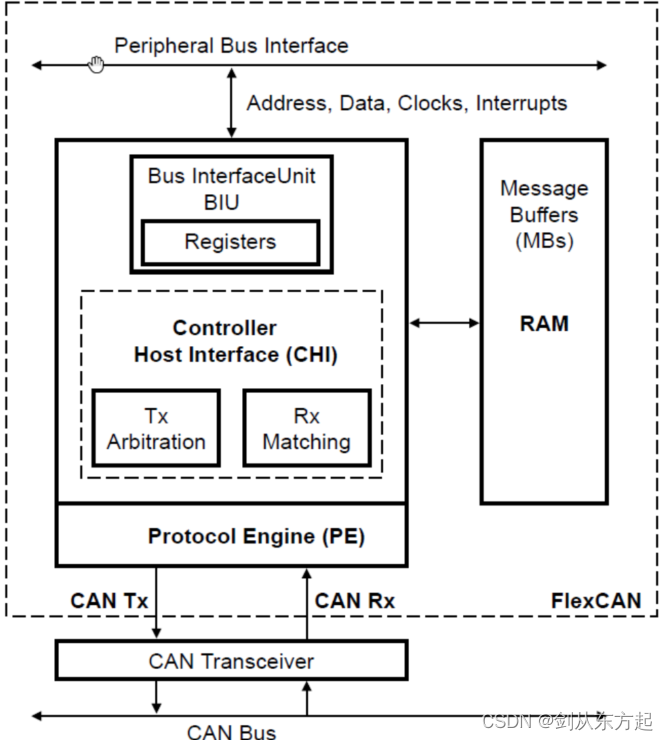
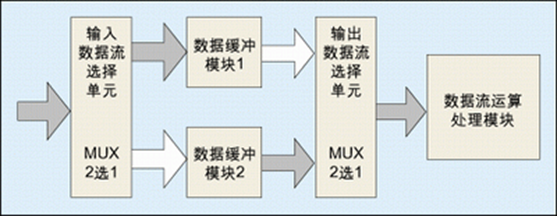
原文地址:Visualize your RAG Data — EDA for Retrieval-Augmented Generation
2024 年 2 月 8 日
Github:https://github.com/Renumics/rag-demo/blob/main/notebooks/visualize_rag_tutorial.ipynb
为探索Spotlight中的数据,我们使用Pandas DataFrame来组织数据。首先,我们从向量存储中提取文本片段及其嵌入。此外,让我们标记正确答案:
import pandas as pd
response = docs_vectorstore.get(include=["metadatas", "documents", "embeddings"])
df = pd.DataFrame(
{
"id": response["ids"],
"source": [metadata.get("source") for metadata in response["metadatas"]],
"page": [metadata.get("page", -1) for metadata in response["metadatas"]],
"document": response["documents"],
"embedding": response["embeddings"],
}
)
df["contains_answer"] = df["document"].apply(lambda x: "Eichler" in x)
df["contains_answer"].to_numpy().nonzero()
问题和相关答案也被投射到嵌入空间中。处理方式与处理文本片段相同:
question_row = pd.DataFrame(
{
"id": "question",
"question": question,
"embedding": embeddings_model.embed_query(question),
}
)
answer_row = pd.DataFrame(
{
"id": "answer",
"answer": answer,
"embedding": embeddings_model.embed_query(answer),
}
)
df = pd.concat([question_row, answer_row, df])
此外,还可以确定问题与文档片段之间的距离:
import numpy as np
question_embedding = embeddings_model.embed_query(question)
df["dist"] = df.apply(
lambda row: np.linalg.norm(
np.array(row["embedding"]) - question_embedding
),
axis=1,
)
该值还可用于可视化,并将存储在列距离中:
