在我之前的几篇文章中分别应用了不同的tricks来改进yolov5模型如下:
加入针对小目标的SPD-Conv模块
《yolov5s融合SPD-Conv用于提升小目标和低分辨率图像检测性能实践五子棋检测识别》
加入BIFPN特征融合模块
《基于yolov5s+bifpn实践隧道裂缝裂痕检测》
加入注意力机制模块
《YOLOV5融合SE注意力机制和SwinTransformer模块开发实践的中国象棋检测识别分析系统》
感兴趣的话可以自行移步阅读。
本文主要是实际项目需要,针对摄像机拍摄到的奶牛的数据进行检测,考虑到真实情况复杂的问题,这里考虑将一些优化技术加入到原生的yolov5中以期来提升模型的检测性能。首先看下效果:
这里主要加入了:注意力模块CBAM、特征提取模块BIFPN和小目标优化技术SPD-Conv,基准模型是yolov5s,兼顾精度和速度。
直接看下yaml文件,如下:
#Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
#Backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 1]], # 1
[-1,1,SPD,[1]], # 2 -P2/4
[-1, 3, C3, [128]], # 3
[-1, 1, Conv, [256, 3, 1]], # 4
[-1,1,SPD,[1]], # 5 -P3/8
[-1, 6, C3, [256]], # 6
[-1, 1, Conv, [512, 3, 1]], # 7-P4/16
[-1,1,SPD,[1]], # 8 -P4/16
[-1, 9, C3, [512]], # 9
