DTL: Disentangled Transfer Learning for Visual Recognition
- 论文链接:https://arxiv.org/pdf/2312.07856.pdf
- 源码链接:https://github.com/heekhero/DTL
简介
大规模预训练加微调的框架已经在各个领域推广。但是由于GPU内存或时间预算的原因,传统的微调可能是难以解决的,因为必须更新整个大模型参数。最近,参数有效迁移学习(PETL)被提出仅更新可训练参数的极小子集。由于其效率和防止过度拟合的能力,PETL的许多变体相继出现。
然而可训练参数的大幅减少并不一定意味着GPU内存使用量同等减少:节省的GPU内存百分比仍然很小(约为25%)。如果由于GPU内存不足而无法对大模型进行微调,即使是PETL框架也可能失败。这个缺点是至关重要的,也是根本性质。因此设计一种有效减少GPU内存使用并充分探索大规模预训练模型效率至关重要。PETL方法的一个共同特征是它们将小型可训练模块与巨大的冻结backbone紧密纠缠。 如LST: Ladder Side-Tuning for parameter and memory efficient transfer learning中所示,为了正确更新特定网络参数,模型必须从激活中缓存相关的中间梯度。这种纠缠设计使缓存称为GPU内存占用的相当大一部分,从而阻碍了大预训练模型在各种任务中应用。
为了解决这个基础缺点,本文提出了纠缠迁移学习(Disentangled Transfer Learning),它通过提出轻量级紧凑侧网络(Compact Side Network,CSN)将权重更新与backbone分离。DTL不仅大大减少了GPU内存占用,也取得了知识迁移的高精度。
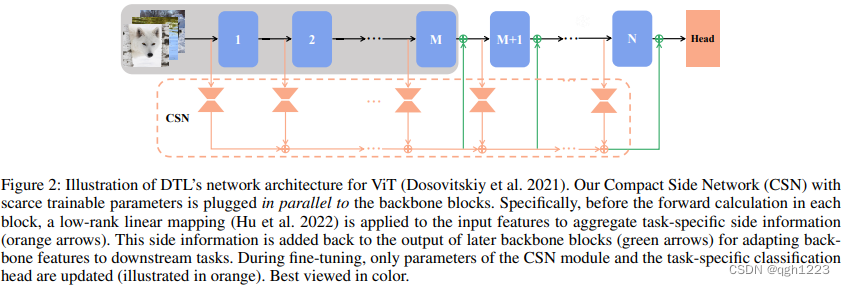
如图2所示,CSN由若干低秩线性映射矩阵以抽取特定任务信息。通过将这些信息注入到后面几个backbone块中,自适应地校准预训练模型生成的部分中间特征,使得这些特征对下游任务更具判别性。本文还可以将DTL增强为DTL+,它插入额外的全局深度可分离卷积(DWConv)层,以在CSN向backbone注入时收集空间信息。DTL非常简单,并且与各种backbone架构兼容。backbone中早期块的输出在微调过程中保持不变,当提供相同输出时可以在多个下游任务中重用backbone特征。
当前PETL方法的限制
假设有N层的FFN网络
y
=
f
N
(
f
N
−
1
(
…
f
1
(
x
)
)
)
y=f_{N}(f_{N-1}(\ldots f_{1}(x)))
y=fN(fN−1(…f1(x)))。层i权重矩阵
W
i
W_{i}
Wi偏差项
b
i
b_{i}
bi。
o
i
+
1
,
z
i
+
1
o_{i+1},z_{i+1}
oi+1,zi+1是层i的输出和激活前特征,满足
o
i
+
1
=
σ
(
z
i
+
1
)
=
σ
(
W
i
o
i
+
b
i
)
o_{i+1}=\sigma(z_{i+1})=\sigma(W_{i}o_{i}+b_{i})
oi+1=σ(zi+1)=σ(Wioi+bi)。Ladder Side-Tuning研究显示从损失
L
L
L后向传播到
W
i
,
b
i
W_{i},b_{i}
Wi,bi的梯度是:
∂
L
∂
W
i
=
∂
L
∂
o
i
+
1
σ
i
′
o
i
∂
L
∂
b
i
=
∂
L
∂
o
i
+
1
σ
i
′
\begin{aligned} \frac{\partial L}{\partial W_{i}}&=\frac{\partial L}{\partial o_{i+1}}\sigma_{i}^{\prime}o_{i}\\ \frac{\partial L}{\partial b_{i}}&=\frac{\partial L}{\partial o_{i+1}}\sigma_{i}^{\prime}\\ \end{aligned}
