原文地址:improve-rag-performance-on-custom-vocabulary
Code:Improve RAG performance on custom vocabulary.ipynb
2024 年 2 月 9 日
 糟糕的检索系统会导致混乱、沮丧和幻觉。
糟糕的检索系统会导致混乱、沮丧和幻觉。
新的嵌入模型比以往更加强大。我们根据 MTEB 等基准对其进行了全面评估。但是,当我们的自定义数据包含一些网上找不到的单词(如内部产品名称和 ID)时,为什么这些模型仍然会惨遭失败呢?在本文中,我们将找出确切原因并提出多种解决方案。
简要说明
当引入自定义词汇或术语,或者使用了较差的分块策略或数据建模时,开箱即用的语义搜索模型就会失效。可以利用关键词搜索、查询扩展或使用 Reciprocal Rank Fusion(RRF)进行动态权重调整,以减少自定义词汇造成的错误。微调嵌入模型需要仔细的数据收集和设计,只有在应用了前面提到的方法后才能进行实验。
改进检索的十亿美元动力
Microsoft 365 的 Copilot 就是一个成功的 RAG 应用程序范例。Copilot 正在利用 RAG 模式,重点强调 R(etrieval)。真正的核心工作是数据建模和检索,Microsoft Graph 已经构建了8年之久。
Microsoft 365的Copilot是成功应用RAG模式的一个例子。Copilot充分利用了RAG模式,重点放在R(etrieval)上。真正的核心工作是数据建模和检索,已经构建了8年之久,即Microsoft Graph。
什么是 RAG?
检索增强生成(RAG)由检索、增强和生成三部分组成。首先,将用户问题转换为搜索查询。其次,通过应用程序接口从各种来源获取相关文本数据。第三,将相关文本数据与用户问题一起插入 LLM(大语言模型)提示。第四,LLM 根据相关文本数据生成对用户问题的回复。最后,将答案与相关数据源一起显示给用户,这样用户就可以轻松验证聊天机器人的答案。
 基本 RAG 工作流程包括检索、增强和生成。
基本 RAG 工作流程包括检索、增强和生成。
这一过程具有透明度和可扩展性。最后一步是显示聊天机器人回答问题的理由,这对于提高透明度至关重要。模块化设计允许 RAG 架构的每个组件独立扩展,因此我们可以切换 LLM、用户界面和信息检索(IR)系统或修改知识库的信息源。
机器学习或黑盒 LLM 通常不容易实现这些优势,因此基本的 RAG 模式很可能经受住时间的考验。LLM 可以换成其他算法,汇集文本数据进行回答,用户界面可以换成增强现实眼镜,IR 系统可以由成千上万个不同的 API 组成,供用户调用(可以查看 Gorilla)。在本例中,ChatGPT 是一种方便的基于文本问答的 LLM,更高级的 IR 系统可以留到以后使用。
既然我们已经就什么是 RAG 模式达成了共识,那么我们就来研究一下 IR 系统的陷阱,特别是 RAG 的陷阱。
向量搜索失败的原因及解决方法
举个例子,假设我们基于 Tesla Model 3 手册,利用语义向量搜索建立了一个 RAG 客户支持聊天机器人。为了建立矢量索引,我们将手册逐页分块。
您可以通过此 Google Colab 笔记本跟进示例。笔记本、微调模型权重、训练数据以及训练和验证损失都可以在 Google Drive 上找到。请记得将所有必要文件从 Google Drive 上传到 Google Colab 文件系统,以便在笔记本中访问。
问题陈述
一位用户进入聊天室。用户在特斯拉汽车仪表盘上遇到一个错误:APP_w304。用户向特斯拉聊天机器人发送信息。
“I see code APP_w304 on my dashboard what to do?”("我在仪表盘上看到了代码 APP_w304,该怎么办?")
query = "I see code app_w304 on my dashboard what to do?"
relevant_page, page_no, X = find_relevant_page_from_document(query)
answer = get_openai_rag_response(query, relevant_page)
print(answer)
我们的特斯拉聊天机器人首先根据语义相似性找到与查询最相关的页面,然后返回,并对问题做出回复。语义检索器找错了页面,结果聊天机器人产生了幻觉。
 聊天机器人无法找到正确的页面并产生幻觉。
聊天机器人无法找到正确的页面并产生幻觉。
语义搜索找到了第 0 页,但问题的真正答案可以在第 217 页找到。第 1 页是封面页:
 第1页:根据语义搜索与用户查询最相关的页面。
第1页:根据语义搜索与用户查询最相关的页面。
封面页几乎没有文字或其他相关信息。注意:当我们显示聊天机器人找到的索引时,我们从索引 0 开始。因此索引 0 对应第 1 页,索引 100 对应第 101 页,以此类推。
语义搜索为何失败?
