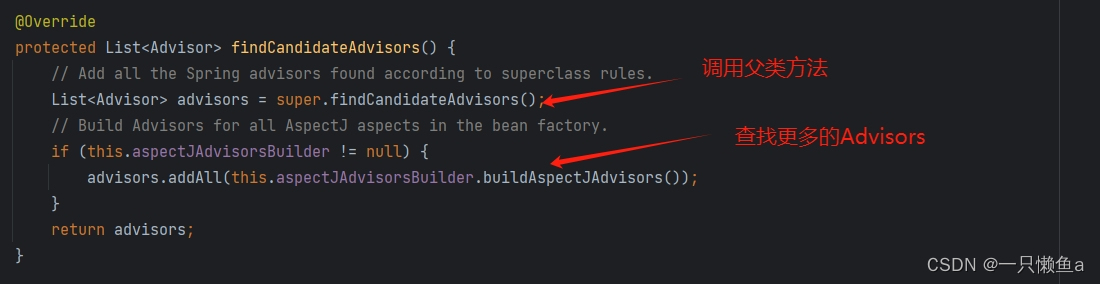
DRF自带的过滤
- 第一个 DjangoFilterBackend 是需要安装三方库见[搜索:多字段筛选]
- 两外两个是安装注册了rest_framework就有。

如上图,只要配置了三个箭头所指的方向,就能使用。
第一个单字段过滤
用户视图集中加上filterset_fields 后,后端搜索过滤就生效了
特点:
- 是准确匹配,如搜王老五,能搜索来,搜老五,是搜不出来的
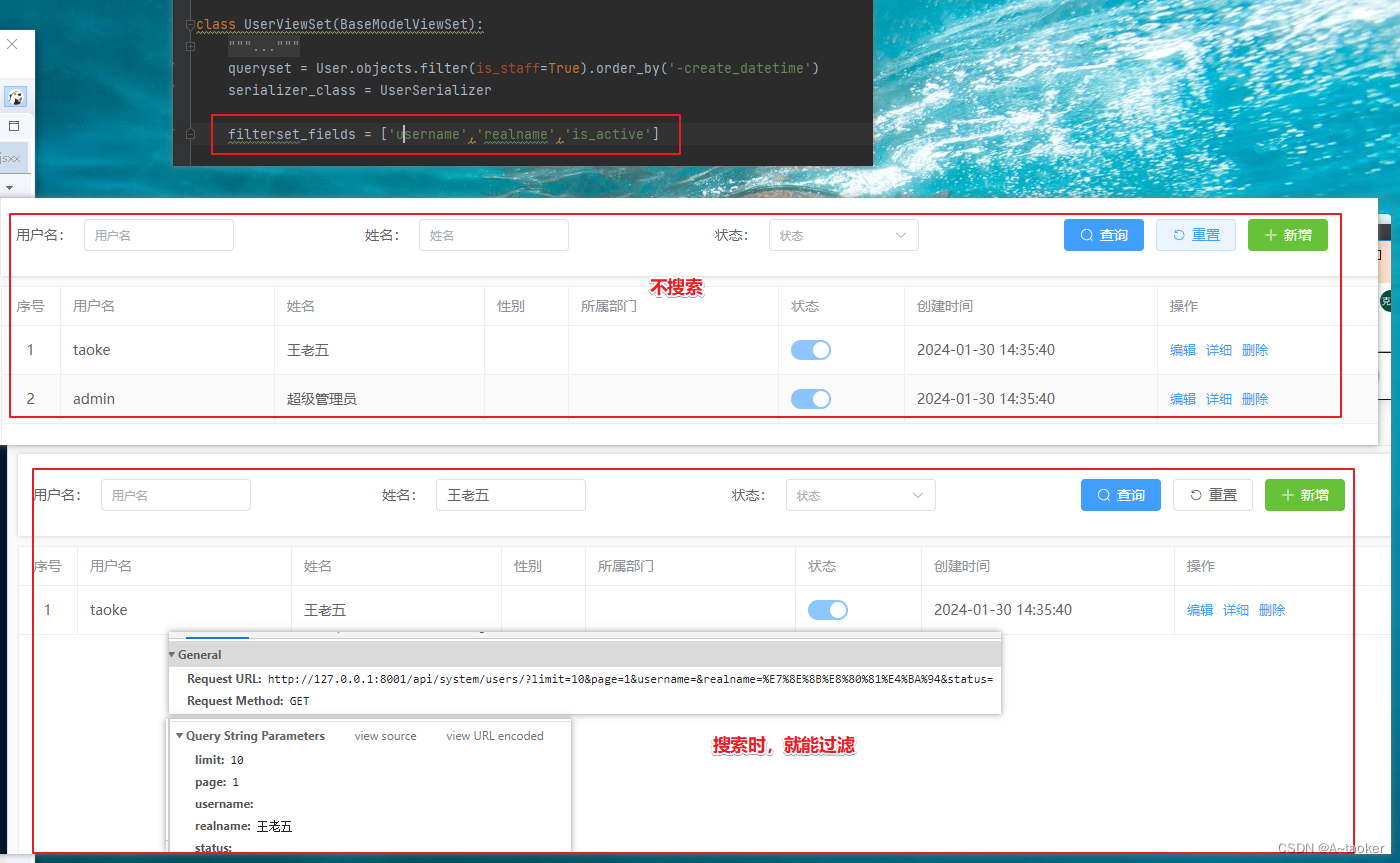
第二个关键字过滤
配置SearchFilter, 即可实现。就不举例了。
# 后端过滤、搜索与排序
filter_backends = [DjangoFilterBackend, SearchFilter, OrderingFilter]
现在已经知道使用djangRF 视图集定义的接口,比如列表接口 可以加参数 ?search=xxx , 进行数据的过滤。
第三个排序
也不举例了,见 添加链接描述
这三个的原理
简单总结得说:
- 就是DjangoFilterBackend, SearchFilter, OrderingFilter三个类中有一个filter_queryset的方法, 传入一个querySet,返回过滤后的querySet。
不清楚得看下面源码说明, 接口都使用了 filter_queryset 方法。
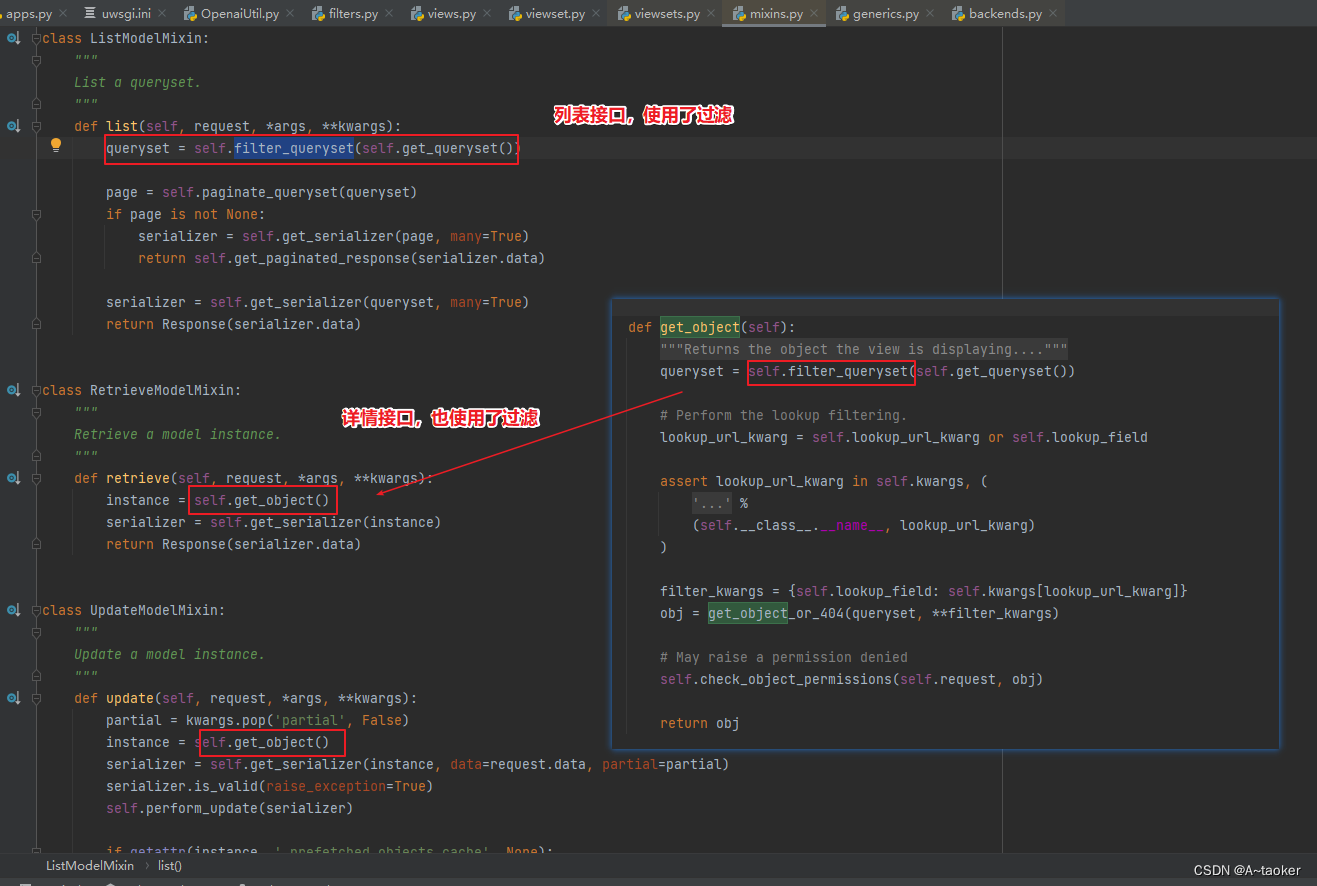
而filter_queryset 是GenericAPIView 类中的代码如下:
(大致逻辑:给一个querySet,返回出过滤后的 querySet)
def filter_queryset(self, queryset):
"""
Given a queryset, filter it with whichever filter backend is in use.
You are unlikely to want to override this method, although you may need
to call it either from a list view, or from a custom `get_object`
