深入理解Flink Sql执行流程
- 1 Flink SQL 解析引擎
- 1.1SQL解析器
- 1.2Calcite处理流程
- 1.2.1 SQL 解析阶段(SQL–>SqlNode)
- 1.2.2 SqlNode 验证(SqlNode–>SqlNode)
- 1.2.3 语义分析(SqlNode–>RelNode/RexNode)
- 1.2.4 优化阶段(RelNode–>RelNode)
- 1.2.5 生成ExecutionPlan
- 1.3 Calcite 优化器
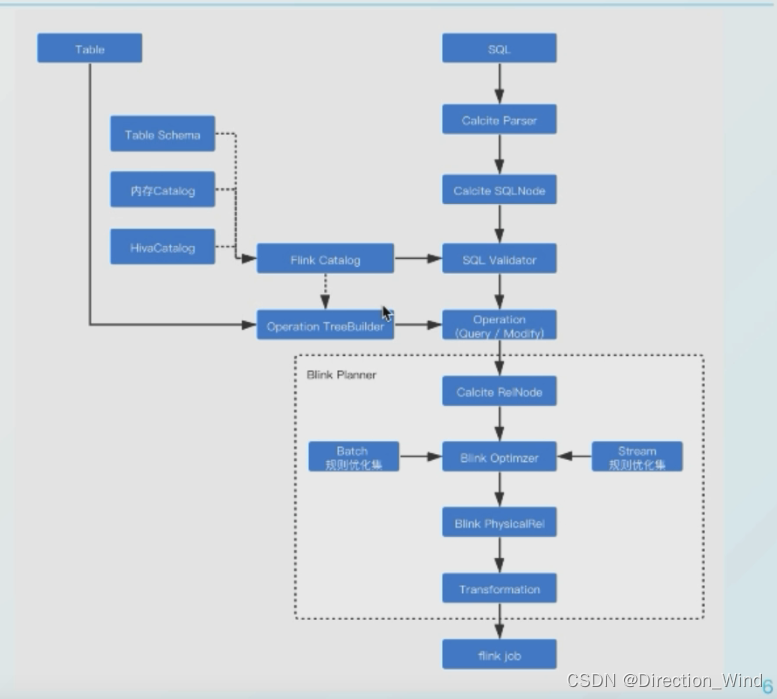
- 2. 简述 Flink Table/SQL 执行流程
- 2.1 Flink Sql 执行流程
- 2.3 Flink Table/SQL 执行流程 的 异同
- 3. 以 Flink SQL Demo 为切入,深入理解 Flink Streaming SQL
- 3.1以官网的代码为例
- 3.3 结合 Flink SQL 执行流程 及 调试 详细说明
- 3.3.1 预览 AST、Optimized Logical Plan、Physical Execution Plan
- 3.3.2 SQL 解析阶段(SQL–>SqlNode)
- 3.3.3 SqlNode 验证(SqlNode–>SqlNode)
- 3.3.4 语义分析(SqlNode–>RelNode/RexNode)
- 3.3.5 优化阶段(Logical RelNode–>FlinkLogicalRel)
- 3.3.5.1 FlinkRuleSets
- Flink 逻辑计划优化
- 3.3.6 生成物理计划(LogicalRelNode–>Physic Plan)
- 3.3.7 生成DataStream(Physic Plan–>DataStream)
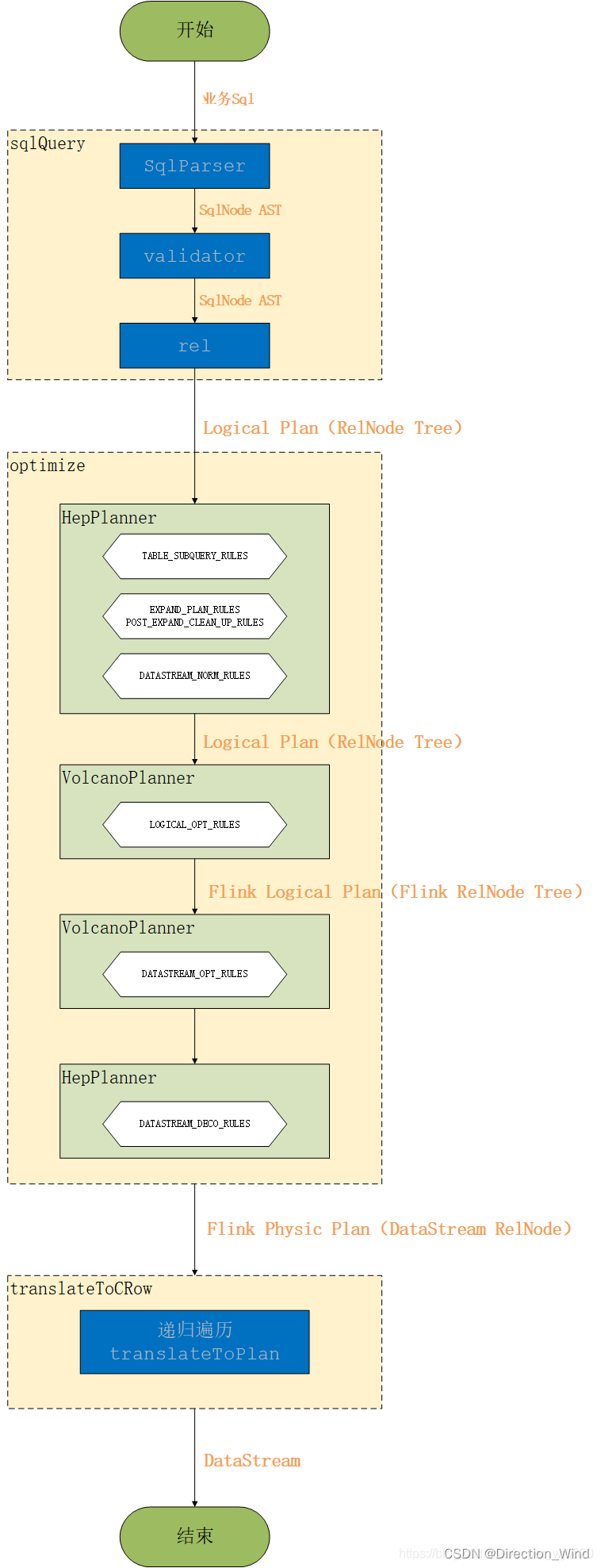
- 3.4 总结Flink Sql执行流程
- 4. catalog相关概念
- 4.1 flink中的catalog
- 4.2 catalog中 表的管理,临时表 永久表
- 5 开发中遇到问题想查询源码如何查询
- 引用
1 Flink SQL 解析引擎
1.1SQL解析器
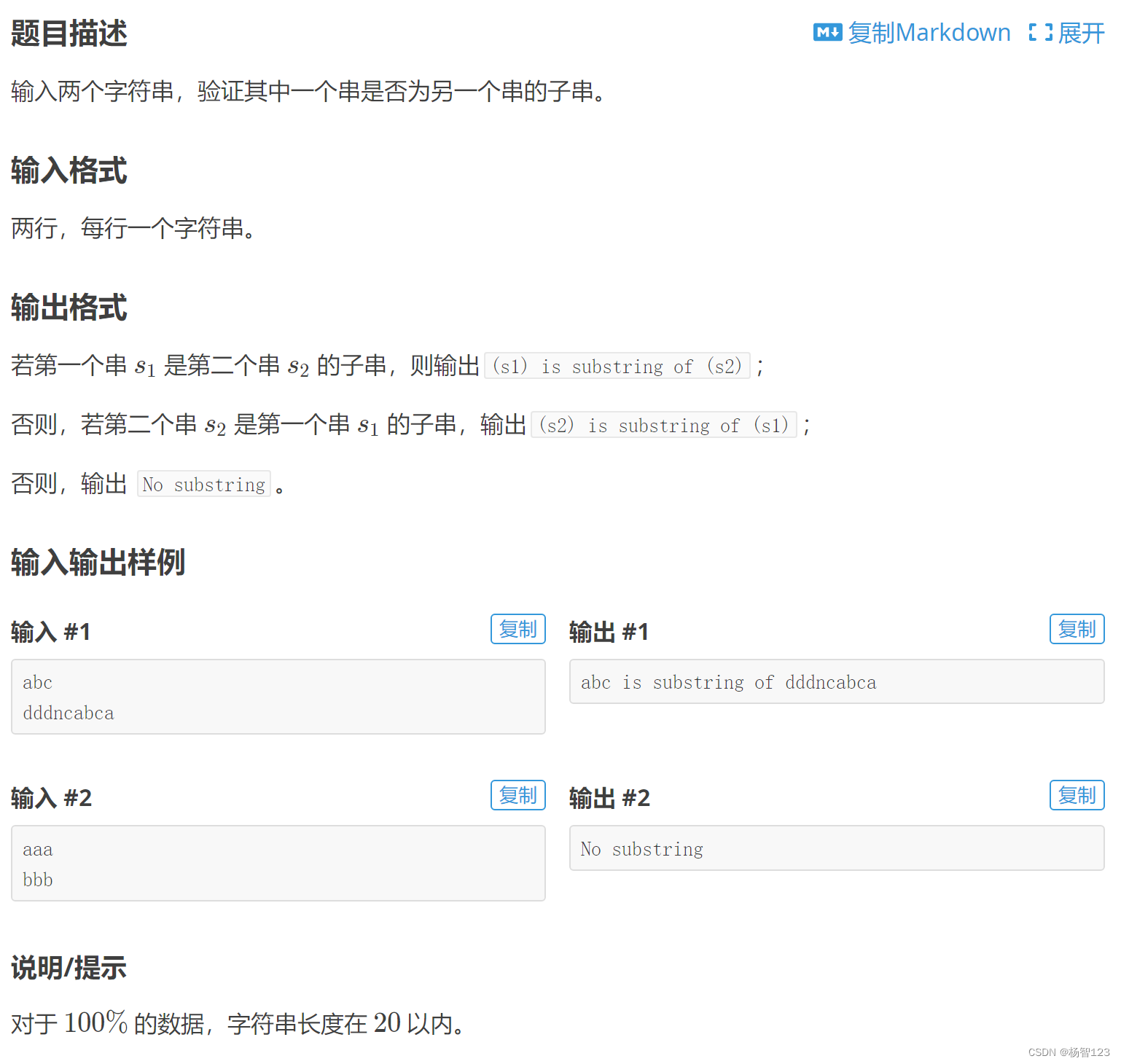
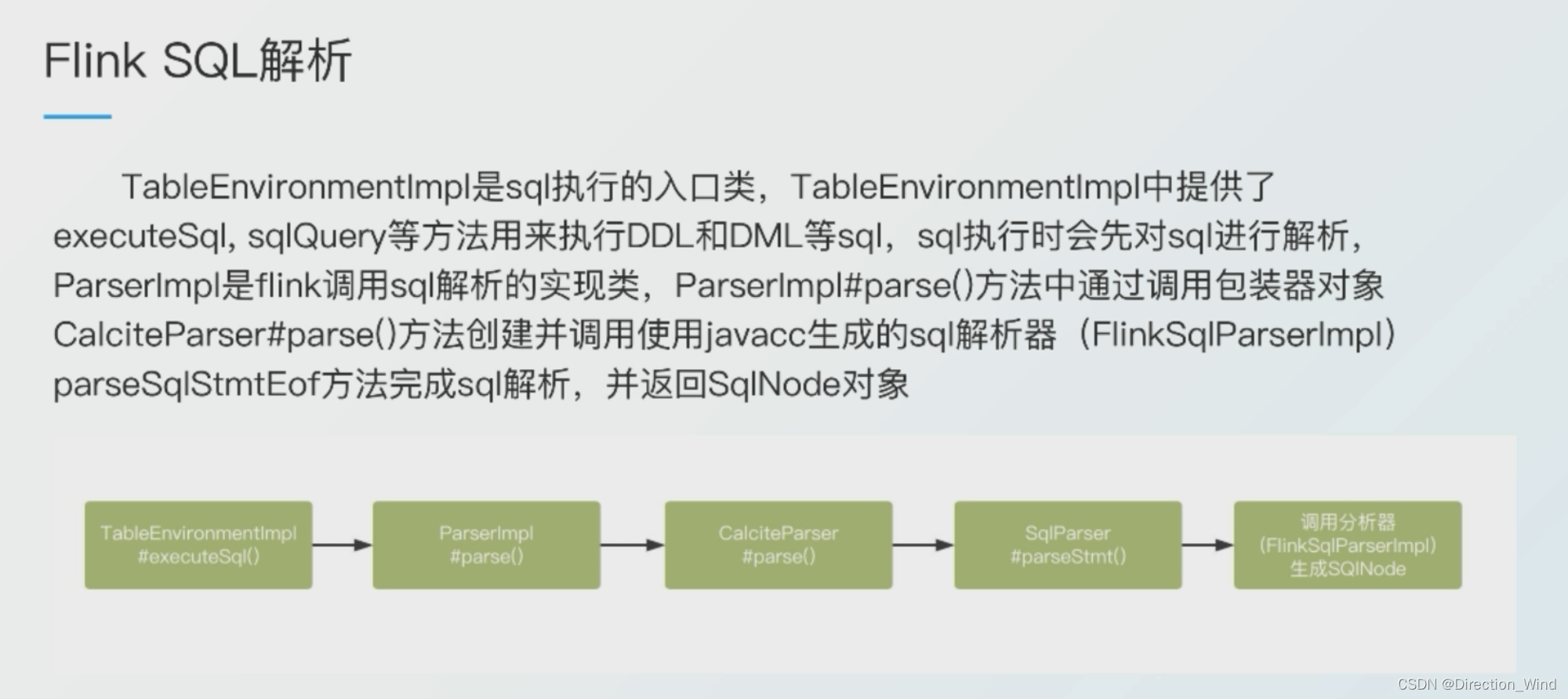
flink在执行sql语句时,是无法像java/scala代码一样直接去使用的,需要解析成电脑可以执行的语言,对sql语句进行解析转化。
 这里说的我感觉其实不是特别准确,应该是 flink使用的是一款开源SQL解析工具Apache Calcite ,Calcite使用Java CC对sql语句进行了解析。
这里说的我感觉其实不是特别准确,应该是 flink使用的是一款开源SQL解析工具Apache Calcite ,Calcite使用Java CC对sql语句进行了解析。

那么我们先来简单说下Calcite工具,梳理一下Calcite的基本概念:
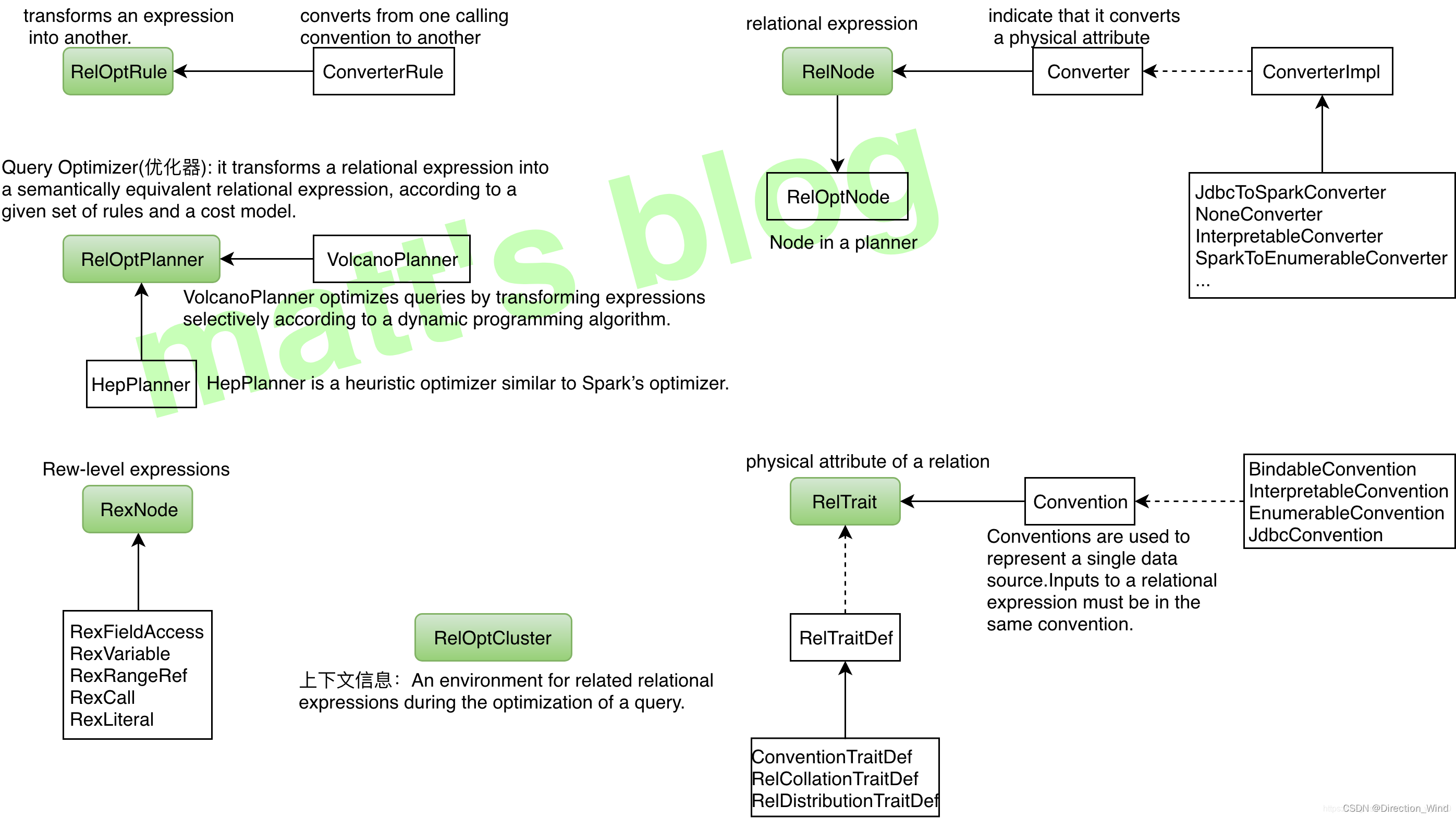

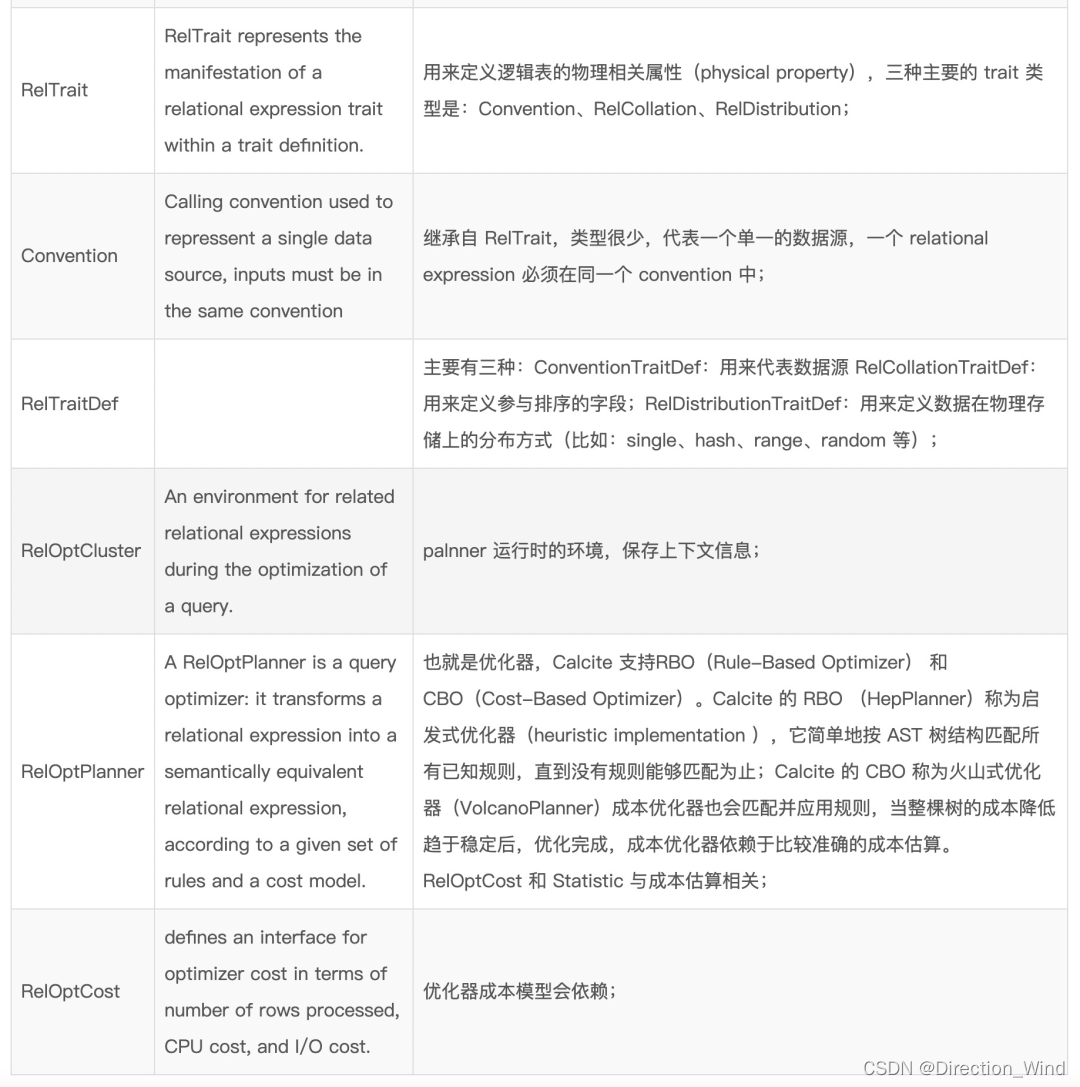
上述图片中具体的概念解释为:
1.2Calcite处理流程
Sql 的执行过程一般可以分为下图中的四个阶段,Calcite 同样也是这样
解析 校验 优化 执行:

对于flink中解析的流程为:
这里为了讲述方便,把 SQL 的执行分为下面五个阶段(跟上面比比又独立出了一个阶段):
1.2.1 SQL 解析阶段(SQL–>SqlNode)
Calcite 使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的 Parser.jj 文件,生成一系列的 java 代码,生成的 Java 代码会把 SQL 转换成 AST 的数据结构(这里是 SqlNode 类型)。
Javacc 实现一个 SQL Parser,它的功能有以下两个,这里都是需要在 jj 文件中定义的。
- List item设计词法和语义,定义 SQL 中具体的元素;
- 实现词法分析器(Lexer)和语法分析器(Parser),完成对 SQL 的解析,完成相应的转换。
即:把 SQL 转换成为 AST (抽象语法树),在 Calcite 中用 SqlNode 来表示;
1.2.2 SqlNode 验证(SqlNode–>SqlNode)

经过上面的第一步,会生成一个 SqlNode 对象,它是一个未经验证的抽象语法树,下面就进入了一个语法检查阶段,语法检查前需要知道元数据信息,这个检查会包括表名、字段名、函数名、数据类型的检查。
即:语法检查,根据元数据信息进行语法验证,验证之后还是用 SqlNode 表示 AST 语法树。具体为使用catalogReaderSupplier创建一个validator,之后验证validator与sqlnode的区别,如果都能找到相应的,就说明语法没有写错的地方
1.2.3 语义分析(SqlNode–>RelNode/RexNode)
经过第二步之后,这里的 SqlNode 就是经过语法校验的 SqlNode 树,接下来这一步就是将 SqlNode 转换成 RelNode/RexNode,也就是生成相应的逻辑计划(Logical Plan)
即:语义分析,根据 SqlNode及元信息构建 RelNode 树,也就是最初版本的逻辑计划(Logical Plan);
1.2.4 优化阶段(RelNode–>RelNode)
第四阶段,也就是 Calcite 的核心所在,优化器进行优化的地方,如过滤条件的下压(push down),在进行 join 操作前,先进行 filter 操作,这样的话就不需要在 join 时进行全量 join,减少参与 join 的数据量等。
在 Calcite 中,提供了两种 planner:HepPlanner 和 VolcanoPlanner,详细可参考下文。
即:逻辑计划优化,优化器的核心,根据前面生成的逻辑计划按照相应的规则(Rule)进行优化;
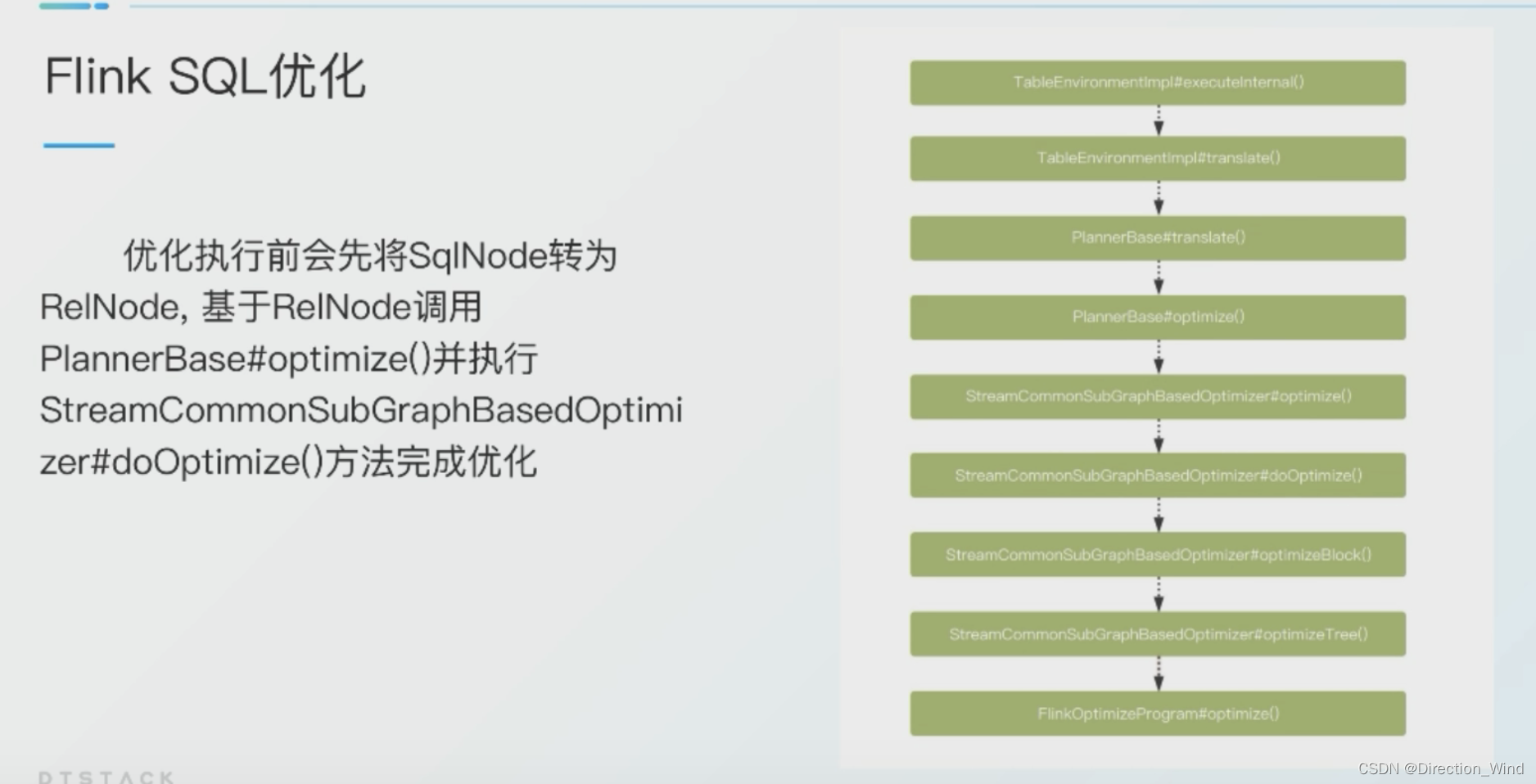
1.2.5 生成ExecutionPlan
这步就是讲最终的执行计划转为Graph图,下面的流程与真正的java代码流程就一致了
1.3 Calcite 优化器
优化器的作用:将解析器生成的关系代数表达式转换成执行计划,供执行引擎执行,在这个过程中,会应用一些规则优化,以帮助生成更高效的执行计划。
Calcite 中 RelOptPlanner 是 Calcite 中优化器的基类:
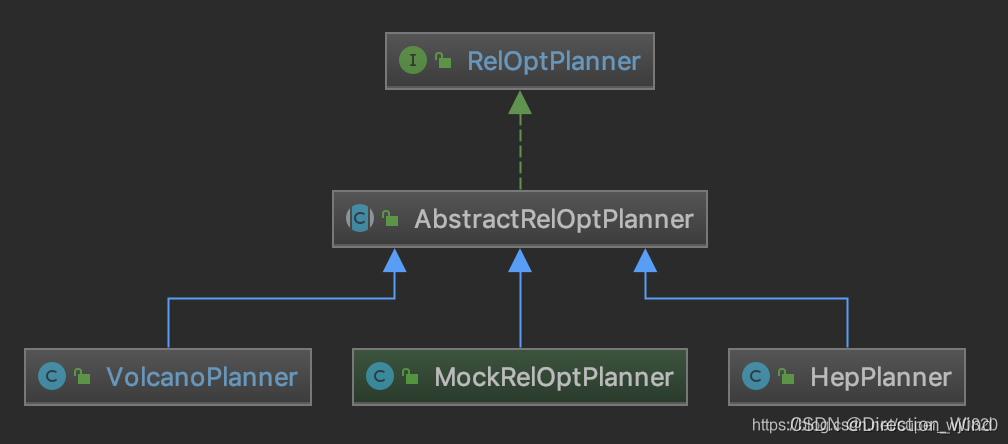
Calcite 中关于优化器提供了两种实现:
HepPlanner:就是基于规则优化RBO 的实现,它是一个启发式的优化器,按照规则进行匹配,直到达到次数限制(match 次数限制)或者遍历一遍后不再出现 rule match 的情况才算完成;
VolcanoPlanner:就是基于成本优化CBO 的实现,它会一直迭代 rules,直到找到 cost 最小的 paln。
阿里的blink 就在sql优化的部分做了大量的工作,包括微批 ,TopN,热点,去重等部分在底层算法做了大量优化,经过实测,7天窗口的情况下,半小时滚动窗口做聚合运算,甚至比直接使用process API的性能更优,使用的资源更小
