1、
注意事项
1、预热
2、torch 异步
import torch
import time
torch.cuda.synchronize()
device = torch.device('cuda:2')
data_type = torch.float32
t1 = time.time()
a = torch.rand((40000000,512),dtype=data_type,device=device)
b = torch.rand((512,1),dtype=data_type,device=device)
t2 = time.time()
print('生成数据用时:',t2-t1)
#a = a.to(device)
#b = b.to(device)
t3 = time.time()
print('放入gpu用时:',t3-t2)
time.sleep(4)
#### 预热
t31 = time.time()
sim = torch.matmul(a, b)
print(torch.max(sim))
t32 = time.time()
print("第一次4000万数据耗时:",t32-t31)
t31 = time.time()
sim = torch.matmul(a, b)
print(torch.max(sim))
t32 = time.time()
print("第二次4000万数据耗时:",t32-t31)
a_ = 0
t4 = time.time()
for i in range(100):
sim = torch.matmul(a, b)
#a_ = torch.max(sim)
a_ += sim[0][0]
#torch.cuda.synchronize() 注意这条不行,从网上看到的说可以等到结果,结果不太行
print(a_)
t5 = time.time()
print("1000次测试4000万数据总耗时:",(t5-t4))
注:这里测试了几种在得到结果之后再统计时间的操作。均可以实现较为准确的统计(print(a_))一定要放在t5前。否则会直接跳出结果
注:torch.cuda.synchronize() 没毛用!
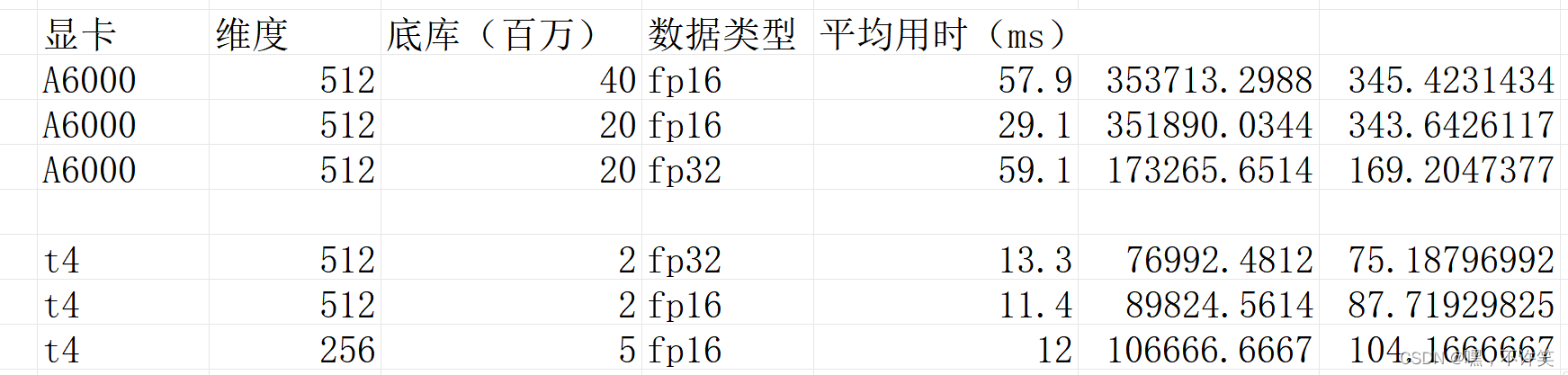
这里放出测试的结果: