原文地址: https://debezium.io/blog/2023/02/04/ddd-aggregates-via-cdc-cqrs-pipeline-using-kafka-and-debezium/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
DDD Aggregates via CDC-CQRS Pipeline using Kafka & Debezium
February 4, 2023 by Purnima Jain
ddd cdc cqrs debezium kafka
在这篇文章中,我们将讨论在规范化的关系数据库(mysql)和去规范化的Nosql数据库(蒙戈数据库)之间的CDC-CQRS管道,这两个数据库是查询数据库,其结果是通过Debezim∓卡夫卡-流创建DDD集合。
您可以找到完整的示例源代码 在这里 .参阅 阅读。 关于构建和运行示例代码的详细信息.
这个例子围绕三个微服务:order-write-service ,order-aggregation-service 和order-read-service .这些服务是在java中作为"弹簧靴"应用程序实现的。
…order-write-service 在mysql数据库中各自的表中,提出了两个保留的端点--------------------------------------------------------Debezum对mysqb日志进行跟踪,以捕捉这些表中的任何事件,并向卡夫卡主题发布消息。这些话题是由order-aggregation-service 这是一个卡夫卡流应用程序,它将来自这两个主题的数据连接起来,创建一个订单集合对象,然后发布到第三个主题。蒙戈数据库接收器连接器使用这个主题,数据在蒙戈数据库中进行持久化,由order-read-service .
解决方案的总体架构见下图:
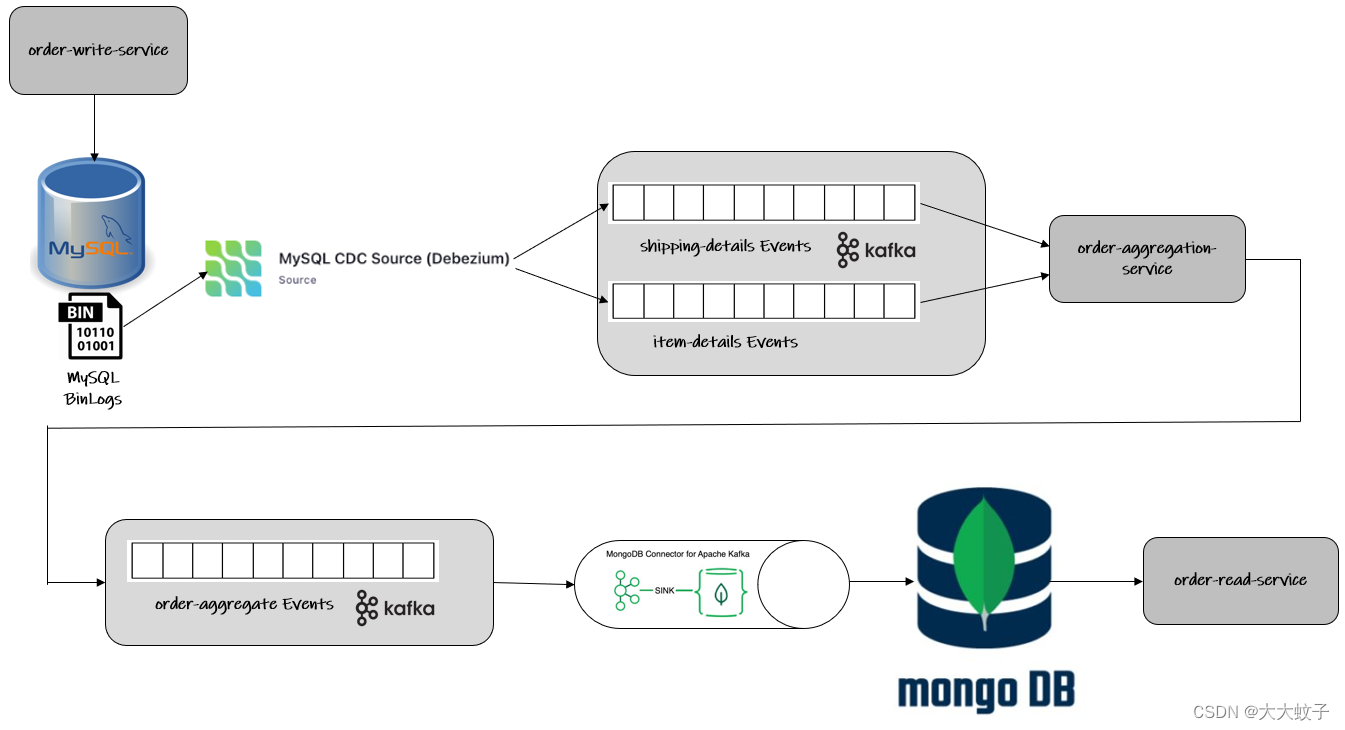
其他应用程序:订单书写服务
触发工作流启动的第一个组件是order-write-service .这已作为弹簧靴应用程序实现,并公开了两个休息点:
帖子:api/shipping-details 在mysql数据库中持久保存运输细节
帖子:api/item-details 在mysql数据库中保留项目细节
这两个端点都将它们的数据保存在mysql数据库中各自的表中。
命令数据库:mysql
上述休息端点的后端处理最终将数据持久化到mysql中各自的表中。
航运细节存储在一个表格中SHIPPING_DETAILS .物品的细节存储在一个表格中ITEM_DETAILS .
