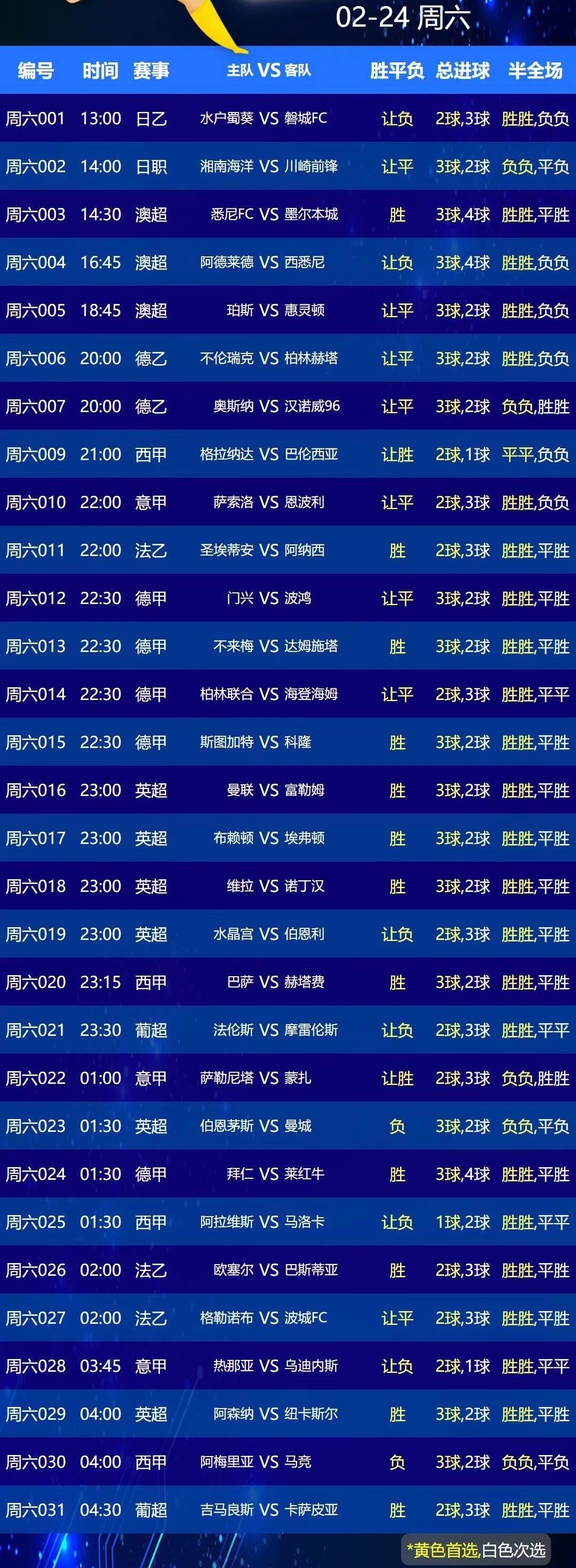
带解释性的医学大模型
- 提出背景
- 解法拆解
- 方法的原因
- 对比以前解法
- 零样本带解释性的医学大模型
- 如何使用CLIP模型和ChatGPT来进行零样本医学图像分类
- 用特定提示查询ChatGPT所生成的医学视觉特征描述
- 相似性得分在不同症状上的可视化,用于解释模型的预测
- 注意力图的可视化
- 对比使用设计的提示和基线提示时的注意力图
- 关键点
- 为ChatGPT选择和设计提示的细节
- CLIP模型的视觉和文本编码器处理医学图像的方式
- 多模态处理能力
- 注意力机制
- 特征激活与识别
- 决策过程的解释性
- 解释模型输出
- 模型调整与优化
论文:https://arxiv.org/pdf/2307.01981.pdf
提出背景
-
问题背景:在现实世界场景中,零样本医学图像分类是一个关键过程,特别是在可能疾病种类繁多、大规模标注数据有限的情况下。
这涉及到计算查询医学图像与可能的疾病类别之间的相似性分数,以确定诊断结果。
-
以前的解法:利用如CLIP这样的预训练视觉-语言模型(VLMs)在零样本自然图像识别中已展现出了卓越的性能,并且在医学应用中显示出潜力。
然而,一个既有希望的性能又能提供解释性的零样本医学图像识别框架还在开发中,天将降于我。
解法拆解
- 解法:提出了一个基于CLIP的零样本医学图像分类框架,并辅以ChatGPT进行解释性诊断,模拟人类专家执行的诊断过程。
- 特征1:利用大型语言模型(LLMs),如ChatGPT,通过疾病类别名称自动生成额外的线索和知识(例如疾病症状或描述),而不仅仅是单一的类别名称,以帮助CLIP提供更准确和可解释的诊断。
- 特征2:设计特定的提示,以提高ChatGPT生成描述视觉医学特征文本的质量。
方法的原因
