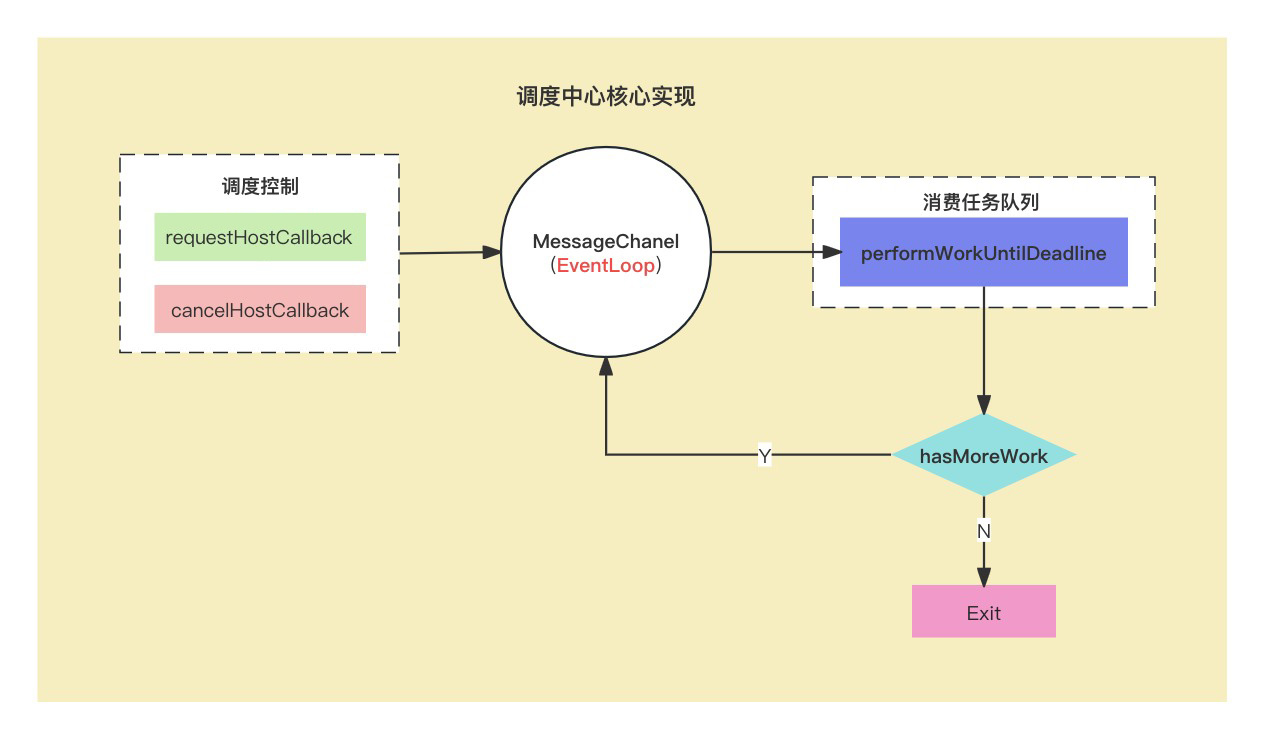
数组和列表
Python中数组和列表是不同的,我敢断言大多数的pythoneer只知道有列表list,却不知道python也有array数组。列表是一个包含不同数据类型的元素集合,而数组是一个只能含相同数据类型的元素集合。
Python的array库是一个提供数组操作的模块,它提供了一种用于存储和处理多个相同类型元素的容器。与Python的列表list相比,数组array在存储和操作大量数值型数据时更为高效,因为它在内存中以连续的方式存储数据,占用的内存空间更小。
数组创建
array(typecode [, initializer]) -> array
返回一个新数组,该数组的项受类型代码的限制,并通过可选的初始值设定项值进行初始化,该值必须是列表、字符串或可在适当类型的元素上迭代。
数组表示基本值,其行为与列表非常相似,只是其中存储的对象类型受到约束。类型是在对象创建时使用类型代码指定的,该代码是单个字符。
类型代码 typecode
| 类型 | C类型 | 最小字节 |
| 'b' | signed integer | 1 |
| 'B' | unsigned integer | 1 |
| 'u' | Unicode character | 2 |
| 'h' | signed integer | 2 |
| 'H' | unsigned integer | 2 |
| 'i' | signed integer | 2 |
| 'I' | unsigned integer | 2 |
| 'l' | signed integer | 4 |
| 'L' | unsigned integer | 4 |
| 'q' | signed integer | 8 |
| 'Q' | unsigned integer | 8 |
| 'f' | floating point | 4 |
| 'd' | floating point | 8 |
创建数组
import array
arr = array.array('i', [1, 2, 3, 4, 5]) # 创建一个整数类型的数组
arr = array.array('u', 'abcde') # 创建一个字符类型的数组
类型属性
import array
arr = array.array('i', [1, 2, 3, 4, 5])
print(arr.typecode) # 打印数组类型 i
数组切片
与列表用法相同:
>>> arr = array.array('i', [1, 2, 3, 4, 5])
>>> arr[0]
1
>>> arr[2]
3
>>> arr[-1]
5
>>> arr[:3]
array('i', [1, 2, 3])
>>> arr[3:]
array('i', [4, 5])
>>> arr[:-1]
array('i', [1, 2, 3, 4])
>>> arr[::-1]
array('i', [5, 4, 3, 2, 1])
>>> arr[1::2]
array('i', [2, 4])
>>> arr[0::2]
array('i', [1, 3, 5])
类型转换
整数数组可以转换到浮点数数组,反之不行。
>>> arr1 = array.array('i', [1, 2, 3, 4, 5])
>>> arr1
array('i', [1, 2, 3, 4, 5])
>>> arr2 = array.array('f', arr1)
>>> arr2
array('f', [1.0, 2.0, 3.0, 4.0, 5.0])
>>> arr3 = array.array('i', arr2)
Traceback (most recent call last):
File "<pyshell#77>", line 1, in <module>
arr3 = array.array('i', arr2)
TypeError: 'float' object cannot be interpreted as an integer
数组与列表占用内存的比较
import sys, array
arr = array.array('i', [_ for _ in range(1024)])
lst = [_ for _ in range(1024)]
print(sys.getsizeof(arr)) # 输出:4176 array对象本身的大小
print(sys.getsizeof(lst)) # 输出:8856 列表list对象本身的大小
# 注意:这些值可能因操作系统或Python解释器的实现和版本而略有不同。
数组方法
append()--将一个新项追加到数组的末尾
buffer_info()--返回给出当前内存信息的信息
byteswap()--字节交换数组的所有项
count()--返回对象的出现次数
extend()--通过从可迭代项中附加多个元素来扩展数组
fromfile()--从文件对象读取项
fromlist()--从列表中追加项
frombytes()--从字符串中追加项
fromunicode()--从unicode字符串中追加项
index()--返回对象第一次出现的索引
insert()--在数组中提供的位置插入一个新项
pop()--移除并返回项(默认为最后一个)
remove()--删除对象的第一个出现项
reverse()--反转数组中项目的顺序
tofile()--将所有项写入文件对象
tolist()--返回转换为普通列表的数组
tobytes()--返回转换为字符串的数组
在举例讲解前先来复习一个列表list的方法,用法相同的(绿色标注)可以省略不学:
append(self, object, /)
Append object to the end of the list.clear(self, /)
Remove all items from list.copy(self, /)
Return a shallow copy of the list.count(self, value, /)
Return number of occurrences of value.extend(self, iterable, /)
