目录
一、查看查询计划
1.1 概述
1.2 查询计划树
1.3 查看查询计划的命令
1.3 查看查询计划
二、查看查询Profile
2.1 启用 Query Profile
2.2 获取 Query Profile
2.3 Query Profile结构与详细指标
2.3.1 Query Profile的结构
2.3.2 Query Profile的合并策略
2.3.3 Query Profile的详细指标
三、Query Hint
3.1 概述
3.2 系统变量 Hint
3.3 Join Hint
为了优化StarRocks集群性能,需要定期对慢查询进行分析优化,避免慢查询影响整个集群的服务能力。query plan查询计划是FE通过解析sql生成的执行计划,而profile是BE执行查询后的结果,包含了每一步的耗时和数据处理量等数据。
一、查看查询计划
1.1 概述
在StarRocks中,一条sql语句的生命周期可以分为(简化版)为查询解析(query parsing),查询计划(query plan)、执行(query execution)三个阶段。一般而言,查询解析不会成为查询性能的瓶颈,因为分析型需求的qps(“每秒查询率”或“每秒请求数”)不高。所以决定查询性能的关键就在于查询规划(query plan)和查询执行(query execution)。两者关系是:query plan负责组织算子(scan/join/aggregation)之间的关系,query execution负责执行具体算子。
1.2 查询计划树
查询规划器用来决定数据库如何具体执行一个 SQL 的,比如用户指定了一个 Join 算子,则查询规划器需要决定具体的 Join 算法,比如是使用 Shuffle 还是 Broadcast;Join顺序是否需要调整以避免笛卡尔积;以及确定最终的在哪些节点执行等等。
Doris的查询规划器是先将一个 SQL语句转换成一个单机执行计划树,SQL --> PlanNodeTree

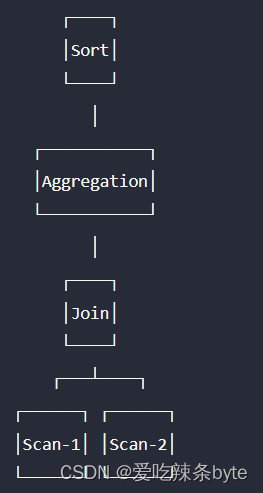
之后,查询规划器会根据具体的算子执行方式、数据的具体分布,将单机查询计划转换为分布式查询计划,即PlanNodeTree --->PlanFragmentTree,分布式查询计划是由多个Plan Fragment 组成的,例如:Plan Fragment 0,Plan Fragment 1,Plan Fragment 2deng 。每个 Fragment 负责查询计划的一部分,各个Fragment之间会通过DataStreamSink和ExchangeNode 算子进行数据的传输。
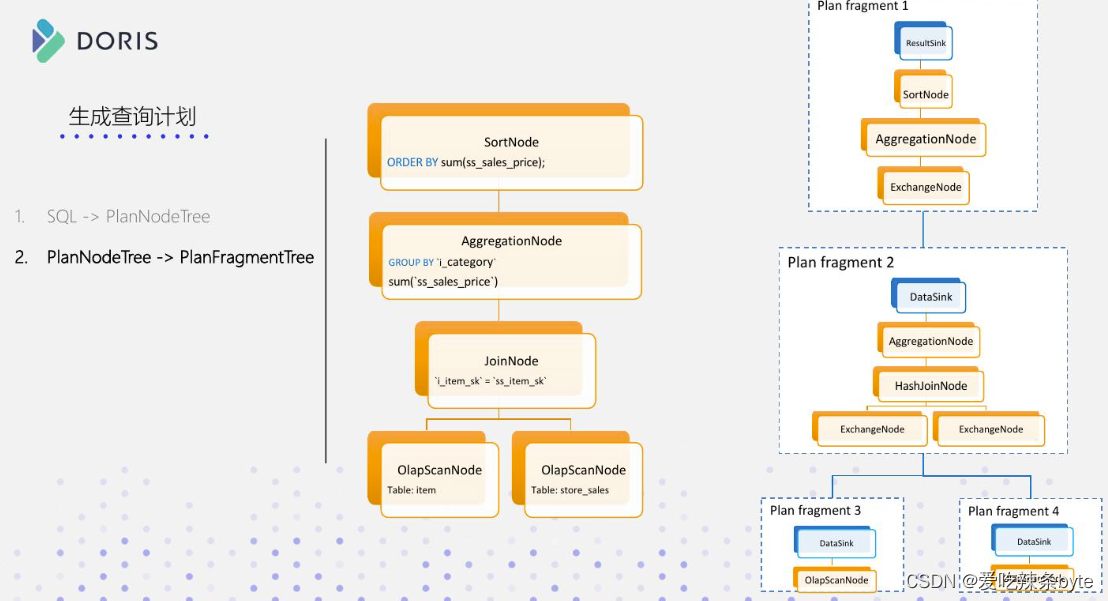


如上图,我们将单机计划分成了两个 Fragment:F1 和 F2。两个 Fragment 之间通过一个 ExchangeNode 节点传输数据。而一个Fragment 会进一步的划分为多个Instance。Instance 是最终具体的执行实例。划分成多个 Instance 有助于充分利用机器资源,提升一个 Fragment 的执行并发度。
1.3 查看查询计划的命令
query plan可以分为逻辑执行计划(logical query plan)和物理执行计划(physical query plan),本文说的query plan默认指代的都是逻辑执行计划。 通过explain sql_statement 命令查看query plan。
ps: Doris中的命令更丰富:查询分析 - Apache Doris
1.3 查看查询计划
来自StarRocks官网案例:分析查询 | StarRocks
查询计划涉及的概念:

以下面这个query plan查询计划为例,进行分析:
mysql> EXPLAIN select count(*)
from store_sales,
household_demographics,
time_dim,
