实验目的
1.使用python将爬虫数据存入mongodb;
2.使用python读取mongodb数据并进行可视化分析。
实验原理
MongoDB是文档数据库,采用BSON的结构来存储数据。在文档中可嵌套其他文档类型,使得MongoDB具有很强的数据描述能力。本节案例使用的数据为链家的租房信息,源数据来自于链家网站,所以首先要获取网页数据并解析出本案例所需要的房源信息,然后将解析后的数据存储到MongoDB中,最后基于这些数据进行城市租房信息的查询和聚合分析等。
实验环境
OS:Windows 10
Python3
MongoDB:v4.4
实验步骤
一、使用python将爬虫数据存入mongodb
1.爬取数据
分析租房信息首先要获取原始的二手房房源数据,本例使用python爬虫技术获取链家网页的二手房楼盘信息。如图所示,对房源信息进行分析需要获取房源所在区域、小区名、房型、面积、具体位置、价格等信息。
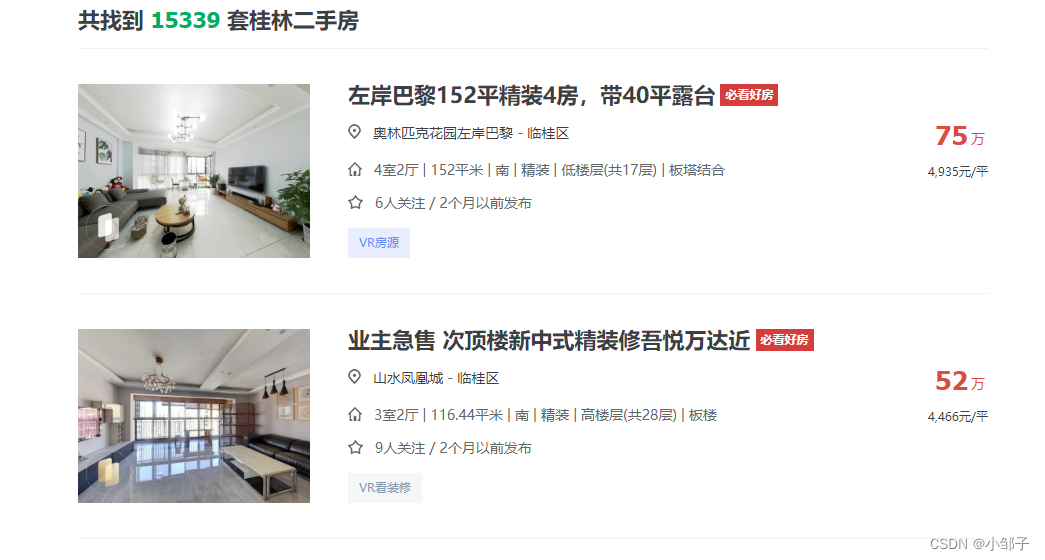
定义了三个函数依次实现此过程:
import requests
import re
import threading
import pandas as pd
from lxml import etree
# 全部信息列表
count=list()
#生成1-10页url
def url_creat():
#基础url
url = 'https://gl.lianjia.com/ershoufang/pg{}/'
#生成前10页url列表
links=[url.format(i) for i in range(1,11)]
return links
#对url进行解析
def url_parse(url):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': 'lianjia_uuid=7e346c7c-5eb3-45d9-8b4f-e7cf10e807ba; UM_distinctid=17a3c5c21243a-0c5b8471aaebf5-6373267-144000-17a3c5c21252dc; _smt_uid=60d40f65.47c601a8; _ga=GA1.2.992911268.1624510312; select_city=370200; lianjia_ssid=f47906f0-df1a-49e2-ad9b-648711b11434; CNZZDATA1253492431=1056289575-1626962724-https%253A%252F%252Fwww.baidu.com%252F%7C1626962724; CNZZDATA1254525948=1591837398-1626960171-https%253A%252F%252Fwww.baidu.com%252F%7C1626960171; CNZZDATA1255633284=1473915272-1626960625-https%253A%252F%252Fwww.baidu.com%252F%7C1626960625; CNZZDATA1255604082=1617573044-1626960658-https%253A%252F%252Fwww.baidu.com%252F%7C1626960658; _jzqa=1.4194666890570963500.1624510309.1624510309.1626962867.2; _jzqc=1; _jzqy=1.1624510309.1626962867.2.jzqsr=baidu|jzqct=%E9%93%BE%E5%AE%B6.jzqsr=baidu; _jzqckmp=1; _qzjc=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2217a3c5c23964c1-05089a8de73cbf-6373267-1327104-17a3c5c23978b3%22%2C%22%24device_id%22%3A%2217a3c5c23964c1-05089a8de73cbf-6373267-1327104-17a3c5c23978b3%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_utm_source%22%3A%22baidu%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22wyyantai%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1624510327,1626962872; _gid=GA1.2.134344742.1626962875; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1626962889; _qzja=1.1642609541.1626962866646.1626962866646.1626962866647.1626962872770.1626962889355.0.0.0.3.1; _qzjb=1.1626962866646.3.0.0.0; _qzjto=3.1.0; _jzqb=1.3.10.1626962867.1; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiNzQ3M2M3OWQyZTQwNGM5OGM1MDBjMmMxODk5NTBhOWRhNmEyNjhkM2I5ZjNlOTkxZTdiMDJjMTg0ZGUxNzI0NDQ5YmZmZGI1ZjZmMDRkYmE0MzVmNmNlNDIwY2RiM2YxZTUzZWViYmQwYmYzMDQ1NDcyMzYwZTQzOTg3MzJhYTRjMTg0YjNhYjBkMGMyZGVmOWZiYjdlZWQwMDcwNWFkZmI5NzA5MjM1NmQ1NDg0MzQ3NGIzYjkwY2IyYmEwMjA2NjBjMjI2OWRjNjFiNDE3ZDc1NGViNjhlMzIzZmI0MjFkNzU5ZGNlMzAzMDhlNDAzYzIzNjllYWFlMzYxZGYxYjNmZmVkNGMxYTk1MmQ3MGY2MmJhMTQ1NWI4ODIwNTE5ODI2Njg2MmVkZTk4OWZiMDhjNTJhNzE3OTBlNDFiZDQzZTlmNDNmOGRlMTFjYTAwYTRlZTZiZWY5MTZkMTcwN1wiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCI3ZjI1NWI1ZlwifSIsInIiOiJodHRwczovL3FkLmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvMTAzMTE2MDkzOTU5Lmh0bWwiLCJvcyI6IndlYiIsInYiOiIwLjEifQ==',
'Host': 'qd.lianjia.com',
'Pragma': 'no-cache',
'Referer': 'https://qd.lianjia.com/',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'}
response=requests.get(url=url,headers=headers).text
tree=etree.HTML(response)
#ul列表下的全部li标签
li_List=tree.xpath("//*[@class='sellListContent']/li")
#创建线程锁对象
lock = threading.RLock()
#上锁
lock.acquire()
for li in li_List:
#标题
title=li.xpath('./div/div/a/text()')[0]
#网址
link=li.xpath('./div/div/a/@href')[0]
#位置
postion=li.xpath('./div/div[2]/div/a/text()')[0]+li.xpath('./div/div[2]/div/a[2]/text()')[0]
#类型
types=li.xpath('./div/div[3]/div/text()')[0].split(' | ')[0]
#面积
area=li.xpath('./div/div[3]/div/text()')[0].split(' | ')[1]
area=area[:-2]
#房屋信息
info=li.xpath('./div/div[3]/div/text()')[0].split(' | ')[2:-1]
info=''.join(info)
#房屋年份
year=li.xpath('./div/div[3]/div/text()')[0].split(' | ')[5]
numbers = re.sub("\D", "",year) # 匹配连续的数字
year=''.join(numbers)
#房屋装修情况
renovation=li.xpath('./div/div[3]/div/text()')[0].split(' | ')[3]