Extend list by appending elements from the iterable.index(self, value, start=0, stop=9223372036854775807, /)
Return first index of value.
Raises ValueError if the value is not present.insert(self, index, object, /)
Insert object before index.pop(self, index=-1, /)
Remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.remove(self, value, /)
Remove first occurrence of value.
Raises ValueError if the value is not present.reverse(self, /)
Reverse *IN PLACE*.sort(self, /, *, key=None, reverse=False)
Sort the list in ascending order and return None.
用法讲解
buffer_info()
返回当前数组缓冲区的内存信息。
import array
arr = array.array('i', [1, 2, 3])
buffer_info = arr.buffer_info()
print(buffer_info) # 输出包含内存地址、大小等信息的元组
byteswap()
字节交换数组的所有项,通常用于处理二进制数据的不同字节顺序。
import array
arr = array.array('i', [0x12345678]) # 假设这是一个32位整数
arr.byteswap()
print(arr) # 输出:[305419896] (0x78563412)
fromfile()
从文件对象中读取项,通常用于从二进制文件中读取数据。
import array
with open('data.bin', 'rb') as f:
arr = array.array('i')
arr.fromfile(f, 3) # 从文件中读取3个整数
print(arr) # 输出:假设文件中有3个整数,则输出这些整数构成的数组
fromlist()
从列表中追加项,创建一个新的数组。
import array
list_data = [1, 2, 3, 4, 5]
arr = array.array('i', list_data)
print(arr) # 输出:array('i', [1, 2, 3, 4, 5])
frombytes()
从字节字符串中追加项,创建一个新的数组。
import array
byte_data = b'\x01\x02\x03\x04'
arr = array.array('B', byte_data) # 'B' 表示无符号字符
print(arr) # 输出:array('B', [1, 2, 3, 4])
tofile()
将所有项写入文件对象,通常用于将数组数据写入二进制文件。
import array
arr = array.array('i', [1, 2, 3])
with open('output.bin', 'wb') as f:
arr.tofile(f)
# 现在'output.bin'文件包含数组的数据
tolist()
返回转换为普通列表的数组。
import array
arr = array.array('i', [1, 2, 3])
list_data = arr.tolist()
print(list_data) # 输出:[1, 2, 3]
tobytes()
返回转换为字节字符串的数组。
import array
arr = array.array('i', [1, 2, 3])
byte_data = arr.tobytes()
print(byte_data) # 输出:b'\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00'
用法举例
实例1
import array
# 创建一个浮点数类型的array实例
float_array = array.array('f', [1.0, 2.0, 3.0, 4.0, 5.0])
# 打印原始数组
print("Original Array:", float_array)
# 计算每个元素的平方
squared_array = array.array('f')
for num in float_array:
squared_array.append(num ** 2)
# 打印平方数组
print("Squared Array:", squared_array)
# 计算每个元素的立方
cubed_array = array.array('f')
for num in float_array:
cubed_array.append(num ** 3)
# 打印立方数组
print("Cubed Array:", cubed_array)
# 计算平方和立方数组的和
sum_squared = sum(squared_array)
sum_cubed = sum(cubed_array)
# 打印和
print("Sum of Squared:", sum_squared)
print("Sum of Cubed:", sum_cubed)输出结果:
Original Array: array('f', [1.0, 2.0, 3.0, 4.0, 5.0])
Squared Array: array('f', [1.0, 4.0, 9.0, 16.0, 25.0])
Cubed Array: array('f', [1.0, 8.0, 27.0, 64.0, 125.0])
Sum of Squared: 55.0
Sum of Cubed: 225.0
实例2
import array
# 原始字符串
original_string = "Hello, World!"
