曾梦想执剑走天涯,我是程序猿【AK】
目录
- 简述概要
- 知识图谱
- 决策树(Decision Tree)
- 随机森林(Random Forest)
简述概要
了解决策树和随机森林
知识图谱
决策树和随机森林都是机器学习中常用的算法,它们在处理分类和回归问题时表现出色。下面分别详解决策树和随机森林的相关概念和工作原理。
决策树(Decision Tree)
决策树是一种基于树形结构的机器学习模型,用于解决分类和回归问题。它通过递归地将数据集划分成更小的子集来工作,每个子集对应决策树中的一个节点。决策树的每个内部节点表示一个特征属性上的判断条件,每个分支代表一个可能的属性值,每个叶节点代表一个类别(对于分类问题)或一个具体数值(对于回归问题)。
构建决策树的关键步骤包括特征选择、决策树生成和剪枝。
- 特征选择:选择最优划分特征,常用的准则有信息增益、增益率和基尼指数。
- 决策树生成:根据选择的特征和阈值,递归地生成决策树。常见的决策树生成算法有ID3、C4.5和CART。
- 剪枝:为了防止过拟合,可以通过剪枝来简化决策树。剪枝分为预剪枝和后剪枝两种。
随机森林(Random Forest)
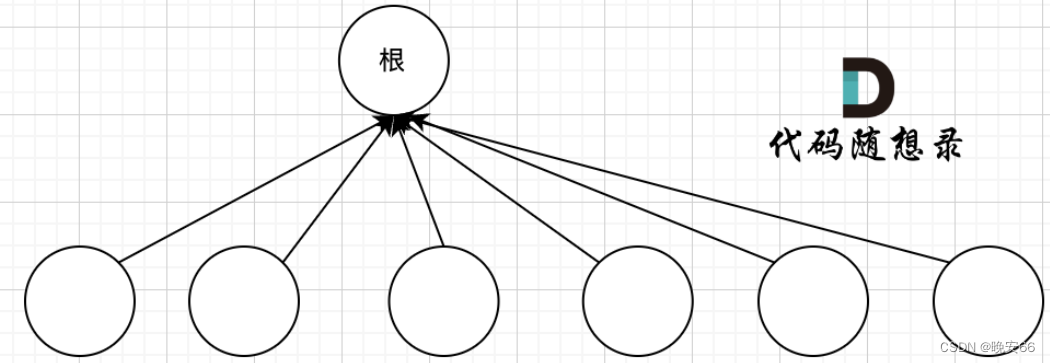
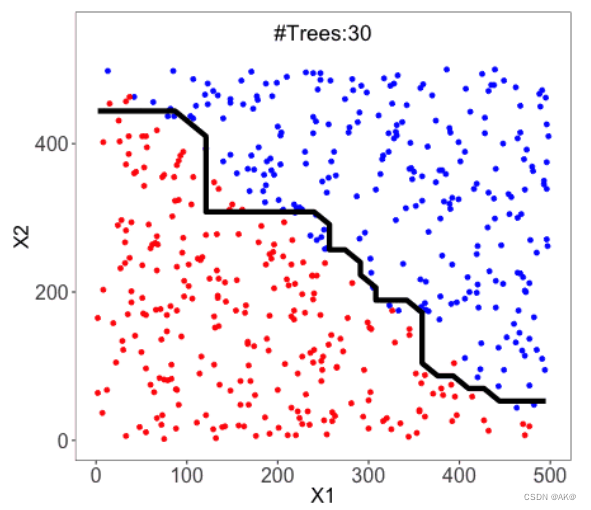
随机森林是一种基于决策树的集成学习算法,它通过构建多个决策树并结合它们的输出来提高模型的泛化能力。随机森林的基本思想是利用多个弱学习器(即决策树)来构建一个强学习器。
随机森林的构建过程如下:
- 采样:从原始数据集中采用有放回抽样(Bootstrap)的方式抽取多个样本子集。
- 构建决策树:对每个样本子集独立地构建决策树。在构建过程中,通常会随机选择一部分特征进行划分,以增加模型的多样性。
- 集成:将多棵决策树的输出进行集成,通常采用投票或平均的方式得到最终的预测结果。
随机森林的优点包括:
- 精度高:由于集成了多个决策树,随机森林通常具有较高的预测精度。
- 鲁棒性强:对噪声和异常值不敏感,能够自动处理缺失值。
- 可解释性好:可以输出特征的重要性排序,有助于理解数据的特征。
- 并行化计算:可以并行地构建多棵决策树,提高计算效率。
总的来说,决策树是一种基于树形结构的分类和回归模型,而随机森林则是通过集成多个决策树来提高模型性能的集成学习算法。两者在机器学习中都有广泛的应用。
推荐链接:
https://www.nvidia.cn/glossary/data-science/random-forest/
https://rstudio-pubs-static.s3.amazonaws.com/304821_b150e48de7bb4252aa1ffcfd51f5ba61.html
https://guomin-h-a.github.io/2020/02/21/decision-tree-and-random-forest/
https://geek-docs.com/machine-learning/machine-learning-tutorial/random-forests.html
---- 永不磨灭的番号:我是AK