[-1, 1, Conv, [1024, 3, 1]], # 10-P5/32
[-1,1,SPD,[1]], # 11 -P5/32
[-1, 3, C3, [1024]], # 12
[-1, 1, SPPF, [1024, 5]], # 13
]
#Head
head:
[[-1, 1, Conv, [512, 1, 1]], #14
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #15
[[-1, 9], 1, BiFPND, [256, 256]], #16
[-1, 3, C3, [512, False]], #17
[-1, 1, Conv, [256, 1, 1]], #18
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #19
[[-1, 6], 1, BiFPND, [128, 128]], #20
[-1, 3, C3, [256, False]], #21
[-1, 1, Conv, [512, 3, 2]], #22
[[-1, 17, 9], 1, BiFPNT, [256, 256]], #23
[-1, 3, C3, [512, False]], #24
[-1, 1, Conv, [512, 3, 2]], #25
[[-1, 14], 1, BiFPND, [256, 256]], #26
[-1, 3, C3, [1024, False]], #27
[-1, 1, CBAM, [1024]], #28
[[21, 24, 28], 1, Detect, [nc, anchors]], #29 Detect
]数据集如下:
YOLO格式标注数据如下:
样例标注实例如下所示:
0 0.065234 0.385764 0.107031 0.095139
0 0.06582 0.539931 0.079297 0.165972
0 0.023633 0.762153 0.046484 0.165972
0 0.16875 0.738889 0.111719 0.177778
0 0.183203 0.663542 0.104688 0.200694
0 0.202344 0.571528 0.079687 0.218056
0 0.258008 0.528125 0.063672 0.189583
0 0.30293 0.500694 0.079297 0.261111
0 0.225195 0.313542 0.118359 0.127083
0 0.422461 0.544792 0.126172 0.135417
0 0.442383 0.636458 0.179297 0.095139
0 0.428711 0.715972 0.185547 0.094444
0 0.406836 0.843056 0.134766 0.223611VOC格式标注数据如下所示:
样例标注实例如下所示:
<annotation>
<folder>0000</folder>
<filename>60a4784df6bcca758ee48d5b.jpg</filename>
<path>60a4784df6bcca758ee48d5b.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>2560</width>