- 之所以使用该解法:是因为在零样本医学图像诊断场景中,存在大量未标注的数据和多样的疾病类别,这使得传统的基于大量标注数据的方法难以应用。
- 之所以使用特征1(自动生成额外线索和知识):是因为仅通过图像和疾病类别的名称,难以达到高准确度和高解释性的诊断结果。额外的疾病相关信息能够提供更全面的上下文,以辅助诊断。
- 之所以使用特征2(设计特定的提示):是为了提升生成文本的质量,使其更贴合医学图像的特点,从而提升诊断的准确性和解释性。
对比以前解法
对比当前提出的解决方案与以往的方法,当前解决方案的主要改进点可以总结如下:
1. 引入解释性:
- 以前的解法:虽然以往的方法,特别是基于CLIP等预训练视觉-语言模型的零样本分类技术,在准确性上已经取得了显著进展,但这些方法往往缺乏足够的解释性。这意味着,尽管模型能够识别图像中的疾病,但它们难以提供关于其决策过程的透明度或解释,这在医学领域是非常重要的。
- 现在的解法:通过整合ChatGPT来自动生成关于疾病的额外线索和知识,本文提出的方法不仅关注于提升诊断的准确性,还强调了解释性。这种方式模拟了医生在做出诊断决策时的思考过程,提供了一个更加透明和可解释的诊断框架。
2. 自动化生成额外线索和知识:
- 以前的解法:以往的零样本诊断方法主要依赖于图像本身和有限的类别标签信息,这在处理复杂的医学图像时可能不足以提供全面的诊断。
- 现在的解法:通过利用大型语言模型(如ChatGPT),当前解决方案能够自动化地生成与特定疾病相关的额外线索和知识,如症状描述、可能的并发症等。这为CLIP提供了更丰富的上下文信息,有助于提高模型在零样本诊断任务中的性能。
3. 提升文本描述的质量:
- 以前的解法:在早期方法中,文本描述通常限于简单的疾病名称或者是直接从训练集中抽取的标签,这限制了模型理解和识别图像的能力。
- 现在的解法:本文提出的框架通过设计特定的提示来增强ChatGPT生成的文本描述质量,使之能够更准确地反映出医学图像的视觉特征。这样的高质量文本描述不仅有助于模型更好地理解图像内容,还能提升最终诊断的准确率和解释性。