#总价
count_price=li.xpath('.//div/div[6]/div/span/text()')[0]
#单价
angle_price=li.xpath('.//div/div[6]/div[2]/span/text()')[0]
angle_price=re.sub("\D", "",angle_price)#只保留数字
dic={'标题':title,"位置":postion,'房屋类型':types,'面积(平米)':area,"单价(元/平)":angle_price,'总价(万)':count_price,'年份':year,'精/简装':renovation,'介绍':info,"网址":link}
print(dic)
#将房屋信息加入总列表中
count.append(dic)
#解锁
lock.release()
def run():
links = url_creat()
#多线程爬取
for i in links:
x=threading.Thread(target=url_parse,args=(i,))
x.start()
x.join()
#将全部房屋信息转化为excel
data=pd.DataFrame(count)
data.to_excel('桂林房屋信息.xlsx',index=False)
if __name__ == '__main__':
run()
爬虫细节参考:【Python爬虫项目】链家房屋信息抓取(超详细适合新手练习附源码)
2.数据清洗
爬出下来的数据存在空缺的情况,并需要去除部分信息【不清洗也可以】
使用python进行数据清洗。首先读取数据
import pandas as pd
data = pd.read_excel("桂林房屋信息.xlsx")
data.head(5)
#data.info()

去掉标题、介绍和网址列,去掉年份为空的行
data_db=data[["位置","房屋类型","面积(平米)","单价(元/平)","总价(万)","年份","精/简装"]].dropna()
data_db["年份"]=data_db["年份"].astype('int')#年份变成整型
data_db = data_db.sort_values(by="年份", ascending=False)#按年份进行排序
data_db
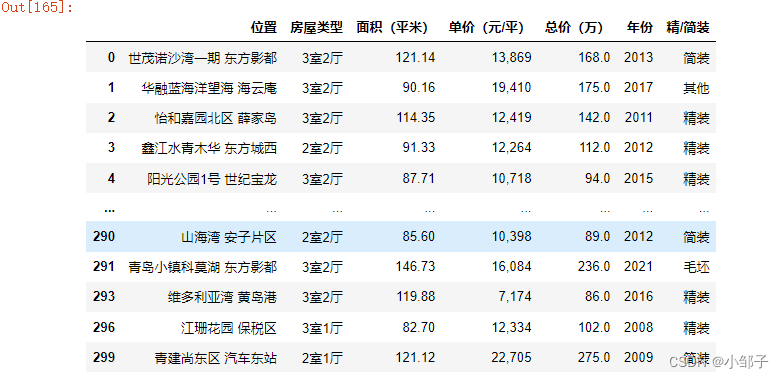
3.数据存储
将清洗好的数据存储到mongodb中:将数据转换成字典列表形式,通过insert_many方法写入
import pandas as pd
from pymongo import MongoClient
# 创建MongoDB客户端
client = MongoClient('localhost', 27017) # 根据自己的配置修改主机名和端口号
db = client['lianjia'] # 选择或创建数据库
collection = db['ershoufang'] # 选择或创建集合
# 读取DataFrame数据
# 转换DataFrame为字典列表形式
documents = data_db.to_dict(orient='records')
# 向集合中插入文档
collection.insert_many(documents)
print("Data stored in MongoDB successfully!")
成功写入
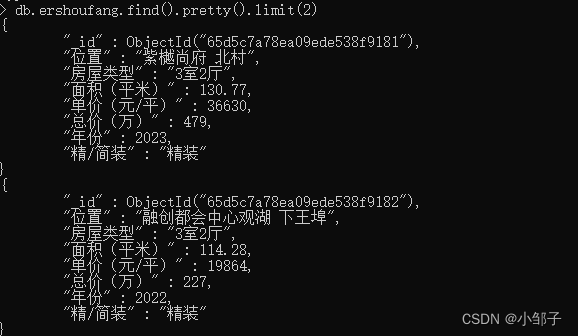
二、使用 python 读取 mongodb 数据并进行可视化分析
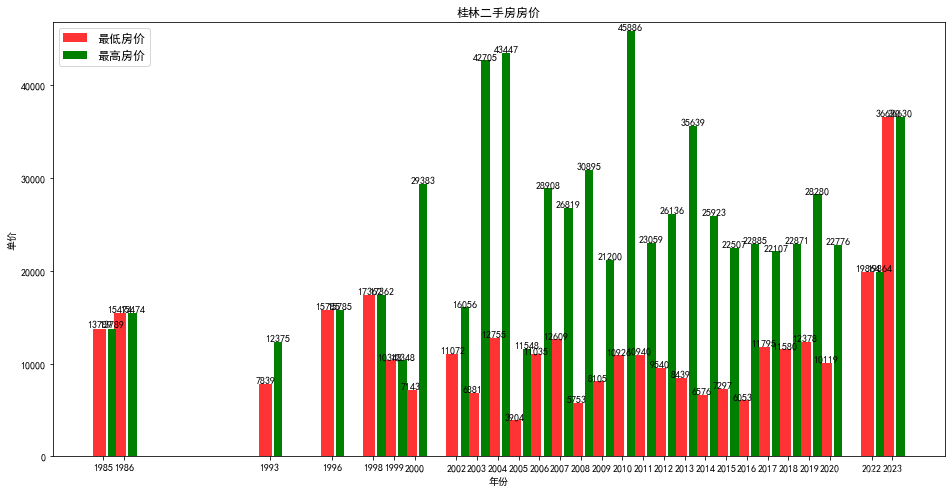
房源数据进行存储后,需要进行数据分析,比如获取不同年份房价(单价)的最小值和最大值,并以条形图的形式展示出来。
1.以统计不同年份的房价为例,使用 MongoDB 聚合管道技术对数据进行分组计算,如下代码片段对房源的不同年份进行分组聚合:
db = client['lianjia'] # 选择数据库
col= db['ershoufang'] # 选择集合
# 使用 $group 操作对文档分组和聚合
pipeline = [
{
"$group": {
"_id": "$年份",
"MinPrice": {"$min": "$单价(元/平)"} ,
"MaxPrice": {"$max" : "$单价(元/平)"}
}
}
]
# 执行聚合操作
price = list(col.aggregate(pipeline))