∂Wi∂L∂bi∂L=∂oi+1∂Lσi′oi=∂oi+1∂Lσi′
其中
σ
i
′
\sigma_{i}^{\prime}
σi′是
∂
o
i
+
1
/
∂
z
i
+
1
\partial o_{i+1}/\partial z_{i+1}
∂oi+1/∂zi+1缩写。进一步
∂
L
/
∂
o
i
+
1
\partial L/\partial o_{i+1}
∂L/∂oi+1可以表示为:
∂
L
∂
o
i
+
1
=
∂
L
∂
o
i
+
2
∂
o
i
+
2
∂
z
i
+
2
∂
z
i
+
2
∂
o
i
+
1
=
∂
L
∂
o
i
+
2
σ
i
+
1
′
W
i
+
1
\frac{\partial L}{\partial o_{i+1}}=\frac{\partial L}{\partial o_{i+2}}\frac{\partial o_{i+2}}{\partial z_{i+2}}\frac{\partial z_{i+2}}{\partial o_{i+1}}=\frac{\partial L}{\partial o_{i+2}}\sigma_{i+1}^{\prime}W_{i+1}
∂oi+1∂L=∂oi+2∂L∂zi+2∂oi+2∂oi+1∂zi+2=∂oi+2∂Lσi+1′Wi+1
为了正确计算除了模型参数外的参数,在链式规则的对应项
{
σ
i
′
}
\{\sigma_{i}^{\prime}\}
{σi′}需要在微调时被缓存,这支配了GPU内存使用。
本文发现代表性的PETL方法将可训练参数与backbone紧密纠缠在一起,这几乎不会减少缓存
{
σ
i
′
}
\{\sigma_{i}^{\prime}\}
{σi′}中GPU内存使用。这一特性表明,与完全微调相比,即使可训练参数数量非常少,GPU内存占用也无法有效减少。
为了解决这一根本问题,本文提出了一种新的学习范式,称为纠缠迁移学习(Disentangled Transfer Learning,DTL)。DTL核心思想是将小型额外模块权重更新从backbone中分离出来。因此为后向传播存储的
σ
i
′
\sigma_{i}^{\prime}
σi′能被剧烈减少。通过这种方式,DTL成功地进一步突破了当前PETL的极限,不仅提高了参数效率,而且在微调大规模预训练模型时减少了必要的GPU内存大小。
本文提出了一种简单且有效的方法正确微调大规模预训练模型。为了平衡不同环境中的识别精度和架构复杂性,本文引入了两种变体DTL和DTL+。
DTL
首先给出最简单的形式。图2给出了ViT架构对应的提出模块框架,这主要由紧凑边网络(Compact Side Network,CSN)组成。CSN被插入到backbone中用于信息聚合和特征自适应。提出的方法与其他类型的ViT兼容。
给定包含N块的ViT backbone,前向计算可以描述为
z
=
b
N
(
b
N
−
1
(
…
b
1
(
x
)
)
)
z=b_{N}(b_{N-1}(\ldots b_{1}(x)))
z=bN(bN−1(…b1(x)))。
z
z
z是输出令牌。
z
i
+
1
z_{i+1}
zi+1是块
b
i
b_{i}
bi输出
z
i
+
1
=
b
i
(
z
i
)
z_{i+1}=b_{i}(z_{i})
zi+1=bi(zi),
z
1
=
x
z_{1}=x
z1=x。本文CSN由N个低秩线性变换矩阵组成,每个插入到一个块中以提取特定于任务的信息。记
w
i
=
a
i
c
i
w_{i}=a_{i}c_{i}
wi=aici是第i块的权重矩阵。其中
a
i
∈
R
d
×
d
