文章目录
- 1 掩码的两个功能
- 1.1 功能1 输入掩码,统一长度
- 1.2 功能2 遮挡未预测信息
- 2 掩码存在的三个位置
- 3 代码实现
Transformer的掩码机制是非常重要的
三个位置,两个功能
1 掩码的两个功能
1.1 功能1 输入掩码,统一长度
实现不同的长度句子同时训练,统一长度,计算注意力机制的时候方便并行计算
假设训练中最长的句子为10个tokens
那么这两句话
“我喜欢猫猫“
“我喜欢打羽毛球”
在不足十个token的情况下,填充pad直到10个,这样可以使得所有序列的长度保持一致都是十个
那么问题来了,模型怎么知道哪些是pad,哪些是真正的token
就通过掩码机制,两个句子的掩码分别为
(0,0,0,0,0,1,1,1,1,1)
(0,0,0,0,0,0,0,1,1,1)
这时候模型对1的位置进行替换处理,使得最后对于计算结果没有影响
具体代码实现中,你会发现在encoder和decoder两个重要组件中里都有padding mask,位置是在softmax之前,
我们在这些位置上补一些无穷小(负无穷)的值,经过softmax操作,这些值就成了0,就不在影响全局概率的预测。
padding的另一种解释,我觉得也不错,放在这里供大家参考
一句文本输入:[1, 2, 3, 4, 5]
input size: 1* 8
加padding:[1, 2, 3, 4, 5, 0, 0, 0]
padding 引入的问题:padding填充数量不一致,导致均值计算偏离
原始均值:(1 + 2 + 3 + 4 + 5) / 5 = 3
padding后的均值: (1 + 2 + 3 + 4 + 5) / 8 = 1.875
引入mask,解决padding的缺陷:
1.2 功能2 遮挡未预测信息
在解码器部分,我们在模型训练的过程中不能让模型知道未来时间步的信息,否则话就相当于告诉了模型最终的答案是什么。
什么意思呢,比如对于翻译任务
我们的编码器输入的是源语言的完整信息,最终编码一个特征memory给到解码器,比如“我喜欢可爱的猫猫”
那么解码器输入的是来自编码器的编码后的整体特征memory还有目标语言的已经预测的信息,比如“I like cute cats”
对于cute这一个词的预测就要给模型memory和I 和 like这两个token的信息
对于cats 这一个词的预测就要给模型memory和I 和 like和 cute 这三个token的信息
那么对于未预测的信息不能提前给模型看~