method if you want to apply the configured filtering backend to the
default queryset.
"""
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
结合已有知识可知,
filter_backends = [DjangoFilterBackend, SearchFilter, OrderingFilter]
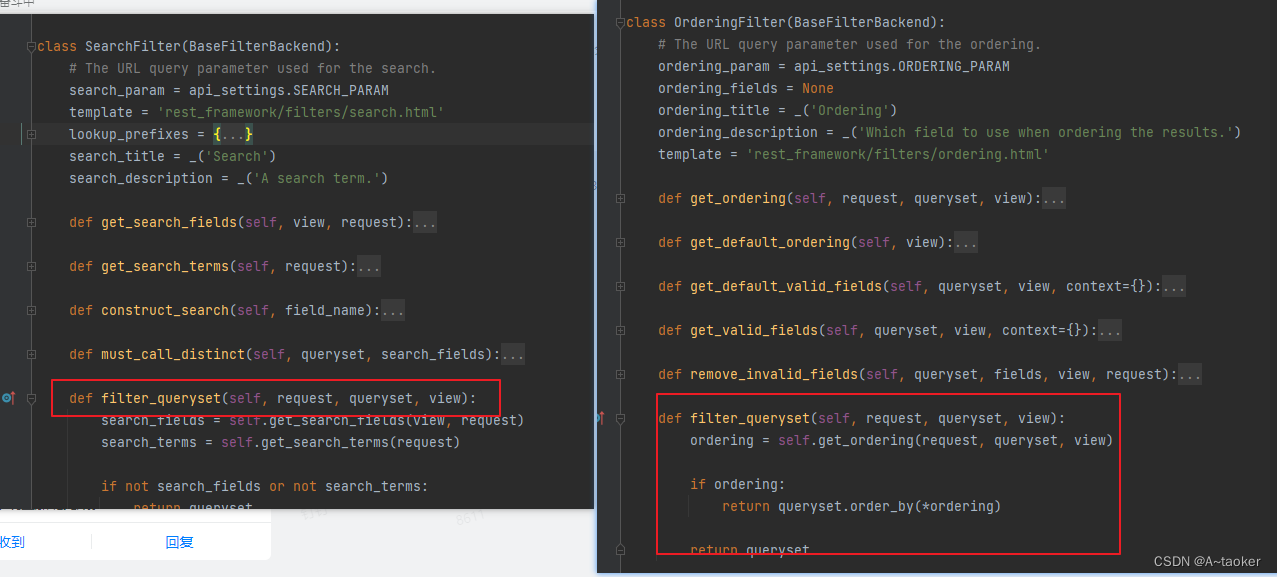
继续观察上面代码的写法(如下图)

每一项backend后面都.filter_queryset ,
说明SearchFilter 或者 OrderingFilter 和DjangoFilterBackend 这是三个类,且里面都有filter_queryset 的方法:
看源码,果然是 ,它们的filter_queryset 里面就有过滤逻辑:
自定义过滤
针对第一个单字段过滤,修改成模糊匹配
找个地方写py文件,如在utils包下,新建一个取名为filters.py 的文件
import django_filters
from system.models import User
class UsersManageFilter(django_filters.rest_framework.FilterSet):
"""
用户管理 简单过滤器
URL格式:http://127.0.0.1:8100/?start_time=2022-10-02 08:00:00&end_time=2023-12-31 23:59:59
"""
# 1.创建时间从
start_time = django_filters.DateTimeFilter(field_name='create_datetime', lookup_expr='gte')
# 2.创建时间到
end_time = django_filters.DateTimeFilter(field_name='create_datetime', lookup_expr='lte')