store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
+------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 11> |
| PARTITION: UNPARTITIONED |
| RESULT SINK |
| 12:MERGING-EXCHANGE |
| limit: 100 |
| tuple ids: 5 |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 12 |
| UNPARTITIONED |
| |
| 8:TOP-N |
| | order by: <slot 11> ASC |
| | offset: 0 |
| | limit: 100 |
| | tuple ids: 5 |
| | |
| 7:AGGREGATE (update finalize) |
| | output: count(*) |
| | group by: |
| | tuple ids: 4 |
| | |
| 6:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: left hash join node can not do colocate |
| | equal join conjunct: `ss_store_sk` = `s_store_sk` |
| | tuple ids: 0 2 1 3 |
| | |
| |----11:EXCHANGE |
| | tuple ids: 3 |
| | |
| 4:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: left hash join node can not do colocate |
| | equal join conjunct: `ss_hdemo_sk`=`household_demographics`.`hd_demo_sk`|
| | tuple ids: 0 2 1 |
| | |
| |----10:EXCHANGE |
| | tuple ids: 1 |
| | |
| 2:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: table not in same group |
| | equal join conjunct: `ss_sold_time_sk` = `time_dim`.`t_time_sk` |
| | tuple ids: 0 2 |
| | |
| |----9:EXCHANGE |
| | tuple ids: 2 |
| | |
| 0:OlapScanNode |
| TABLE: store_sales |
| PREAGGREGATION: OFF. Reason: `ss_sold_time_sk` is value column |
| partitions=1/1 |
| rollup: store_sales |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 0 |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 11 |
| UNPARTITIONED |
| |
| 5:OlapScanNode |
| TABLE: store |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `store`.`s_store_name` = 'ese' |
| partitions=1/1 |
| rollup: store |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 3 |
| |
| PLAN FRAGMENT 3 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 10 |