2. 简述 Flink Table/SQL 执行流程
Flink Table API&SQL 为流式数据和静态数据的关系查询保留统一的接口,而且利用了Calcite的查询优化框架和SQL parser。
该设计是基于Flink已构建好的API构建的,Flink的 core API 和引擎的所有改进都会自动应用到Table API和SQL上。
下面是两种视图的执行流程,从两个方向介绍了处理操作:
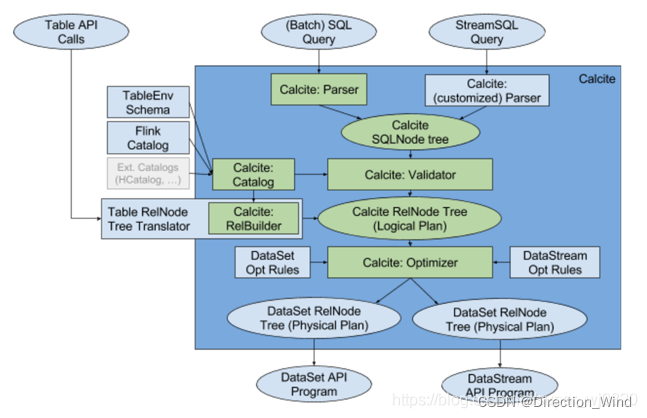
2.1 Flink Sql 执行流程
一条stream sql从提交到calcite解析、优化最后到flink引擎执行,一般分为以下几个阶段:
- Sql Parser: 将sql语句通过java cc解析成AST(语法树),在calcite中用SqlNode表示AST;
- Sql Validator: 结合数字字典(catalog)去验证sql语法;
- 生成Logical Plan: 将sqlNode表示的AST转换成LogicalPlan, 用relNode表示;
- 生成 optimized LogicalPlan: 先基于calcite rules 去优化logical Plan,再基于flink定制的一些优化rules去优化logical Plan;
- 生成Flink PhysicalPlan: 这里也是基于flink里头的rules,将optimized LogicalPlan转成成Flink的物理执行计划;
- 将物理执行计划转成Flink ExecutionPlan: 就是调用相应的tanslateToPlan方法转换和利用CodeGen元编程成Flink的各种算子。
2.3 Flink Table/SQL 执行流程 的 异同
可以看出来,Table API 与 SQL 在获取 RelNode 之后是一样的流程,只是获取 RelNode 的方式有所区别:
- Table API :通过使用 RelBuilder来拿到RelNode(LogicalNode与Expression分别转换成RelNode与RexNode),具体实现这里就不展开了;
- SQL :通过使用Planner。首先通过parse方法将用户使用的SQL文本转换成由SqlNode表示的parse tree。接着通过validate方法,使用元信息来resolve字段,确定类型,验证有效性等等。最后通过rel方法将SqlNode转换成RelNode;
在flink提供两种API进行关系型查询,Table API 和 SQL。这两种API的查询都会用包含注册过的Table的catalog进行验证,除了在开始阶段从计算逻辑转成logical plan有点差别以外,之后都差不多。同时在stream和batch的查询看起来也是完全一样。只不过flink会根据数据源的性质(流式和静态)使用不同的规则进行优化, 最终优化后的plan转传成常规的Flink DataSet 或 DataStream 程序。
3. 以 Flink SQL Demo 为切入,深入理解 Flink Streaming SQL
3.1以官网的代码为例
代码:
package apps.alg;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
/**
* Simple example for demonstrating the use of SQL on a Stream Table in Java.
*
* <p>This example shows how to:
* - Convert DataStreams to Tables
* - Register a Table under a name
* - Run a StreamSQL query on the registered Table
*
*/
public class test {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
// set up execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStream<Order> orderA = env.fromCollection(Arrays.asList(
new Order(1L, "beer", 3),
new Order(1L, "diaper", 4),
new Order(3L, "rubber", 2)));
DataStream<Order> orderB = env.fromCollection(Arrays.asList(
new Order(2L, "pen", 3),
new Order(2L, "rubber", 3),
new Order(4L, "beer", 1)));
// register DataStream as Table
tEnv.registerDataStream("OrderA", orderA, "user, product, amount");
tEnv.registerDataStream("OrderB", orderB, "user, product, amount");
// union the two tables
Table result = tEnv.sqlQuery("SELECT " +
"* " +
"FROM " +
"( " +
"SELECT " +
"* " +
"FROM " +
"OrderA " +
"WHERE " +
"user < 3 " +
"UNION ALL " +
"SELECT " +
"* " +
"FROM " +
"OrderB " +
"WHERE " +
"product <> 'rubber' " +
") OrderAll " +
"WHERE " +
"amount > 2");
System.out.println(tEnv.explain(result));
tEnv.toAppendStream(result, Order.class).print();
env.execute();
}
// *************************************************************************
// USER DATA TYPES
// *************************************************************************
/**
* Simple POJO.
*/
public static class Order {
public Long user;
public String product;
public int amount;
public Order() {
}
public Order(Long user, String product, int amount) {
this.user = user;
this.product = product;
this.amount = amount;
}
@Override
public String toString() {
return "Order{" +
"user=" + user +
