开篇语录:以架构师的能力标准去分析每个问题,过后由表及里分析问题的本质,复盘总结经验,并把总结内容记录下来。当你解决各种各样的问题,也就积累了丰富的解决问题的经验,解决问题的能力也将自然得到极大的提升。
励志做架构师的撸码人,认知很重要,可以订阅:架构设计专栏
撸码人平时大多数时间都在撸码或者撸码的路上,很少关注框架的一些底层原理,当出现问题时没能力第一时间解决问题,出现问题后不去层层剖析问题产生的原因,后续也就可能无法避免或者绕开同类的问题。因此不要单纯做Ctrl+c和Ctrl+V,而是一边仰望星空(目标规划),一边脚踏实地去分析每个问题。
一、背景
我们最近在使用mybatis执行批量数据插入,数据插入非常慢:每批次5000条数据大概耗时在3~4分钟左右。架构师的职责之一是疑难技术点攻关:要主动积极解决系统出现的问题,过后由表及里分析问题的本质,复盘总结经验,并把总结内容记录下来分享给团队,确保后续如何智慧地绕开同类问题。
以下是排查问题的过程和思路:
二、定位问题
1、全面打印日志:
日志是排查问题的第一手资料。
logback设置mybatis相关日志打印:
<logger name="org.mybatis.spring" level="DEBUG"/> <logger name="org.apache.ibatis" level="DEBUG"/> <!-- <logger name="java.sql.PreparedStatement" level="DEBUG"/>--> <!-- <logger name="java.sql.Statement" level="DEBUG"/>--> <!-- <logger name="java.sql.Connection" level="DEBUG"/>--> <!-- <logger name="java.sql.ResultSet" level="DEBUG"/>-->
2、初步定位问题
发现Creating a new SqlSession到查询语句耗时特别长:

3、初步排查问题:
有几个可能的原因导致创建新的SqlSession到查询语句耗时特别长:
1. 数据库连接池问题:如果连接池中没有空余的连接,则创建新的SqlSession时需要等待连接释放。可以通过增加连接池大小或者优化查询语句等方式来缓解该问题。
排除连接池问题:我们连接池比较大,通过mysql show processlist查看几乎没有慢查询的连接。
2. 网络延迟问题:如果数据库服务器和应用服务器之间的网络延迟较大,则创建新的SqlSession时会受到影响。可以通过优化网络配置或者将数据库服务器和应用服务器放在同一台机器上等方式来缓解该问题。
排除网络问题:ping mysql地址,耗时都在0.5ms左右。
3. 查询语句过于复杂:如果查询语句过于复杂,则会导致查询时间较长。可以通过优化查询语句或者增加索引等方式来缓解该问题。
排除复杂sql问题:简单insert 语句,通过mysql show processlist查看没有慢查询的连接。
<insert id="batchInsertDuplicate">
INSERT INTO b_table_#{day} (
<include refid="selectAllColumn"/>
) VALUES
<foreach collection="list" item="item" index="index" separator=",">
(
#{item.id ,jdbcType=VARCHAR },
#{item.sn ,jdbcType=VARCHAR },
#{item.ip ,jdbcType=VARCHAR },
.....
