编辑:OAK中国
首发:oakchina.cn
喜欢的话,请多多👍⭐️✍
内容可能会不定期更新,官网内容都是最新的,请查看首发地址链接。
▌前言
Hello,大家好,这里是OAK中国,我是Ashely。
每年都有朋友咨询我们零基础怎么做模型训练?后来发现大家对这方面需求较大,所以我们研发了OAK训练机,让小白用户能全程0代码体验模型训练并部署到OAK相机上。
虽然OAK训练机极大得简化了训练过程,但是在为特定目的训练模型时,收集数据集现在却成了最耗时的事情。而且自行收集的数据集可能存在版权和隐私问题,有些数据集只能保存在用户手上,不方便交给第三方训练。
那么有没有什么方案可以优化这一过程呢?
今天给大家分享一款超乎想象的解决方案——DataDreamer!
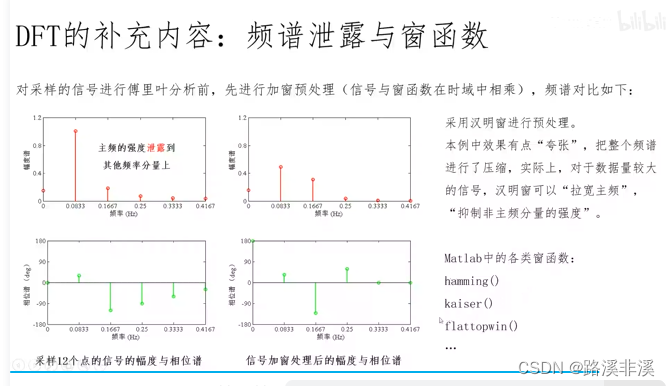
【开源】用DataDreamer生成10K图像训练yolov8头盔检测模型
▌DataDreamer:一步生成1000+带标注的图像
随着ChatGPT、Midjourney等生成式AI的爆火,数据在人工智能领域的重要性愈发弥足重要。而在模型训练这一任务中,往往第一步——收集数据,就让不少人头疼不已。传统的做法不仅耗时,还存在各种潜在风险。
那么想象一下,是否有可能绕过传统方式,可以在不需要真实世界数据的情况下创建数据集呢?DataDreamer让这一想法成为现实!
假设你需要一个应用程序来检测视频和图像中的机器人,你现在只需要输入一个命令即可生成数千张带标准的图像。
datadreamer –class_names robot
这种创新方法不仅节省了时间,而且为人工智能开发开辟了新的途径,不受传统数据收集方法的限制。
Prompt: A photo of robot interacting with nature in a serene field. The bot seems to meditate & appreciate the beauty of the environment as it soaks up the suns rays.
提示:机器人在宁静的田野中与大自然互动的照片。机器人似乎在冥想和欣赏环境的美丽,因为它吸收了太阳光线。

Prompt: A photo of robot assisting a human in the kitchen, as they cook a meal together, showing the collaboration between man and machine.
提示:机器人在厨房里协助人类一起做饭的照片,展示了人与机器之间的协作。

利用此数据集,你可以有效地训练专为OAK相机使用的模型,该模型能够在各种真实场景中检测真实的机器人。在下面的视频中,我们演示了在 DataDreamer 生成的 2,000 张图像数据集上训练的模型的性能。
DataDreamer:让创建自定义数据集轻松无比!还自带标注!
▌三步使用DataDreamer
DataDreamer 是一个库,它使你能够从头开始创建几乎任何你能想象到的类的自定义数据集。此过程简化为三个关键步骤:
- 提示生成:在这个阶段,我们利用强大的 Mistral-7B-Instruct-v0.1 来生成语义丰富的提示,这对于在生成的图像中准确描绘目标对象至关重要。对于更直接的方法,我们还提供了简单地连接目标对象的选项。
- 图像生成:用户可以在两个图像生成器之间进行选择。首先是 Stable Diffusion XL,它以遵守提示和卓越的图像质量而闻名,尽管生成速度较慢。第二种选择是 SDXL-Turbo,它提供了更快的生成时间,但在图像保真度方面略有妥协。
- 图像标注:在最后一步中,我们使用 OWLv2 等模型来注释生成的图像。此过程利用了一开始提供的类名,确保每个图像都根据你的规范准确标记。
通过集成这些先进的模型,DataDreamer 不仅简化了为计算机视觉领域的各种应用创建定制数据集的过程,而且还增强了效果。

▌性能比较:DataDreamer数据集VS真实数据集
用Datadreamer生成的数据集训练出来的模型,与用真实世界的数据集训练的模型相比,具体性能如何呢?我们做了一个有趣的实验。
我们使用PASCAL VOC数据集(这是目标检测中著名的基准),作为真实数据的基础。在此基础上,我们使用 DataDreamer 创建了一个可比较的数据集,针对 PASCAL VOC 数据集中存在的相同 20 个类别。
我们用于 DataDreamer 的命令如下:
datadreamer --save_dir generated_dataset_voc_2k --class_names aeroplane bicycle bird boat bottle bus car cat chair cow dining\ table dog horse motorbike person potted\ plant sheep sofa train tv --prompts_number 2000 --prompt_generator lm --num_objects_range 1 3 --image_generator sdxl
此命令生成一个包含 2000 个提示的数据集,每个图像聚焦 1 到 3 个对象,并使用 SDXL 图像生成器获得高质量结果。对于 17k 数据集,我们将提示数字更改为 17,000(与真实数据集中的图像数量相同),并将图像生成器更改为 sdxl-turbo。
下面,我们展示了来自生成的 DataDreamer 数据集的一些示例:

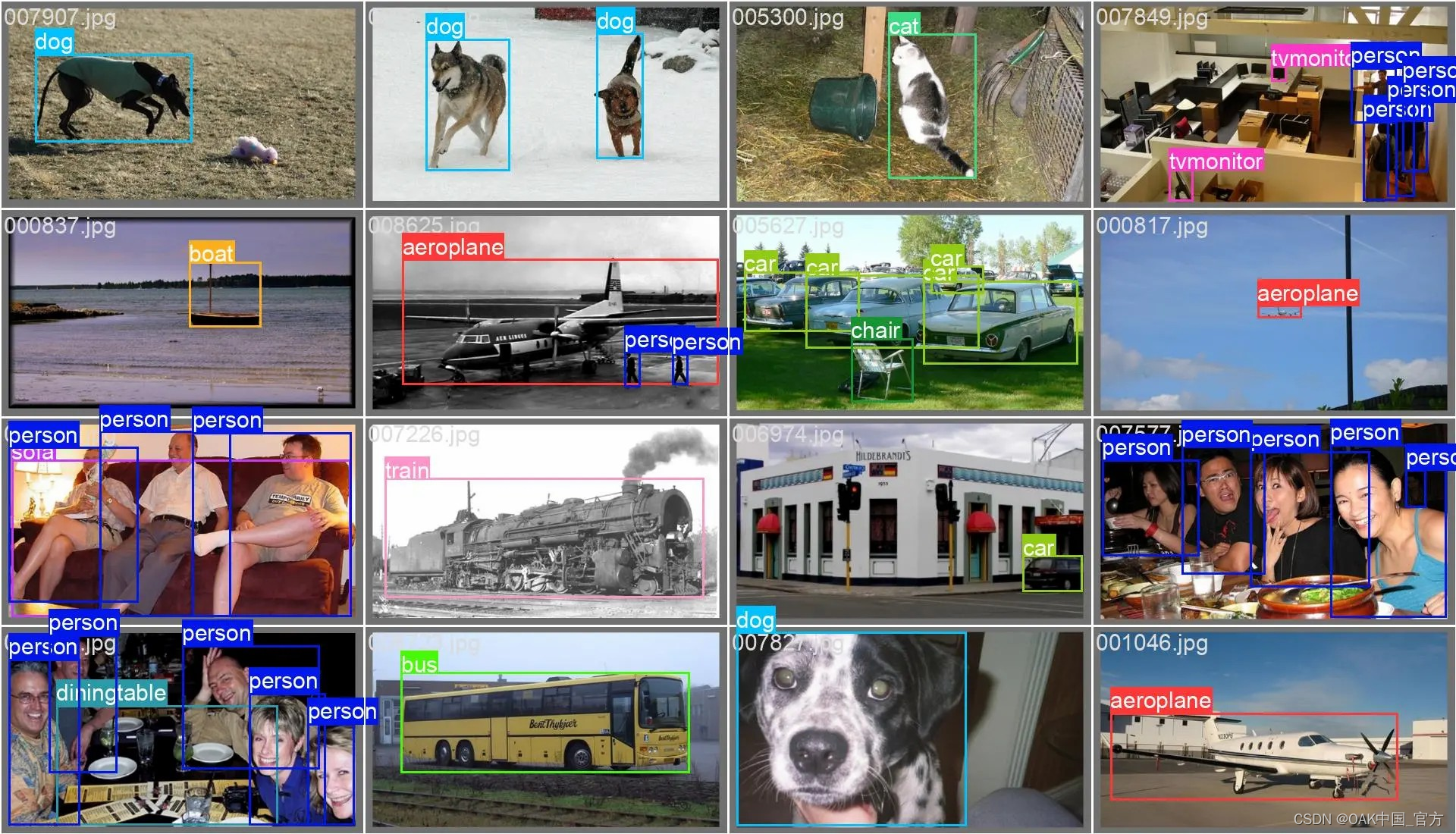
为了进行比较,以下是来自原始 VOC PASCAL 数据集的注释图像:
为了评估使用合成数据训练计算机视觉模型的有效性,我们开始使用 YOLOv8n 模型对两种不同的训练场景进行实验:
- 在合成数据上训练,然后在真实数据上进行微调:在这种方法中,我们首先完全在 DataDreamer 生成的合成数据集上训练 YOLOv8n 模型。一旦模型从这些生成的图像中学习,我们就会根据PASCAL VOC数据集中的真实数据对其进行微调。这个两步过程旨在通过微调来了解在合成数据上训练的模型对真实世界图像的适应程度。
- 仅使用真实数据进行训练:在这里,YOLOv8n 模型仅使用来自 PASCAL VOC 数据集的真实图像进行训练。这种传统方法可以作为基准,比较在训练过程中纳入合成数据的有效性。