# 将字符串转换为字符数组
# 注意:'u' 类型用于存储 Unicode 字符,但在 Python 3 中,'u' 类型已被废弃
# 我们应该使用 'U' 类型来存储 Unicode 字符(码点),但这通常用于宽字符集
# 在此示例中,我们将使用字节数组 'b' 并通过编码字符串来处理它
# 编码原始字符串为字节
encoded_string = original_string.encode('utf-8')
# 创建一个字节类型的array实例
byte_array = array.array('b', encoded_string)
# 打印字节数组
print("Byte Array:", byte_array)
# 查找特定字节(例如查找 'o' 字符的字节表示)
# 注意:这里我们查找的是 'o' 字符的 UTF-8 编码的第一个字节
# 在 ASCII 中,'o' 的编码是 0x6F,但在 UTF-8 编码的字符串中,我们需要找到正确的字节序列
# 对于简单的 ASCII 字符,UTF-8 编码与 ASCII 编码相同
target_byte = ord('o') # 获取 'o' 字符的 ASCII 码点值
target_indices = [i for i, b in enumerate(byte_array) if b == target_byte]
print("Indices of 'o':", target_indices)
# 替换所有 'o' 字符的字节表示为另一个字符(例如 'x')
# 注意:直接替换可能破坏 UTF-8 编码的多字节字符序列
# 因此,这个例子仅适用于单字节字符(ASCII 范围内)的字符串
replacement_byte = ord('x') # 获取 'x' 字符的 ASCII 码点值
for i in target_indices:
byte_array[i] = replacement_byte
# 将修改后的字节数组转换回字符串
# 注意:如果替换了多字节字符的一部分,解码可能会失败
try:
modified_string = byte_array.tobytes().decode('utf-8')
print("Modified String:", modified_string)
except UnicodeDecodeError:
print("Decoding failed due to invalid UTF-8 sequence.")
# 注意:在处理包含非ASCII字符的字符串时,应该格外小心,
# 因为UTF-8编码可能会使用多个字节来表示一个字符。
# 在这种情况下,直接替换单个字节可能会破坏字符的编码。
输出结果:
Byte Array: array('b', [72, 101, 108, 108, 111, 44, 32, 87, 111, 114, 108, 100, 33])
Indices of 'o': [4, 8]
Modified String: Hellx, Wxrld!
实例3
import array
# 创建一个整数类型的array实例
int_array = array.array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 打印原始数组
print("Original Integer Array:", int_array)
# 将数组写入文件
with open('int_array.bin', 'wb') as f:
int_array.tofile(f)
# 打开文件以读取二进制数据
with open('int_array.bin', 'rb') as f:
# 读取整个文件到数组中
# 由于我们知道文件中的数据类型和大小,我们可以使用这些信息来创建数组
# 假设文件中的整数是32位的(即 'i' 表示整数),并且我们不知道有多少个整数
# 我们可以先读取文件的大小,然后除以整数的字节大小来得到整数的数量
file_size = f.seek(0, 2) # 移动到文件末尾以获取文件大小
num_ints = file_size // 4 # 假设整数是32位的(4字节)
f.seek(0) # 将文件指针重置回文件开头
# 创建一个空的array实例,用于存储读取的数据
read_array = array.array('i')
# 从文件中读取整数数据到数组中
read_array.fromfile(f, num_ints)
# 打印从文件中读取的数组
print("Array Read from File:", read_array)
# 验证两个数组是否相同
assert int_array == read_array
print("The arrays are the same.")输出结果:
Original Integer Array: array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Array Read from File: array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
The arrays are the same.
完。