我们可以将第 1 页分成若干句子,然后找出与用户查询最相似的句子。我们使用的嵌入模型要求在简短查询前加上 "Represent this sentence for searching relevant passages:"句子。该模型的训练目的是为短查询到长段落(s2p)的匹配生成高质量的嵌入。这意味着,我们为查询预置一个句子,以便模型识别我们正在用短查询查找长段落。我们使用点积来测量文本相似性。
我们通过查找换行符(\n)来提取句子。
page_texts = np.array([x for x in relevant_page.split('\n') if len(x) > 1])
page_ems = get_opensource_embeddings(page_texts)
q = get_opensource_embeddings(query, is_s2p=True).flatten()
v = q @ page_ems.T
top_matches = page_texts[np.argsort(v)[::-1]]
for i, m in enumerate(top_matches[:5]):
print(f"Match #{i}: {m}")
 与用户查询最相似的句子。
与用户查询最相似的句子。
问题在于标记化
我们希望找到与错误代码 APP_w304 相关的页面,但最终匹配到的页面上的数字和关键词似乎与我们的查询无关。数字 3、0 和 4 在最相似的句子中重复出现,这就是问题的根源——标记化(tokenization)。
标记化首先将文本分解成单词和子单词,然后将它们转换成数字。这些数字由嵌入模型处理。标记化的目的是找到英语中自然出现的单词和词干。我们有一个错误代码 APP_w304 ,它不是一个合适的英语单词。嵌入模型会尝试匹配标记,而不是我们直觉上认为的自然单词。您可以在 OpenAI 的在线演示中尝试使用 OpenAI tokenizer 对文本进行标记。我们使用的是开源嵌入模型 bge-base-en-v1.5,它使用的标记符与 OpenAI 的不同。
让我们看看我们的错误代码和最相似的句子包含哪些标记。
query_tokens = tokenizer.encode('APP_w304')
best_match_tokens = tokenizer.encode('Software version: 2023.44.30')
print_output(f"APP_w304 tokenized: {[tokenizer.decode(token) for token in query_tokens]}")
print_output(f"Software version: 2023.44.30: {[tokenizer.decode(token) for token in best_match_tokens]}")
 标记化的用户查询和手册中最相似的句子。
标记化的用户查询和手册中最相似的句子。
现在,我们看到的文本就像我们的嵌入模型一样——以标记序列的形式出现。我们在用户查询中有一个标记 app,在匹配的句子中有一个标记 software。数字之间也很接近,如 ##3 和 ##30 。这些标签可以解释为任何字母,它只是表示数字 3 作为某个单词的一部分出现。
嵌入模型不理解任何类型的自定义词汇、缩写或首字母缩略词,这些特殊词汇被标记为本身并不表达意义的子词汇。有人可能会说,标记的总和大于单个标记,对单个标记的调查并不代表真正的语义。虽然这是事实,但对单个标记的研究展示底层的基本工作原理。
补充语义搜索:关键词搜索,BM25
BM25(Best Matching 25)可以帮助我们解决自定义词汇的问题。它能将句子分解成单独的单词,并形成一个搜索索引,强调重要的单词。
在将 BM25 与我们的手册进行匹配时,BM25 为 APP_w304 这样的罕见词分配了更高的权重。这使得在众多词语中找到这一特定代码变得更加容易。不过,BM25 只查找完全匹配的词,而不考虑同义词或整个文本的含义。
由于 BM25 考虑的是精确文本匹配,因此必须为 BM25 定义一个标记器。在这里,标记器接收一段文本,并根据空格""和换行符"\n "将其分解为单个单词。对于 BM25,我们将使用 rank-bm25 Python 软件包。
from rank_bm25 import BM25Okapi
def bm25_tokenizer(sentence):
list_split_by_space = sentence.split(' ')
list_of_lists_by_newline = [token.split('\n') for token in list_split_by_space]
corpus = [word for word_list in list_of_lists_by_newline for word in word_list]
# Remove empty strings, assuming word must have at least 3 characters
corpus = [word.lower() for word in corpus if len(word) > 2]
return corpus
tokenized_corpus = [bm25_tokenizer(doc) for doc in texts]
tokenized_query = bm25_tokenizer(query)
bm25 = BM25Okapi(tokenized_corpus)
定义标记符后,我们就可以搜索最相关的页面并打印聊天机器人的答案。
most_similar_page = bm25.get_top_n(tokenized_query, texts, n=1)[0]
answer = get_openai_rag_response(query, most_similar_page)
print(answer)
 聊天机器人找到了正确的页面并给出了合理的答案。
聊天机器人找到了正确的页面并给出了合理的答案。
找到正确的页面后,聊天机器人就可以做出回应。
在使用基于关键词的模型时,预处理至关重要,因为单个关键词会成为搜索词。即使我们进行了最少量的预处理,BM25 的性能仍优于带有错误代码的语义搜索。不过,预处理需要大量工作,而且无法扩展到涵盖所有同义词和语义。
如果我们能从关键字和语义搜索中获得最佳效果呢?