以下是SHIPPING_DETAILS 表格,一栏ORDER_ID 关键是:

以下是ITEM_DETAILS 表格,一栏ORDER_ID +ITEM_ID 关键是:
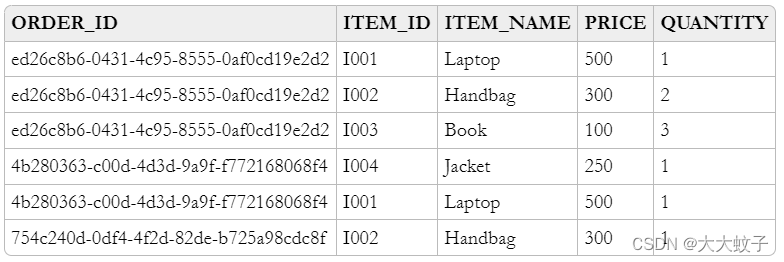
卡夫卡连接源连接器:MySQL
更改数据捕获(ccc)是一种从数据库事务日志中捕获更改事件的解决方案(在mysql的情况下称为宾基日志),并将这些事件转发给下游消费者EX。卡夫卡主题。
Debezum是一个为更改数据捕获提供低延迟数据流平台的平台,它是在阿帕奇卡夫卡之上建立的。它允许将数据库行级更改作为事件捕获并发布到阿帕奇卡夫卡主题。我们设置和配置Debezum来监视我们的数据库,然后我们的应用程序为对数据库进行的每个行级更改消费事件。
在我们的案例中,我们将使用Debezimmysql源连接器来捕捉上述表中的任何新事件,并将其转发给阿帕奇卡夫卡。为了实现这一点,我们将通过将以下JSON请求发送到卡夫卡连接的其余API来注册我们的连接器:
{
“name”: “app-mysql-db-connector”,
“config”: {
“connector.class”: “io.debezium.connector.mysql.MySqlConnector”,
“tasks.max”: “1”,
“database.hostname”: “mysql_db_server”,
“database.port”: “3306”,
“database.user”: “custom_mysql_user”,
“database.password”: “custom_mysql_user_password”,
“database.server.id”: “184054”,
“database.server.name”: “app-mysql-server”,
“database.whitelist”: “app-mysql-db”,
“table.whitelist”: “app-mysql-db.shipping_details,app-mysql-db.item_details”,
“database.history.kafka.bootstrap.servers”: “kafka_server:29092”,
“database.history.kafka.topic”: “dbhistory.app-mysql-db”,
“include.schema.changes”: “true”,
“transforms”: “unwrap”,
“transforms.unwrap.type”: “io.debezium.transforms.ExtractNewRecordState”
}
}
上述配置是基于1.9.5.最后。请注意,如果您试图使用Debezum2.0+的演示,上面的一些配置属性有了新的名称,配置将需要一些调整。
它建立了一个io.debezium.connector.mysql.MySqlConnector ,从指定的mysql实例捕获更改。请注意,通过表格包括清单,只对SHIPPING_DETAILS 和ITEM_DETAILS 可捕捉到表格。它还应用一个命名为单一消息转换(SMT)ExtractNewRecordState 它提取了after 场来自卡夫卡记录中的德贝兹改变事件。SMT只替换了原来的更改事件。after 创建一个简单的卡夫卡记录。
默认情况下,卡夫卡主题名称是"服务器.架构.表名",根据我们的连接器配置,它可以翻译为:
app-mysql-server.app-mysql-db.item_details
app-mysql-server.app-mysql-db.shipping_details
卡夫卡河应用:订单集合服务
卡夫卡河应用,即order-aggregation-service ,将处理来自卡夫卡CDC-主题的数据。这些主题接收疾病预防控制中心事件的基础是在mysql中找到的运输细节和项目细节关系。
在此基础上,可以建立如下用于创建和维护DDD订单的克兰兹拓扑结构。
应用程序读取来自运输细节-CDC主题的数据。由于卡夫卡主题记录是用德贝齐姆JSON格式与未包装的信封,我们需要解析订单标识和运输详细信息,以创建一个以订单标识为键、以运输详细信息为值的KTAD。
// Shipping Details Read
KStream<String, String> shippingDetailsSourceInputKStream = streamsBuilder.stream(shippingDetailsTopicName, Consumed.with(STRING_SERDE, STRING_SERDE));
// Change the Json value of the message to ShippingDetailsDto
KStream<String, ShippingDetailsDto> shippingDetailsDtoWithKeyAsOrderIdKStream = shippingDetailsSourceInputKStream
.map((orderIdJson, shippingDetailsJson) -> new KeyValue<>(parseOrderId(orderIdJson), parseShippingDetails(shippingDetailsJson)));
// Convert KStream to KTable
KTable<String, ShippingDetailsDto> shippingDetailsDtoWithKeyAsOrderIdKTable = shippingDetailsDtoWithKeyAsOrderIdKStream.toTable(
Materialized.<String, ShippingDetailsDto, KeyValueStore<Bytes, byte[]>>as(SHIPPING_DETAILS_DTO_STATE_STORE).withKeySerde(STRING_SERDE).withValueSerde(SHIPPING_DETAILS_DTO_SERDE));
同样,应用程序读取项目细节-CDC-主题的数据,并按一个列表中与同一订单相关的所有项目解析每个邮件到组的订单标识和项目标识-然后将其聚合到一个以订单标识为键、与该特定订单相关的项目列表作为值的KSab中。
// Item Details Read
KStream<String, String> itemDetailsSourceInputKStream = streamsBuilder.stream(itemDetailsTopicName, Consumed.with(STRING_SERDE, STRING_SERDE));
// Change the Key of the message from ItemId + OrderId to only OrderId and parse the Json value to ItemDto
KStream<String, ItemDto> itemDtoWithKeyAsOrderIdKStream = itemDetailsSourceInputKStream
.map((itemIdOrderIdJson, itemDetailsJson) -> new KeyValue<>(parseOrderId(itemIdOrderIdJson), parseItemDetails(itemDetailsJson)));
// Group all the ItemDtos for each OrderId
KGroupedStream<String, ItemDto> itemDtoWithKeyAsOrderIdKGroupedStream = itemDtoWithKeyAsOrderIdKStream.groupByKey(Grouped.with(STRING_SERDE, ITEM_DTO_SERDE));
// Aggregate all the ItemDtos pertaining to each OrderId in a list
KTable<String, ArrayList> itemDtoListWithKeyAsOrderIdKTable = itemDtoWithKeyAsOrderIdKGroupedStream.aggregate(
(Initializer<ArrayList>) ArrayList::new,
(orderId, itemDto, itemDtoList) -> addItemToList(itemDtoList, itemDto),
Materialized.<String, ArrayList, KeyValueStore<Bytes, byte[]>>as(ITEM_DTO_STATE_STORE).withKeySerde(STRING_SERDE).withValueSerde(ITEM_DTO_ARRAYLIST_SERDE));
由于两个KTAS都有订单作为键,使用订单很容易将它们连接起来创建一个叫做订单集合的聚合。订单集合是通过从船舶细节和项目细节中吸收数据而创建的一个复合对象。然后,这个订单集合写到一个订单集合卡夫卡主题。
// Joining the two tables: shippingDetailsDtoWithKeyAsOrderIdKTable and itemDtoListWithKeyAsOrderIdKTable
ValueJoiner<ShippingDetailsDto, ArrayList, OrderAggregate> shippingDetailsAndItemListJoiner = (shippingDetailsDto, itemDtoList) -> instantiateOrderAggregate(shippingDetailsDto, itemDtoList);
KTable<String, OrderAggregate> orderAggregateKTable = shippingDetailsDtoWithKeyAsOrderIdKTable.join(itemDtoListWithKeyAsOrderIdKTable, shippingDetailsAndItemListJoiner);
// Outputting to Kafka Topic
orderAggregateKTable.toStream().to(orderAggregateTopicName, Produced.with(STRING_SERDE, ORDER_AGGREGATE_SERDE));
卡夫卡连接槽连接器:蒙戈布连接器
接收器连接器是一个卡夫卡连接器,它读取来自阿帕奇卡夫卡的数据并将数据写入一些数据库。使用蒙戈数据库接收器连接器,很容易将DDD聚合物写入蒙戈数据库。它所需要的只是一个配置,可以发布到卡夫卡连接的其余API,以便运行连接器。
{
“name”: “app-mongo-sink-connector”,
“config”: {
“connector.class”: “com.mongodb.kafka.connect.MongoSinkConnector”,
“topics”: “order_aggregate”,
“connection.uri”: “mongodb://root_mongo_user:root_mongo_user_password@mongodb_server:27017”,
“key.converter”: “org.apache.kafka.connect.storage.StringConverter”,
“value.converter”: “org.apache.kafka.connect.json.JsonConverter”,
“value.converter.schemas.enable”: false,
“database”: “order_db”,
“collection”: “order”,
“document.id.strategy.overwrite.existing”: “true”,
“document.id.strategy”: “com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy”,
“transforms”: “hk,hv”,
“transforms.hk.type”: “org.apache.kafka.connect.transforms.HoistField
K
e
y
"
,
"
t
r
a
n
s
f
o
r
m
s
.
