文章目录
- 前言
- 模型概念
- 模型是什么?
- 模型参数有哪些
- 神经网络参数案例
- 为什么要生成模型
- 模型的大小
- 什么是大模型
- 模型的训练和推理
- 模型训练
- 训练概念
- 训练过程
- 训练过程中的一些概念
- 模型推理
- 推理概念
- 推理过程
- 总结
前言
自定义神经网络一之Tensor和神经网络
通过上一篇文章,我们大概了解了神经网络以及常见的神经网络结构和应用场景。但是在日常与算法同学打交道中,基本都是算法同学提供模型,工程化同学进行推理获取结果。
那么模型是什么,怎么产生的模型,模型训练和推理又是干嘛的呢?下面我们一一道来。
模型概念
模型是什么?
一个模型通常是一个构建好的并通过数据训练过的神经网络。它会保存学习到的特征和模式,用来对新的数据进行预测或者解决特定的问题。
通常,一个神经网络模型主要包含两部分:结构(Architecture) 和 权重(Weights)。
- 结构:这部分定义了模型的各个层及其连接方式。比如有多少层,每一层有多少个节点,每一层用的是什么类型的激活函数等等。这个结构是设计模型时预先定义好的。
- 权重:在模型的训练过程中,模型会学习到一些权重和偏置,这些都存储在权重中。这些权重和偏置就是模型从数据中学到的规律和知识,用来进行预测的。
模型参数有哪些
参考:深度学习之参数初始化
参数是模型所需要学习的一部分,通常被认为是模型的"知识"。这些参数处理输入数据,帮助模型做出预测。
以最常见的深度学习模型——神经网络为例,它的参数主要包括权重和偏置。
- 权重(Weights):权重决定了每一个输入特征对最终输出预测的影响程度。例如,在多层感知器(MLP)中,每一个输入节点和隐藏节点之间都有一个权重,该权重决定了输入值被乘以多少然后送入下一层节点。
- 偏置(Biases):偏置是用来调节神经元的激活阈值。可以看作是当所有的输入特征都为0时模型的预测值。如果没有偏置,神经元的输出就只是输入的加权和,当输入都是0时,输出也会是0。有了偏置之后,即使所有输入都是0,神经元还是有可能被激活。
- 公式: Y = W1 * X1 + W2 * X2 + b
- 两个输入节点(X1,X2),和一个输出节点(Y)
- W1和W2就是权重,分别定义了X1和X2对Y的贡献。
- b就是偏置
在神经网络中,我们使用张量来表示权重和偏置。每一层的权重可以用一个二维的张量来表示,其中行表示输入节点的数量,列表示输出节点的数量。偏置则是一个一维的张量,长度等于输出节点的数量。
神经网络参数案例
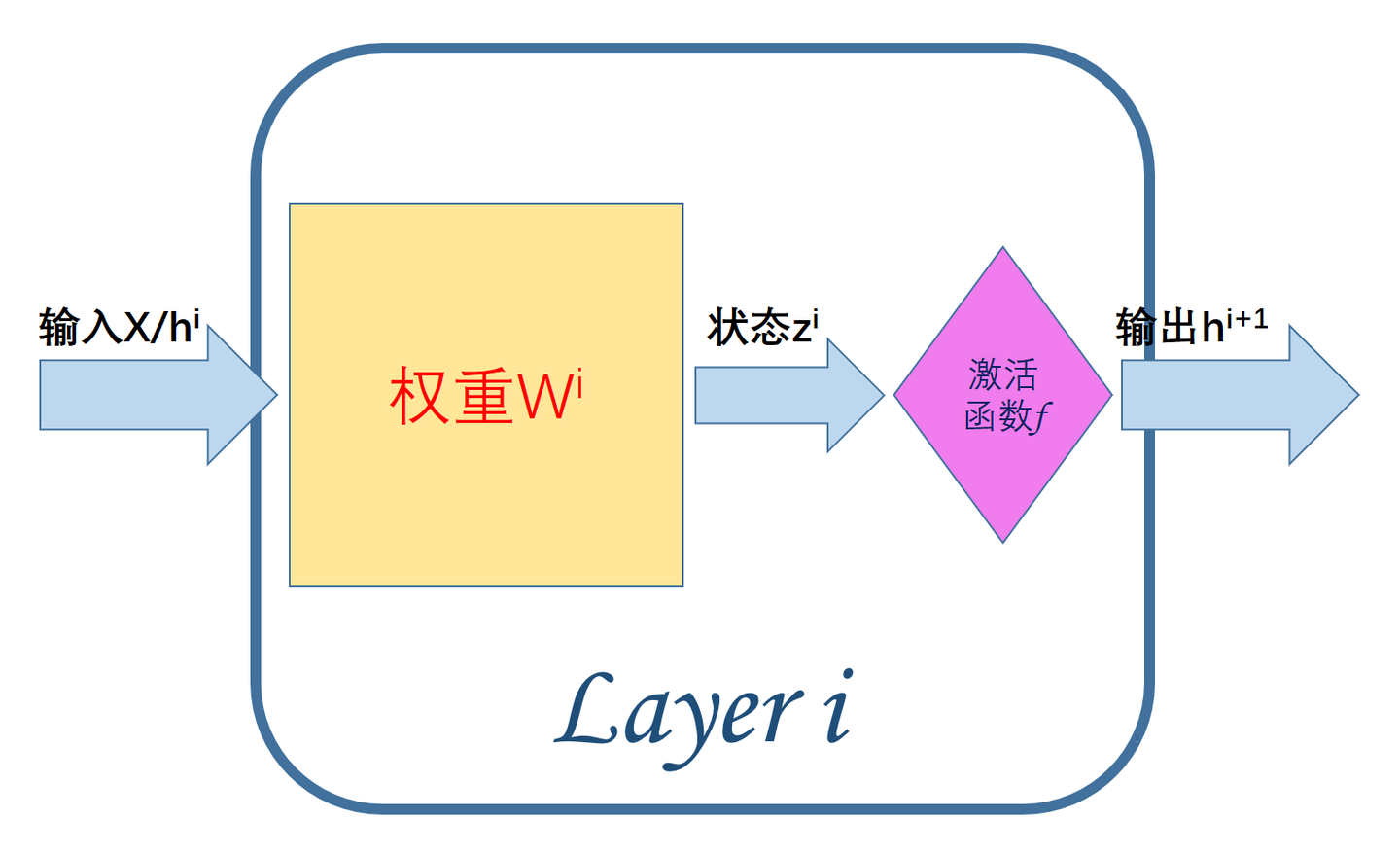
由图可知,每一个层内部的组成主要有:
输入X/hi:来自原始样本X的输入(i=0)或上一层(第i−1层)的输出hi。
权重W:网络模型训练的主体对象,第ii层的权重参数wi。
状态值z:作为每一层激活函数f的输入,处于网络层的内部,所以称之为状态值。
激活值h:状态值zi经过了激活函数f后的输出,也就是第i层的最终输出hi;
为什么要生成模型
训练结束之后,我们可以直接使用训练好的神经网络进行推理,但是这样的话不具备移植性,程序运行结束没有存档。
