在大数据时代,实时数据同步已经有很多地方应用,包括从在线数据库构建实时数据仓库,跨区域数据复制。行业落地场景众多,例如,电商 GMV 数据实时统计,用户行为分析,广告投放效果实时追踪,社交媒体舆情分析,跨区域用户管理。亚马逊云科技提供了从数据库到分析,以及机器学习的全流程方案。
有几种数据同步方式可以考虑:
Amazon Zero-ETL
ETL 是将业务系统的数据经过提取(Extract)、转换清洗(Transform)和加载(Load)到数据仓库、大数据平台的过程。借助 Zero-ETL ,数据库本身集成 ETL 到数据仓库的功能,减少在不同服务间手动迁移或转换数据的工作。
Amazon Database Migration Service(DMS)
DMS 可以迁移关系数据库、数据仓库、NoSQL 数据库及其他类型的数据存储,支持同构或者异构数据库和数据仓库的数据转换。
Flink + Kafka
Flink 作为开源实时计算引擎,支持包括各种关系数据库、NoSQL 数据库和数据仓库的多种数据源和下游连接,加上 Kafka 消息管道作为上下游解耦,可以满足各种场景和压力的数据同步需求。
其他开源方案:Debezium,Canal
如何选择合适的数据同步方案?
1. 工具对于数据源和目标端的支持。
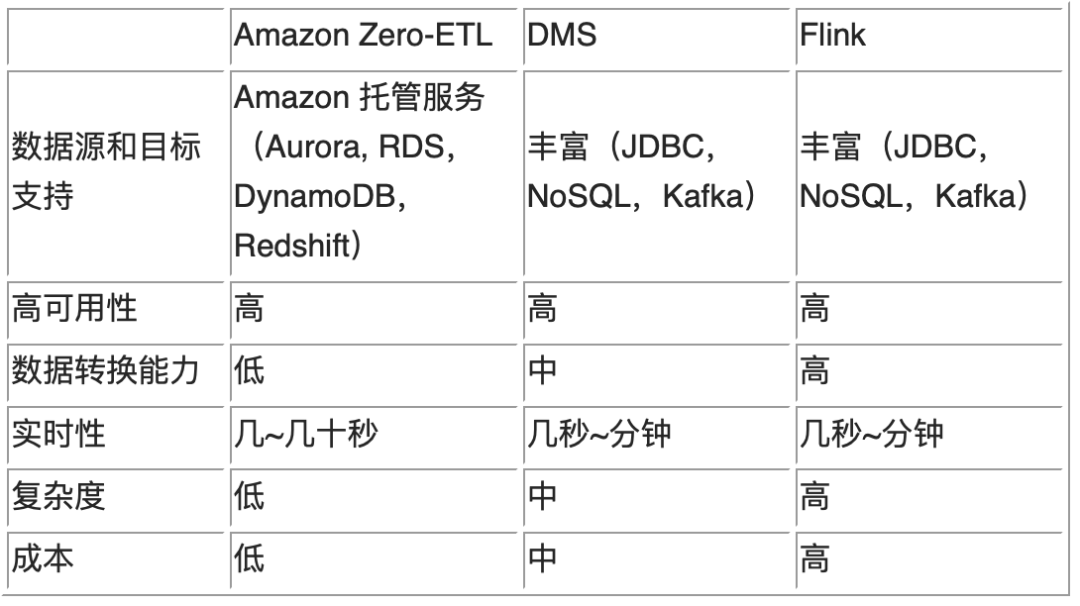
Amazon Zero-ETL 目前正式支持从 Amazon Aurora MySQL 到 Amazon Redshift,其他的正在预览的数据源包括 Amazon Aurora PostgreSQL,Amazon RDS MySQL 和 Amazon DynamoDB。目标端现在支持 Aurora MySQL 到 Amazon Redshift,以及 Amazon DynamoDB 到 Amazon Opensearch,正在预览功能是从 Amazon DynamoDB 到 Amazon Redshift。相对来说,DMS 和 Flink 方案支持的数据更加广泛,常见的 JDBC 关系型数据库和 MongoDB 等 NoSQL 数据库都支持,并且还支持 Kafka 和 Kinesis 等消息管道。
下图列出了 Flink 支持的上下游数据:

2. 架构稳定性,可以长期在生产环境运行,有高可用和故障恢复机制。