4. 训练自由的零样本诊断流程:
- 以前的解法:传统方法往往需要大量的标注数据来训练模型,这在医学领域是一个重大挑战,因为高质量的医学图像标注既昂贵又耗时。
- 现在的解法:本文提出的方法不需要额外的训练过程,即可直接应用于零样本医学图像诊断。这种训练自由的方法大大降低了实施零样本诊断技术的门槛,使其更容易被医疗机构采纳和使用。
总的来说,当前的解决方案通过增强解释性、自动生成额外的疾病相关信息、提升文本描述的质量,并实现一个无需额外训练的零样本诊断流程,在准确性、解释性以及易用性方面对以往的方法进行了显著。
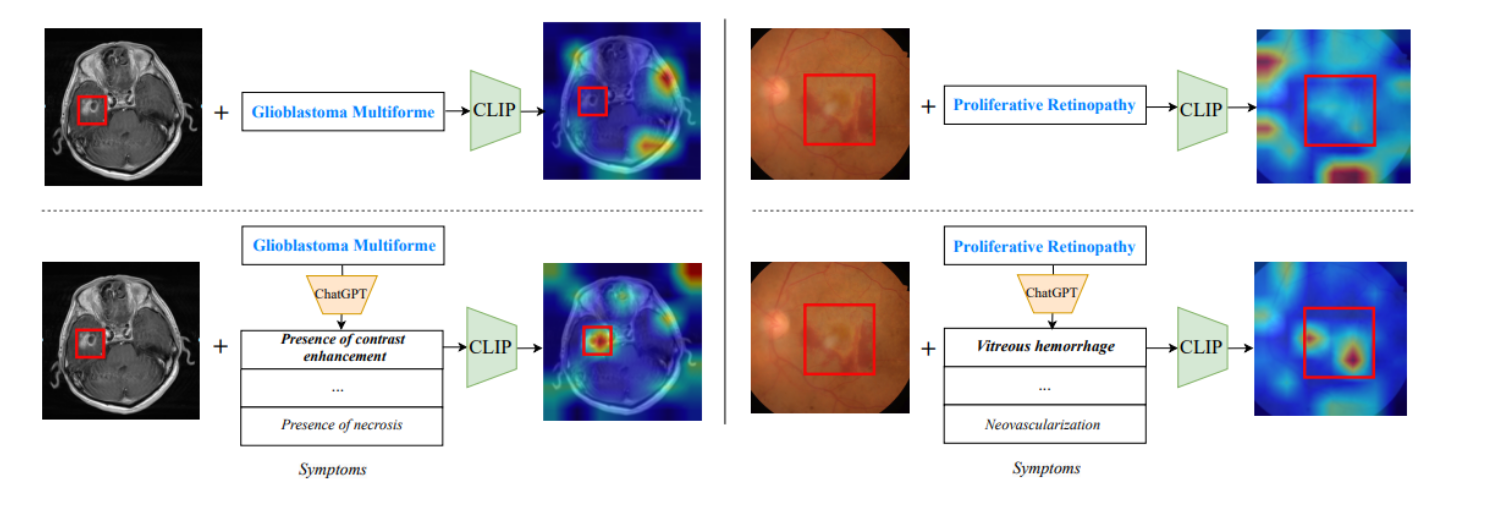
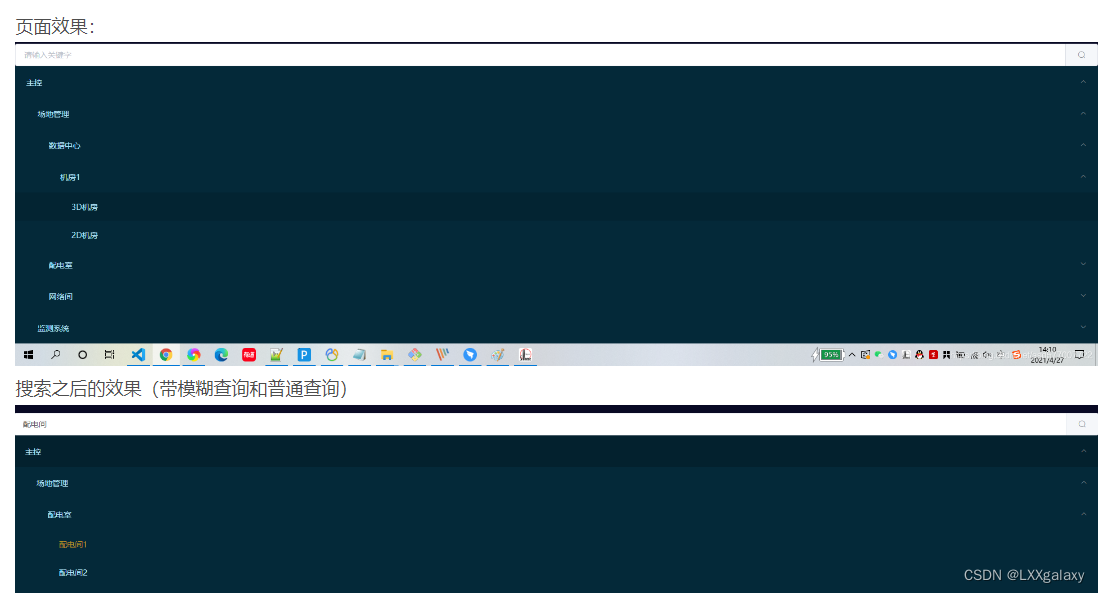
这张图展示的是一个零样本医学图像分类的可视化比较,对比了两种方法下模型的注意力图(Attention maps)。
注意力图,用于显示模型在处理数据时关注的区域。
在顶部行,你可以看到两个例子:
-
在左边,一个脑部MRI图像被标记出来,仅用了“Glioblastoma Multiforme”(一种脑肿瘤)作为诊断类别输入到CLIP模型中。
生成的注意力图显示模型关注的区域不是很明确,可能分散在整个图像上。
-
在右边,有一个眼底图像,同样地,仅用“Proliferative Retinopathy”(一种眼病)作为输入。
这里的注意力图也显示出模型关注的区域并不集中。
在底部行,展示的是本文提出的方法,通过结合ChatGPT生成的病症描述来增强模型的注意力:
-
在左边的脑部MRI图像中,除了疾病类别,还加入了由ChatGPT提供的额外病症信息,如“Presence of contrast enhancement”(对比度增强的存在)和“Presence of necrosis”(坏死的存在)。