| UNPARTITIONED |
| |
| 3:OlapScanNode |
| TABLE: household_demographics |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `household_demographics`.`hd_dep_count` = 5 |
| partitions=1/1 |
| rollup: household_demographics |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 1 |
| |
| PLAN FRAGMENT 4 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 09 |
| UNPARTITIONED |
| |
| 1:OlapScanNode |
| TABLE: time_dim |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `time_dim`.`t_hour` = 8, `time_dim`.`t_minute` >= 30 |
| partitions=1/1 |
| rollup: time_dim |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 2 |
+------------------------------------------------------------------------------+
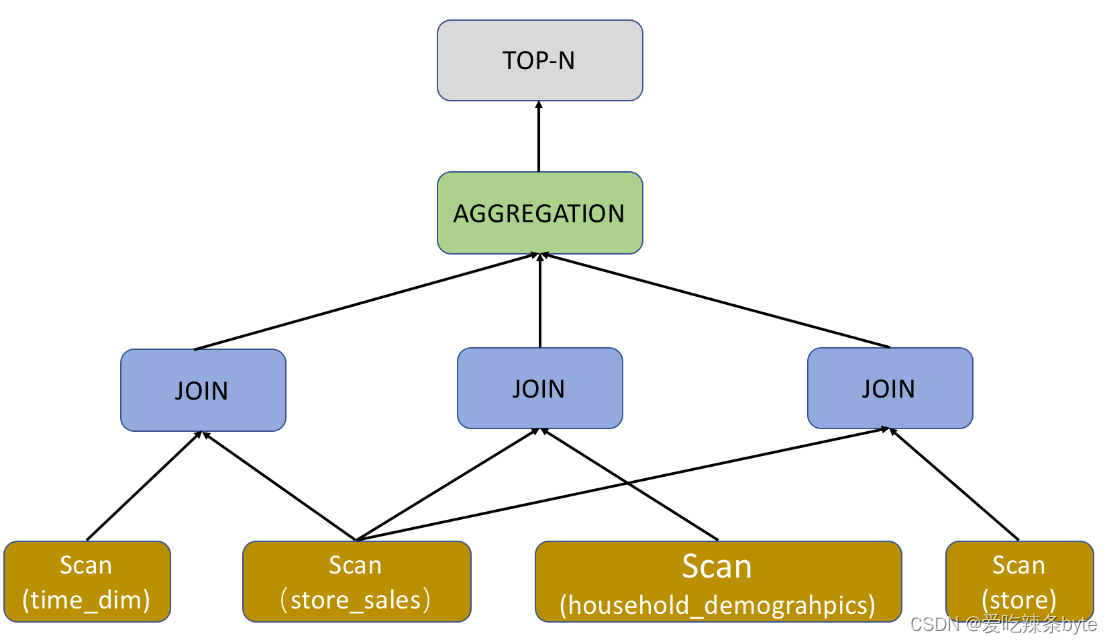
128 rows in set (0.02 sec)解析过程:query plan分为 5 个pan fragment,编号从 0 至4,通过从下至上的方式查看query plan。
step1:最底部的 Plan Fragment 为 Fragment 4,它负责扫描time_dim表,并提前执行相关查询条件 time_dim.t_hour = 8 and time_dim.t_minute >= 30,即谓词下推。这里的time_dim表采用的是聚合表,对于聚合表(Aggregate Key),StarRocks 会根据不同查询选择是否开启预聚合 PREAGGREGATION。以上示例中 time_dim 表的预聚合为关闭状态,此状态之下 StarRocks 会读取 time_dim 的全部维度列,如果当前表包含大量维度列,这可能会成为影响性能的一个关键因素。如果 time_dim 表被设置为根据 Range Partition 进行数据划分(数据分区),Query Plan 中的 partitions 会表征查询命中的分区,无关分区被自动过滤,从而有效减少扫描数据量。如果当前表有物化视图,StarRocks 会根据查询去自动选择物化视图,如果没有物化视图,那么查询自动命中 base table(基表),也就是以上示例中展示的 rollup: time_dim。
step2:当 time_dim 表数据扫描完成之后,Fragment 4 的执行过程也就随之结束,此时它将扫描得到的数据传递给其他 Fragment(各个Fragment之间,通过DataStreamSink和ExchangeNode 算子进行数据的传输)。以上示例 EXCHANGE ID : 09 表征了数据传递给了标号为 9 的接收节点。
Fragment 2,3,4功能类似,只是负责扫描的表不同。而查询中的 Order/Aggregation/Join 算子,都在 Fragment 1 中进行。