", product='" + product + '\'' +
", amount=" + amount +
'}';
}
}
}
引入pom:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency
如果要在IDEA中执行调试 可以参考
https://blog.csdn.net/Direction_Wind/article/details/122843896
这篇帖子操作
表OrderA定义三个字段:user, product, amount,先分别做select查询,再将查询结果 union,最后做select,最外层加了一个Filter,以便触发Filter下推及合并。运行代码的结果为:
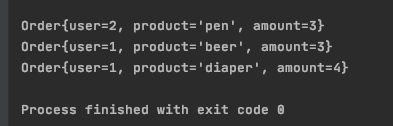
3.3 结合 Flink SQL 执行流程 及 调试 详细说明
3.3.1 预览 AST、Optimized Logical Plan、Physical Execution Plan
程序方法可以打印 待执行Sql的抽象语法树(Abstract Syntax Tree)、优化后的逻辑计划以及物理计划:
== Abstract Syntax Tree ==
== Optimized Logical Plan ==
== Physical Execution Plan ==
== Abstract Syntax Tree ==
LogicalProject(user=[$0], product=[$1], amount=[$2])
+- LogicalFilter(condition=[>($2, 2)])
+- LogicalUnion(all=[true])
:- LogicalProject(user=[$0], product=[$1], amount=[$2])
: +- LogicalFilter(condition=[<($0, 3)])
: +- LogicalTableScan(table=[[default_catalog, default_database, OrderA]])
+- LogicalProject(user=[$0], product=[$1], amount=[$2])
+- LogicalFilter(condition=[<>($1, _UTF-16LE'rubber')])
+- LogicalTableScan(table=[[default_catalog, default_database, OrderB]])
== Optimized Logical Plan ==
Union(all=[true], union=[user, product, amount])
:- Calc(select=[user, product, amount], where=[AND(<(user, 3), >(amount, 2))])
: +- DataStreamScan(table=[[default_catalog, default_database, OrderA]], fields=[user, product, amount])
+- Calc(select=[user, product, amount], where=[AND(<>(product, _UTF-16LE'rubber':VARCHAR(2147483647) CHARACTER SET "UTF-16LE"), >(amount, 2))])
+- DataStreamScan(table=[[default_catalog, default_database, OrderB]], fields=[user, product, amount])
== Physical Execution Plan ==
Stage 1 : Data Source
content : Source: Collection Source
Stage 2 : Data Source
content : Source: Collection Source
Stage 3 : Operator
content : SourceConversion(table=[default_catalog.default_database.OrderA], fields=[user, product, amount])
ship_strategy : FORWARD
Stage 4 : Operator
content : Calc(select=[user, product, amount], where=[((user < 3) AND (amount > 2))])
ship_strategy : FORWARD
Stage 5 : Operator
content : SourceConversion(table=[default_catalog.default_database.OrderB], fields=[user, product, amount])
ship_strategy : FORWARD
Stage 6 : Operator
content : Calc(select=[user, product, amount], where=[((product <> _UTF-16LE'rubber':VARCHAR(2147483647) CHARACTER SET "UTF-16LE") AND (amount > 2))])
ship_strategy : FORWARD
3.3.2 SQL 解析阶段(SQL–>SqlNode)
和前面介绍的 Calcite 处理流程一致,此处Flink解析Flink SQL 的语法和词法解析 完全依赖Calcite提供的SqlParser。
在 tEnv.sqlQuery() 方法中,下面的 Step-1 即为SQL解析过程,入参为 待解析的SQL,返回解析后的 SqlNode 对象。
*TableEnvironment.scala*
def sqlQuery(query: String): Table = {
val planner = new FlinkPlannerImpl(getFrameworkConfig, getPlanner, getTypeFactory)
// Step-1: SQL 解析阶段(SQL–>SqlNode), 把 SQL 转换成为 AST (抽象语法树),在 Calcite 中用 SqlNode 来表示
val parsed = planner.parse(query)
if (null != parsed && parsed.getKind.belongsTo(SqlKind.QUERY)) {
// Step-2: SqlNode 验证(SqlNode–>SqlNode),语法检查,根据元数据信息进行语法验证,验证之后还是用 SqlNode 表示 AST 语法树;
val validated = planner.validate(parsed)
// Step-3: 语义分析(SqlNode–>RelNode/RexNode),根据 SqlNode及元信息构建 RelNode 树,也就是最初版本的逻辑计划(Logical Plan)
val relational = planner.rel(validated)
new Table(this, LogicalRelNode(relational.rel))
} else {
...