#{item.createTime ,jdbcType=TIMESTAMP },
#{item.updateTime ,jdbcType=TIMESTAMP }
)
</foreach>
ON DUPLICATE KEY UPDATE
`ip`=VALUES(`ip`),
`updateTime`=VALUES(`updateTime`)
</insert>4. 数据库服务器性能问题:如果数据库服务器性能较低,则创建新的SqlSession时会受到影响。可以通过优化数据库服务器配置或者升级硬件等方式来缓解该问题。
排除数据库服务器性能问题:mysql是8核16G,通过mysql show processlist查看没有慢查询的连接。
5. 应用服务器性能问题:如果应用服务器性能较低,则创建新的SqlSession时会受到影响。可以通过优化应用服务器配置或者升级硬件等方式来缓解该问题。
暂时无法确定:top查看cpu占用比较高90%,可能原因是mybatis框架处理sql语句引起cpu飙高。
三、定位cpu飙高耗时的方法
1、优化代码:
5000条改为500条批量插入,查看每个线程的耗时依然很高,说明是mybatis框架处理sql语句耗cpu。
top -H -p 18912
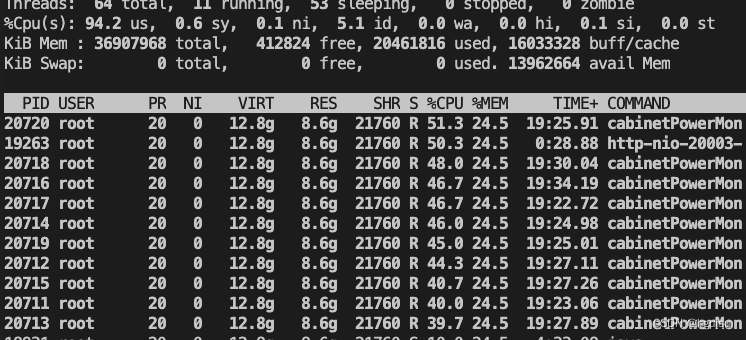
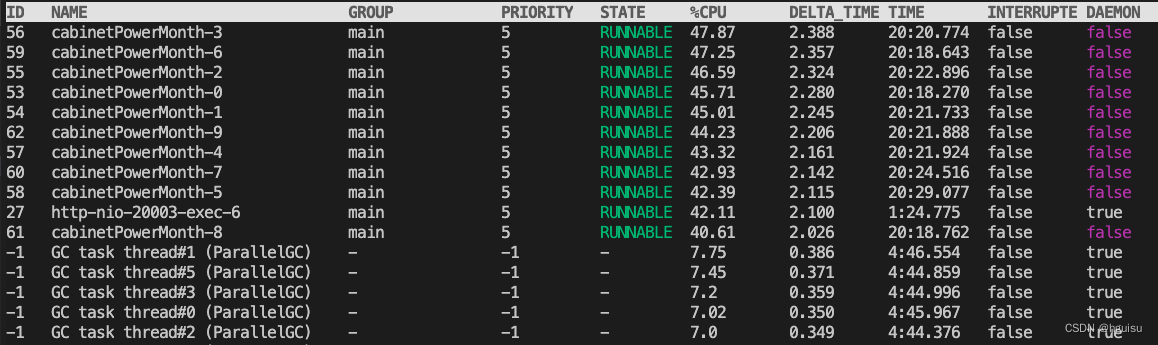
2、使用arthas定位:
curl -O https://arthas.aliyun.com/arthas-boot.jar java -jar arthas-boot.jar pid
使用dashboard可以查看每个线程耗cpu情况,和top -H 差不多:
3、trace方法耗时:
trace com.xxxx.class xxxmethod

逐步跟进去:

最后定位方法
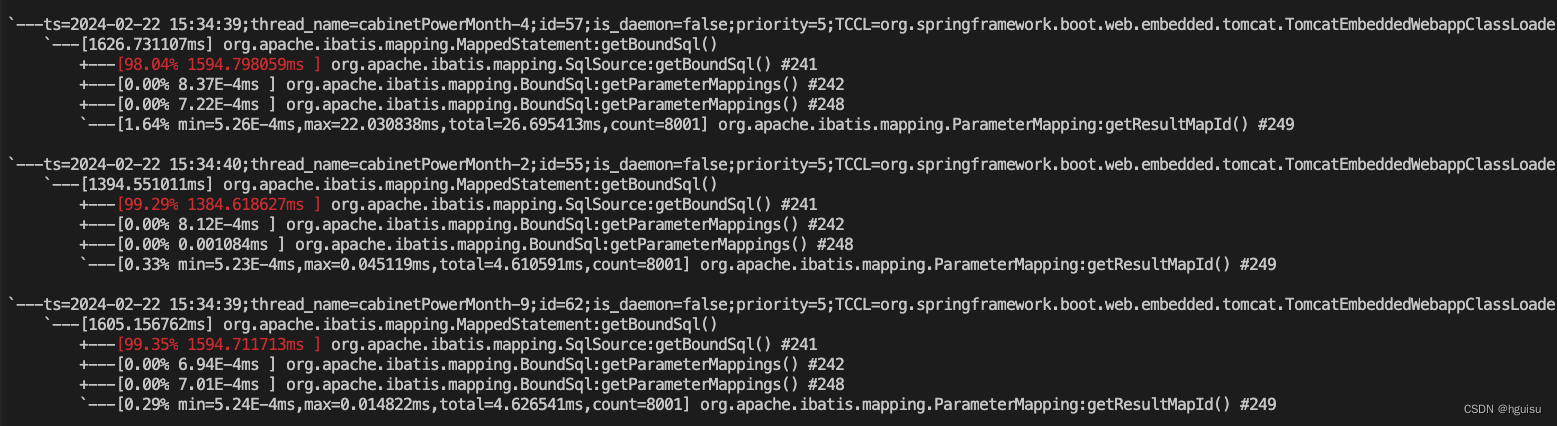
org.apache.ibatis.parsing.GenericTokenParser:parse耗时: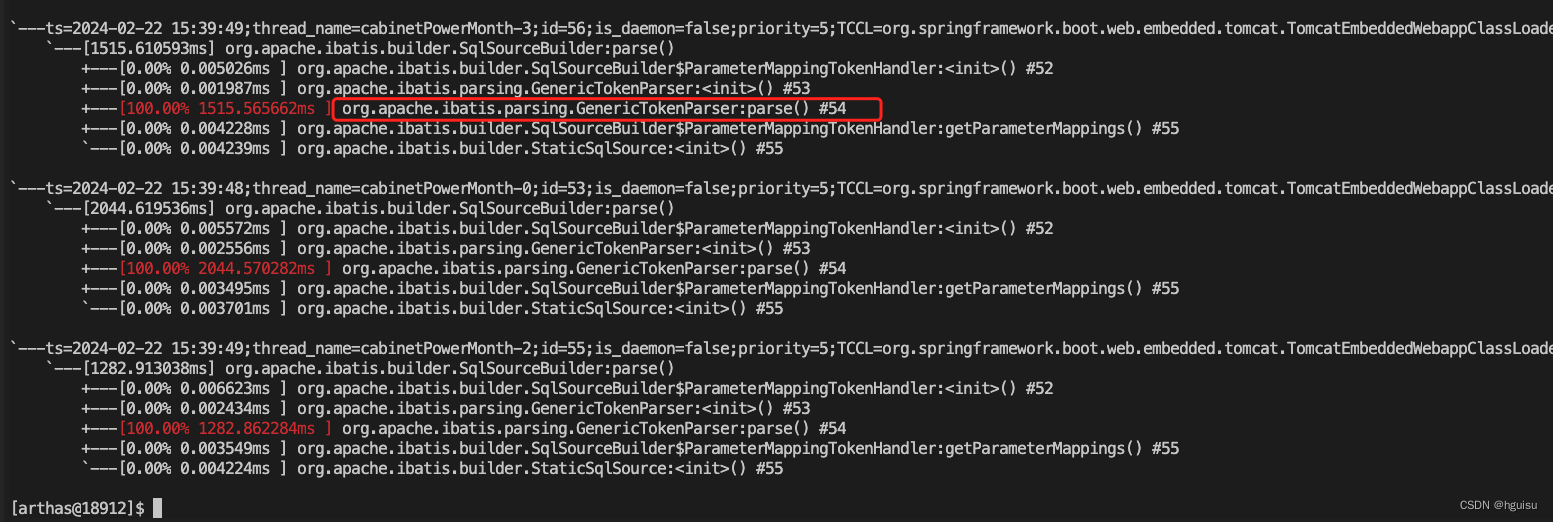
查看 org.apache.ibatis.parsing.GenericTokenParser:parse的源码:
public String parse(String text) {
StringBuilder builder = new StringBuilder();
if (text != null) {
String after = text;
int start = text.indexOf(this.openToken);
for(int end = text.indexOf(this.closeToken); start > -1; end = after.indexOf(this.closeToken)) {
String before;
if (end <= start) {
if (end <= -1) {
break;
}
before = after.substring(0, end);
builder.append(before);
builder.append(this.closeToken);
after = after.substring(end + this.closeToken.length());
} else {
before = after.substring(0, start);
String content = after.substring(start + this.openToken.length(), end);