step3:Fragment 1 集成了三个 Join 算子的执行,采用默认的 BROADCAST 方式进行执行,也就是小表向大表广播的方式进行。如果两个 Join 的表都是大表,建议采用 SHUFFLE 的方式进行。目前 StarRocks 只支持 HASH JOIN,也就是采用哈希算法进行 Join。以上示例中的 colocate 字段用来表述两张 Join 表采用同样的分区/分桶方式。如果分区/分桶方式相同,Colocate Join 的过程可以直接在本地执行,不用进行数据的移动。Join 执行完成之后,Fragment 1 就会执行上层的 Aggregation、Order by 和 TOP-N 算子。
二、查看查询Profile
2.1 启用 Query Profile
官网文章地址:Query Profile 概述 | StarRocks
Profile 包含了一个sql查询涉及的所有工作节点的执行信息,有助于我们分析查询性能的瓶颈。将变量 enable_profile 设置为 true 以启用 Query Profile:SET enable_profile = true;
2.2 获取 Query Profile
以下步骤获取 Query Profile:
- 在浏览器中访问
http://<fe_ip>:<fe_http_port>。 - 在显示的页面上,单击顶部导航中的 queries。
- 在 Finished Queries 列表中,选择您要分析的查询并单击 Profile 列中的链接。

页面将跳转至相应 Query Profile

2.3 Query Profile结构与详细指标
2.3.1 Query Profile的结构
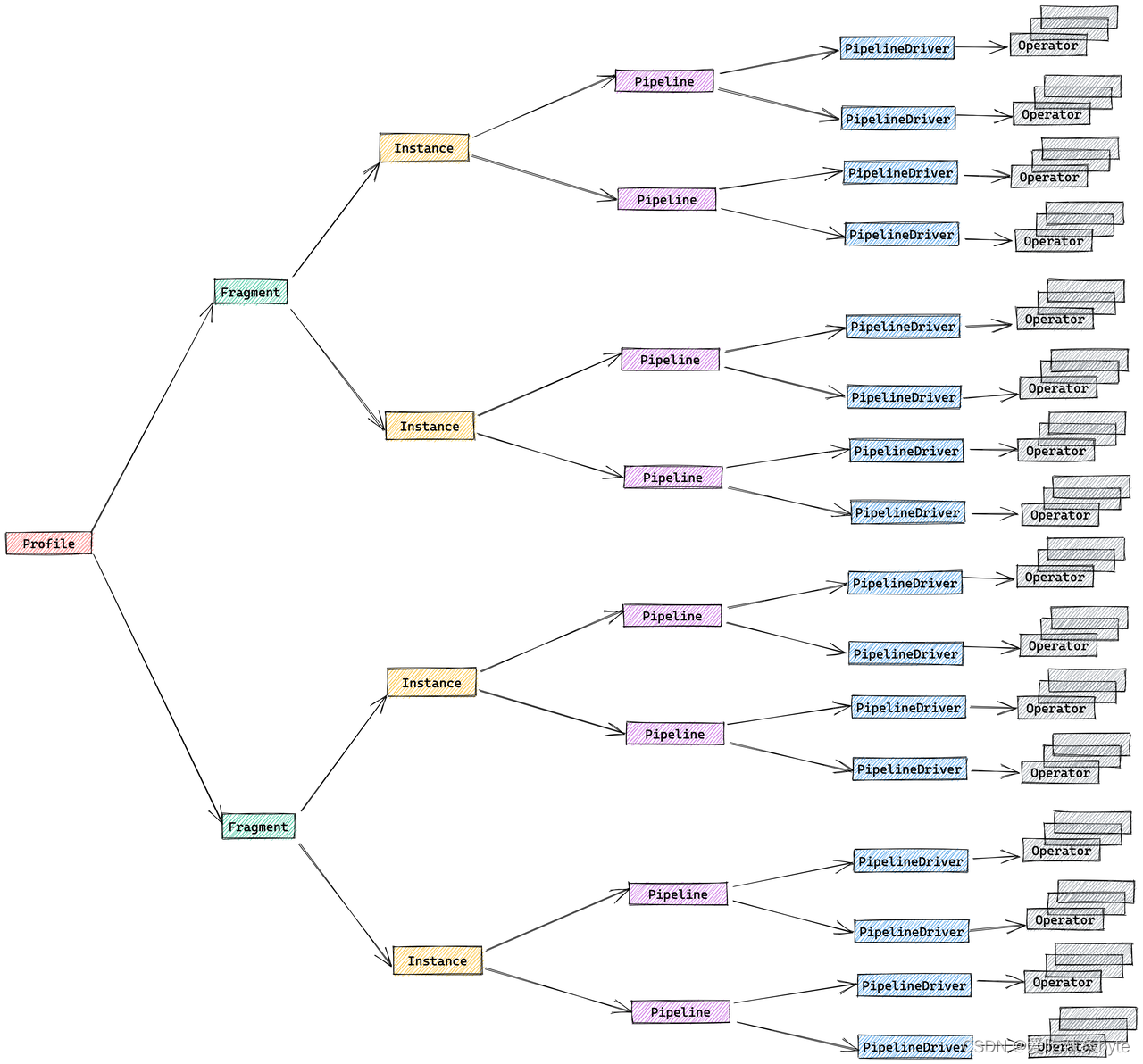
Query Profile 的结构与执行引擎的设计密切相关,由以下五部分组成:
- Fragment:执行树。一个查询由一个或多个Fragment组成
- FragmentInstance:每个Fragment可以有多个实例,每个实例称作FragmentInstance,分别由不同的计算节点来执行
- Pipeline:一个FragmentInstance会被拆分成多个Pipeline,每个Pipeline是一个执行链,由一组首尾相接的 Operator 构成。
- PipelineDriver:一个 Pipeline 可以有多个实例,每个实例称为 PipelineDriver,以充分利用多个计算核心。
- Operator:算子,一个 PipelineDriver 由多个 Operator 组成。
2.3.2 Query Profile的合并策略
同一个Fragment 关联的多个 FragmentInstance 在结构上具有高度相似性。为了减少 Query Profile 的体积,可以将 FragmentInstance 层进行合并,原本的五层结构便简化为三层:
- Fragment:执行树
- Pipeline:执行链
- Operator:算子
通过一个 Session变量 pipeline_profile_level 来控制这个合并行为,其可选值有2个:
1:合并,即三层结构。默认值。2:不合并,即保留原始的五层结构。- 其他任何数值都会被当成默认值
1。
通常没有必要调整这个参数,就采取默认值1
2.3.3 Query Profile的详细指标
太多了,看官网:Query Profile 结构与详细指标 | StarRocks
三、Query Hint
3.1 概述
Hint是一种指令或注释,显式地向查询优化器建议如何执行查询,Hint 仅在单个查询范围内生效。 StarRocks 目前支持两种 Hint:系统变量 Hint 和 Join Hint
3.2 系统变量 Hint
在 selec等语句中通过 /*+ ... */ 注释的形式设置一个或多个系统变量 hint。其他语句中如果包含 select 子句(如创建物化视图create materialized view as select,创建视图create view as select),则也可以在该 select 子句中使用系统变量 hint。
select [/*+ set_var(key=value [, key = value]*) */] ...