在结合了这些额外信息后,生成的注意力图显示模型现在更集中地关注在图像的特定区域上,这可能对于诊断该类型的脑肿瘤是关键的。
-
在右边的眼底图像中,同样地,结合了ChatGPT生成的病症描述,如“Vitreous hemorrhage”(玻璃体出血)和“Neovascularization”(新生血管)。
加入了这些描述后,注意力图更集中于眼底图像的相关区域,这对于诊断增殖性视网膜病变是重要的。
这张图的主要目的是说明通过将ChatGPT生成的详细病症描述结合到CLIP模型中,可以显著提高模型的注意力集中度,进而可能提高医学图像分类和诊断的准确性。
虽然传统的大型模型(如GPT)具有一定程度的解释性,但这种解释性主要体现在模型输出的语言部分,而不足以直接应用于图像数据的解释性。
-
专业领域的语境:医学领域的术语和概念非常专业和复杂。
传统的大型语言模型虽然能够产生解释性文本,但这些解释可能不足以覆盖或准确地反映医学图像中的具体病理特征。
因此,需要专门设计的方法来确保生成的文本与医学诊断的专业性和准确性相匹配。
-
视觉和语言的结合:在零样本医学图像分类任务中,需要模型不仅理解文本描述,还要理解图像内容,并将两者结合起来进行准确的分类。
传统的语言模型不直接处理图像数据,因此需要与视觉模型(如CLIP)结合,以实现跨模态的理解。
-
解释性的具体化:传统的大型语言模型可能能够解释语言任务中的决策,但在图像诊断中,解释需要与特定的视觉标记和生理结构相联系。
通过加入医学图像中的具体病理特征描述,可以提高诊断的可解释性,使医疗专业人员更容易理解模型的决策过程。
-
可靠性和准确性的提升:在医学图像分析中,准确性至关重要。
通过结合特定的医学知识和病理特征,可以提高模型对于医学图像的理解,从而提高分类和诊断的准确性。
-
可操作的解释:医生和医疗专业人员需要的不仅仅是模型能给出分类结果,还需要明白为什么会这样分类。