我们可以保存成模型的方式,然后通过解析模型去进行推理,这样的模型是具备移植性的。而且相当于保留了训练成果,可以继续在这个模型上进行进一步的训练。
模型的保存通常包括两部分:
模型的结构和模型的权重。模型的结构保存了神经网络的架构(例如,各个层的类型,层的数量,每层的节点数等),而模型的权重保存了训练过程中学到的模型参数。
在Python的深度学习框架(如TensorFlow, PyTorch)中,“保存”模型通常意味着将模型的结构和权重序列化为二进制格式,并写入磁盘。对于TensorFlow和Keras,保存的模型通常是.h5或.ckpt(Checkpoint)格式的文件;对于PyTorch,保存的模型通常是.pt或.pth格式的文件。
模型的大小
参考:大模型(Large Model)常识综述(三)
这里要区分模型的磁盘大小和训练参数大小的区别。比如现在的大模型,训练参数可能是7b,13b,70b等,这里的b的单位是亿,比如7b代表7亿参数。
而模型的磁盘大小是指神经网络训练结束,保存为模型文件的大小。例如7b的llama2磁盘大小是3.8G, 13b的llama2磁盘大小是7.4G
我们自定义的神经网络,2层神经网络+单个权重参数,保存模型大小为40k左右。
什么是大模型
**大模型是指具有大规模参数和复杂计算结构的机器学习模型。**这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。
小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
而当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,其表现出了一些未能预测的、更复杂的能力和特性,模型能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,这种能力被称为“涌现能力”。而具备涌现能力的机器学习模型就被认为是独立意义上的大模型,这也是其和小模型最大意义上的区别。
模型的训练和推理
机器学习模型的训练和推理是一个基于数据的反馈循环过程。
训练过程是模型学习数据的过程,而推理过程是使用已训练好的模型进行预测或分类的过程。
模型训练
训练概念
一个初始神经网络通过不断的优化自身参数,来让自己变得准确。这整个过程就称之为训练(Training)
训练过程
- 数据准备:选择和收集相应的数据集,对数据进行清洗、标注、特征提取等预处理操作,以便让数据适合模型的输入。
- 模型选择和定义:根据问题的需求,选择合适的模型架构,比如神经网络、决策树等,并定义模型的结构、参数和超参数。
- 模型初始化:对模型参数进行初始化操作,这样可以让模型开始训练时具有一定的初始能力。
- 前向传播:将数据输入模型,通过模型的每一层计算,从输入层到输出层的过程称为前向传播。在前向传播过程中,模型会依次计算每一层的输出,并在最后一层产生预测结果。
- 激活函数:每个神经元接收到输入后对其加权求和,然后传递给激活函数,根据激活函数的结果确定神经元的输出。