那么现在问题来了,看样子我们需要模型一个词一个词的预测,那这样多慢啊,这不是有点循环神经网络的意思了吗,但是我在这篇博客手撕Transformer(一)| 经典Positional_encoding 用法and代码详解-CSDN博客里面讲到,深度学习一定要有矩阵思维,这里的训练过本质上也是这个过程,通过矩阵使得这些词的预测同步进行,怎么做到的?这一点非常重要,要充分理解
Transformer不是一个词一个词预测的。他是一批都一次性预测,然后每一个和之后的进行比较~矩阵的并行计算
1用编码器的输出memory结合第1 个token预测第二个tokens( 第二步)
2用编码器的输出memory结合第1,2 个token预测第三个token( 第三步)
3用编码器的输出memory结合第1,2,3 个token 预测第四个token (第四步)
以此类推
以上这些是同时进行的,就是通过掩码机制
我们最终会生成这样一个矩阵
[0,1,1
0,0,1
0,0,0 ]
第一行代表模型最终只能看到第一个token,此时第二个和第三个都看不到,这时预测第二个
第二行代表模型最终只能看到第一,二个token,此时第三个看不到,这时预测第三个
依此类推
2 掩码存在的三个位置
存在于三个位置
位置1,2的实现的功能一,位置3实现的功能2
但位置1,2 虽然功能差不多,但输入有差别,因为位置1实现的是自注意力,位置2是交叉注意力
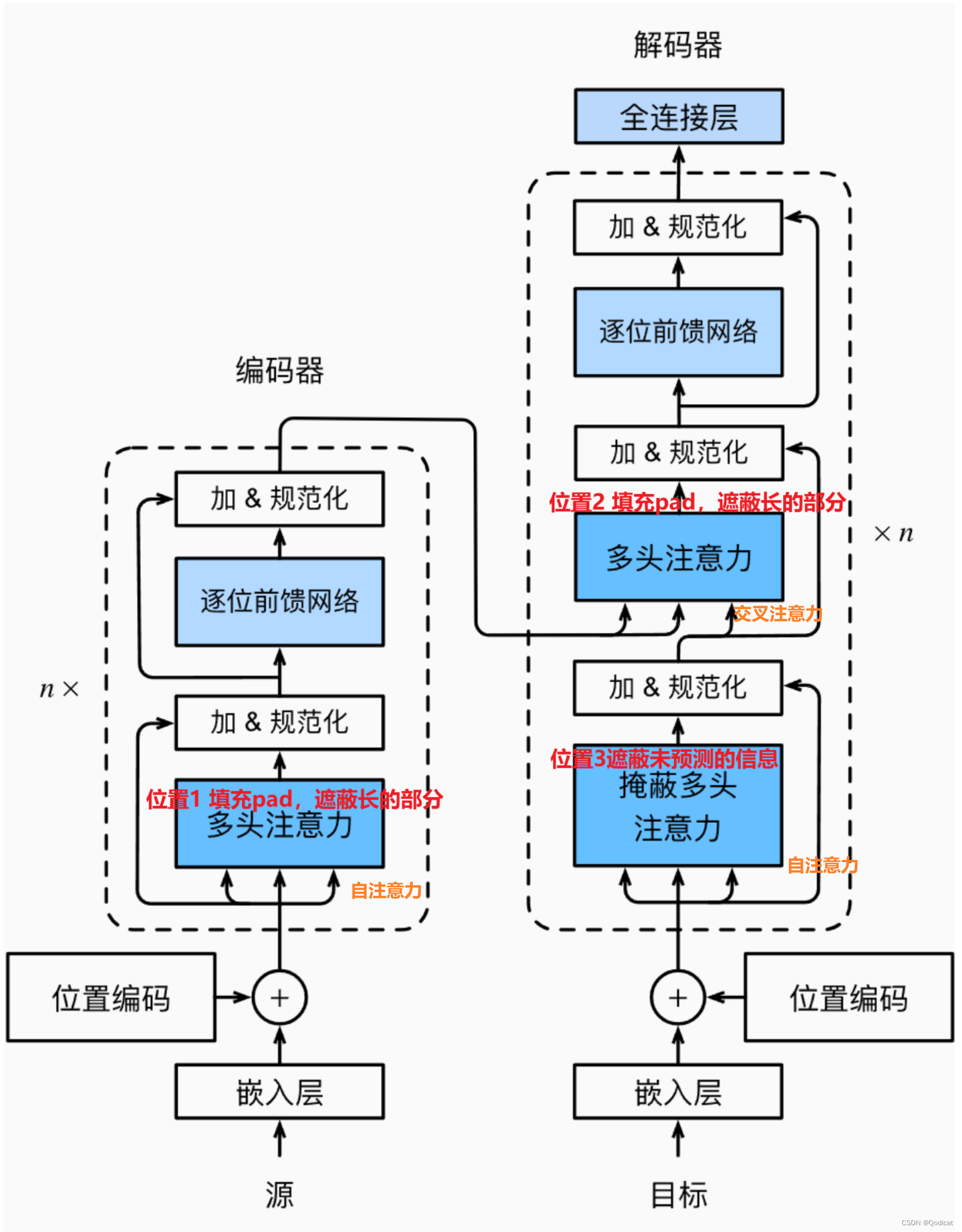
或者可以理解为什么,最后对最后的Q,K乘积的注意力矩阵的遮蔽,为0的部分计算注意力,为1的部分不计算
3 代码实现
要理解这部分的代码可以核心看
【深度学习】Transformer中的mask机制超详细讲解_transformer mask-CSDN博客
分别介绍了三个位置的代码的实现,每个位置介绍了两种代码实现的方法
我觉得原作者写的非常好,我就不重复造轮子了,如果之后有时间基于他的我会进一步完善
参考
[transformer掩码-CSDN博客](https://blog.csdn.net/Arctic_Beacon/article/details/122416407#:~:text=transformer掩码 1 一、padding mask 数据输入模型的时候长短不一,为了保持输入一致,通过加padding将input转成固定tensor。 一句文本输入: [1%2C 2%2C,scaled_dot_product_attention ( q%2C k%2C v%2C mask )%3A )
4.4 Transformer编码器部分实现–掩码张量 - 知乎 (zhihu.com)
图片基于李沐老师的动手深度学习进行标记