| id | question | embedding | answer | source | page | document | contains_answer | dist | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | question | Who built the Nürburgring | [0.005164676835553928, -0.011625865528385777, ... | nan | nan | nan | nan | nan | nan |
| 1 | answer | nan | [-0.007912757349432444, -0.021647867427574807, ... | The Nürburgring was built in the 1920s in the town | nan | nan | nan | nan | 0.496486 |
| 2 | 000062fd07a090c7c84ed42468a0a4b7f5f26bf8 | nan | [-0.028886599466204643, 0.006249633152037859, ... | nan | data/docs/Hamilton–Vettel rivalry.html | -1 | Media reception... | 0 | 0.792964 |
| 3 | 0003de08507d7522c43bac201392929fb2e26b86 | nan | [-0.031988393515348434, -0.002095212461426854, ... | nan | data/docs/Cosworth GBA.html | -1 | Team Haas[edit]... | 0 | 0.726574 |
| 4 | 000543bb633380334e742ec9e0c15a188dcb0bf2 | nan | [-0.007886063307523727, 0.007812486961483955, ... | nan | data/docs/Interlagos Circuit.html | -1 | Grand Prix motorcycle racing. | 0 | 0.728354 |
可通过以下方式启动聚类:
from renumics import spotlight
spotlight.show(df)
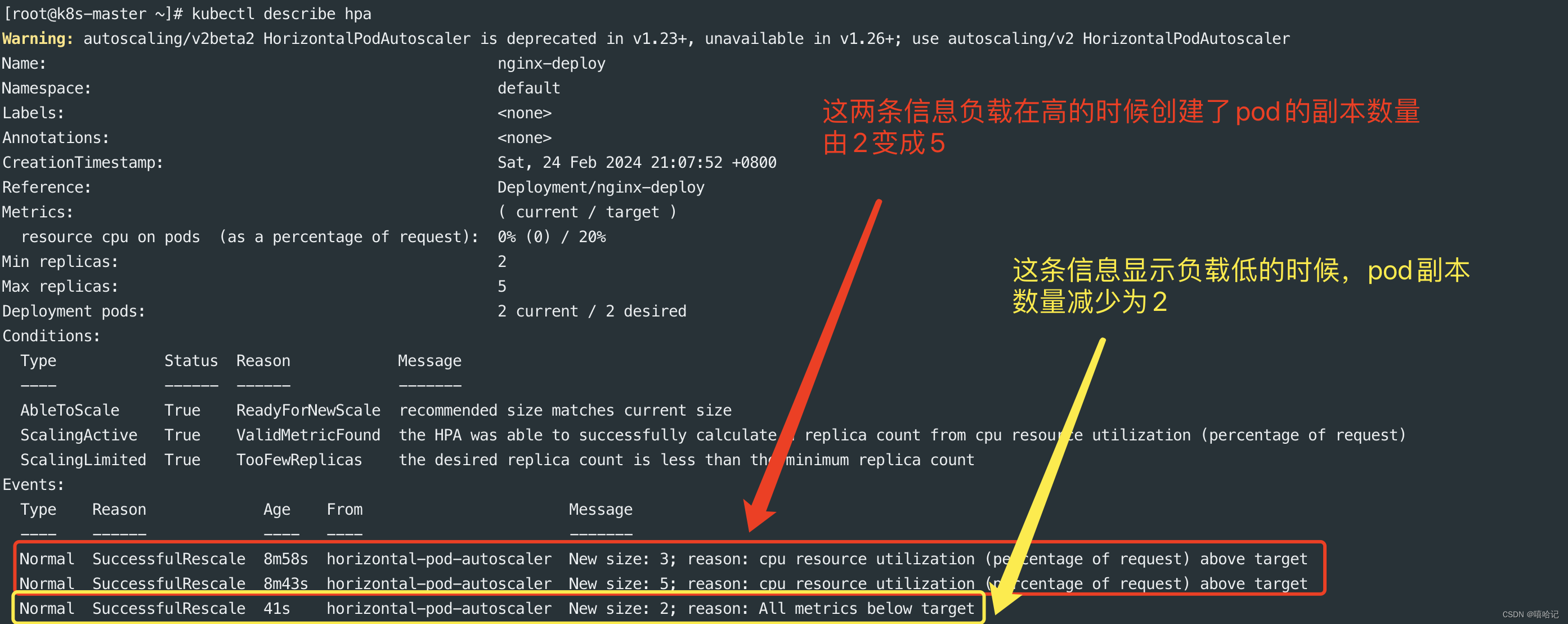
它将打开一个新的浏览器窗口。左上角的表格部分显示数据集的所有字段。您可以使用 "可见列 "按钮选择 "问题"、"答案"、"来源"、"文档 "和 "距离 "列。按 "dist "排序的表格会将问题、答案和最相关的文档片段显示在最上面。选择前 14 行,可在右上角的相似性地图中突出显示。
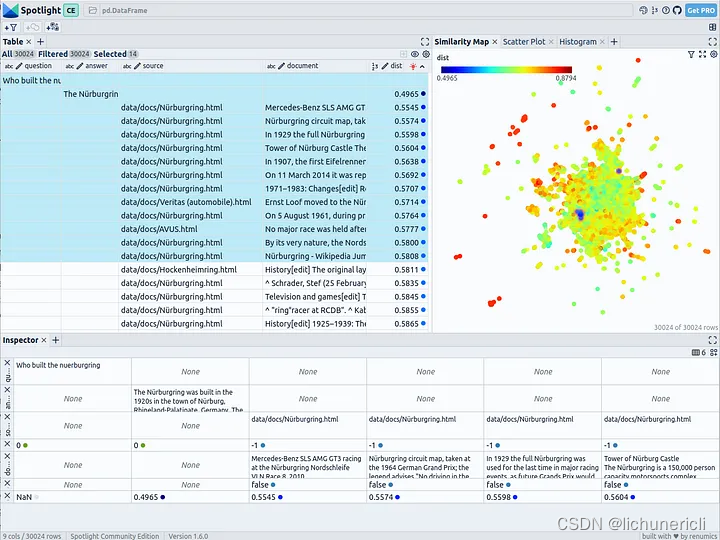
您可以观察到,最相关的文档与问题和答案非常接近。这包括包含正确答案的单个文档片段。
单个问题、答案和相关文档的良好可视化显示了 RAG 的巨大潜力。使用降维技术可以让用户和开发人员访问嵌入空间。本文具体介绍的实用性仍然非常有限。探索这些方法在提出许多问题方面的可能性,从而说明 RAG 系统在运行中的使用情况,或通过评估问题检查嵌入空间的覆盖情况,仍然令人兴奋。
使用 Spotlight 等工具可以使 RAG 的可视化变得更容易,从而增强数据科学工作流程。