Amazon Zero-ETL 是托管服务功能,无需管理。DMS 也可以使用高可用配置。Flink 可以运行在 Amazon EMR 托管服务之上,节点和任务调度都有高可用保障。
3. 数据转换能力。Amazon Zero-ETL 支持特定的数据源和目标,源和目标数据一致,不能在 ETL 过程中转换数据或者实时 JOIN 等操作。DMS 只支持小部分数据类型和列的过滤,其他功能还未解锁。Flink 实时计算引擎本身就有强大的数据转换能力,实时聚合查询等能力也更加丰富。
4. 实时性。Amazon Zero-ETL 可以实现秒级别的同步延迟。DMS 可以通过 batch apply 或者提高任务并发度实现更高实时性。Flink 本身就能处理大量实时计算,加上 Kafka 解耦,能满足各种压力下的高实时性。
5. 复杂度。Amazon Zero-ETL 只需要在支持的数据库 Integration 功能即可创建实时 ETL 管道,无需其他组件,操作最简单。DMS 创建复制实例,设置源和目标,以及优化任务参数,相对略微复杂。Flink 基于开源技术,需要创建 EMR 和 MSK Kafka 服务,运行多个 Flink 任务,以构建进出的数据管道,更灵活的数据转换还需要编写程序,相对最复杂。
6. 成本。Amazon Zero-ETL 功能本身不收费,只收取因为 ETL 而产生额外的 IO 和存储费用。DMS 收取复制实例的费用。Flink 架构最为复杂,EMR 和 Kafka 集群高可用,各需要 3 个以上节点,相对成本最高。
以下是三种方案的简单对比。
客户根据自己的业务需求,选择合适的方案。
大数据运维力量比较薄弱,而且业务数据源和目标都支持,可以选择 Amazon Zero-ETL。
数据源和目标不在 Amazon Zero-ETL 支持范围,或者中国和海外跨区域复制,不想构建复杂的管道,选择 DMS。
有比较强的运维和开发能力,需要高性能和数据转换能力,选择 Flink。
除了实时数据仓库之外,有些客户需要实现中国和海外的数据库同步。Amazon 原生的服务只支持除了中国之外其他区域之间的同步,由于 Amazon Zero-ETL 对于区域和服务的限制,此时可以考虑 DMS 或者 Flink 方案。DMS 由单独的实例来进行数据中转,配置简单。但是如果数据库写入压力很高的时候,DMS 可能处理能力受限,造成源和目标端数据延迟增加,实时性受到影响。此时可以使用 Flink 方案,提供更高的处理能力。
