推理能力的测评框架。
收集了2010-2022年全国高考卷的题目,其中包括1781道客观题和1030道主观题,构建起GAOKAO-bench的主要评测数据。同时评测分为两部分,自动化评测的客观题部分和依赖于专家打分的主观题部分,这两部分结果构成了最终的分数,您可以通过构建示例中的脚本快速对一个已部署的大模型进行评测,或者向我们提交您需要评测的模型的主观题预测结果,进行我们人工评分的流水线操作。所有过程的数据和结果都是公开的。
AGIEval
https://github.com/ruixiangcui/AGIEval
AGIEval 是一个用于评估基础模型在标准化考试(如高考、公务员考试、法学院入学考试、数学竞赛和律师资格考试)中表现的数据集。
AGIEval 是一个以人为中心的基准测试,专门用于评估基础模型在与人类认知和解决问题相关的任务中的一般能力。该基准源自 20 项针对普通人类考生的官方、公开和高标准的入学和资格考试,例如普通大学入学考试(例如,中国高考(高考)和美国 SAT)、法学院入学考试、数学竞赛、律师资格考试和国家公务员考试。有关基准测试的完整描述,请参阅我们的论文:AGIEval:评估基础模型的以人为本的基准。
多语言测试
M3Exam
https://github.com/DAMO-NLP-SG/M3Exam
包含 12317 个问题,涵盖从高资源语种例如中文英文,到低资源语种例如斯瓦希里语及爪哇语等9个语言。
一个特点是所有问题均来源是当地的真实人类试题,所以包含了特定的文化背景,要求模型不仅是能理解语言,还需要对背景知识有所掌握。
中文部分也公开了图片类试题,可以测试中文多模态模型。
LongBench
LongBench 是第一个用于对大型语言模型进行双语、多任务、全面评估长文本理解能力的基准测试。
传统NLP数据集
HellaSwag
https://arxiv.org/abs/1905.07830
TruthfulQA
https://arxiv.org/abs/2109.07958
GLUE
https://gluebenchmark.com/
Xtreme
https://sites.research.google/xtreme
多语言
SST2
https://huggingface.co/datasets/sst2
适合情感分析
Embedding数据集
MTEB
https://huggingface.co/blog/mteb
测试平台
lm-evaluation-harness
https://github.com/EleutherAI/lm-evaluation-harness
opencompass
https://github.com/open-compass/opencompass
GitHub 上公开的大模型数据集的链接地址,共计20个:
- funNLP: 中英文敏感词、语言检测、手机号归属地查询、名字推断性别等功能的数据集和模型。
- Chinese-Word-Vectors: 大规模的中文词向量数据集。
- BERT-wwm: 预训练中文BERT模型及其相关数据集。
- Chinese-BERT-wwm: 中文预训练BERT模型及其相关数据集。
- chinese-poetry: 中文古诗词数据集。
- chinese-xlnet: 中文预训练XLNet模型及其相关数据集。
- bert-for-tf2: TensorFlow 2.0版本的BERT预训练模型。
- bert: Google开源的BERT模型及其相关数据集。
- GPT2-chitchat: 模仿微信聊天的中文GPT-2模型。
- Text2SQL: 文本到SQL语句的转换数据集和模型。
- chinese-medical-ner: 中文医学命名实体识别数据集。
- NL2SQL: 自然语言到SQL语句的转换数据集和模型。
- Chinese-Language-Embeddings: 快速文本嵌入的中文预训练模型。
- ChineseNER: 中文命名实体识别数据集。
- pydgraph: Python客户端库,用于与Dgraph数据库进行交互。
- fastHan: 基于LSTM的中文分词、命名实体识别和依存句法分析模型。
- paddlepaddle-cn: PaddlePaddle深度学习框架的中文文档和示例代码。
- Chinese-LSTM-CRF: 使用LSTM-CRF模型进行中文命名实体识别的数据集和模型。
- THUCNews: 头条新闻文本分类数据集。
- spacy: Python自然语言处理工具包。
以下是40个GitHub全网公开的大模型数据集的链接地址:
- funNLP
- OpenCLaP
- GLUE
- GPT2-chitchat
- AICopilot
- The BigBadNLP List
- UnsupervisedQA
- Chinese Chatbot Corpus
- Medical Dialog
- BERT Pretrained Models
- DialogPT
- KoGPT2
- T5
- MegaNLP
- Hugging Face Datasets
- LAMBADA
- F1Span
- SUPERB
- TyDiQA
- PiGAN
- LiuNLP
- XGLUE
- OK-VQA
- DialogRL
- STD-QA
- UnRel
- SENTIMENT-CLASSIFICATION
- 1 Billion Word Benchmark
- GLoSA
- SentEval
- Story Cloze Test
- CoLA
- SNLI
- QQP
- QNLI
- SST-2
- MRC-QA
- WiC
- RTE
- WiC