- 计算损失函数:将模型预测的结果与真实标签进行比较,计算模型的误差。常用的损失函数有平方损失、交叉熵损失等。
- 反向传播:根据损失函数的值,通过反向传播算法计算模型中各个参数的梯度。梯度是损失函数对参数的变化率,反向传播的目的是根据模型对样本的预测误差来调整模型参数,使得预测结果更加准确。
- 参数更新:利用优化算法(如梯度下降算法)根据梯度信息对模型参数进行更新。更新参数的过程会降低模型在当前任务上的训练误差。
- 重复迭代:通过重复执行前面的步骤,不断训练模型,直到模型的性能达到预期或收敛。
训练过程中的一些概念
正向传播: 输入信号从输入层经过各个隐藏层向输出层传播。在输出层得到实际的响应值,若实际值与期望值误差较大,就会转入误差反向传播阶段。
反向传播: 按照梯度下降的方法从输出层经过各个隐含层并逐层不断地调整各神经元的连接权值和阈值,反复迭代,直到网络输出的误差减少到可以接受的程度,或者进行到预先设定的学习次数。
代(Epoch): 使用训练集的全部数据对模型进行一次完整训练,被称为“一代训练”。
批大小(Batch size): 使用训练集的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据”
迭代(Iteration): 使用一个Batch数据对模型进行一次参数更新的过程,被称为“一次训练”(一次迭代)。每一次迭代得到的结果都会被作为下一次迭代的初始值。一个迭代=一个正向通过+一个反向通过。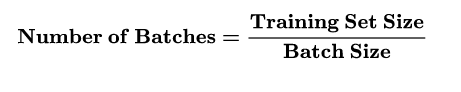
比如训练集有500个样本,batchsize = 10 ,那么训练完整个样本集:iteration=50,epoch=1.
模型推理
推理概念
你训练好了一个模型,在训练数据集中表现良好,但是我们的期望是它可以对以前没看过的图片进行识别。你重新拍一张图片扔进网络让网络做判断,这种图片就叫做现场数据(livedata),如果现场数据的区分准确率非常高,那么证明你的网络训练的是非常好的。这个过程,称为推理(Inference)。
推理过程
- 数据准备:与训练过程相似,对输入数据进行预处理和特征提取。
2. 模型加载:将训练好的模型加载到内存中,准备进行推理。
3. 前向传播:将处理后的数据输入模型,并通过前向传播计算得到输出结果。
4. 输出解释:针对输出结果进行解释和处理,根据具体的问题进行分类、回归、预测等。
5. 结果反馈:将输出结果反馈给用户或其他系统,完成推理过程。
需要注意的是,训练过程通常需要大量的数据和计算资源来完成,而推理过程相对较快,因为训练过程中大部分的计算已经在模型参数更新时完成了。
总结
本篇博客主要介绍了神经网络中模型的相关概念以及模型的训练和推理过程。整体来说更偏概念性,特别是训练和推理部分。后续我们会在自定义神经网络部分详细解释训练和推理在代码上的表示。
end






![[02 git ] 清华大学电子系科协软件部2023暑期培训](https://img-blog.csdnimg.cn/direct/f572f750c14c4764a61cf260d2c81e33.png)