提供详细的病理特征描述,可以帮助医疗专业人员理解模型的判断依据,这种操作层面的解释在实际应用中非常有价值。
零样本带解释性的医学大模型
面对零样本医学图像分类问题,误区是认为每个类别都需要大量标注样本才能进行有效的分类。
实际上,预训练的模型可以借助其已经学习到的丰富特征表示来弥补样本的不足。
结合VLMs来获取图像的视觉表示,同时利用LLMs生成有关的症状文本描述,并通过相似度计算实现精确的医学图像分类。
特征1: 使用CLIP的视觉编码器获取图像的视觉表示。
- 使用原因: 视觉编码器能够捕捉图像的关键视觉特征。
特征2: 利用ChatGPT根据设计好的提示生成诊断类别的主要症状描述。
- 使用原因: 症状描述增加了文本信息,有助于模型理解和识别图像中的医学特征。
特征3: 使用CLIP的文本编码器将症状描述转换为文本表示。
- 使用原因: 文本编码器将自然语言转换成机器可处理的编码,使之可以与视觉表示相结合进行相似度比较。
特征4: 定义一个评分函数来计算图像-文本对的相似度。
- 使用原因: 通过量化图像与文本描述的相似性,可以为分类提供依据。
如何使用CLIP模型和ChatGPT来进行零样本医学图像分类
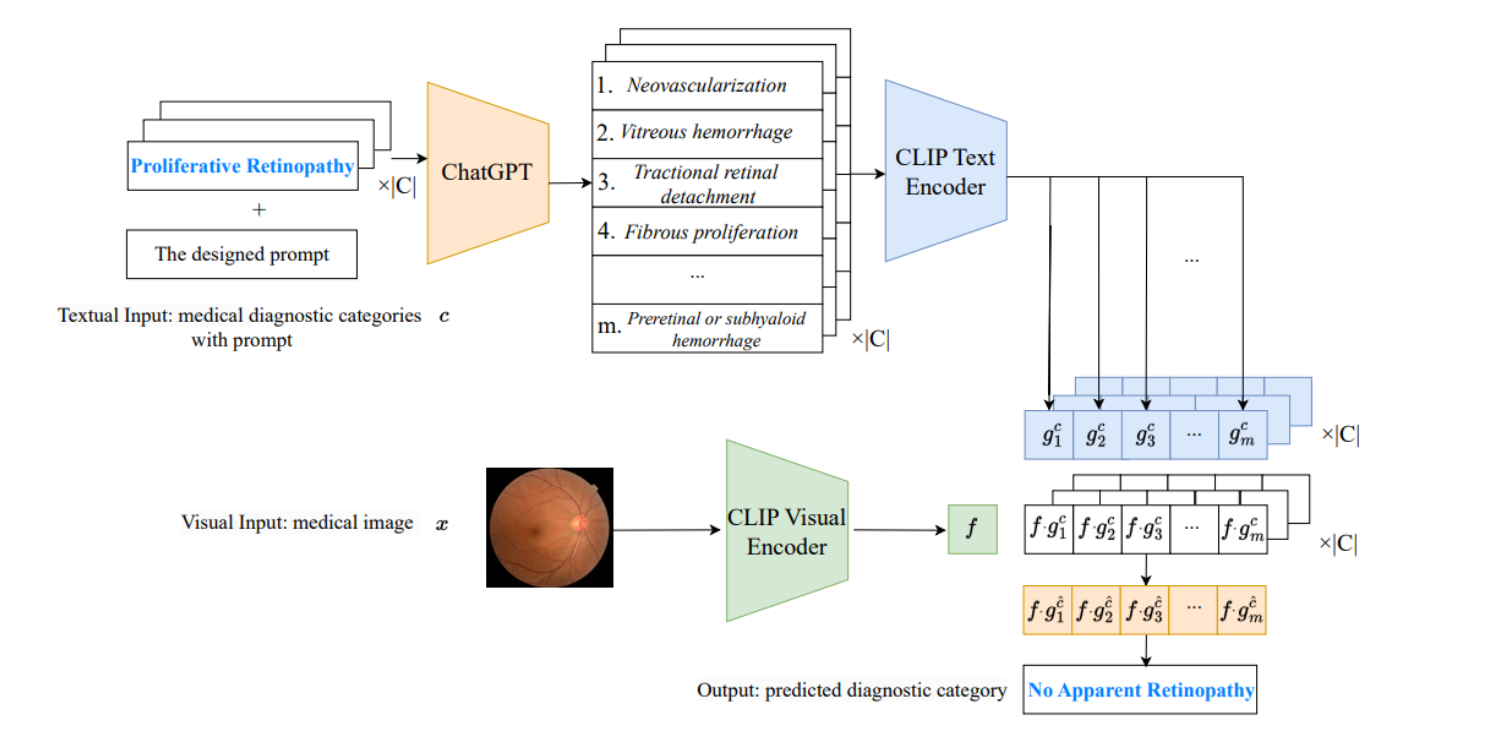
- 文本输入:首先,将医学诊断类别(如"proliferative retinopathy")和设计的提示输入到ChatGPT模型。
- ChatGPT输出:ChatGPT根据输入生成与诊断类别相关的主要症状描述列表,如图中的1到m个不同的症状。
- 视觉输入:同时,医学图像作为视觉输入,通过CLIP的视觉编码器处理,生成视觉特征表示f。
- CLIP文本编码器:生成的症状描述(如图中的neovascularization,vitreous hemorrhage等)通过CLIP的文本编码器转换为文本特征表示g。
- 相似性计算:图像的视觉表示f和每个症状描述的文本表示g计算点积,得到一个相似性得分。