}
}
被解析后的SqlNode AST,每个SQL组成会翻译成一个节点:
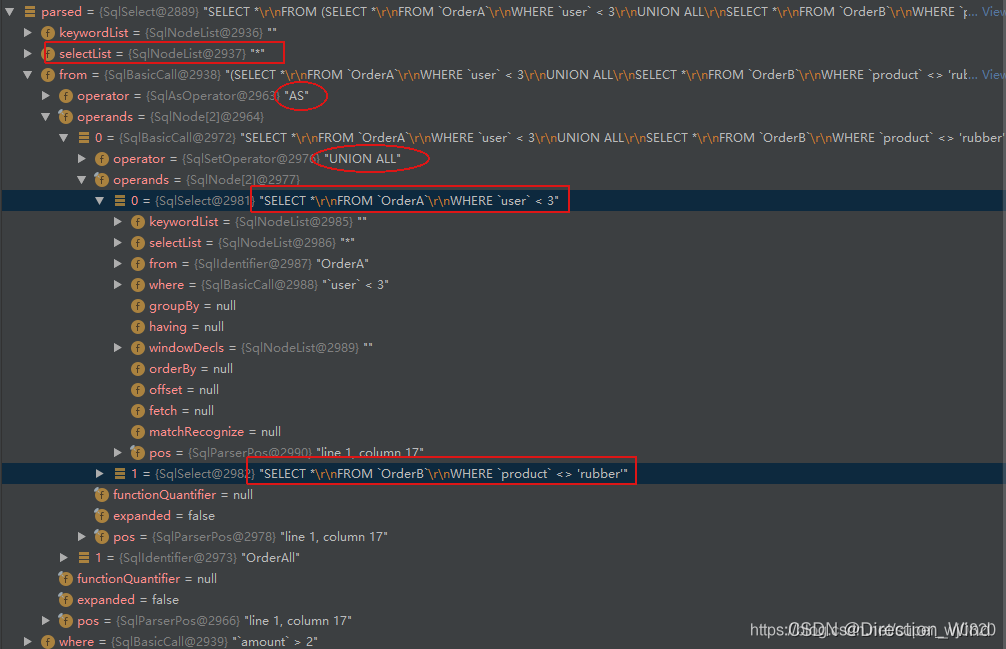
可以看出来 如果开启了并行 ,unionall两遍的语句是在同一个顺序级别的,对解析器而言是两个相同的操作。
3.3.3 SqlNode 验证(SqlNode–>SqlNode)
SQL在被SqlParser解析后,得到SqlNode组成的 抽象语法树(AST),此后还要根据注册的Catalog对该 SqlNode AST 进行验证。
以下语句注册表OrderA和OrderB:
tEnv.registerDataStream(“OrderA”, orderA, “user, product, amount”);
tEnv.registerDataStream(“OrderB”, orderB, “user, product, amount”);
Step-2 即为SQL解析过程,入参为 待验证的SqlNode AST,返回验证后的 SqlNode 对象。
相对于Calcite原生的SQL校验,Flink拓展了语法校验范围,如Flink支持自定义的FunctionCatalog,用于校验SQL Function的入参个数及类型的相关校验,具体用法和细节后续补充。
下面为SQL校验的过程:
**FlinkPlannerImpl.scala**
private def validate(sqlNode: SqlNode, validator: FlinkCalciteSqlValidator): SqlNode = {
try {
sqlNode.accept(new PreValidateReWriter(
validator, typeFactory))
// do extended validation.
sqlNode match {
case node: ExtendedSqlNode =>
node.validate()
case _ =>
}
// no need to validate row type for DDL and insert nodes.
if (sqlNode.getKind.belongsTo(SqlKind.DDL)
|| sqlNode.getKind == SqlKind.INSERT
|| sqlNode.getKind == SqlKind.CREATE_FUNCTION
|| sqlNode.getKind == SqlKind.DROP_FUNCTION
|| sqlNode.getKind == SqlKind.OTHER_DDL
|| sqlNode.isInstanceOf[SqlLoadModule]
|| sqlNode.isInstanceOf[SqlShowCatalogs]
|| sqlNode.isInstanceOf[SqlShowCurrentCatalog]
|| sqlNode.isInstanceOf[SqlShowDatabases]
|| sqlNode.isInstanceOf[SqlShowCurrentDatabase]
|| sqlNode.isInstanceOf[SqlShowTables]
|| sqlNode.isInstanceOf[SqlShowFunctions]
|| sqlNode.isInstanceOf[SqlShowViews]
|| sqlNode.isInstanceOf[SqlShowPartitions]
|| sqlNode.isInstanceOf[SqlRichDescribeTable]
|| sqlNode.isInstanceOf[SqlUnloadModule]) {
return sqlNode
}
sqlNode match {
case explain: SqlExplain =>
val validated = validator.validate(explain.getExplicandum)
explain.setOperand(0, validated)
explain
case _ =>
validator.validate(sqlNode)
}
}
catch {
case e: RuntimeException =>
throw new ValidationException(s"SQL validation failed. ${e.getMessage}", e)
}
}
至此,Flink引擎已将 用户业务 转化成 如下抽象语法树(AST),此AST并未应用任何优化策略,只是Sql节点的原生映射 :
== Abstract Syntax Tree ==
3.3.4 语义分析(SqlNode–>RelNode/RexNode)
前面经过的SQL解析和SQL验证之后得到的SqlNode,仅仅是将SQL解析到java数据结构的固定节点上,并没有给出相关节点之间的关联关系以及每个节点的类型等信息,因此还需要将SqlNode转换为逻辑计划(RelNode)。
在 tEnv.sqlQuery() 方法中, Step-3 即为SQL解析过程,入参为 验证后的SqlNode,返回的是包含RelNode信息的RelRoot对象。
下面为构建逻辑计划的过程:
private def rel(validatedSqlNode: SqlNode, sqlValidator: FlinkCalciteSqlValidator) = {
try {
assert(validatedSqlNode != null)
val sqlToRelConverter: SqlToRelConverter = createSqlToRelConverter(sqlValidator)
sqlToRelConverter.convertQuery(validatedSqlNode, false, true)
// we disable automatic flattening in order to let composite types pass without modification
// we might enable it again once Calcite has better support for structured types
// root = root.withRel(sqlToRelConverter.flattenTypes(root.rel, true))
// TableEnvironment.optimize will execute the following
// root = root.withRel(RelDecorrelator.decorrelateQuery(root.rel))
// convert time indicators
// root = root.withRel(RelTimeIndicatorConverter.convert(root.rel, rexBuilder))
} catch {
case e: RelConversionException => throw new TableException(e.getMessage)
}
}
private def createSqlToRelConverter(sqlValidator: SqlValidator): SqlToRelConverter = {
new SqlToRelConverter(
createToRelContext(),
sqlValidator,
sqlValidator.getCatalogReader.unwrap(classOf[CalciteCatalogReader]),
cluster,
convertletTable,
sqlToRelConverterConfig)
}
至此,用户通过 StreamTableEnvironment 对象 注册的Calatlog信息 和 业务Sql 都 转化成了 逻辑计划(Logical Plan),同时,TableApi和SqlApi 也在 Logical Plan 这里达成一致,后续进行的优化阶段、生成物理计划和生成DataStream,都是相同的过程。
3.3.5 优化阶段(Logical RelNode–>FlinkLogicalRel)
tEnv.sqlQuery() 返回 Table 对象,在Flink中,Table对象既可通过TableApi生成,也可以通过SqlApi生成,TableApi和SqlApi至此达成一致。
在业务代码中,toAppendStream方法会进行 Logical Plan 的优化、生成物理计划以及生成DataStream的过程:
tEnv.toAppendStream(result, Order.class).print();
跟踪代码,会进入 StreamTableEnvironment.scala 的 translate 方法,这里我做个示范:
1 按住ctrl左键跳转进入toAppendStream方法
2 ctrl+H 查看 StreamTableEnvironment接口中toAppendStream 的具体实现类
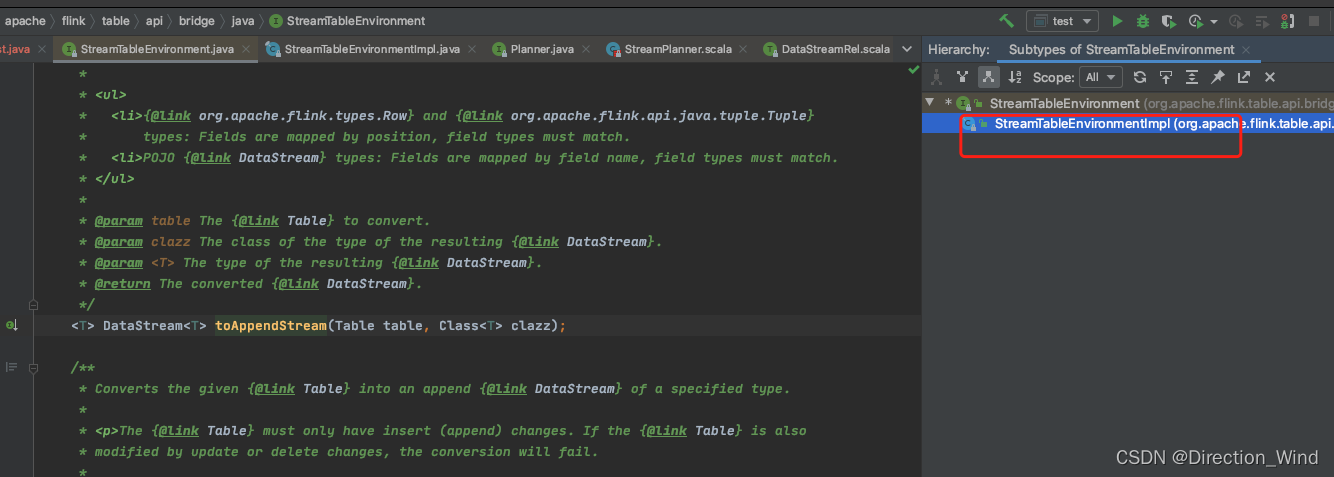
3 进入StreamTableEnvironmentImpl类查看toAppendStream 方法
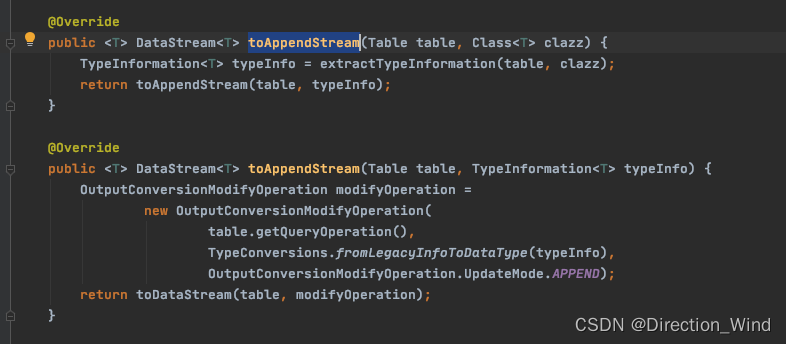
可以看到 return toDataStream(table, modifyOperation); 点击进入toDataStream
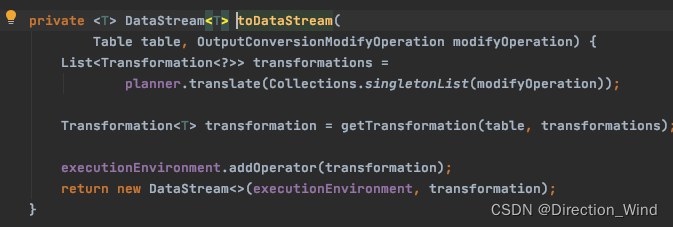
4 点击进入 translate 算子,操作同第2步 查看接口的具体实现
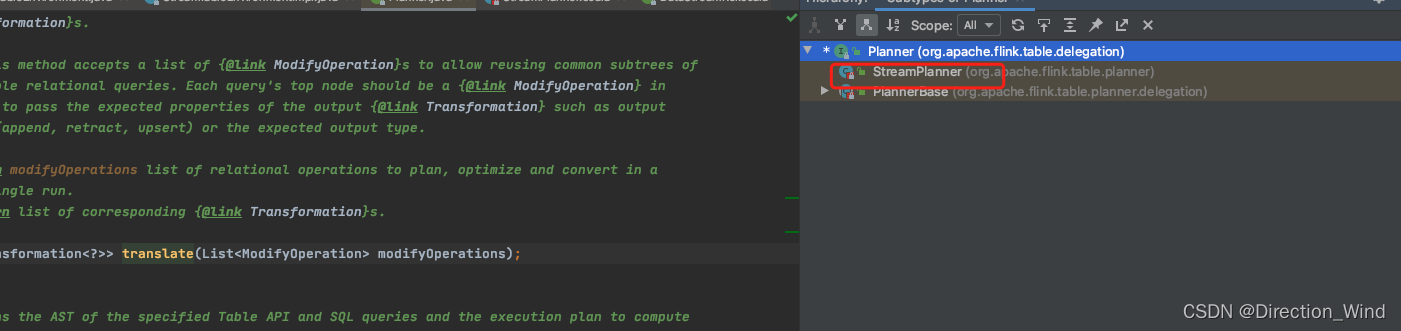
就可以得到真正的translate 实现方法
override def translate(
tableOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
val planner = createDummyPlanner()
tableOperations.asScala.map { operation =>
val (ast, updatesAsRetraction) = translateToRel(operation)
// Step-4: 优化阶段 + Step-5: 生成物理计划
val optimizedPlan = optimizer.optimize(ast, updatesAsRetraction, getRelBuilder)
// Step-6: 转成DataStream
val dataStream = translateToCRow(planner, optimizedPlan)
dataStream.getTransformation.asInstanceOf[Transformation[_]]
}.filter(Objects.nonNull).asJava
}
//translate操作 具体的 DataStreamRelNode 转换为 流的 真正操作执行
private def translateToCRow(planner: StreamPlanner, logicalPlan: RelNode): DataStream[CRow] = {
// 依次递归调用每个节点的 translateToPlan 方法,将 DataStreamRelNode 转化为 DataStream,最终生成 DataStreamGraph
logicalPlan match {
case node: DataStreamRel =>
getExecutionEnvironment.configure(
config.getConfiguration,
Thread.currentThread().getContextClassLoader)
node.translateToPlan(planner)
case _ =>
throw new TableException("Cannot generate DataStream due to an invalid logical plan. " +
"This is a bug and should not happen. Please file an issue.")