Amazon DocumentDB(与 MongoDB 兼容)广泛应用于游戏、广告、电商、媒体、金融、物联网等行业场景,也可以实时数据同步到数据仓库。
以下方案介绍了如何通过 EMR Flink 和 Kafka,构建跨区域 Amazon DocumentDB 之间的实时数据同步。Flink 支持传统 SQL 和 DataStream 编程接口。本方案中使用 Flink SQL,无需编写代码。
整体架构如下:
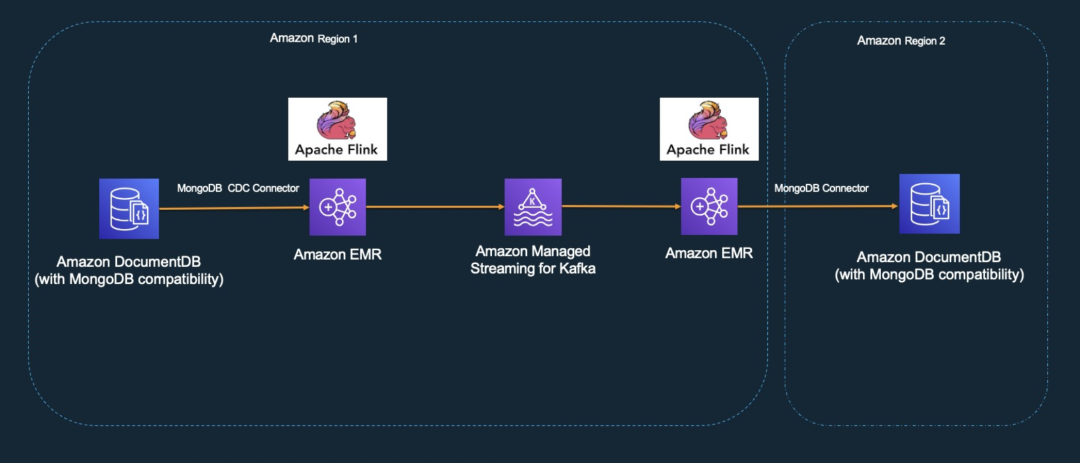
此方案中,首先需要打通中国到海外的网络,例如专线或者 SD-WAN。这样使数据传输更加安全,而且 DocumentDB 只支持内网访问。数据源和目标都是 DocumentDB,之间使用 EMR Flink,以 Flink Mongodb CDC Connector 把源 DocumentDB 的数据拉取过来,以 Kafka connector 打入 MSK Kafka 消息队列,下游 EMR Flink 拉取 Kafka 消息,然后通过 Mongodb connector 写入目标 DocumentDB。MSK Kafka 起到解耦作用,避免上下游数据进出速度不同的问题。EMR 可以使用两个单独的集群,如果单集群性能足够,也可以只使用一个集群,分别运行上下游不同的 Flink 任务。
在 Flink Kafka connector 的选择上,分 Kafka 和 Upsert Kafka 两种。Kafka Connector 从 Kafka topic 中消费和写入数据,通过 CDC 工具从其他数据库捕获的变更事件,使用 CDC 格式将消息解析为 Flink SQL INSERT,UPDATE,DELETE 消息,支持 CDC 格式包括:debezium,canal,maxwell。
示例:
CREATE TABLE behavior_kafka_sink (...)
WITH ( 'connector' = 'kafka',... 'format' = ‘debezium-json');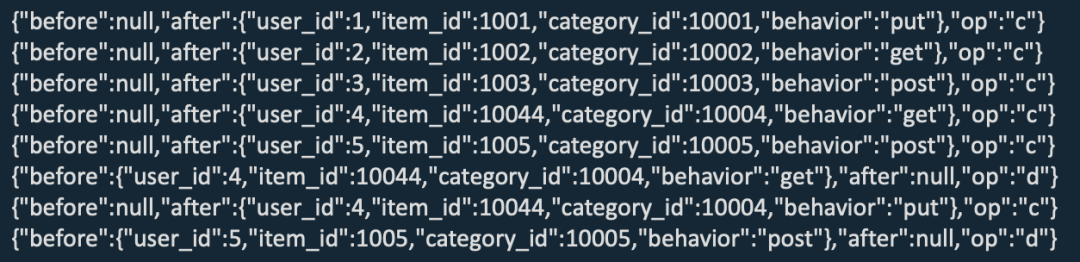
Upsert Kafka Connector 作为 sink,消费 changelog 流,将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。
CREATE TABLE behavior_kafka_sink (...)