#创建物化视图时在 SELECT 子句中通过系统变量 query_timeout 来设置查询执行超时时间。
create materialized view mv
partition by dt
distributed by hash(`key`)
buckets 10
refresh async
as select /*+ set_var(query_timeout=500) */ * from dual;
3.3 Join Hint
针对多表关联查询,优化器一般会主动选择最优的 Join 执行方式(Join Reorder)。在特殊情况下,用户使用 Join Hint显式地指定Join 执行方式。目前 Join Hint 支持的Join执行方式有Broadcast Join、Shuffle Join、Bucket Shuffle Join 和 Colocate Join。
当Join Hint指定Colocate Join或 Bucket Shuffle Join 时,需要确保表的数据分布情况满足这两种 Join 执行方式的要求,否则用户指定的Join执行方式不生效。
#语法
... join { [broadcast] | [shuffle] | [bucket] | [colocate] | [unreorder]} ...
#说明:使用 Join Hint 时大小写不敏感。
举例:
- Shuffle Join
如果需要将表 A、B 中分桶键取值相同的数据行 Shuffle 到相同机器上,再进行 Join 操作,您可以设置 Join Hint 为 Shuffle Join。
select k1 from t1 join [SHUFFLE] t2 on t1.k1 = t2.k2 group by t2.k2;- Broadcast Join
如果表 A 是个大表,表 B 是个小表,则可以设置 Join Hint 为 Broadcast Join。表 B 的数据全量广播到表 A 数据所在的机器上,再进行 Join 操作。Broadcast Join 相比较于 Shuffle Join,节省了 Shuffle 表 A 数据的开销。
select k1 from t1 join [broadcast] t2 on t1.k1 = t2.k2 group by t2.k2;- Bucket Shuffle Join
如果关联查询中 Join 命中表 A 的分桶键 ,且表 A 和表 B 均是大表的情况下,可以设置 Join Hint 为 Bucket Shuffle Join。表 B 数据会按照表 A 数据的分布方式,Shuffle 到表 A 数据所在机器上,再进行 Join 操作。Bucket Shuffle Join 是在 Broadcast Join 的基础上进一步优化,Shuffle B 表的数据量全局只有一份,比 Broadcast Join 少传输了很多倍数据量。
select k1 from t1 join [bucket] t2 on t1.k1 = t2.k2 group by t2.k2;- Colocate Join
如果建表时指定表A 和 B属于同一个 Colocation Group,则表 A 和表 B 分桶键取值相同的数据行一定分布在相同 BE 节点上。当关联查询中 Join命中表 A 和 B 的分桶键,可以设置 Join Hint 为 Colocate Join。 具有相同键值的数据直接在本地 Join,减少数据在节点间的传输耗时,从而提高查询性能。
select k1 from t1 join [colocate] t2 on t1.k1 = t2.k2 group by t2.k2;通过explain命令来查看 Join Hint 是否生效。如果返回结果所显示的 Join 执行方式符合 Join Hint,则表示 Join Hint 生效。
explain select k1 from t1 join [colocate] t2 on t1.k1 = t2.k2 group by t2.k2;参考文章:
StarRocks技术内幕:查询原理浅析
【源码解析系列】 Apache Doris 查询源码解析
Doris的查询计划-腾讯云开发者社区-腾讯云
分析查询 | StarRocks





![[嵌入式系统-35]:RT-Thread -20- 新手指南:在Keil MDK-ARM 模拟器上运行RT-Thread](https://img-blog.csdnimg.cn/direct/bf8758996db74b75838b7d218de5bb8b.png)