}
}
3.3.5.1 FlinkRuleSets
Calcite框架允许我们使用规则来优化逻辑计划,Flink在Optimize过程中,使用 FlinkRuleSets 定义优化规则进行优化:

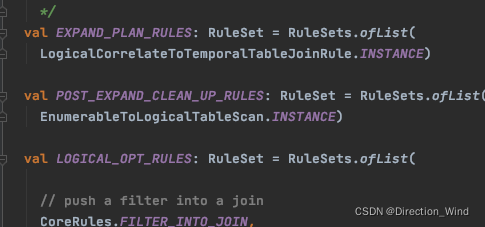
此处,简单描述下各RuleSet的作用:
- DATASTREAM_NORM_RULES:Transform window to LogicalWindowAggregate
- DATASET_OPT_RULES:translate to Flink DataSet nodes
- TABLE_SUBQUERY_RULES:Convert sub-queries before query decorrelation
规则的具体实现也在相同的 类包中
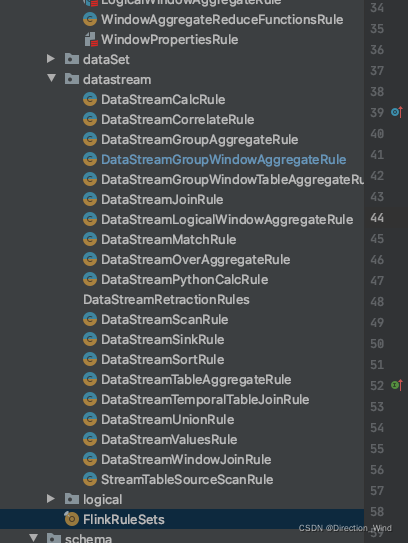
如 :DataStreamGroupWindowAggregateRule 为 GROUPING SETS 相关的规则
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.table.plan.rules.datastream
import org.apache.calcite.plan.{RelOptRule, RelOptRuleCall, RelTraitSet}
import org.apache.calcite.rel.RelNode
import org.apache.calcite.rel.convert.ConverterRule
import org.apache.flink.table.api.TableException
import org.apache.flink.table.plan.nodes.FlinkConventions
import org.apache.flink.table.plan.nodes.datastream.DataStreamGroupWindowAggregate
import org.apache.flink.table.plan.nodes.logical.FlinkLogicalWindowAggregate
import org.apache.flink.table.plan.schema.RowSchema
import scala.collection.JavaConversions._
class DataStreamGroupWindowAggregateRule
extends ConverterRule(
classOf[FlinkLogicalWindowAggregate],
FlinkConventions.LOGICAL,
FlinkConventions.DATASTREAM,
"DataStreamGroupWindowAggregateRule") {
override def matches(call: RelOptRuleCall): Boolean = {
val agg: FlinkLogicalWindowAggregate = call.rel(0).asInstanceOf[FlinkLogicalWindowAggregate]
// check if we have grouping sets
val groupSets = agg.getGroupSets.size() != 1 || agg.getGroupSets.get(0) != agg.getGroupSet
if (groupSets || agg.indicator) {
throw new TableException("GROUPING SETS are currently not supported.")
}
!groupSets && !agg.indicator
}
override def convert(rel: RelNode): RelNode = {
val agg: FlinkLogicalWindowAggregate = rel.asInstanceOf[FlinkLogicalWindowAggregate]
val traitSet: RelTraitSet = rel.getTraitSet.replace(FlinkConventions.DATASTREAM)
val convInput: RelNode = RelOptRule.convert(agg.getInput, FlinkConventions.DATASTREAM)
new DataStreamGroupWindowAggregate(
agg.getWindow,
agg.getNamedProperties,
rel.getCluster,
traitSet,
convInput,
agg.getNamedAggCalls,
new RowSchema(rel.getRowType),
new RowSchema(agg.getInput.getRowType),
agg.getGroupSet.toArray)
}
}
object DataStreamGroupWindowAggregateRule {
val INSTANCE: RelOptRule = new DataStreamGroupWindowAggregateRule
}
对于flink1.12还未实现真正的流批一体,针对批/流应用,采用不同的Rule进行优化,下面是流处理的各规则的优化过程:
**StreamOptimizer.scala**
/**
* Generates the optimized [[RelNode]] tree from the original relational node tree.
*
* @param relNode The root node of the relational expression tree.
* @param updatesAsRetraction True if the sink requests updates as retraction messages.
* @return The optimized [[RelNode]] tree
*/
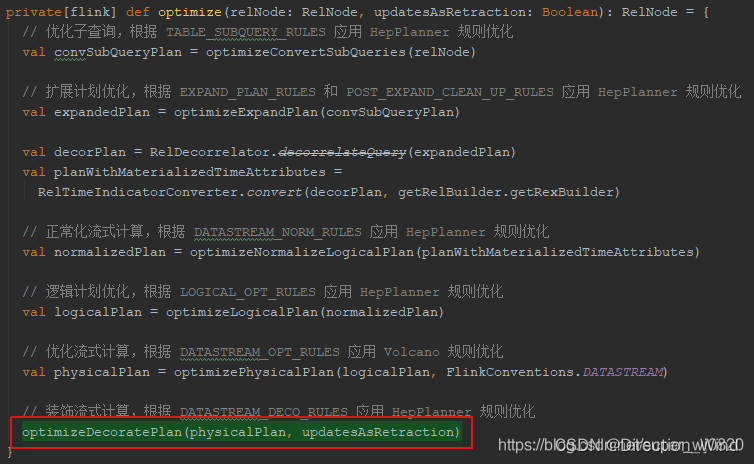
def optimize(
relNode: RelNode,
updatesAsRetraction: Boolean,
relBuilder: RelBuilder): RelNode = {
// 优化子查询,根据 TABLE_SUBQUERY_RULES 应用 HepPlanner 规则优化
val convSubQueryPlan = optimizeConvertSubQueries(relNode)
// 扩展计划优化,根据 EXPAND_PLAN_RULES 和 POST_EXPAND_CLEAN_UP_RULES 应用 HepPlanner 规则优化
val expandedPlan = optimizeExpandPlan(convSubQueryPlan)
val decorPlan = RelDecorrelator.decorrelateQuery(expandedPlan, relBuilder)
val planWithMaterializedTimeAttributes =
RelTimeIndicatorConverter.convert(decorPlan, relBuilder.getRexBuilder)
// 正常化流式计算,根据 DATASTREAM_NORM_RULES 应用 HepPlanner 规则优化