- 输出:所有相似性得分进行平均,最终得到的得分最高的类别(如图中显示的"No Apparent Retinopathy")被认为是图像的预测诊断类别。
这个方法提供了一个无需训练的框架,可以直接利用预训练的VLM和LLM进行医学图像的诊断。
通过结合图像的视觉特征和文本描述的症状,该方法可以识别出图像所代表的医学类别,从而实现零样本分类。
用特定提示查询ChatGPT所生成的医学视觉特征描述
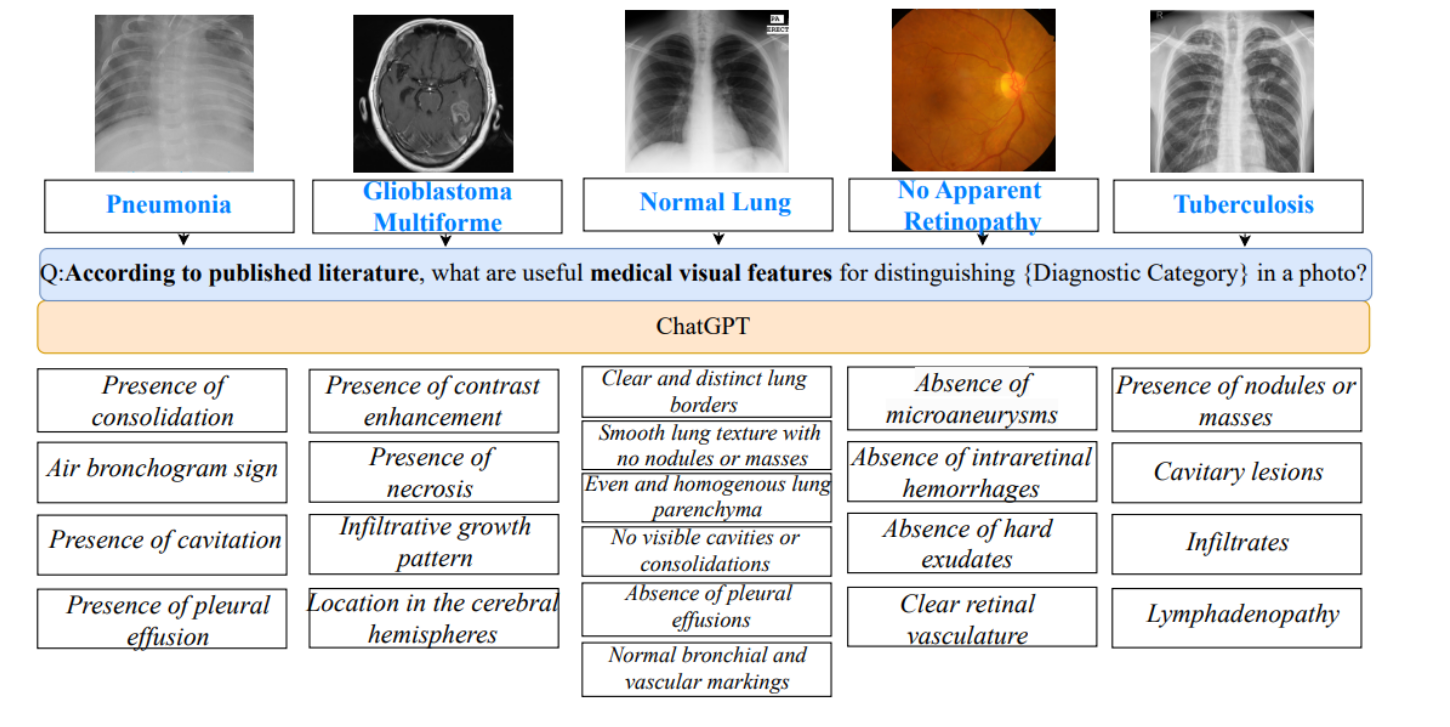
这些描述用于帮助区分不同的诊断类别,例如肺炎、多形性胶质母细胞瘤、正常肺、没有明显的视网膜病变和结核病。
每个诊断类别下面都列出了ChatGPT根据文献生成的几个关键视觉特征。
相似性得分在不同症状上的可视化,用于解释模型的预测
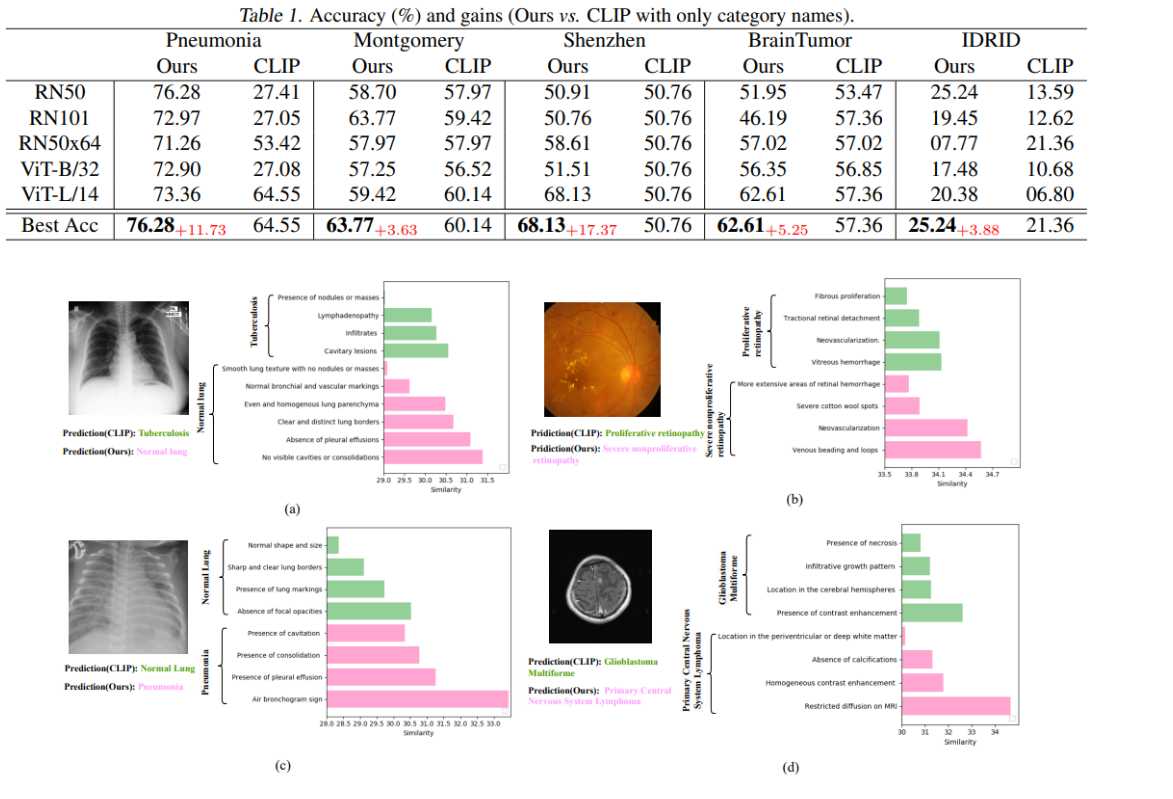
图中的不同颜色条形表示图像与每个症状描述之间的相似度。
通过比较正确类别和CLIP错误推理的类别的相似度,展示了该框架准确性的来源。
注意力图的可视化
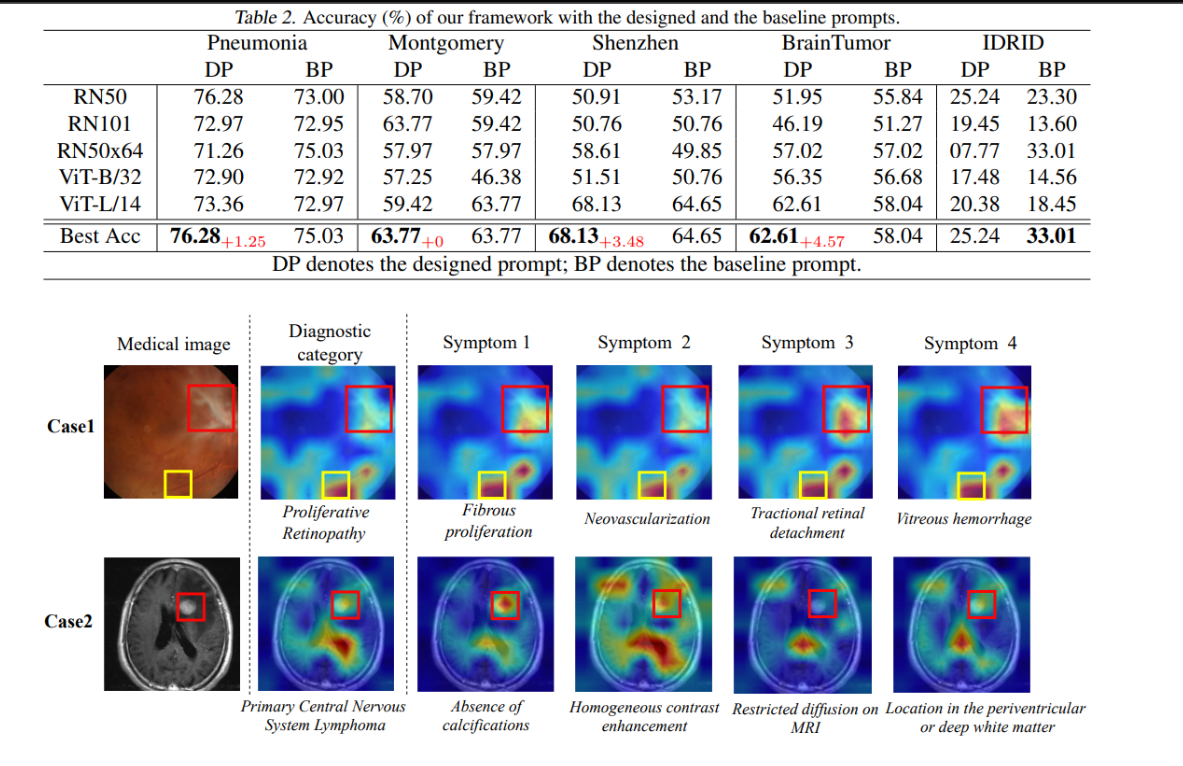
这些注意力图结合了医学图像和ChatGPT生成的文本描述。
它们展示了模型在识别不同病症时关注图像的哪些区域,例如在诊断增生性视网膜病变时关注到了纤维增生、新生血管形成、牵拉性视网膜脱离和玻璃体出血等特征。
对比使用设计的提示和基线提示时的注意力图
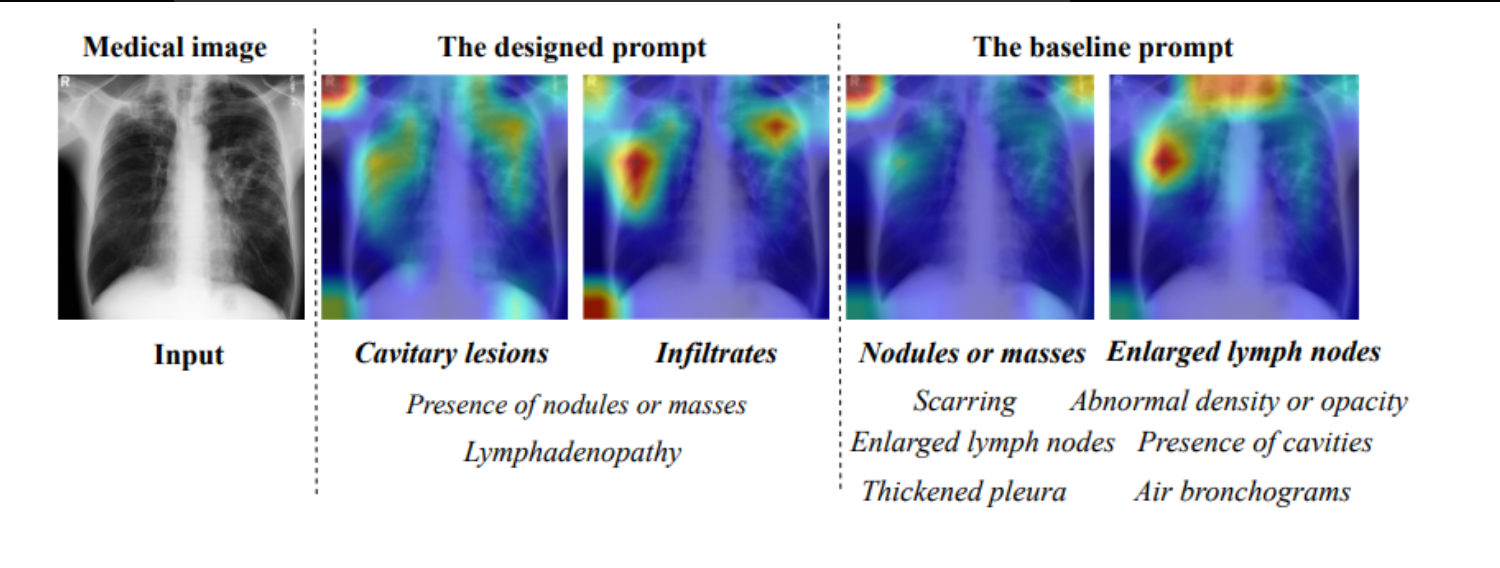
可以看到,不同提示生成的注意力焦点有所不同,说明提示设计对于模型关注的区域和诊断有显著影响。
关键点
- 特征1:使用预训练的视觉-语言模型(如CLIP),利用其强大的图像和文本联合理解能力。
- 特征2:结合大型语言模型(如ChatGPT)自动生成的文本描述,增加了对未见类别的描述性知识。