′
,
c
i
∈
R
d
′
×
d
a_{i}\in \mathbb{R}^{d\times d^{\prime}},c_{i}\in \mathbb{R}^{d^{\prime}\times d}
ai∈Rd×d′,ci∈Rd′×d且
d
′
≪
d
d^{\prime}\ll d
d′≪d。CSN逐渐从每个块聚集信息:
h
i
+
1
=
h
i
+
z
i
w
i
z
i
+
1
=
b
i
(
z
i
)
\begin{aligned} h_{i+1}&=h_{i}+z_{i}w_{i}\\ z_{i+1}&=b_{i}(z_{i})\\ \end{aligned}
hi+1zi+1=hi+ziwi=bi(zi)
h
i
h_{i}
hi是CSN的第i层输出,
h
1
=
0
h_{1}=0
h1=0。在这之后,从
M
M
M块开始,聚合的特定于任务的信息
h
i
+
1
h_{i+1}
hi+1用于通过将
z
i
+
1
z_{i+1}
zi+1添加回
z
i
+
1
z_{i+1}
zi+1来使其适应下游任务。因此当
i
≥
M
i\geq M
i≥M时满足
z
i
+
1
′
=
z
i
+
1
+
θ
(
h
i
+
1
)
z_{i+1}^{\prime}=z_{i+1}+\theta(h_{i+1})
zi+1′=zi+1+θ(hi+1)
z
i
+
1
′
z_{i+1}^{\prime}
zi+1′是
b
i
b_{i}
bi的适应输出。
θ
(
x
)
\theta(x)
θ(x)是swish激活函数。为了防止
z
i
+
1
′
z_{i+1}^{\prime}
zi+1′在微调开始时急剧偏离
z
i
+
1
z_{i+1}
zi+1,
α
i
\alpha_{i}
αi遵循均匀分布初始化,
c
i
c_{i}
ci是零初始化。第i块的输出可以表示为:
z
i
+
1
′
=
{
z
i
+
1
+
θ
(
h
i
+
1
)
if
i
≥
M
z
i
+
1
otherwise
z_{i+1}^{\prime}=\left\{\begin{array}{ll} z_{i+1}+\theta\left(h_{i+1}\right) & \text { if } i \geq M \\ z_{i+1} & \text { otherwise } \end{array}\right.
zi+1′={zi+1+θ(hi+1)zi+1 if i≥M otherwise
本文发现小的
d
′
d^{\prime}
d′表现得相当好,这表明backbone特征具有高度冗余性。除了保持
d
′
d^{\prime}
d′较小之外,在Swish中使用较大的
β
\beta
β来进一步减少冗余。
DTL+
为了进一步加强本文方法的有效性,在应用
θ
\theta
θ之后,本文将一个额外的全局深度可分离卷积(Depthwise Separable Convolution,DWConv)层
g
g
g附加到每个侧层。DTL+公式可以描述为:
z
i
+
1
′
=
{
z
i
+
1
+
g
(
θ
(
h
i
+
1
)
)
if
i
≥
M
z
i
+
1
otherwise
z_{i+1}^{\prime}=\left\{\begin{array}{ll} z_{i+1}+g(\theta\left(h_{i+1}\right)) & \text { if } i \geq M \\ z_{i+1} & \text { otherwise } \end{array}\right.
zi+1′={zi+1+g(θ(hi+1))zi+1 if i≥M otherwise
g
g
g步幅设置为1,零填充用于确保不改变特征尺寸。
g
g
g在不同CSN层间共享,使得g中的可训练参数数量与初始CSN相比是小的并且整个CSN模块仍然是轻量级的。