val normalizedPlan = optimizeNormalizeLogicalPlan(planWithMaterializedTimeAttributes)
// 逻辑计划优化,根据 LOGICAL_OPT_RULES 应用 VolcanoPlanner 规则优化
val logicalPlan = optimizeLogicalPlan(normalizedPlan)
val logicalRewritePlan = optimizeLogicalRewritePlan(logicalPlan)
// 优化流式计算,根据 DATASTREAM_OPT_RULES 应用 Volcano 规则优化
val physicalPlan = optimizePhysicalPlan(logicalRewritePlan, FlinkConventions.DATASTREAM)
// 装饰流式计算,根据 DATASTREAM_DECO_RULES 应用 HepPlanner 规则优化
optimizeDecoratePlan(physicalPlan, updatesAsRetraction)
}
由上述过程也可以看出,Flink基于FlinkRuleSets的rule进行转换的过程中,既包含了 优化 logical Plan 的过程,也包括了生成 Flink PhysicalPlan 的过程。
Flink 逻辑计划优化
从 3.3.5.1 节的优化过程可看出,Flink在进行 logical Plan 优化之前,会应用 HepPlanner 针对 TABLE_SUBQUERY_RULES、EXPAND_PLAN_RULES、POST_EXPAND_CLEAN_UP_RULES、DATASTREAM_NORM_RULES 这些规则进行预处理,处理完之后 才会应用 VolcanoPlanner 针对 LOGICAL_OPT_RULES 中罗列的优化规则,尝试使用不同的规则优化,试图计算出最优的一种优化plan返回,说的简单点就是一个relNode在不同的优化规则中传递,一次一次的优化,得到最好的结果。
VolcanoPlanner的优化操作为:
** Optimizer.scala **
protected def optimizeLogicalPlan(relNode: RelNode): RelNode = {
val logicalOptRuleSet = getLogicalOptRuleSet
val logicalOutputProps = relNode.getTraitSet.replace(FlinkConventions.LOGICAL).simplify()
if (logicalOptRuleSet.iterator().hasNext) {
runVolcanoPlanner(logicalOptRuleSet, relNode, logicalOutputProps)
} else {
relNode
}
1. Logic RelNode :normalizedPlan
应用 HepPlanner 针对 预处理规则 进行预处理后,会得到 Logic RelNode :
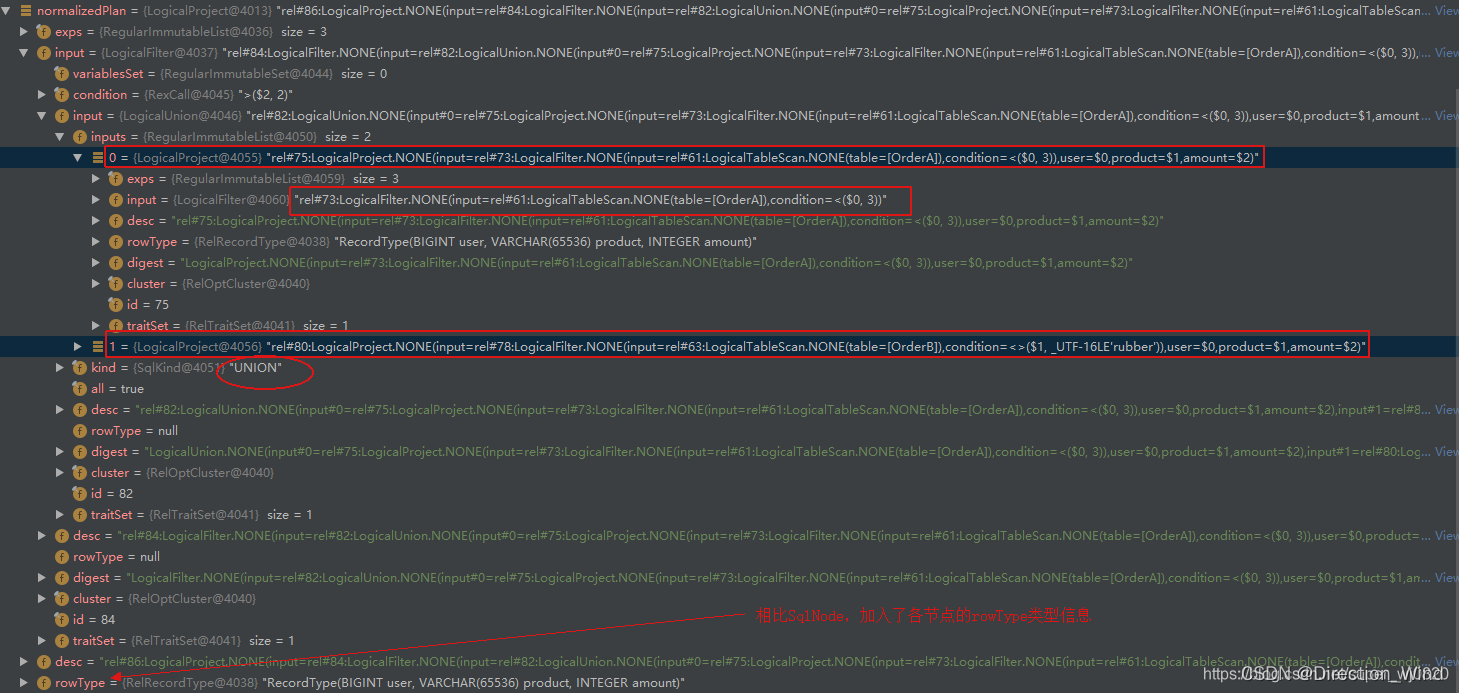
对比 Sql解析之后得到的 SqlNode 发现, Logic RelNode 同样持有 Sql 各组成的 映射信息,除此之外,相比SqlNode,Logic RelNode 加入了各节点的 rowType 类型信息。
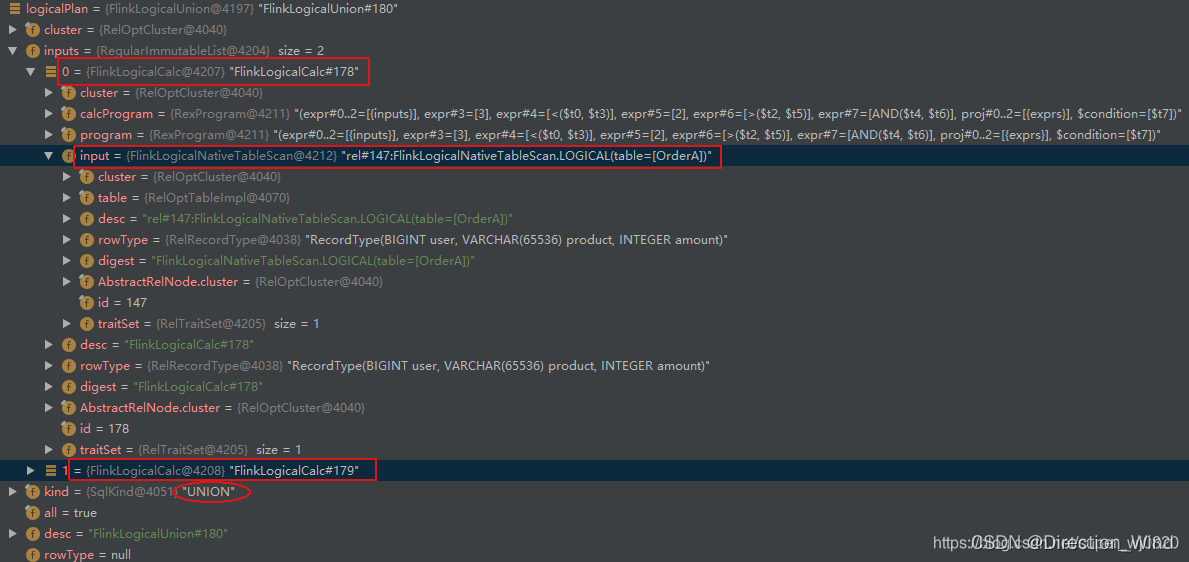
2. Optimized Logical RelNode :logicalPlan
VolcanoPlanner 根据 FlinkRuleSets.LOGICAL_OPT_RULES 找到最优的执行Planner,并转换为 Flink Logical RelNode 返回:
3.3.6 生成物理计划(LogicalRelNode–>Physic Plan)
应用 VolcanoPlanner 针对 FlinkRuleSets.DATASTREAM_OPT_RULES,将 Optimized Logical RelNode 转换为 Flink Physic Plan (Flink Logical RelNode -> DataStream RelNode)。
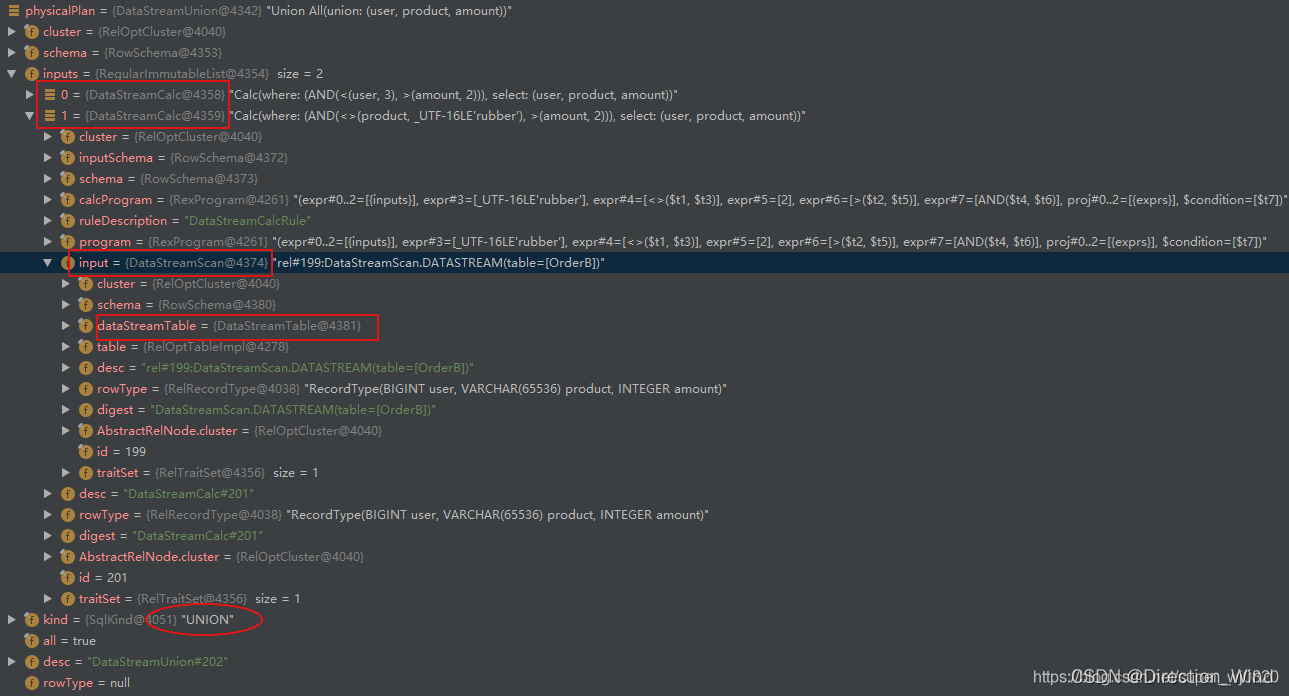
此时,用户的执行计划已被优化为如下计划:
== Optimized Logical Plan ==
如果是 RetractStream 则还会使用 FlinkRuleSets.DATASTREAM_DECO_RULES 进行 Retract特征 的一个包装:
至此,Step-4: 优化阶段 + Step-5: 生成物理计划 已完成。
3.3.7 生成DataStream(Physic Plan–>DataStream)
StreamTableEnvironment.scala 的 translate 方法中最后一步,Step-6:转成DataStream,此处将用户的业务Sql最终转成 Stream Api 执行。有上面提到过的 translateToCRow 方法转换为真正的流。针对优化后得到的逻辑计划(实际已转成物理计划 DataStreamRel),由外到内遍历各节点,将 DataStreamRel Node 转化为 DataStream,以下面物理计划为例:
== Optimized Logical Plan ==
依次递归调用 DataStreamUnion、DataStreamCalc、DataStreamScan 类中 重写的 translateToPlan 方法,将各节点的 DataStreamRel 实现 转化为 DataStream 执行计划的实现。
关于 DataStreamRel 的类继承关系如下图所示,RelNode 是 Calcite 定义的 Sql节点关系 数据结构,FlinkRelNode 继承自 RelNode,其有三个实现,分别是FlinkLogicalRel、DataStreamRel、DataSetRel,分别对应Flink内部 对 Sql 表达式的 逻辑计划的描述以及物理计划的描述。

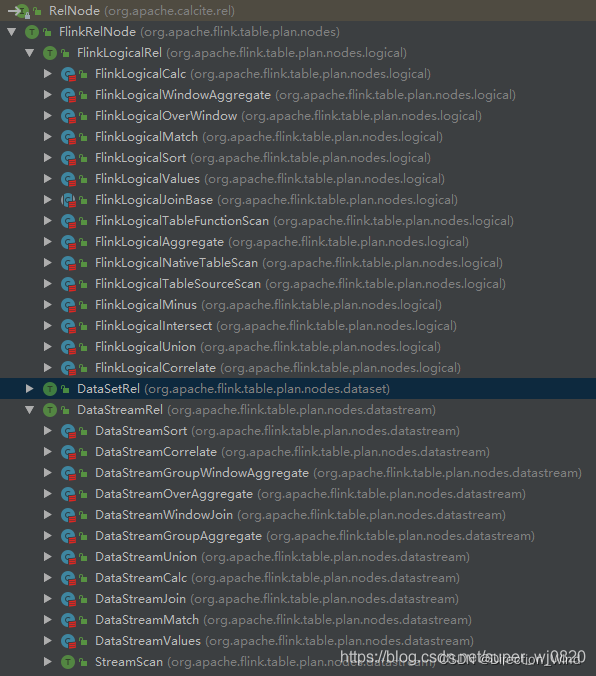
3.4 总结Flink Sql执行流程
4. catalog相关概念
4.1 flink中的catalog
在上文中,提到过不少次catalog 这个东西,那这个东西到底是个什么呢?
catalog 是sql中的一个概念,是一个元数据空间/管理器。
在创建StreamTableEnvironment的时候 ,就已经创建了catalog了



可以看到,在创建环境空间的时候,就已经创建了catalog,并且是默认是存储在内存中的,那么这个GenericInMemoryCatalog中:
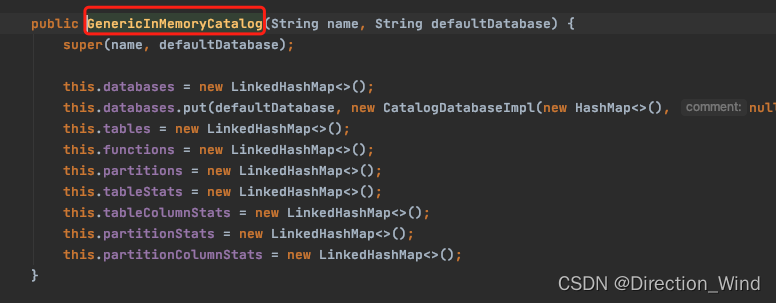
在这里就能看到了,catalog中就是一些table的基础信息数据,数据库,表,方法,分区等等,都放在一个个的hashmap中。
在 catalogManager.java 能看到

catalog 其实不止一个。
如果说 flink中与hive交互,例如sink 到hive,那么hive的元数据 ,也会被创建进flink的catalog中,例如:
也可以自己创建一个新的 catalog。那么在flink sql中临时表 永久表 都是怎么存在catalog中的呢?