# 3.用户名-模糊搜索
username = django_filters.CharFilter(field_name='username', lookup_expr='icontains')
# 4.姓名号码-模糊搜索
realname = django_filters.CharFilter(field_name='mobile', lookup_expr='icontains')
class Meta:
model = User
fields = []
在到视图集下,写 filterset_class即可生效。

除了改成模糊支持模糊搜索,还可以比如根据某个字段的时间范围来过滤等等
具体可以搜索 :django_filters如何使用
根据原理自己写一个过滤类,比如实现数据过滤
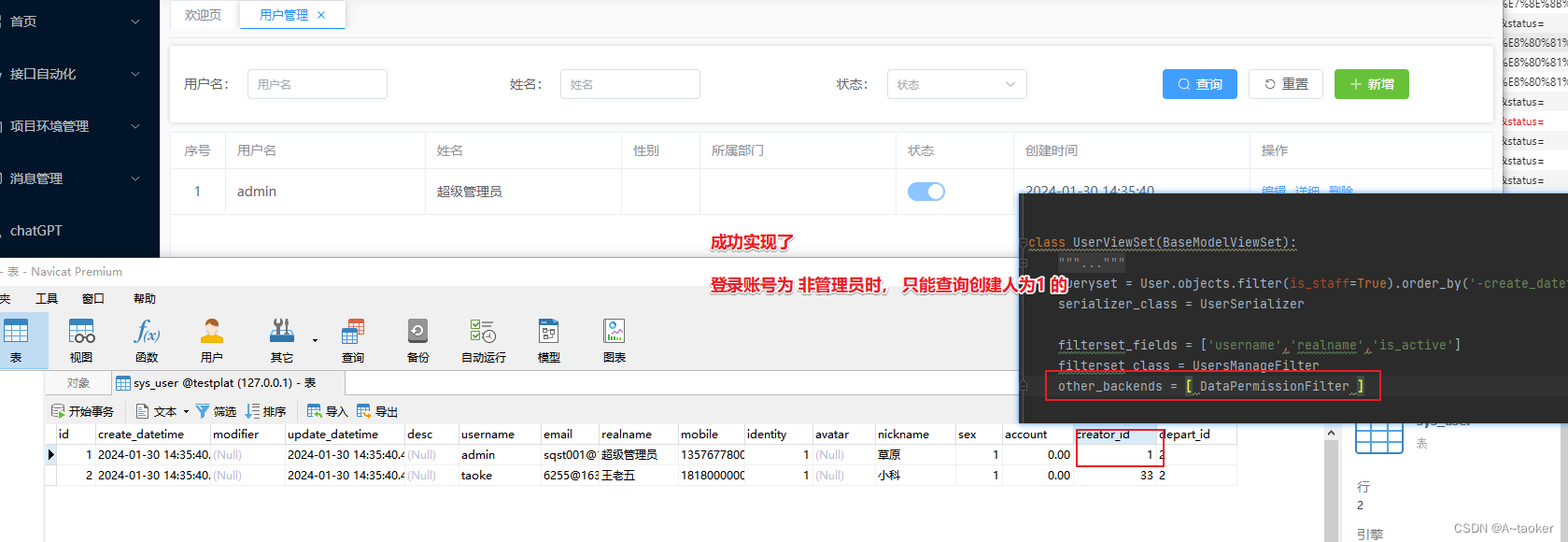
同样在filters.py中, 自定义一个类,需要继承BaseFilterBackend,写一个filter_queryset方法即可、 里面就可以写根据用户角色,角色的权限来返回不同的数据了
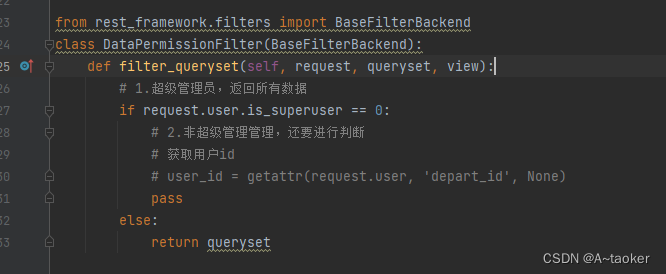
同时,视图集中,在filter_backends中,要加上这个类。

这里先写一个简单易懂的例子,试试
- 根据登录用户,超级管理员就返回所有的数据
- 非超级管理员,假设只能看见自己创建的数据
from rest_framework.filters import BaseFilterBackend
class DataPermissionFilter(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
# 1.超级管理员,返回所有数据
if request.user.is_superuser == 0:
# 2.非超级管理管理,还要进行判断
# 获取用户id
user_id = getattr(request.user, 'id', None)
# 返回创建者 登录人自己创建的数据
return queryset.filter(creator=user_id)
else:
return queryset
验证:为非超级管理员时
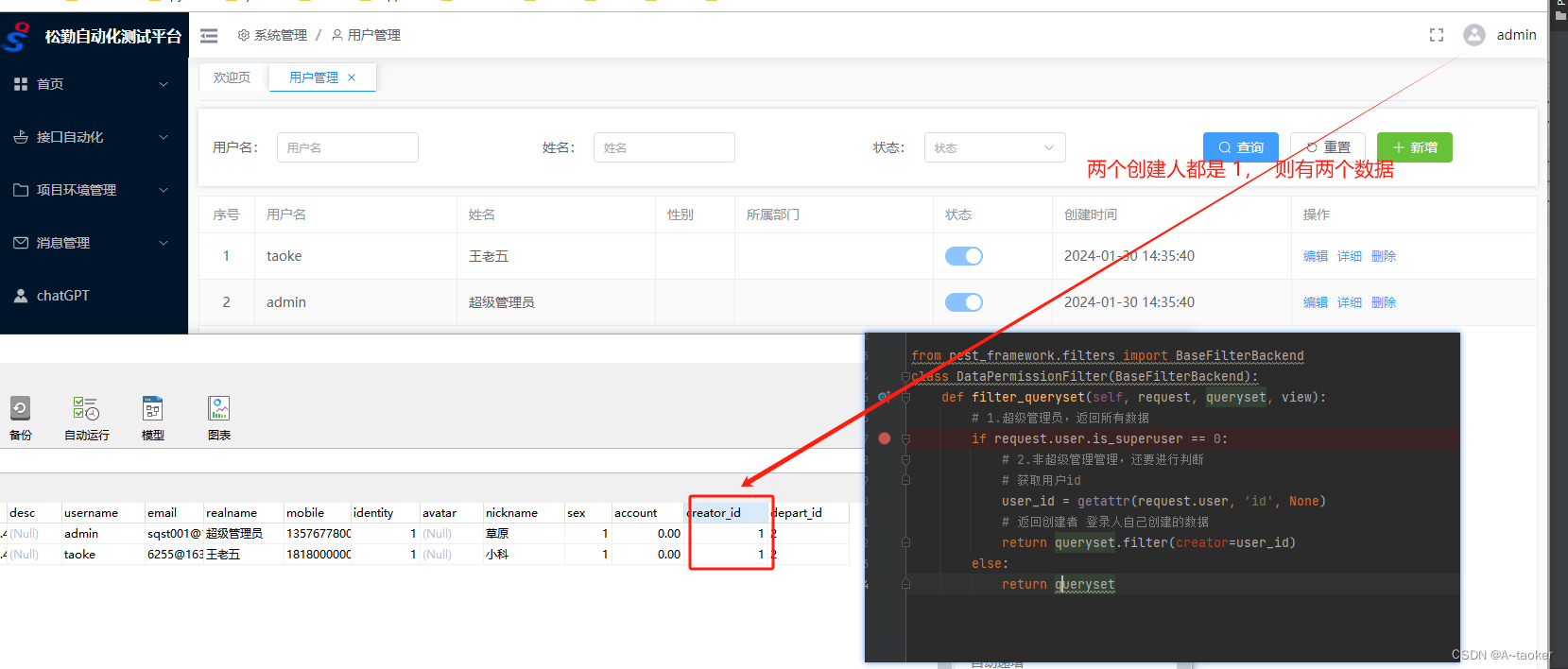