结合语义搜索和关键词搜索
语义搜索和关键词搜索关注文本的不同方面。我们可以将任何搜索算法与 Reciprocal Rank Fusion (RRF) 相结合。RRF 的工作原理是评估多个排序结果的搜索得分,并将它们合并成一个统一的结果集。RRF 的细节在下面的代码中有解释,但这并不是理解的关键。正式的解释见他们长达 2 页的研究论文。
def rrf(all_rankings: list[list[int]]):
"""Takes in list of rankings produced by multiple retrieval algorithms,
and returns newly of ranked and scored items."""
scores = {} # key is the index and value is the score of that index
# 1. Take every retrieval algorithm ranking
for algorithm_ranks in all_rankings:
# 2. For each ranking, take the index and the ranked position
for rank, idx in enumerate(algorithm_ranks):
# 3. Calculate the score and add it to the index
if idx in scores:
scores[idx] += 1 / (60 + rank)
else:
scores[idx] = 1 / (60 + rank)
# 4. Sort the indices based on accumulated scores
sorted_scores = sorted(scores.items(), key=lambda item: item[1], reverse=True)
return sorted_scores
通过在 RRF 中插入我们的检索算法排名
new_ranks = rrf([semantic_top_5_matches_idx, keyword_top_5_matches_idx])
print_output(new_ranks)
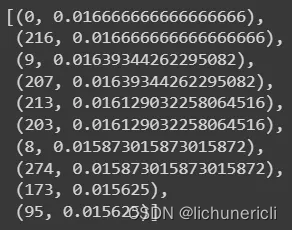 页面和排名分数由 RRF 计算。
页面和排名分数由 RRF 计算。
语义检索算法和关键词检索算法在任何事情上都无法达成一致。RRF 假设检索算法结果之间存在重叠。如果这一假设不成立,我们最终只能从两种算法中选取最靠前的结果,从而使算法变得毫无用处。我们可以权衡不同的检索算法,但这不是解决根本问题的通用方法。
我们最后的选择是对检索算法进行微调,使其至少部分保持一致,或者尝试使用重新排序。重新排序的基本思想是训练一个模型,根据某些标准对最终结果集进行重新排序。这将引入第三个模型,但我们希望用我们的模型来解决根本问题,而不是引入更多的模型和复杂性。
接下来,让我们对嵌入模型进行微调。
 AI很困惑,无法解决问题,迷失在沙漠中。微调可以帮助我们的人工智能吗?
AI很困惑,无法解决问题,迷失在沙漠中。微调可以帮助我们的人工智能吗?