4.2 catalog中 表的管理,临时表 永久表
表代表具体的数据
视图代表一段逻辑
举个例子:如果用hive的catalog,例如 new hiveCatalog;
然后 tenv.executesql("create table "); 那么这个表 真的会建到hive中。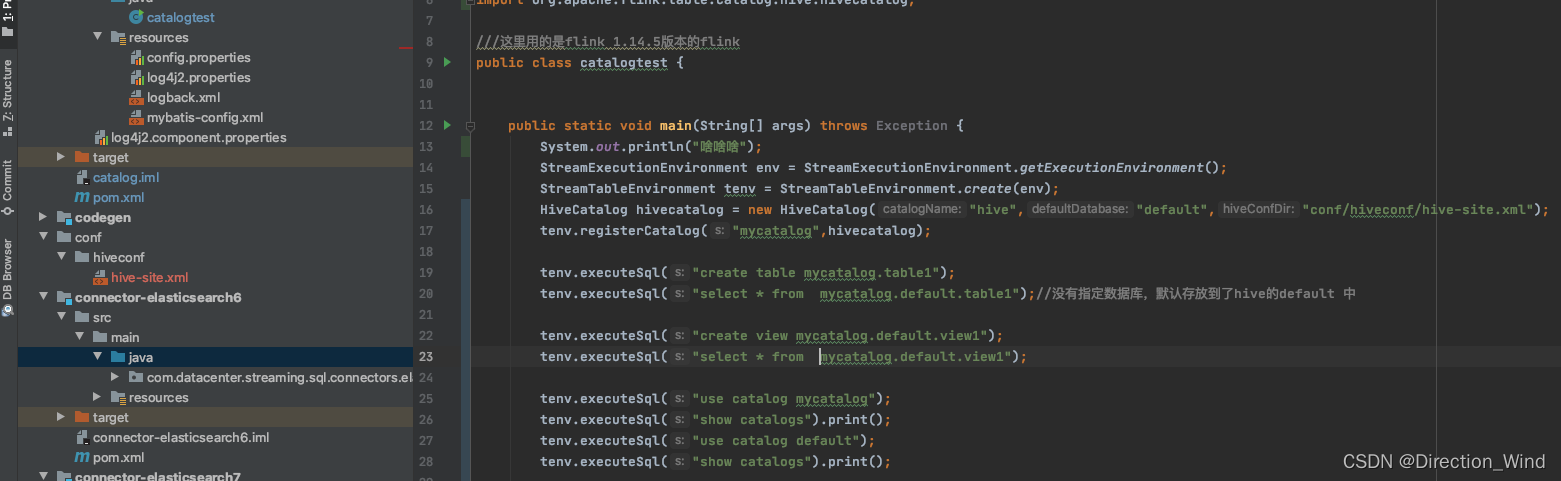
上图中 hiveConfDir中 存放的就是hive的metastore

<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://yourhive:9083</value>
</property>
</configuration>
那么 如果我现在 tenv.executeSql(“create view view1”); 我创建一个视图,那么 这个视图被放到了 哪个元数据空间,是flink中的memory的,还是 hive中的元数据空间?
答:flink中 default中默认的 ,想持久化的话需要: tenv.executeSql(“create view mycatalog.default.view1”);
指定mycatalog这样子相当于 在hive中也创建了一个持久化的视图。否则她就是在GenericMemoryCatalog中,也就是 flink指定默认catalog。
1 以上的建表和建视图相当于 ,在flink中,持久化了数据到flink中,包括建表 建视图,但这些,只能在flink中查询使用,在hive中,如hive命令行会报错,因为元数据不同。
2 在hive中 show tables;可以看到table1,缺不能在hive中 seletc * from table1;
3 在flink中 可以 show tables,也可以 seletc * from table1;
4 就算flink任务停止,重新启动,或用其他的flink任务去 select ,也可以执行。
5 可以理解为,他用的hive的catalog,存入了一些 flink的 东西
现在请问,如果我建的是个临时表,用hive的catalog: tenv.executeSql(“create temporary table mycatalog.table1”);
我在hive的命令行中查询 show tables; 会有table1嘛?
答案是:不会的,因为临时表 ,只会存在与flink的这个任务中,这个会话中。
那么问题来了,这个临时表,他存放进了hivecatalog中么?
如果你在任务中,create temporary 一个临时表,下面show create tables;就会发现 他也没有进入到hivecatalog中,那么这部分临时表的元数据,他放在了哪里呢?
我们看CatalogManager 源码会发现,临时表的元数据管理 与 正式表的元数据管理是分开的:
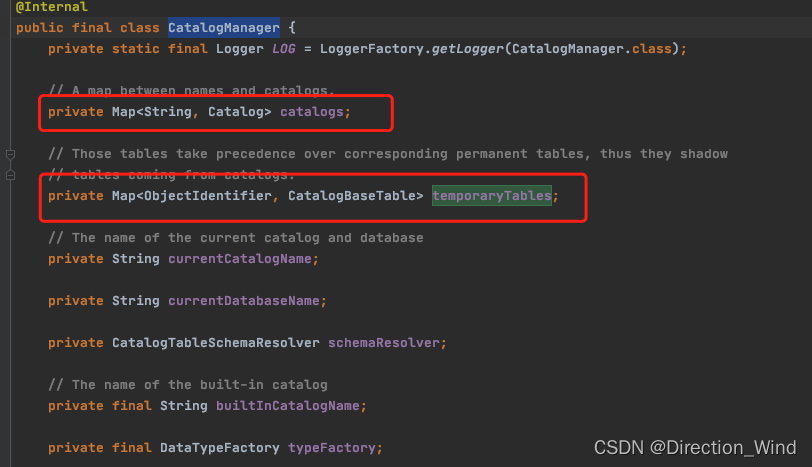
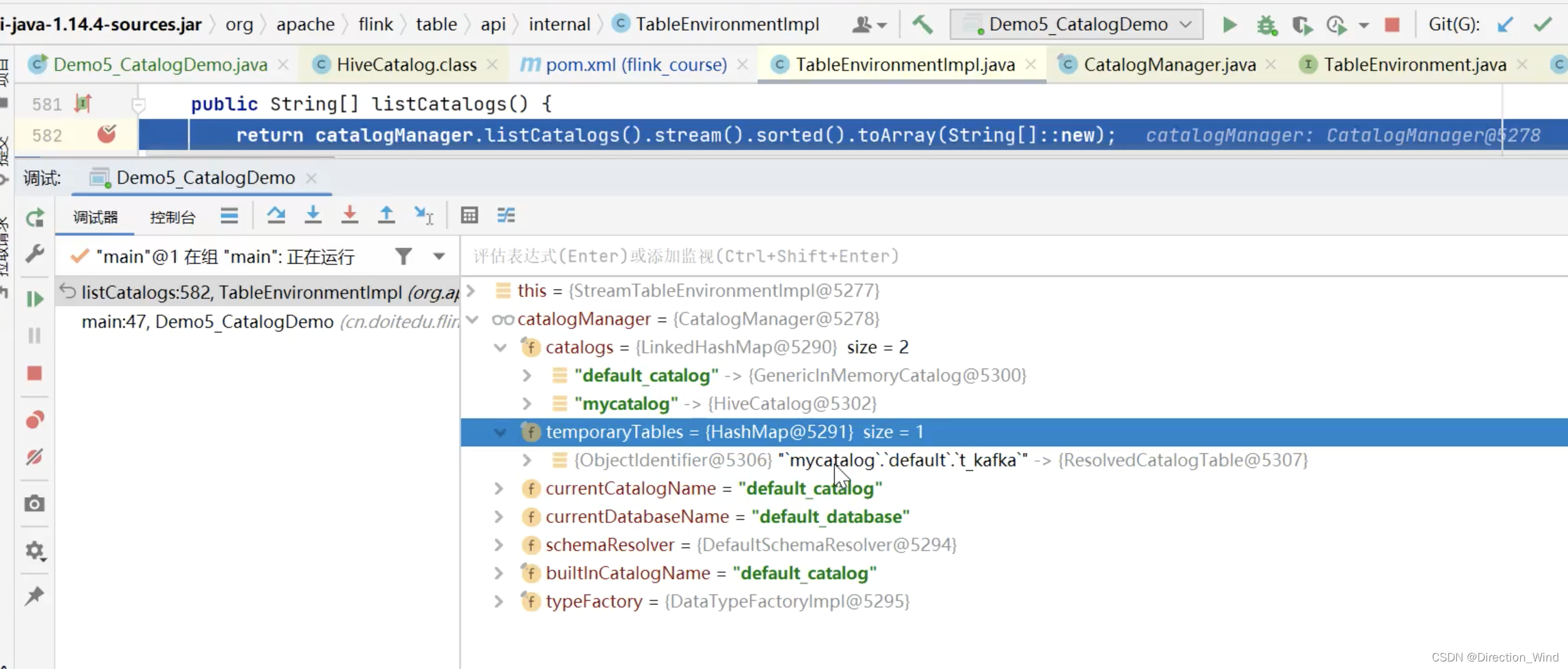
5 开发中遇到问题想查询源码如何查询
举一个简单地例子,我开发中 不知道create中具体可以加入那些参数,就可以故意写错 connector写成 connecdtor 这样就会爆出异常,根据报错的顺序就可以追踪到具体的代码中查看
/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/bin/java -javaagent:/Applications/IntelliJ IDEA.app/Contents/lib/idea_rt.jar=59800:/Applications/IntelliJ IDEA.app/Contents/bin -Dfile.encoding=UTF-8 -classpath /Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/cldrdata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/jaccess.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/nashorn.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/jfxswt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/lib/packager.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/lib/tools.jar:/Users/congpeng/Documents/code/flinkTest/flinkcdc/target/classes:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-api-scala-bridge_2.12/1.14.5/flink-table-api-scala-bridge_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-api-scala_2.12/1.14.5/flink-table-api-scala_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/scala-lang/scala-reflect/2.12.7/scala-reflect-2.12.7.jar:/Users/congpeng/.m2/repository/org/scala-lang/scala-library/2.12.7/scala-library-2.12.7.jar:/Users/congpeng/.m2/repository/org/scala-lang/scala-compiler/2.12.7/scala-compiler-2.12.7.jar:/Users/congpeng/.m2/repository/org/scala-lang/modules/scala-xml_2.12/1.0.6/scala-xml_2.12-1.0.6.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-scala_2.12/1.14.5/flink-scala_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/com/twitter/chill_2.12/0.7.6/chill_2.12-0.7.6.jar:/Users/congpeng/.m2/repository/com/twitter/chill-java/0.7.6/chill-java-0.7.6.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-streaming-scala_2.12/1.14.5/flink-streaming-scala_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/com/google/code/findbugs/jsr305/1.3.9/jsr305-1.3.9.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-shaded-force-shading/14.0/flink-shaded-force-shading-14.0.jar:/Users/congpeng/.m2/repository/org/projectlombok/lombok/1.18.24/lombok-1.18.24.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-sql-connector-hive-3.1.2_2.11/1.14.5/flink-sql-connector-hive-3.1.2_2.11-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-csv/1.14.5/flink-csv-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-json/1.14.5/flink-json-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-connector-jdbc_2.12/1.14.4/flink-connector-jdbc_2.12-1.14.4.jar:/Users/congpeng/.m2/repository/com/h2database/h2/2.1.210/h2-2.1.210.jar:/Users/congpeng/.m2/repository/mysql/mysql-connector-java/8.0.27/mysql-connector-java-8.0.27.jar:/Users/congpeng/.m2/repository/com/google/protobuf/protobuf-java/3.11.4/protobuf-java-3.11.4.jar:/Users/congpeng/.m2/repository/com/ververica/flink-sql-connector-mysql-cdc/2.3.0/flink-sql-connector-mysql-cdc-2.3.0.jar:/Users/congpeng/.m2/repository/org/awaitility/awaitility/4.0.1/awaitility-4.0.1.jar:/Users/congpeng/.m2/repository/org/hamcrest/hamcrest/2.1/hamcrest-2.1.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-shaded-guava/30.1.1-jre-16.0/flink-shaded-guava-30.1.1-jre-16.0.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-statebackend-rocksdb_2.12/1.14.5/flink-statebackend-rocksdb_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/com/ververica/frocksdbjni/6.20.3-ververica-1.0/frocksdbjni-6.20.3-ververica-1.0.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-api-java-bridge_2.12/1.14.5/flink-table-api-java-bridge_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-api-java/1.14.5/flink-table-api-java-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-java/1.14.5/flink-java-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/commons/commons-lang3/3.3.2/commons-lang3-3.3.2.jar:/Users/congpeng/.m2/repository/org/apache/commons/commons-math3/3.5/commons-math3-3.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-streaming-java_2.12/1.14.5/flink-streaming-java_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-file-sink-common/1.14.5/flink-file-sink-common-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-planner_2.12/1.14.5/flink-table-planner_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-runtime_2.12/1.14.5/flink-table-runtime_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-code-splitter/1.14.5/flink-table-code-splitter-1.14.5.jar:/Users/congpeng/.m2/repository/org/codehaus/janino/janino/3.0.11/janino-3.0.11.jar:/Users/congpeng/.m2/repository/org/codehaus/janino/commons-compiler/3.0.11/commons-compiler-3.0.11.jar:/Users/congpeng/.m2/repository/org/apache/calcite/avatica/avatica-core/1.17.0/avatica-core-1.17.0.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-table-common/1.14.5/flink-table-common-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-core/1.14.5/flink-core-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-annotations/1.14.5/flink-annotations-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-metrics-core/1.14.5/flink-metrics-core-1.14.5.jar:/Users/congpeng/.m2/repository/com/esotericsoftware/kryo/kryo/2.24.0/kryo-2.24.0.jar:/Users/congpeng/.m2/repository/com/esotericsoftware/minlog/minlog/1.2/minlog-1.2.jar:/Users/congpeng/.m2/repository/org/objenesis/objenesis/2.1/objenesis-2.1.jar:/Users/congpeng/.m2/repository/commons-collections/commons-collections/3.2.2/commons-collections-3.2.2.jar:/Users/congpeng/.m2/repository/org/apache/commons/commons-compress/1.21/commons-compress-1.21.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-connector-files/1.14.5/flink-connector-files-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-connector-base/1.14.5/flink-connector-base-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-shaded-asm-7/7.1-14.0/flink-shaded-asm-7-7.1-14.0.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-clients_2.12/1.14.5/flink-clients_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-runtime/1.14.5/flink-runtime-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-rpc-core/1.14.5/flink-rpc-core-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-rpc-akka-loader/1.14.5/flink-rpc-akka-loader-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-queryable-state-client-java/1.14.5/flink-queryable-state-client-java-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-hadoop-fs/1.14.5/flink-hadoop-fs-1.14.5.jar:/Users/congpeng/.m2/repository/commons-io/commons-io/2.8.0/commons-io-2.8.0.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-shaded-zookeeper-3/3.4.14-14.0/flink-shaded-zookeeper-3-3.4.14-14.0.jar:/Users/congpeng/.m2/repository/org/javassist/javassist/3.24.0-GA/javassist-3.24.0-GA.jar:/Users/congpeng/.m2/repository/org/xerial/snappy/snappy-java/1.1.8.3/snappy-java-1.1.8.3.jar:/Users/congpeng/.m2/repository/org/lz4/lz4-java/1.8.0/lz4-java-1.8.0.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-optimizer/1.14.5/flink-optimizer-1.14.5.jar:/Users/congpeng/.m2/repository/commons-cli/commons-cli/1.3.1/commons-cli-1.3.1.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-runtime-web_2.12/1.14.5/flink-runtime-web_2.12-1.14.5.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-shaded-netty/4.1.65.Final-14.0/flink-shaded-netty-4.1.65.Final-14.0.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-shaded-jackson/2.12.4-14.0/flink-shaded-jackson-2.12.4-14.0.jar:/Users/congpeng/.m2/repository/org/slf4j/slf4j-api/2.0.7/slf4j-api-2.0.7.jar:/Users/congpeng/.m2/repository/org/roaringbitmap/RoaringBitmap/0.9.28/RoaringBitmap-0.9.28.jar:/Users/congpeng/.m2/repository/org/roaringbitmap/shims/0.9.28/shims-0.9.28.jar:/Users/congpeng/.m2/repository/org/apache/flink/flink-metrics-dropwizard/1.14.4/flink-metrics-dropwizard-1.14.4.jar:/Users/congpeng/.m2/repository/io/dropwizard/metrics/metrics-core/3.2.6/metrics-core-3.2.6.jar cdctest
啥啥啥
SLF4J: No SLF4J providers were found.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See https://www.slf4j.org/codes.html#noProviders for further details.