通过比较这两种场景,我们旨在了解合成数据对模型学习能力及其在真实场景中的性能的影响。这种比较将阐明使用合成数据集进行初始训练的潜在优势,特别是在收集大量真实世界数据具有挑战性或不切实际的情况下。
▌结果
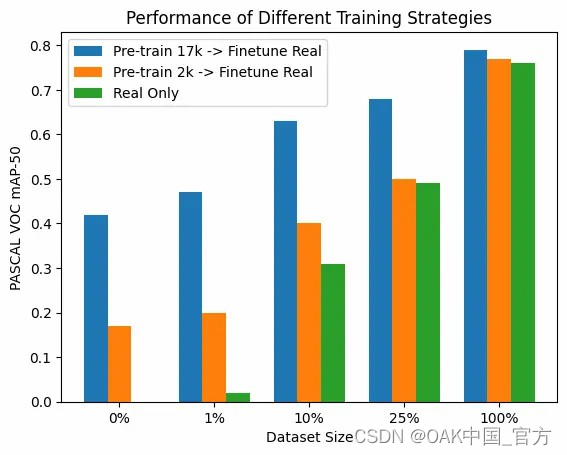
真实数据集大小:17k 张图片、1% – 170 张图片、10% – 1.7k 张图片、25% – 4.25k 张图片。性能是根据实际验证数据来衡量的。
根据结果,很明显DataDreamer 生成的合成数据集在真实标注图像稀缺或根本没有的情况下特别有用。对于收集大量真实世界数据不切实际或不可能的情况,这是一个至关重要的发现。
观察结果表明,虽然合成数据在数据稀缺的情况下显著提高了模型性能,但随着真实数据数量的增加,优势会减弱。这种逐渐缩小的差异表明,虽然合成数据是初始训练阶段的强大工具,尤其是在真实数据稀缺的情况下,但随着更多真实世界的数据可用于训练,其影响会减弱。
▌总结
通过简化数据集创建过程,DataDreamer 不仅让每个人都能访问它,而且让它变得高效——从经验丰富的数据科学家到该领域的初学者。它是数据收集领域的游戏变革者,使用户能够快速生成合成数据,训练初始模型,并在可用时使用真实世界的数据增强这些模型。
▌今后的工作
DataDreamer 背后的团队致力于发展和增强其功能,以满足 AI 模型训练日益增长的需求和复杂性。DataDreamer 的未来路线图包括几项令人兴奋的增强功能和新增功能:
扩展任务种类:我们计划集成其他任务,如实例分割和关键点检测。这些高级功能将允许更细致和详细的数据生成,以满足更广泛的人工智能应用。
加快数据集生成速度:重点将放在提高数据集生成效率上。此增强功能将显著减少创建大型、多样化数据集所需的时间,从而加快模型开发周期。
模型更新和添加:计划在数据集生成过程的每个步骤中使用的模型进行持续更新和添加。这将确保 DataDreamer 始终处于技术前沿,利用 AI 的最新进展来创建卓越的数据集。
功能增强:我们的目标是为 DataDreamer 添加更复杂的功能。这些功能旨在进一步减少对真实数据的依赖,允许使用最少的真实数据集训练稳健的模型。
通过这些改进,DataDreamer 不仅将简化模型训练的初始阶段,还将突破合成数据可以实现的界限,使其成为 AI 开发领域更强大的工具。
最后,我们邀请更广泛的社区加入我们这个激动人心的旅程。你的贡献,无论是以反馈、想法还是直接参与开发的形式,对于塑造 DataDreamer 的未来都是无价的。我们可以一起重新定义 AI 模型训练的前景。让我们携手合作,让 DataDreamer 不仅仅是一个工具,而是一个社区驱动的 AI 创新催化剂!
了解更多,请访问Github-luxonis/datadreamer,Colab notebook link。
▌参考资料
https://www.oakchina.cn/2024/02/22/datadreamer/
https://github.com/luxonis/datadreamer
OAK中国
| OpenCV AI Kit在中国区的官方代理商和技术服务商
| 追踪AI技术和产品新动态
戳「+关注」获取最新资讯↗↗