<height>1440</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>102</xmin>
<ymin>111</ymin>
<xmax>329</xmax>
<ymax>573</ymax>
</bndbox>
</object>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1</xmin>
<ymin>549</ymin>
<xmax>275</xmax>
<ymax>819</ymax>
</bndbox>
</object>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>19</xmin>
<ymin>1062</ymin>
<xmax>416</xmax>
<ymax>1322</ymax>
</bndbox>
</object>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>497</xmin>
<ymin>1103</ymin>
<xmax>1165</xmax>
<ymax>1373</ymax>
</bndbox>
</object>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1132</xmin>
<ymin>1076</ymin>
<xmax>1524</xmax>
<ymax>1325</ymax>
</bndbox>
</object>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1146</xmin>
<ymin>1306</ymin>
<xmax>1621</xmax>
<ymax>1438</ymax>
</bndbox>
</object>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1527</xmin>
<ymin>1089</ymin>
<xmax>1970</xmax>
<ymax>1435</ymax>
</bndbox>
</object>
</annotation>
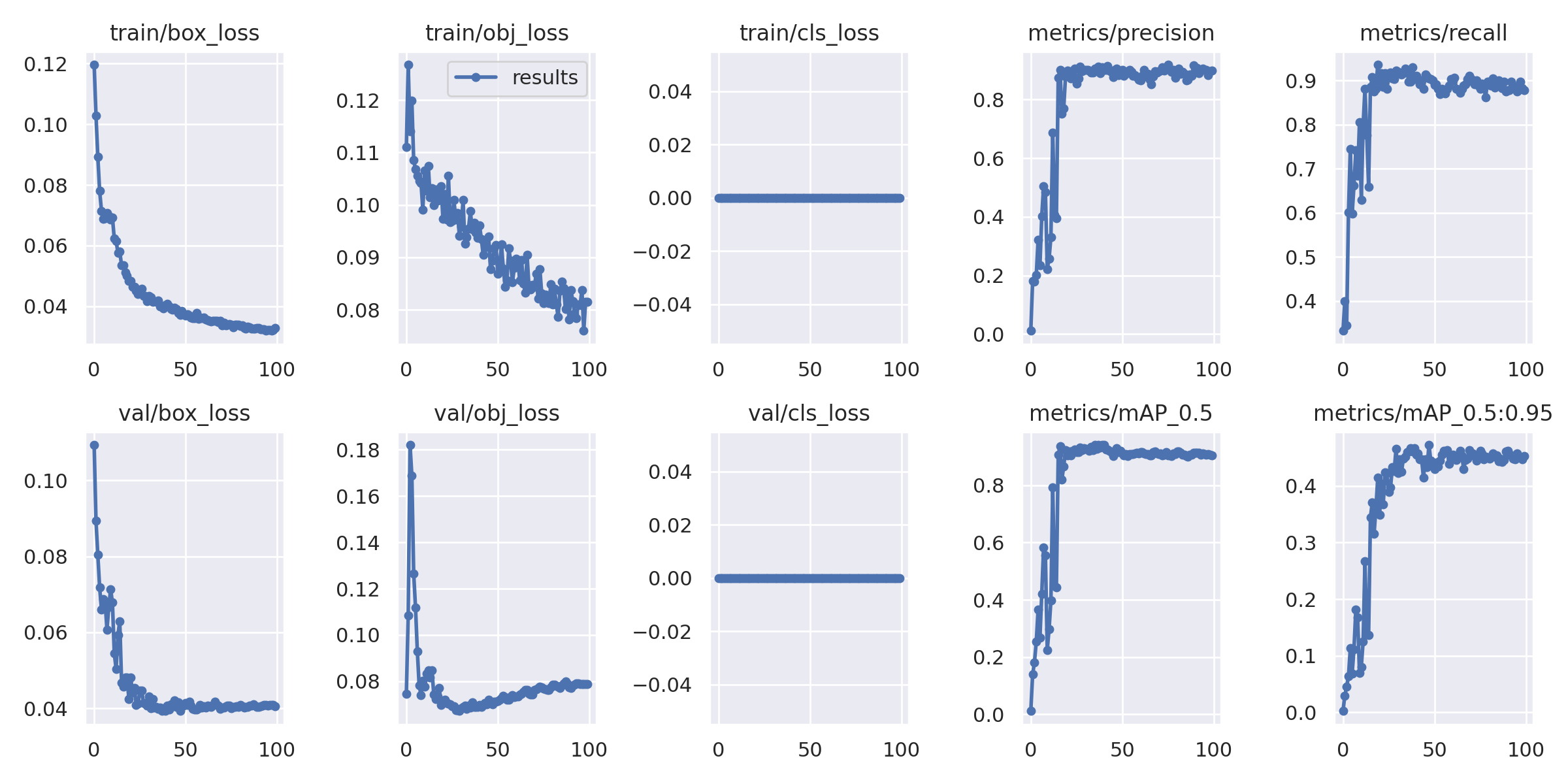
默认设定100次epoch计算,训练完成后结果目录如下所示:
标签数据可视化:
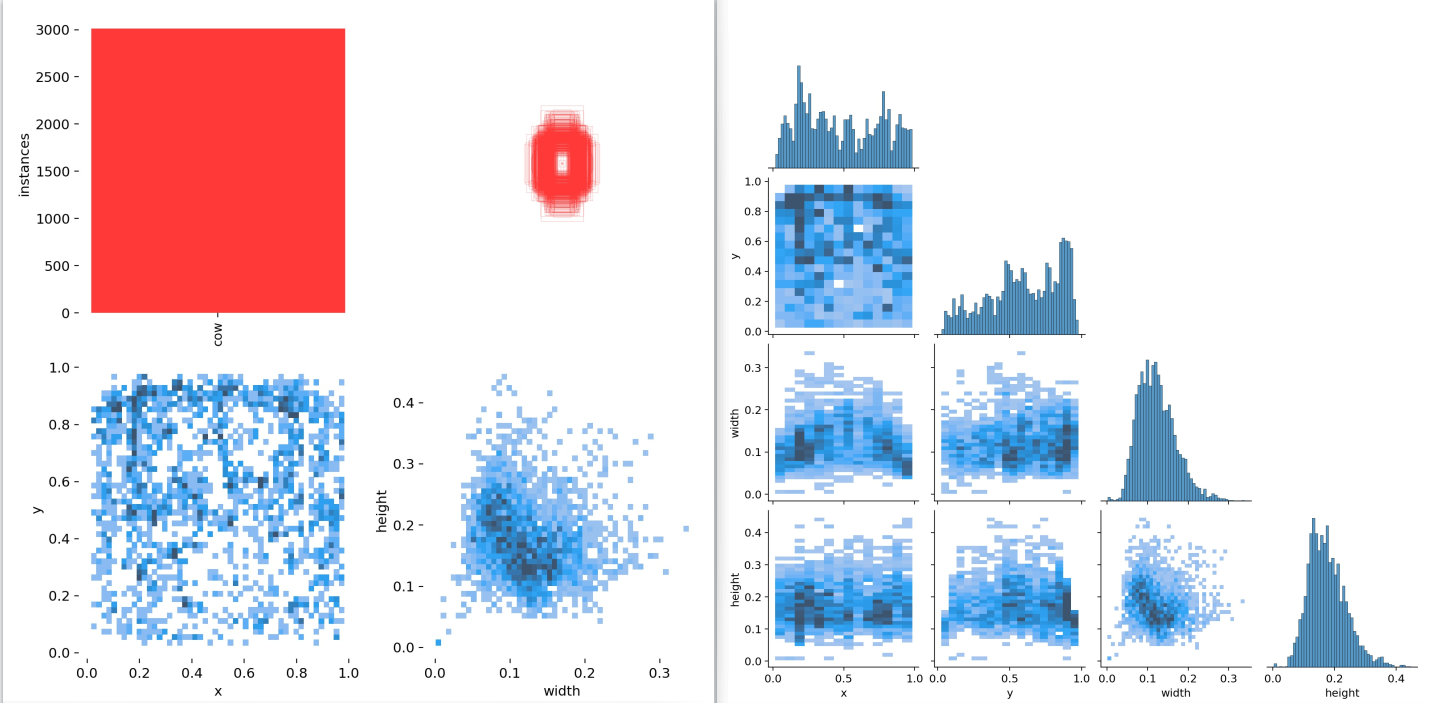
这里只有一个类别。
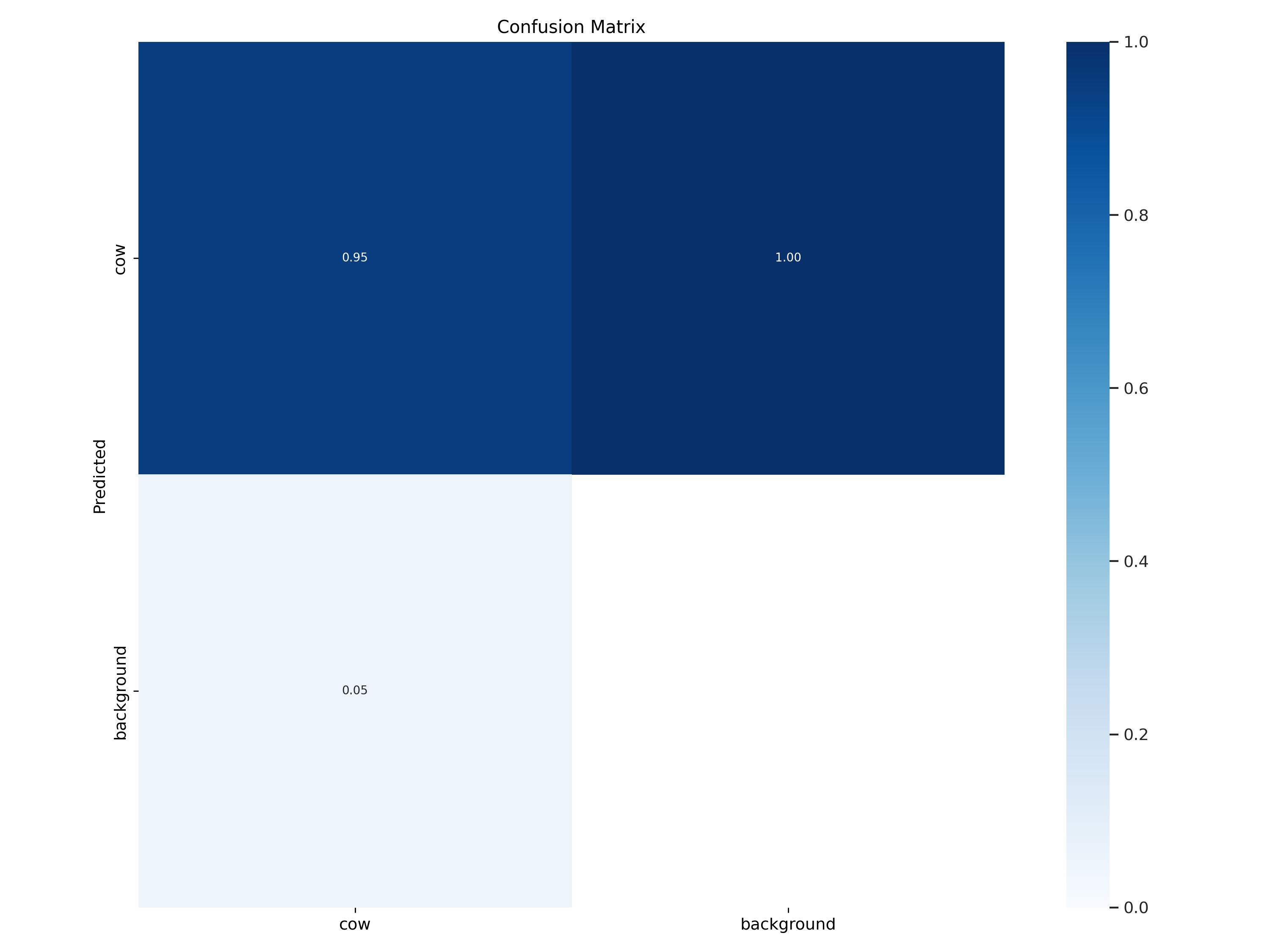
混淆矩阵:
训练过程指标可视化:
F1值曲线和PR曲线:
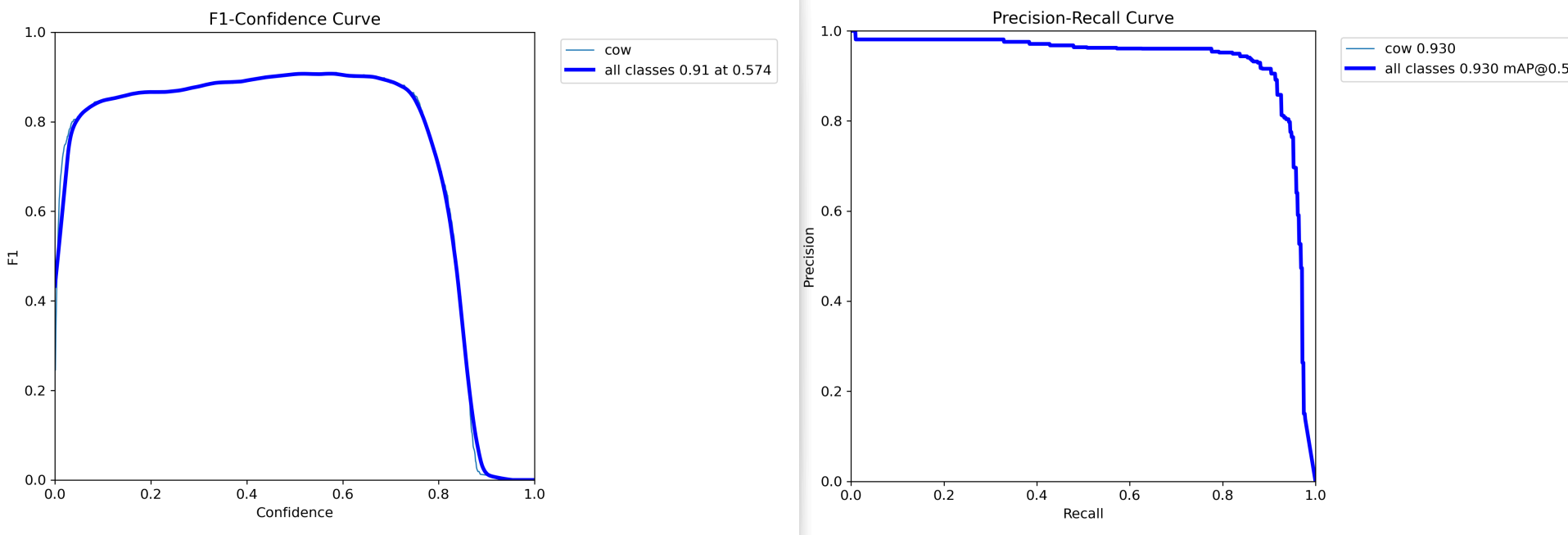
从检测结果样例上面来直观看的话效果还是很不错的,结合F1值曲线也不难印证这一点。
![[数据结构]栈和队列](https://img-blog.csdnimg.cn/87aa07754158440fa6fa92046f49d6b4.png)


![[Android]序列化原理Parcelable](https://img-blog.csdnimg.cn/99a589e6f99a43c19b8bc47b8e19a2be.png)