# 打印分组和聚合结果
for doc in price:
print(doc)

出现了问题:
#这样提取的不了“_id”字段到列表year中
year =[]
for doc in price:
year.append(doc["_id"])
也就是nongodb聚合出来的结果python不能直接提取到列表,这个问题我也不知道如何解决。。。
大佬们若知道还请评论区告知一声。
所以,比较笨拙的办法为,把聚合的结果先存储到新的集合中:
db.ershoufang.aggregate( [
{$group:{
"_id":"$年份",
"MinPrice":{"$min":"$单价(元/平)"},
"MaxPrice":{"$max":"$单价(元/平)"}
}
},
{ $sort : { "_id" : 1 } },
{"$out":
{"db":"lianjia","coll":"tongji"}
}
])
其中,{ $sort : { “_id” : 1 } }为按照_id字段排序,即为按照年份排序, {“$out”:{“db”:“lianjia”,“coll”:“tongji”}} 为把聚合结果作文新文档存放在数据库lianjia的集合tongji中。
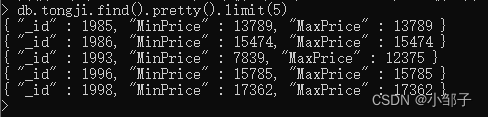
这样就可以提取文档的字段到列表中了,进行下一步:绘图。
2.基于聚合统计出的数据使用 python 绘制条形图,使用到 matplotlib 库,具体代
码如下:
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import json
col2= db['tongji'] # 选择集合
year =[]
Min_Price =[]
Max_Price =[]
#获取聚合后的数据并插入 year ,Min_Price,Max_Price,用于纵横坐标显示。
for doc in col2.find():
year.append(doc["_id"])
Min_Price.append(doc["MinPrice"])
Max_Price.append(doc["MaxPrice"])
# 设置中文字体和负号正常显示
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
# 创建一个新的画布并指定大小为10x6英寸
plt.figure(figsize=(16, 8))
x=year
#绘制条形图 :条形中点横坐标;height:长条形高度;width:长条形宽度,默认值0.8;label:为后面设置 legend 准备
rects1=plt.bar(x,height=Min_Price,width=0.4,alpha=0.8,color='red', label="最低房价")
rects2=plt.bar([i + 0.4 for i in x],height=Max_Price, width=0.4, color='green', label="最高房价")
plt.ylim(0,max(Max_Price)+1000) # y 轴取值范围
plt.legend(loc="upper left", prop={"size": 12, }) # 显示图例 设置图例的大小和方向
#设置两个柱状图数据显示
for rect in rects1:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+1,
str(height), ha="center", va="bottom")
for rect in rects2:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+1,
str(height), ha="center", va="bottom")
plt.ylabel("单价")
#设置 x 轴刻度显示值;参数一:中点坐标;参数二:显示值
plt.xticks([index + 0.2 for index in x],year)
plt.xlabel("年份")
plt.title("桂林二手房房价")
#显示条形图
plt.show()
结果如图所示
一些容易出现的问题:
1.数据类型问题:爬虫阶段下载的数据可能是文本类型的或者带单位,数据分析需要改为浮点型或者整型,当然也可以在下载的时候处理好
2.下载的数据若要以年份进行排序,需要提前处理,否则画图会出现问题。
参考资料:《NoSQL数据库原理与应用》,主编:王爱国、许桂秋。