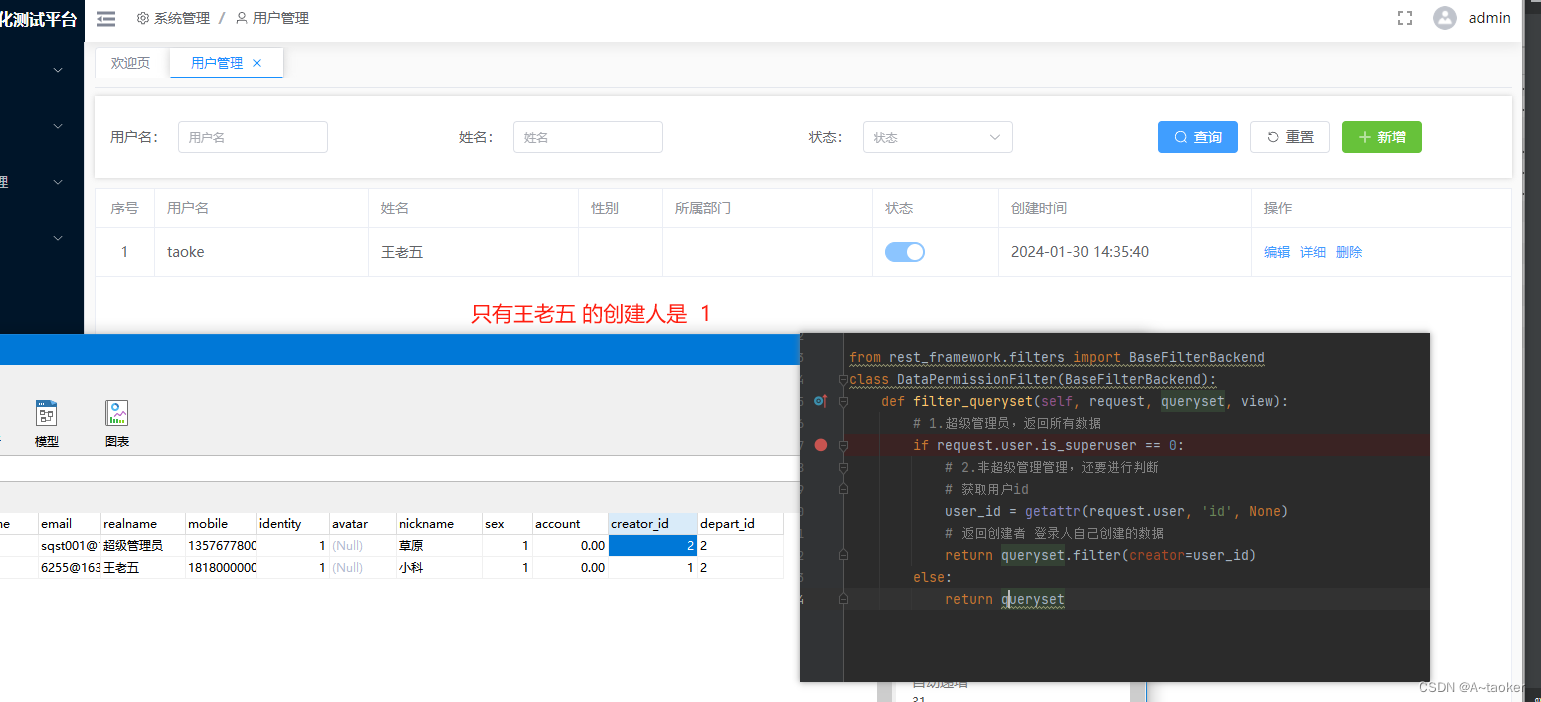
为超级管理员时,就返回的全部
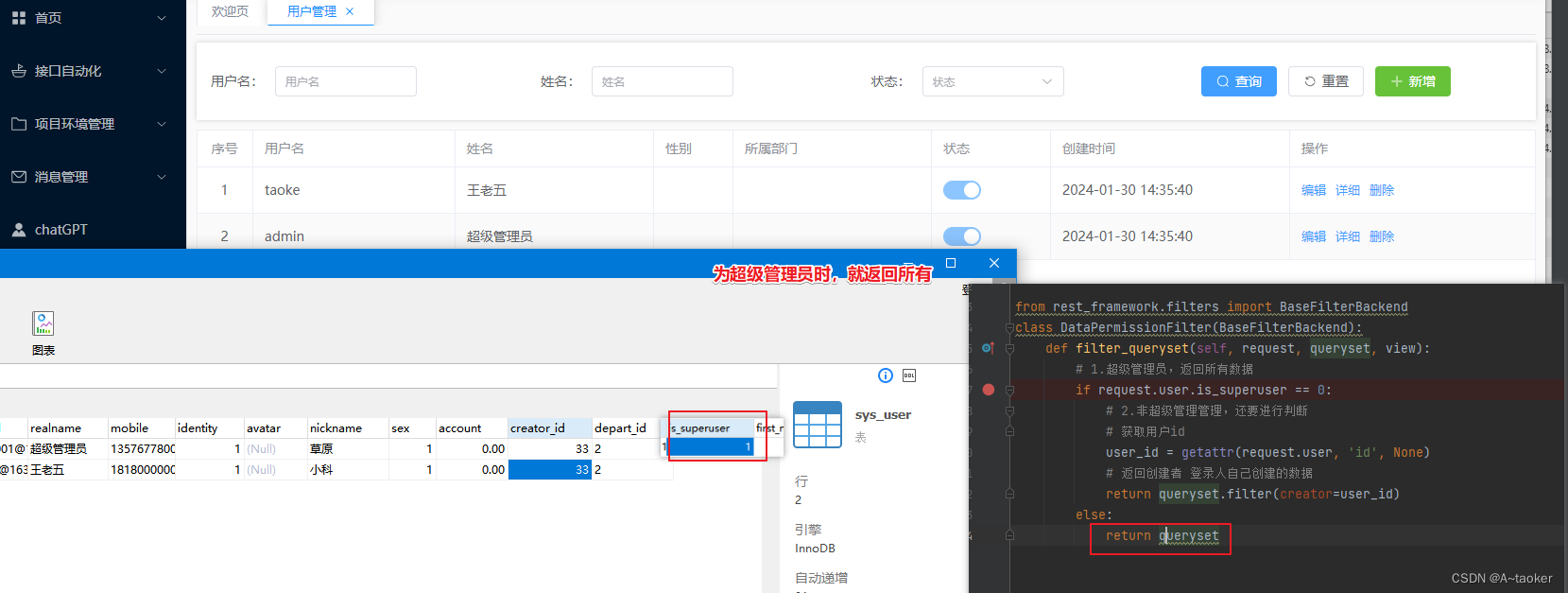
-
以上是一个简单的例子。是根据queryset中的创建人来的,
首先要满足你所查询的querySet是拥有创建人这个字段的。 -
复杂点的逻辑一,可以是根据用户拥有的角色,角色又拥有哪些数据,
假如
A角色关联的是 1公司,2公司数据,
B角色关联的是 2公司,3公司数据
当查询某种数据时,对应的模型也就需要有公司字段。
3.复杂点的逻辑二, 可以是根据用户拥有的角色,角色又拥有部门,
要查询的数据也拥有部门,实现了数据权限
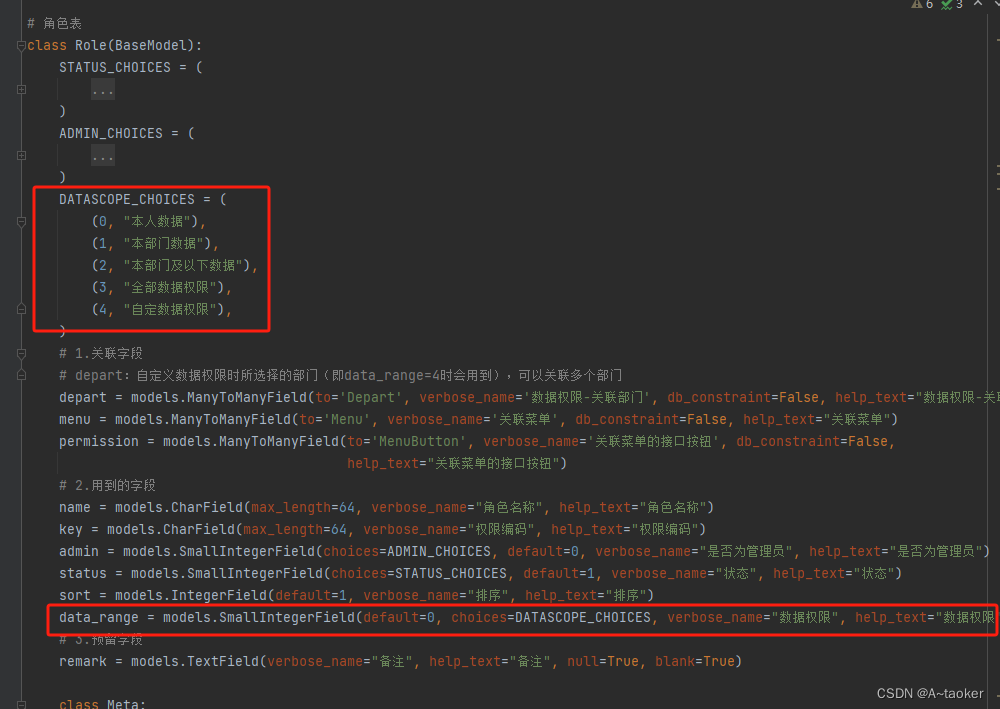
角色模型如下:
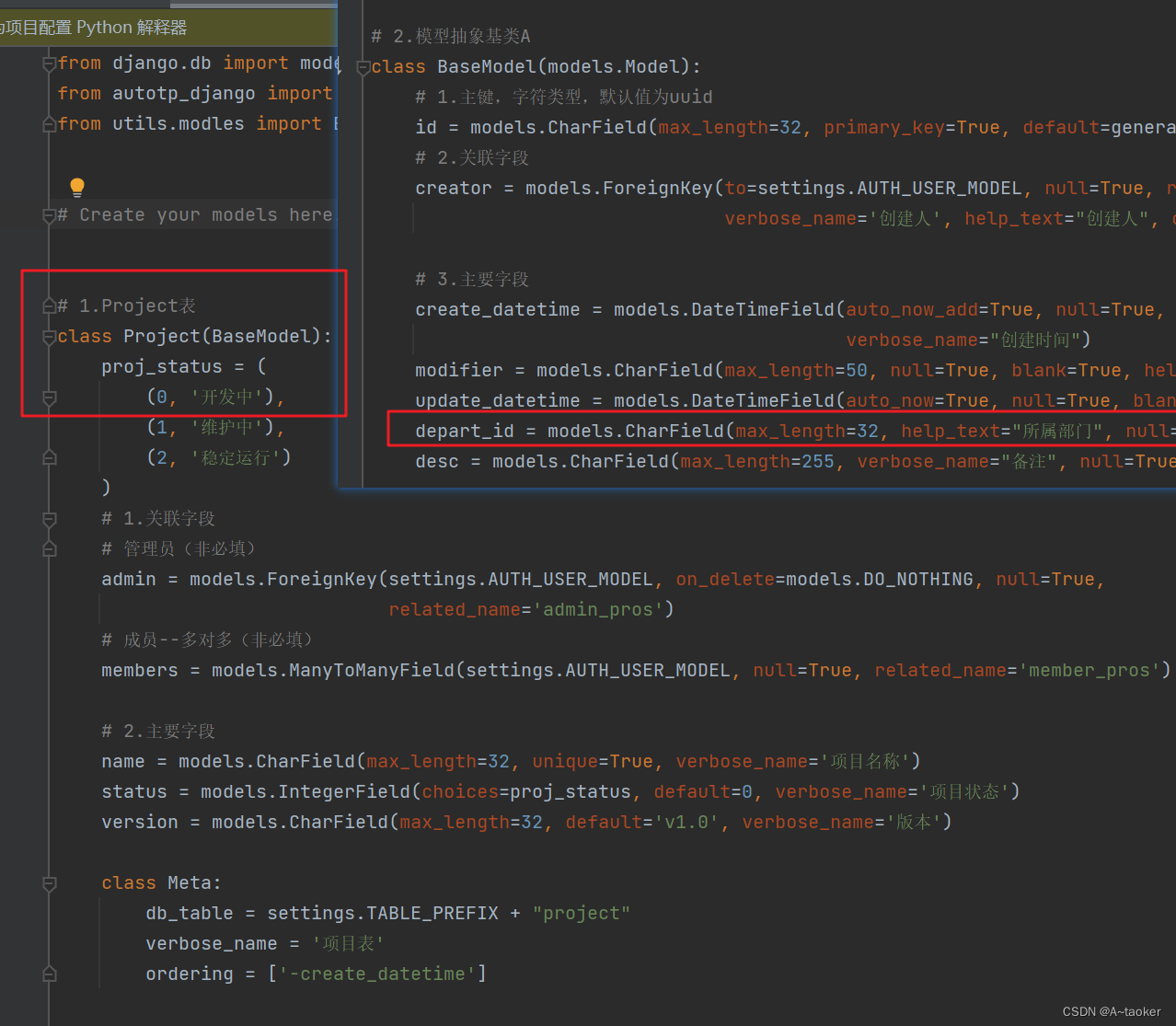
业务模型:
如这个Project项目模型,它是存在depart_id的。
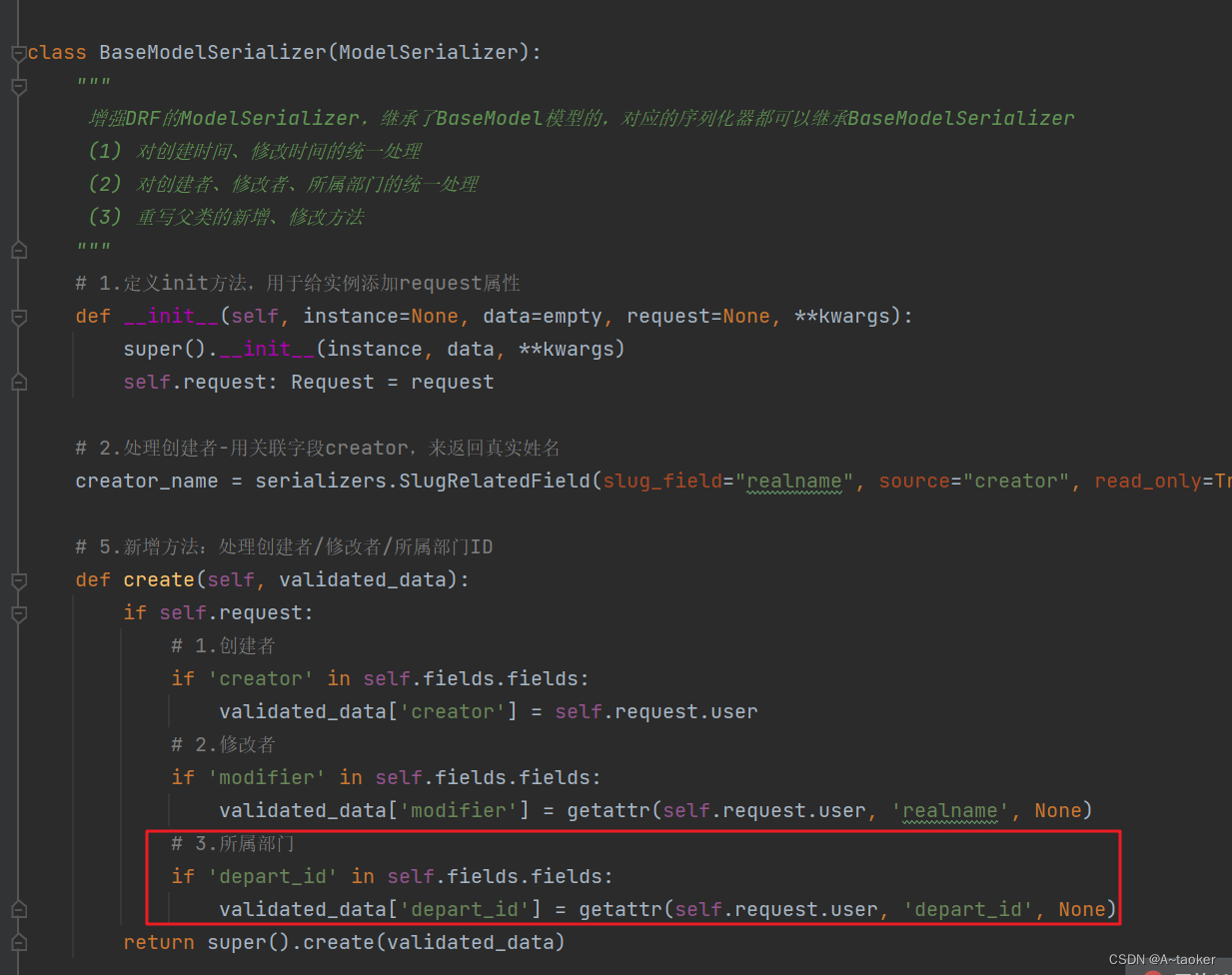
另外:序列化器基类中,重写了create方法,比如,在新建一个 project时,该数据的depart_id,字段就是当前用户的数据。
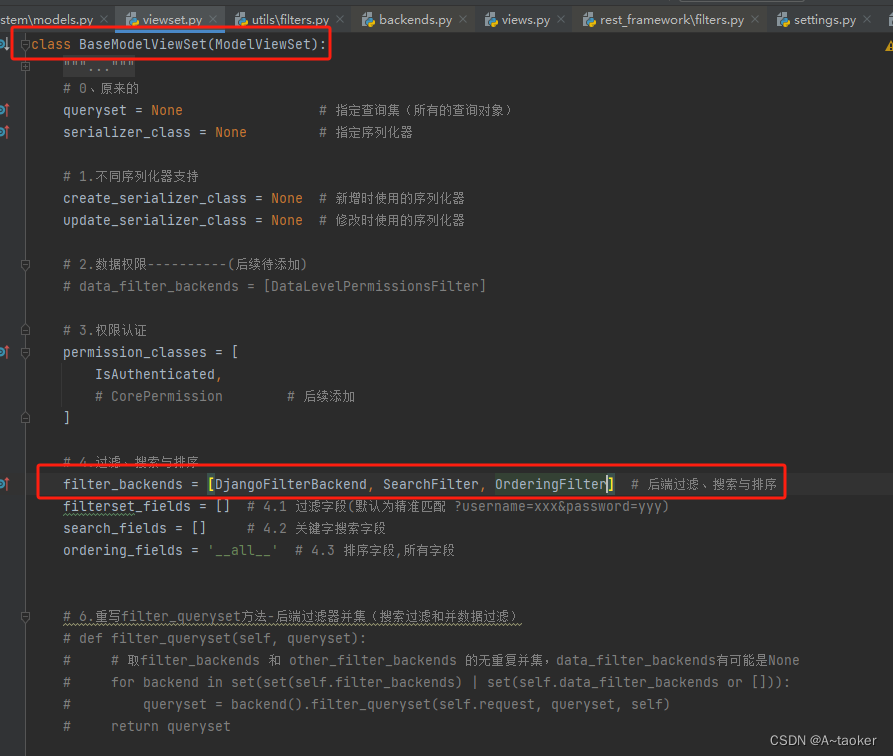
过滤类的写法如下:
主要解析:
- 用户是超级管理员, 就 所有数据不过滤
- 用户(部门id,和角色是必有的,但也要考虑无),根据用户角色们,如果其中有个角色的 data_range为3, 或者有个角色为 管理员admin, 就是 所有数据 不过滤
- 根据用户角色们,如果角色们的data_range没有3, 有 data_range为0,那么就 会查业务数据的
creator为当前用户的数据,且depart_id 为自己部门的数据, 业务数据没有depart_id也能查 - 根据用户角色们,如果角色们的data_range没有3和0,那就是124, 就会查业务数据
depart_id满足的数据
以下代码现有逻辑:当存在多个角色,一个角色为0 仅本人数据, 一个角色为1本部门数据时, 会优先满足0 的情况
此代码仅做参考,
- 因为还没解决仅本人数据,和 本部门数据同时存在的矛盾。、