h
k
.
f
i
e
l
d
"
:
"
i
d
"
,
"
t
r
a
n
s
f
o
r
m
s
.
h
v
.
t
y
p
e
"
:
"
o
r
g
.
a
p
a
c
h
e
.
k
a
f
k
a
.
c
o
n
n
e
c
t
.
t
r
a
n
s
f
o
r
m
s
.
H
o
i
s
t
F
i
e
l
d
Key", "transforms.hk.field": "_id", "transforms.hv.type": "org.apache.kafka.connect.transforms.HoistField
Key","transforms.hk.field":"id","transforms.hv.type":"org.apache.kafka.connect.transforms.HoistFieldValue”,
“transforms.hv.field”: “order”
}
}
查询数据库:
将DDD聚合写入数据库order_db 在收藏中order 在蒙戈德。订单会变成_id 在餐桌上order 列存储订单-集合为JSON。
其他应用:订单-阅读-服务
在蒙戈数据库中持久存在的订单集合通过一个休息端点提供。order-read-service .
获取:api/order/{order-id} 从蒙戈数据库检索订单
执行指令
提供了此博客的完整源代码 在这里 在基特布。先克隆这个存储库然后转换成cdc-cqrs-pipeline 目录。该项目提供一个为所有组件提供服务的码头组合文件:
Mysql
通过浏览器管理mysql(原名为ppin行政人员)
蒙戈德
蒙戈快递,通过浏览器管理蒙戈数据库
饲养员
相融合的卡夫卡
卡夫卡连接
一旦所有服务启动,通过执行Create-MySQL-Debezium-Connector 和Create-MongoDB-Sink-Connector 分别要求cdc-cqrs-pipeline.postman_collection.json .执行请求Get-All-Connectors 验证连接器是否已正确创建。
更改为个别目录,并将三个弹簧靴应用程序展开:
order-write-service:在1号端口运行8070
order-aggregation-service:在1号端口运行8071
order-read-service:在1号端口运行8072
有了这个,我们的设置就完成了。
为了测试应用程序,执行请求Post-Shipping-Details 从邮递员收集到插入货运细节Post-Item-Details 插入特定订单ID的详细项目。
最后,执行Get-Order-By-Order-Id 在邮差集合中请求检索完整的订单聚合。
概括的
阿帕奇卡夫卡是服务间消息传递的高度可扩展和可靠的支柱。将阿帕奇卡夫卡置于整体架构的中心,也确保了所涉服务的脱钩。例如,如果解决方案的单个组件失败或在一段时间内无法使用,则将在稍后处理事件:在重新启动后,Debezum连接器将继续跟踪相关表,从它以前关闭的位置开始。同样,任何消费者将继续处理其先前抵消的主题。通过对已经成功处理的消息进行跟踪,可以检测到副本,并将其排除在重复处理之外。
当然,不同服务之间的此类事件管道最终是一致的,即:订单阅读服务等消费者可能比订单写作服务等生产者落后一些。通常情况下,这很好,可以用应用程序的业务逻辑来处理。此外,整个解决方案的端到端延迟通常较低(秒甚至次秒范围),这要归功于基于日志的变化数据捕获,它允许在接近实时的时间内发布事件。