在自定义数据中微调嵌入模型
通过微调,我们希望在 APP_w304 代码中产生语义,将其与相机的问题联系起来。
由于代码 APP_w304 与 "相机被遮挡或失明 "相关,因此我们应尝试将代码移近 "相机 "和其他相关词,如 "失明"。现在,APP_w304 与单词 application 和 software 相似,正如您所看到的,它在我们的矢量搜索中效果不佳。
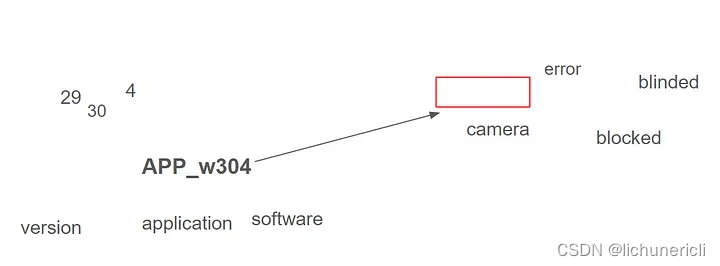 向量(嵌入)空间中的单个单词。靠近的单词被定义为相似的单词。APP_w304 应移近红色框。插图。
向量(嵌入)空间中的单个单词。靠近的单词被定义为相似的单词。APP_w304 应移近红色框。插图。
从技术角度讲,我们希望 APP_w304 的嵌入更接近相机一词的嵌入,而远离应用程序一词的嵌入。为此,我们需要以下训练数据:
- query: a sentence including one of our error codes
- positive passage: a text similar to our error code
- negative passage: a text dissimilar to our error code
我们不能只考虑 APP_w304 这一个错误代码,因为手册中有几十个错误代码。我们可以手动收集数据,这很费力,也可以尝试自动生成数据。
生成训练数据
我们需要收集查询以及与查询相似和不相似的段落。例如,三元组 (query, positive, negative) 可以是 (“What’s APP_w218 error?”, “Autosteer speed limit exceeded”, “seatbelts must be fastened”)。我们的正面段落必须与查询密切相关,而负面段落必须是否定或硬性否定。硬性否定是指与正面段落 "有些相似",但有一些细微差别的句子。在这种情况下,硬否定句可能是 "autosteer connection error"。硬性否定句较难生成,因此我们将继续生成 "简单 "的否定句。
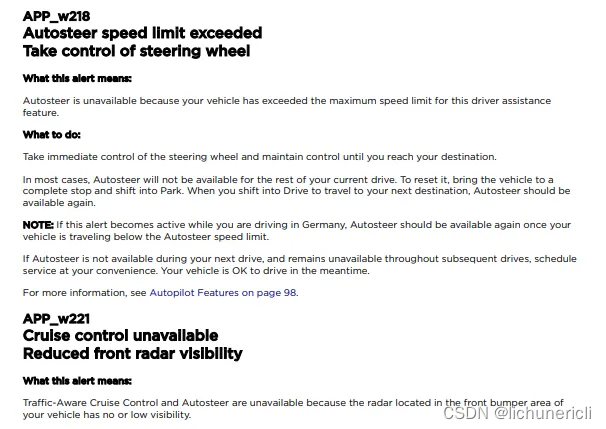 出现示例错误代码 APP_w218 的页面。
出现示例错误代码 APP_w218 的页面。
我们在页面级别上对 PDF 文档进行了分块。由于我们的语义搜索将每一页都视为一个段落,因此我们必须将完整的页面视为正反两方面的段落。在上图中,我们可以看到一个故障排除页面可能包含多个错误代码。最理想的情况是,我们为一个错误代码建立一个单独的分块,这样我们就只能在一个分块中捕捉到一个主题。这需要重新定义分块策略,不在本教程的范围之内。
让我们收集文档中的所有错误代码,并生成用户可能提出的现实问题,例如:
- ‘I see error code $errorCode. What should I do?’
- ‘There’s code $errorCode on my dashboard. Help!’
我们可以将查询的页面作为正面段落,而将故障排除页面之前的随机页面作为负面段落。
GPT-4 等 LLM 通常用于生成合成数据。我们将遍历每个故障排除页面,将其输入 GPT-4,生成与页面错误代码相关的查询。准确的 GPT-4 提示可在 Google Colab 示例笔记本中找到。
下图是单个训练数据点的示例
 包含查询、肯定段落和否定段落的三元组示例。
包含查询、肯定段落和否定段落的三元组示例。
在开始训练之前,我们还需要定义损失函数。我们希望在负向段落和查询嵌入接近时进行惩罚,而在正向段落和查询接近时进行奖励。我们将使用余弦嵌入损失函数(CosineEmbeddingLoss)。
现在,我们可以开始训练我们的模型,每隔一个epoch 跟踪一次验证损失,以确保我们没有过度拟合。
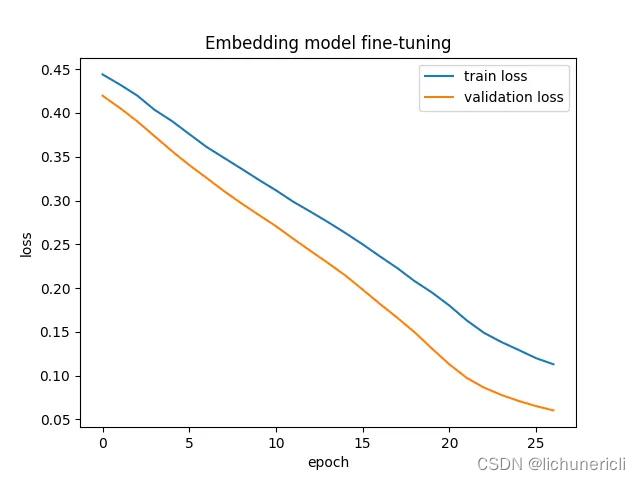 验证损失始终低于训练损失,这意味着我们没有过度拟合。当损失在“肘点”开始变平时,我们停止训练。
验证损失始终低于训练损失,这意味着我们没有过度拟合。当损失在“肘点”开始变平时,我们停止训练。
我们可以看到,训练和验证损失在可控的情况下得到了很好的控制。