- 业务数据是哪个部门的人创建,就属于哪个部门的数据(创建业务数据时,depart_id的存值(上面那张图)),如果业务中,要求各个部门只看自己部门的数据,才有存在的价值
"""
@Remark: 自定义过滤器
"""
from rest_framework.filters import BaseFilterBackend
from system.models import Depart
import django_filters
from system.models import User
class DataLevelPermissionsFilter(BaseFilterBackend):
"""
功能:《数据级权限过滤器》,步骤如下:
第一步. 当前用户为超级管理员,则返回所有数据
第二步. 获取用户所属部门的id,没有部门则返回空数据
第三步. 判断用户是否分配角色,没有则返回空数据
第四步. 获取用户所有角色的数据权限列表(会有多个角色,进行去重)------> 得到 data_permissions_list,
如:[0, 1, 2,4 ],其中0表示本人数据,1表示本部门数据,2表示本部门及以下数据, (3 添加不进来的)
第五步. 仅访问本人数据(考虑到部门可能会变更,所以再添加当前部门条件)------如果有0,仅本人数据,就不管有 有角色为124 的数据权限(因为已经提前返回了)
第六步. 判断业务模型是否有部门ID字段(depart_id),没有返回所有数据
第七步. 根据各个角色的数据权限部门并集,返回对应部门的数据
"""
def filter_queryset(self, request, queryset, view):
# 1.超级管理员,返回所有数据
if request.user.is_superuser == 0:
# 2. 获取用户所属部门id,没有部门,则返回None(无数据)
depart_id = getattr(request.user, 'depart_id', None)
if not depart_id:
return queryset.none()
# 3. 判断用户是否分配角色,没有则仅返回【空】
if not hasattr(request.user, 'role'):
return queryset.none()