Exception in thread "main" org.apache.flink.table.api.ValidationException: Unable to create a source for reading table 'default_catalog.default_database.flinka'.
Table options are:
'connecdtor'='mysql-cdc'
'database-name'='mysql'
'hostname'='localhost'
'password'='******'
'port'='3306'
'table-name'='a'
'username'='root'
at org.apache.flink.table.factories.FactoryUtil.createTableSource(FactoryUtil.java:150)
at org.apache.flink.table.planner.plan.schema.CatalogSourceTable.createDynamicTableSource(CatalogSourceTable.java:116)
at org.apache.flink.table.planner.plan.schema.CatalogSourceTable.toRel(CatalogSourceTable.java:82)
at org.apache.calcite.sql2rel.SqlToRelConverter.toRel(SqlToRelConverter.java:3585)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertIdentifier(SqlToRelConverter.java:2507)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertFrom(SqlToRelConverter.java:2144)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertFrom(SqlToRelConverter.java:2093)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertFrom(SqlToRelConverter.java:2050)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectImpl(SqlToRelConverter.java:663)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertSelect(SqlToRelConverter.java:644)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertQueryRecursive(SqlToRelConverter.java:3438)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertQuery(SqlToRelConverter.java:570)
at org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$rel(FlinkPlannerImpl.scala:177)
at org.apache.flink.table.planner.calcite.FlinkPlannerImpl.rel(FlinkPlannerImpl.scala:169)
at org.apache.flink.table.planner.operations.SqlToOperationConverter.toQueryOperation(SqlToOperationConverter.java:1057)
at org.apache.flink.table.planner.operations.SqlToOperationConverter.convertSqlQuery(SqlToOperationConverter.java:1026)
at org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:301)
at org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:101)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:736)
at cdctest.main(cdctest.java:37)
Caused by: org.apache.flink.table.api.ValidationException: Table options do not contain an option key 'connector' for discovering a connector.
at org.apache.flink.table.factories.FactoryUtil.getDynamicTableFactory(FactoryUtil.java:554)
at org.apache.flink.table.factories.FactoryUtil.createTableSource(FactoryUtil.java:146)
... 19 more
Process finished with exit code 1
例如从这里就能看出来
代码报错都在 (cdctest.java:37)
解析代码入口在 (TableEnvironmentImpl.java:736)
具体抛出错误在 (FactoryUtil.java:150)
点开 (FactoryUtil.java:150) 在具体报错的那一步,debug ,一步一步往下查,就可以看到真正的具体报错在哪里,通过一步一步报错和比对,发现 真实报错是这里发生的
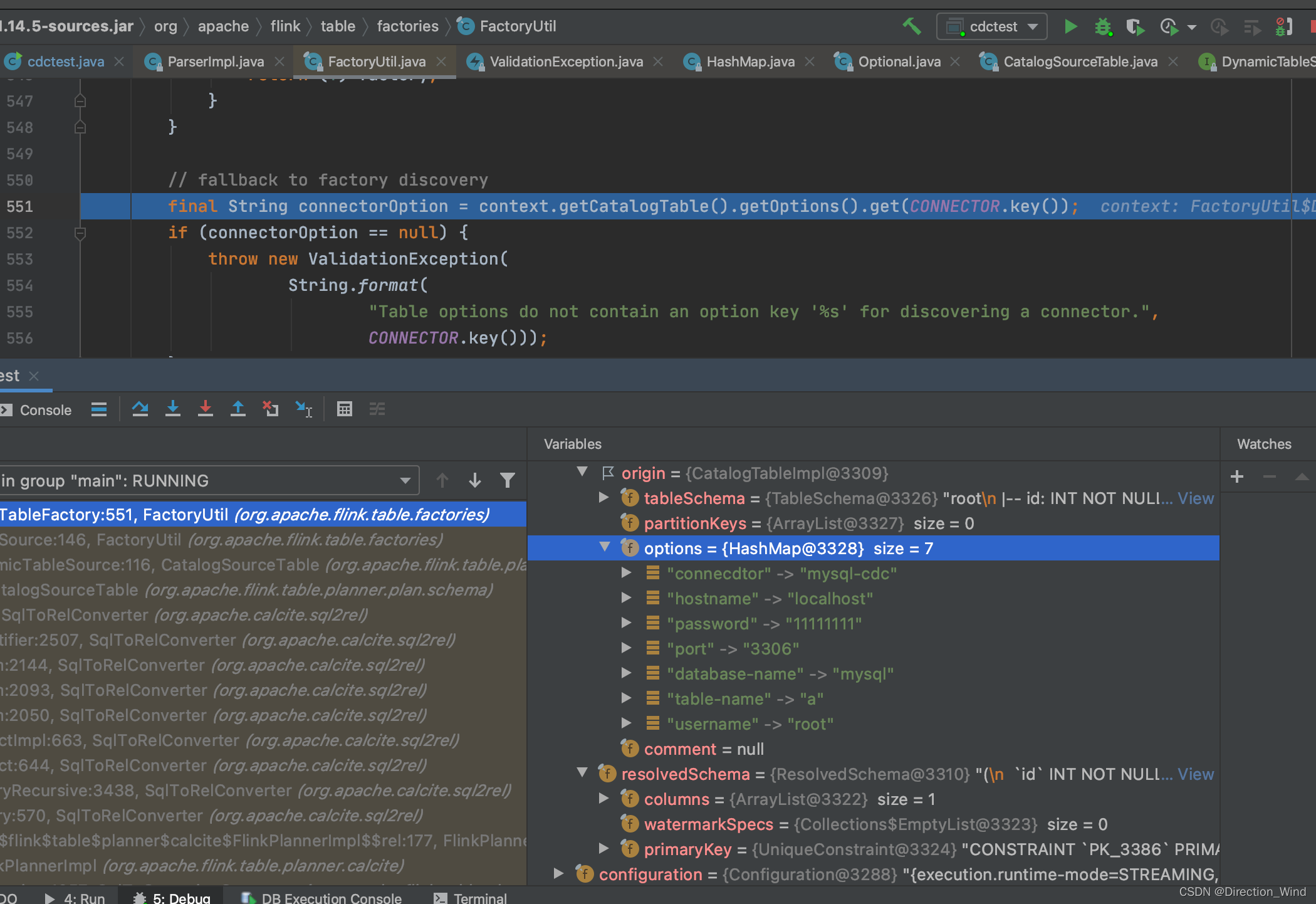
最后确认的是
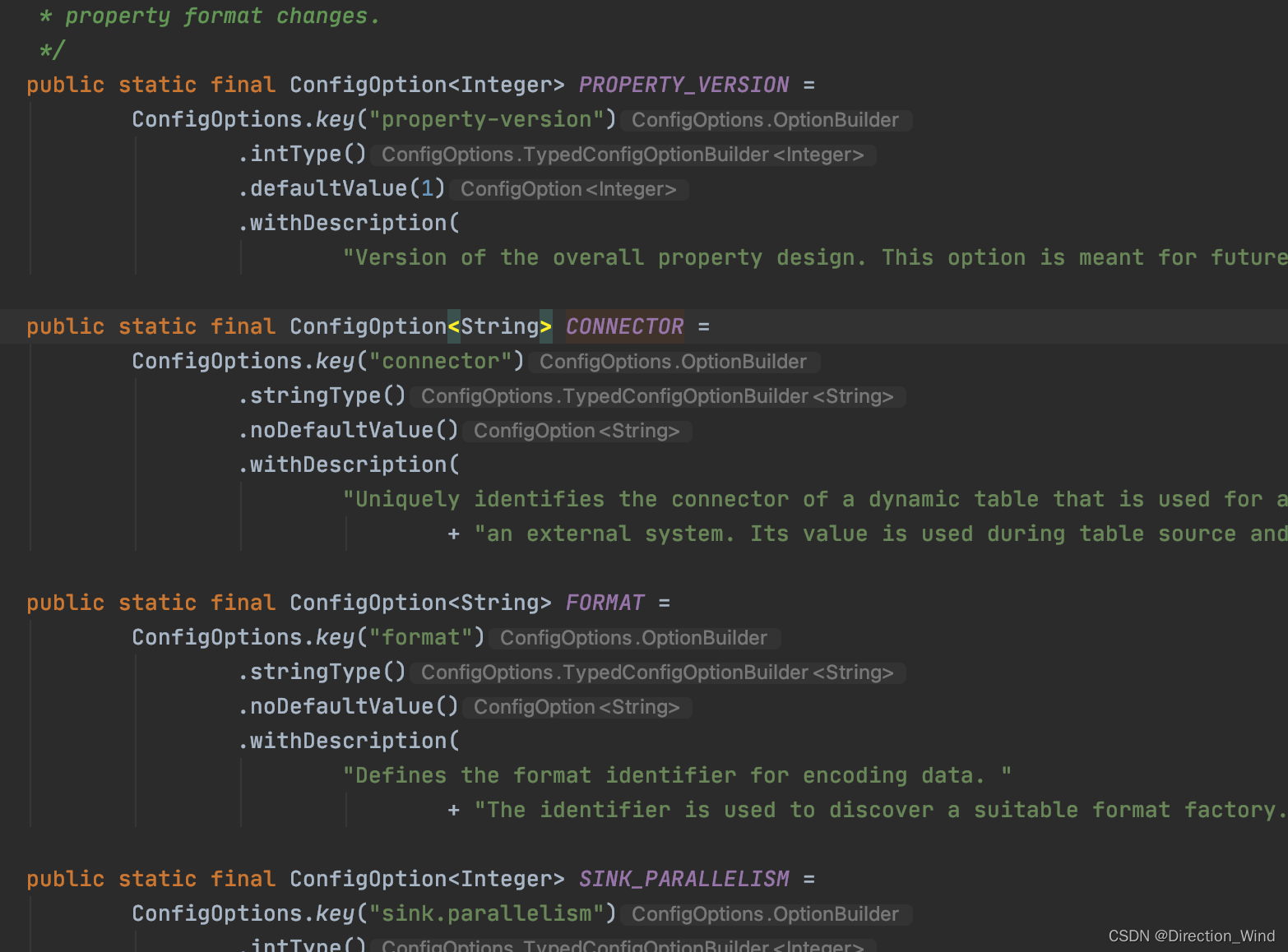
他会用代码中的配置项和这里的configoption 也就是factory里的最hash比对,如果有不同的 就会报那一步也就是 connector的错出来
引用
所有代码都在我的git上,需要的同学可以自取,如果找不到可以私信我
flinksql的语法扩展可以参考我的另一篇文章:
calcite 在flink中的二次开发