String substitution;
if (start > 0 && text.charAt(start - 1) == '\\') {
before = before.substring(0, before.length() - 1);
substitution = this.openToken + content + this.closeToken;
} else {
substitution = this.handler.handleToken(content);
}
builder.append(before);
builder.append(substitution);
after = after.substring(end + this.closeToken.length());
}
start = after.indexOf(this.openToken);
}
builder.append(after);
}
return builder.toString();
}主要作用是对 SQL 进行解析,对转义字符进行特殊处理(删除反斜杠)并处理相关的参数(${}),如sql需要解析的标志${name} 替换为实际的文本。我们可以使用一个例子说明:
final Map<String,Object> mapper = new HashMap<String, Object>();
mapper.put("name", "张三");
mapper.put("pwd", "123456");
//先初始化一个handler
TokenHandler handler = new TokenHandler() {
@Override
public String handleToken(String content) {
System.out.println(content);
return (String) mapper.get(content);
}
};
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
System.out.println("************" + parser.parse("用户:${name},你的密码是:${pwd}"));通过源码发现,如果mapper定义的字段很多,for遍历条数比较大(下面红色部分):
<insert id="batchInsertDuplicate">
INSERT INTO b_table_#{day} (
<include refid="selectAllColumn"/>
) VALUES
<foreach collection="list" item="item" index="index" separator=",">
(
#{item.id ,jdbcType=VARCHAR },
#{item.sn ,jdbcType=VARCHAR },
#{item.ip ,jdbcType=VARCHAR },
.....
#{item.createTime ,jdbcType=TIMESTAMP },
#{item.updateTime ,jdbcType=TIMESTAMP }
)
</foreach>
ON DUPLICATE KEY UPDATE
`ip`=VALUES(`ip`),
`updateTime`=VALUES(`updateTime`)
</insert>
需要解析耗时较久,由于都是字符串遍历,特别耗CPU,因此可以看到cpu飙升很高。
四、解决
解决:直接执行原声sql。
不使用mapper方式拼接sql,而是手动拼接好sql,使用JdbcTemplate执行原声sql。