目录
1、朴素贝叶斯算法
1.1 案例
1.2 联合概率、条件概率、相互独立
1.3 贝叶斯公式
1.4 朴素贝叶斯算法原理
1.5 应用场景
2、朴素贝叶斯算法对文本进行分类
2.1 案例
2.2 拉普拉斯平滑系数
3、API
4、案例:20类新闻分类
4.1 步骤分析
4.2 代码分析
5、总结
- sklearn转换器和估算器
- KNN算法
- 模型选择和调优
- 朴素贝叶斯算法
- 决策树
- 随机森林
1、朴素贝叶斯算法
朴素?
假设:特征与特征之间是相互独立的
1.1 案例
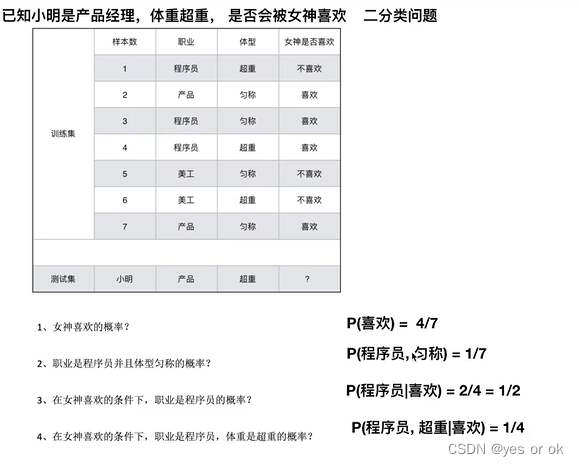
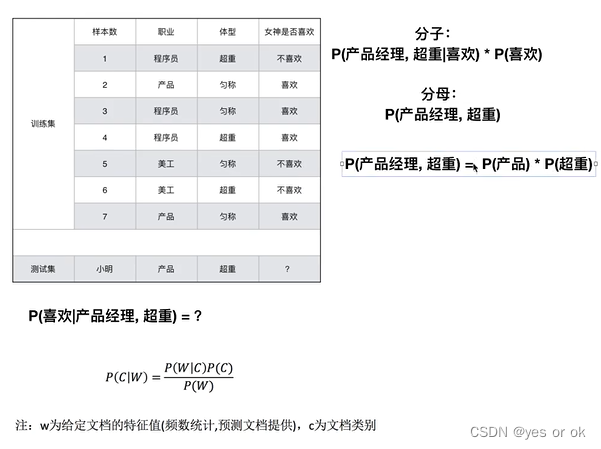

1.2 联合概率、条件概率、相互独立

1.3 贝叶斯公式

1.4 朴素贝叶斯算法原理
朴素 + 贝叶斯
1.5 应用场景
- 文本分类(单词作为特征)
2、朴素贝叶斯算法对文本进行分类
2.1 案例


2.2 拉普拉斯平滑系数

3、API

4、案例:20类新闻分类

4.1 步骤分析
- 获取数据
- 划分数据集
- 特征工程 --文本特征抽取
- 朴素贝叶斯预估器流程
- 模型评估
4.2 代码分析
from sklearn.datasets import load_iris, fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
def knn_iris():
# 用KNN 算法对鸢尾花进行分类
# 1、获取数据
iris = load_iris()
# 2、划分数据集
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state=6)
# 3、特征工程 - 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN 算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train,y_train)
# 5、模型评估
# 方法1 :直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n",y_predict)
print("直接比对真实值和预测值:\n",y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test,y_test)
print("准确率为:\n",score)
return None
def knn_iris_gscv():
# 用KNN 算法对鸢尾花进行分类,添加网格搜索和交叉验证
# 1、获取数据
iris = load_iris()
# 2、划分数据集
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state=6)
# 3、特征工程 - 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN 算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索和交叉验证
# 参数准备
param_dict = {"n_neighbors":[1,3,5,7,9,11]}
estimator = GridSearchCV(estimator,param_grid=param_dict,cv=10)
estimator.fit(x_train,y_train)
# 5、模型评估
# 方法1 :直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n",y_predict)
print("直接比对真实值和预测值:\n",y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test,y_test)
print("准确率为:\n",score)
# 最佳参数:best_params_
print("最佳参数:\n",estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n",estimator.best_score_)
# 最佳估计值:best_estimator_
print("最佳估计值:\n",estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n",estimator.cv_results_)
return None
def nb_news():
# 用朴素贝叶斯算法对新闻进行分类
# 1、获取数据
news = fetch_20newsgroups(subset="all")
# 2、划分数据集
x_train,x_test,y_train,y_test = train_test_split(news.data,news.target)
# 3、特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、用朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train,y_train)
# 5、模型评估
# 方法1 :直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == "__main__":
# 代码1 :用KNN算法对鸢尾花进行分类
# knn_iris()
# 代码2 :用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
# knn_iris_gscv()
# 代码3:用朴素贝叶斯算法对新闻进行分类
nb_news()5、总结







![[服务器-数据库]MongoDBv7.0.4不支持ipv6访问](https://img-blog.csdnimg.cn/img_convert/e7b858f50b1b1f328b3ad9c5b2e872b3.png)

![【深度学习:对象跟踪】对象跟踪完整指南 [教程]](https://img-blog.csdnimg.cn/direct/1ef869d8a2634f6294a0677817cb6ea6.png#pic_center)