# return queryset.filter(depart_id=depart_id) 本部门的数据
# 4. 获取用户的所有角色列表,得到【数据】范围列表(如:本人数据、本部门数据、本部门及以下数据等)
role_list = request.user.role.filter(status=1).values('admin', 'data_range')
data_permissions_list = []
for ele in role_list:
# 4.1 全部数据(3)或者角色为管理员,则返回全部数据
if 3 == ele.get('data_range') or ele.get('admin') == True:
return queryset
data_permissions_list.append(ele.get('data_range'))
# 4.2 得到所有角色无重复的【数据权限】列表
data_permissions_list = list(set(data_permissions_list)) # 可能是 [0, 1, 2,4]
# 5. 仅访问本人数据(考虑到部门可能会变更,所以再添加当前部门条件)
if 0 in data_permissions_list:
if not getattr(queryset.model, 'depart_id', None):
return queryset.filter(creator=request.user)
else:
# 换部门了,就不能访问原来部门的数据
return queryset.filter(creator=request.user, depart_id=depart_id) # (创建人是当前用户,查询的数据是当前部门的数据)
# 6. 判断业务模型是否有部门ID字段(depart_id),没有返回所有数据
if not getattr(queryset.model, 'depart_id', None):
return queryset
# 7. 处理:1=本部门数据、2=本部门及以下数据、4=自定数据权限 的情况
depart_list = []
for data_range in data_permissions_list:
if data_range == 4: # 6.1 自定义数据权限(读取role里面的depart部门)
depart_list.extend(request.user.role.filter(status=1).values_list('depart__id', flat=True))
elif data_range == 2: # 6.2 本部门及以下数据权限
depart_list.extend(get_depart(depart_id, ))
elif data_range == 1: # 6.3 本部门数据权限
depart_list.append(depart_id)
return queryset.filter(depart_id__in=list(set(depart_list)))
else:
return queryset
# 没用到
class UsersManageFilter(django_filters.rest_framework.FilterSet):
"""
用户管理 简单过滤器
URL格式:http://127.0.0.1:8100/?start_time=2022-10-02 08:00:00&end_time=2023-12-31 23:59:59
"""
# 1.创建时间从
start_time = django_filters.DateTimeFilter(field_name='create_datetime', lookup_expr='gte')
# 2.创建时间到
end_time = django_filters.DateTimeFilter(field_name='create_datetime', lookup_expr='lte')
# 3.用户名-模糊搜索
username = django_filters.CharFilter(field_name='username', lookup_expr='icontains')
# 4.手机号码-模糊搜索
mobile = django_filters.CharFilter(field_name='mobile', lookup_expr='icontains')
class Meta:
model = User
fields = []
def get_depart(depart_id, depart_all_list=None, depart_list=None):
"""
递归获取部门的所有下级部门
:param depart_id: 需要获取的部门id
:param depart_all_list: 所有部门列表
:param depart_list: 递归部门list
:return:
"""
if not depart_all_list:
depart_all_list = Depart.objects.all().values('id', 'parent')
if depart_list is None:
depart_list = [depart_id]
for ele in depart_all_list:
if ele.get('parent') == depart_id:
depart_list.append(ele.get('id'))
get_depart(ele.get('id'), depart_all_list, depart_list)
return list(set(depart_list))
使用自定义类
方式1 笨办法:在新的视图集中,重写filter_backends, 把自定义的类装到列表里即可

方式2 : 假如已经定义了视图集基类
并且在继承视图集基类后,不想重写filter_backends
就可以这样:
在基类写一个other_backends, 并重写filter_queryset
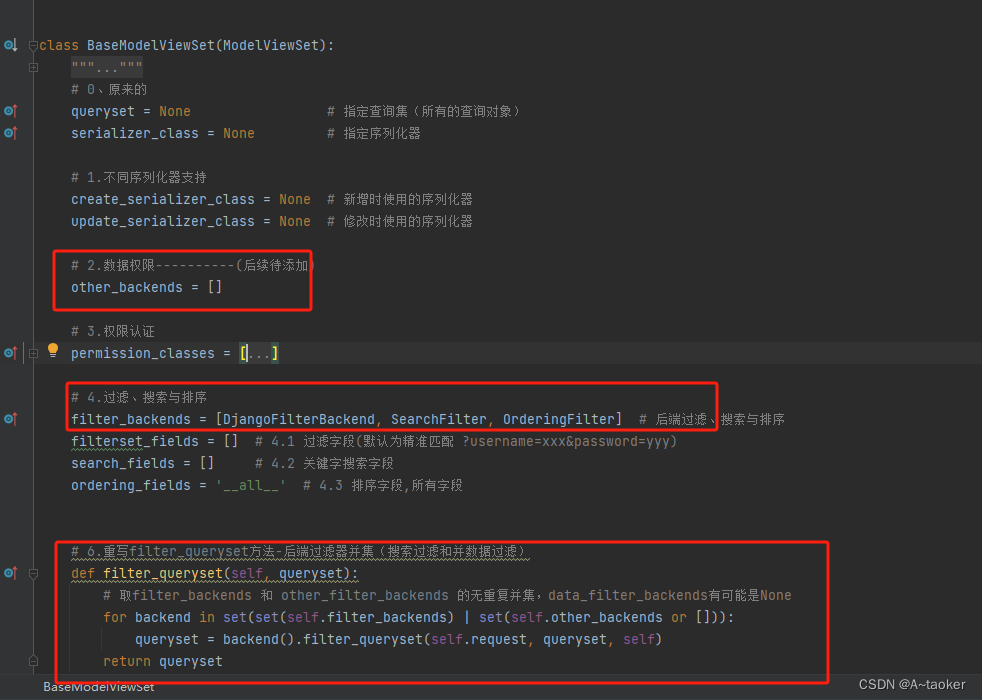
# 6.重写filter_queryset方法-后端过滤器并集(搜索过滤和并数据过滤)
def filter_queryset(self, queryset):
# 取filter_backends 和 other_filter_backends 的无重复并集,data_filter_backends有可能是None
for backend in set(set(self.filter_backends) | set(self.other_backends or [])):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
在具体的视图集中,这样写就实现了