- 特征3:设计特定的提示来优化ChatGPT生成的文本描述,提高其与医学图像相关性和准确性。
为ChatGPT选择和设计提示的细节
-
设计原则:设计提示时,首先确保使用医学领域内精确的术语。例如,如果是关于肺炎的提示,我们会使用“渗透”、“结节”等具体术语,而不是笼统的“异常”。
此外,提示应该引导生成具体可见的病理特征描述,这些描述能够直观反映在图像上。
-
优化过程:通过逐步细化提示的语言,我们优化ChatGPT的输出。开始可能是一个简单的提示,如“描述肺炎的X射线图像特点”,然后根据生成的描述的质量,我们可能会添加更多具体性,如“描述细菌性肺炎在X射线图像上的表现”。
-
实际例子:在处理肺结核的分类任务时,我们可能会设计这样一个提示:“列出在肺结核患者的胸部X射线图像中可能观察到的特征”。
ChatGPT可能会响应:“典型的肺尖部阴影和空洞形成”。
CLIP模型的视觉和文本编码器处理医学图像的方式
-
视觉编码器:CLIP的视觉编码器采用深度卷积网络,它通过学习大量图像数据,能够从医学图像中提取出代表性的特征,如肺部的阴影区域、肺纹理的变化等。
-
文本编码器:文本编码器则将ChatGPT生成的描述转化为与视觉特征相匹配的文本表示。
它通过语义理解,将“空洞形成”等词汇编码为模型可以与视觉特征对比的形式。
-
特征整合:CLIP通过注意力机制,将视觉特征与文本特征相结合。
例如,如果文本描述提到“肺尖部阴影”,模型的注意力机制会特别关注图像中相应区域的特征,以确保高度的匹配度。
多模态处理能力
图像与文本的融合:在CLIP中,视觉和文本的融合通过一个多模态变换器实现,它允许模型理解文本描述中的医学信息,并与图像中的相应视觉特征相结合。
注意力机制
注意力分配:在处理包含肺结核特征的X射线图像时,模型的注意力分配可能集中在图像的上部区域,因为肺结核往往在肺尖更容易表现出来。
注意力可视化:我们可以通过生成的热图看到,模型在肺尖区域的注意力明显增强,这与医学知识是一致的。
特征激活与识别
特征激活图:特征激活图展示了在识别含有肺结核特征的图像时,哪些卷积层被激活,反映出模型如何识别肺尖阴影和空洞等关键特征。
病理特征的自动标识:模型通过训练学会识别典型的肺结核病理特征,例如通过增强的边缘检测网络来自动标识空洞形成的区域。
决策过程的解释性
解释模型输出
通过将模型的分类决策与生成的文本描述和注意力机制的可视化相结合,我们能够提供一个全面的解释框架。
这种方法允许我们不仅展示模型如何“看到”图像中的特定病理特征,还能解释它为何将这些特征与特定的医学诊断相联系。
-
生成文本描述的利用:当ChatGPT生成的文本描述被用作模型分类的一部分时,这些描述本身就提供了关于模型决策过程的直接见解。
例如,如果模型将一张X射线图像分类为显示肺炎特征,生成的文本可能包括“双肺见散在斑片状阴影”,这直接指向了模型识别的特定病理标记。
-
注意力机制的可视化:通过将注意力机制的输出以热图的形式可视化,我们可以展示模型在图像中关注的区域。
这种可视化直观地证明了模型是如何根据文本描述中的关键词(如“阴影”或“增厚”)来定位图像中的相应区域。
-
与医学知识库的结合:将模型的预测与现有的医学知识库相结合,可以进一步增强解释性。
例如,模型识别的图像特征和病理标记可以与医学数据库中的类似案例进行比较,从而为模型的决策提供额外的验证。
模型调整与优化
-
超参数调整:通过调整模型的超参数,如学习率或正则化因子,我们可以改变模型的学习过程和最终的注意力分配。
这一调整过程需要基于模型在验证集上的表现来进行,以确保找到最优的参数设置,从而提高模型在新图像上的准确性和解释性。
-
模型微调:对于具体的医学图像分类任务,模型可能需要针对特定的数据集进行微调。
这一过程包括在特定医学图像数据集上继续训练模型,以调整其权重,使之更好地适应任务。微调后的模型能够更准确地识别特定病理特征,同时也可能提供更加直观的解释。