我们现在能用语义搜索找到正确的页面吗?我们的训练集中没有包含错误代码 APP_w304,以了解模型是否能够泛化到新的错误代码。
chunks, outs = get_opensource_embeddings(texts)
relevant_page, page_no, X = find_relevant_page_from_document(USER_QUERY, passage_chunks=chunks)
print_output(USER_QUERY)
print_output(str(page_no))
 使用语义搜索时最相关的页面是第 214 页。第 217 页将是正确的页面。
使用语义搜索时最相关的页面是第 214 页。第 217 页将是正确的页面。
我们错过了一页正确的页面。这并不奇怪,因为训练数据集中没有 APP_w3** 错误代码。例如,APP_w222 表示由于摄像头可见度而无法使用巡航控制,APP_w224 表示由于缺乏校准而无法使用巡航控制。如果没有在训练数据中看到 APP_w223,理论上算法可以将 APP_w223 插值为标定问题和摄像头可见度问题。然而,我们没有任何其他以 APP_w3** 开头的代码,因此我们只能得到粗略的通用性。
我们的目标是对嵌入模型进行微调,使错误代码具有语义意义,从而使 BM25 之间的结果重叠,并能够使用 RRF。
我们是否成功调整了语义搜索?
微调语义搜索与关键词搜索相结合
现在我们可以再次运行 RRF,看看点击率最高的内容。
 针对 BM25、语义搜索计算并与 RRF 相结合的热门匹配。找到正确的第 217 页。
针对 BM25、语义搜索计算并与 RRF 相结合的热门匹配。找到正确的第 217 页。
我们的语义搜索在排除故障的页面(215、216、213、214、249)周围找到了匹配项,现在我们的关键字搜索和语义搜索结果出现了重叠。RRF 的输出结果发现索引 216 是最佳匹配项,得分 0.034,映射到正确的页面 217。
我们能够将错误代码的语义传授给我们的嵌入模型--这是一个巨大的成功。
 人工智能已经解决了大部分问号,并正在向更好的方向迈进。仍然有一些问题悬而未决,但现在我们有了解决这些问题的基础。
人工智能已经解决了大部分问号,并正在向更好的方向迈进。仍然有一些问题悬而未决,但现在我们有了解决这些问题的基础。
设计 IR 系统
我们成功地对自定义词汇的嵌入模型进行了微调。问题是,我们一开始就不应该这样做。一般来说,我们可以通过将问题分解为基本要素来找到更简单的解决方案。
如何改进检索系统的设计?
- 更好的分块——我们没有在主题层面定义分块,每个分块(每个页面)都有多个主题。
- 获取结构数据——对于 IR 系统,我们的目标是减少使用黑盒模型生成数据的需要,最大限度地增加我们可以信任的确定性构件的数量。
- 不同 IR 系统的使用效率低下——我们知道,关键词搜索有助于精确术语的搜索,而语义搜索则有助于语义和意义的搜索。我们应该找到一种方法,在适当的时候动态地利用每种系统。
我们在处理问题时,就好像我们无法访问生成 PDF 的数据源一样。在实际使用案例中,我们应该尝试访问生成 PDF 的结构数据源。首先,这将允许我们根据主题本身进行分块。如果我们有一个映射{$errorCode : $meaning},我们也可以简单地增强我们的查询,而不是微调嵌入模型。例如:
“I see code APP_w304 (Camera blocked or blinded) on my dashboard what to do?” (我在仪表盘上看到代码 APP_w304(摄像头被遮挡或盲区),该怎么办?)
通过 "增强查询",我们可以将错误代码的语义引入查询,从而无需进行词汇调整。
如果我们无法增强查询,另一种方法是分析输入的查询句,并动态调整不同 IR 系统的权重。如果查询包含自定义词汇,我们就会给关键词搜索分配更高的权重,反之亦然。
结论
我们将复杂的主题与现实世界的示例联系起来,现在您已准备好面对私有数据集的艰巨挑战。
这篇文章再次比我预期的要长,我不得不抄近路。有关完整的代码示例,请查看Google Colab Notebook。在下一篇文章中,我计划要么深入研究检索算法,要么介绍一些与幻觉有关的基本现实问题以及如何解决这些问题。