WITH ( 'connector' = ‘upsert-kafka',... 'key.format' = 'json', 'value.format' = 'json');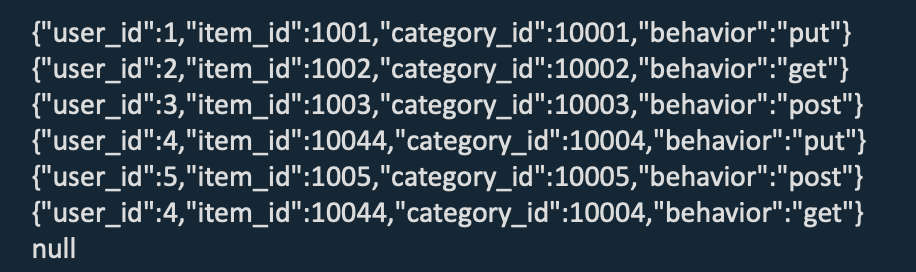
删除操作时,Upsert Kafka 产生 null 消息,下游无法处理。而 Kafka Connector 使用 debezium CDC 格式获取前后变化,下游可以处理 Upsert 数据。
本方案中使用 Kafka Connector 以及 debezium json 格式。
Flink CDC mongodb connector 对 SSL 支持不足,本方案中禁用 DocumentDB SSL。另外,由于 DocumentDB 分片模式不支持 Change Stream,无法读取 CDC 变化数据,请选择实例模式。
下面进入实战演示,此演示中没有真正创建中国到海外区域的专线,而是使用跨区域 VPC peering 作为替代。
功能测试
环境
源 DocumentDB:us-west-2 区域,5.0.0 版本,实例模式,1 写,1读,r6g.xlarge,禁用 SSL,开启 Chang Stream
目标 DocumentDB:us-east-1 区域,5.0.0 版本,实例模式,1 写,1 读,r6g.xlarge,禁用 SSL
EMR:6.10.0,Flink 1.16.0,1 主节点,2 核心节点,m6g.xlarge
MSK Kafka 3.5.1,3 节点,m7g.large,为方便禁用验证
准备工作
登录 EMR 主节点,下载 flink jar 包并复制到/usr/lib/flink/lib 目录,用户和组都更改为 flink。需要 flink jar 包如下:
flink-connector-jdbc-1.16.2.jar
flink-sql-connector-kafka-1.16.1.jar
flink-sql-connector-mongodb-cdc-2.3.0.jar
flink-sql-connector-mongodb-1.0.1-1.16.jar创建 DocumentDB collection,并打开 Change Stream
mongosh --host ping.cluster-cubokui4azxq.us-west-2.docdb.amazonaws.com:27017 --username user --password xxxxxxxx --retryWrites=false
use inventory
db.adminCommand({ modifyChangeStreams: 1, database: "inventory", collection: "", enable: true });插入数据
rs0 [direct: primary] inventory> db.products.insertMany(
[
{
"Item": "Pen",
"Colors": ["Red","Green","Blue","Black"],
"Inventory": {
"OnHand": 244,
"MinOnHand": 72
}
},
{
"Item": "Poster Paint",
"Colors": ["Red","Green","Blue","Black","White"],
"Inventory": {
"OnHand": 47,
"MinOnHand": 50
}
},
{
"Item": "Spray Paint",
"Colors": ["Black","Red","Green","Blue"],
"Inventory": {
"OnHand": 47,
"MinOnHand": 50,
"OrderQnty": 36
}
}
]
)登录 EMR 主节点,创建 Kafka topic。Kafka 在分区内有顺序,简单起见设置分区数为 1
cd kafka_2.13-2.8.1/bin
./kafka-topics.sh --bootstrap-server b-2.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-3.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-1.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092 --replication-factor 3 --partitions 1 --create --topic mongo-kafka查看 kafka 消息
./kafka-console-consumer.sh --bootstrap-server b-2.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-3.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-1.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092 --topic mongo-kafka --from-beginning创建 Flink 任务
cd /usr/lib/flink/bin
./yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -nm flink-cdc
yarn application -list运行 Flink SQL 客户端
$ ./sql-client.sh embedded -s flink-cdc设置 checkpoint
SET execution.checkpointing.interval = 3s;创建 Flink DocumentDB 源表,使用 mongodb cdc connector。主键必须设置。Flink SQL 不支持 MongoDB JSON 对象类型,以 STRING 替代
CREATE TABLE mongo_products (
_id STRING,
Item STRING,
Colors STRING,
Inventory STRING,
PRIMARY KEY(_id) NOT ENFORCED
) WITH (
'connector' = 'mongodb-cdc',
'hosts' = 'ping.cluster-cubokui4azxq.us-west-2.docdb.amazonaws.com:27017',
'username' = 'user',
'password' = 'password',
'database' = 'inventory',
'collection' = 'products'
);创建 Flink Kafka 表,使用 kafka connector,debezium json 格式
CREATE TABLE mongo_kafka (
_id STRING,
Item STRING,
Colors STRING,
Inventory STRING,
PRIMARY KEY(_id) NOT ENFORCED
)
WITH (
'connector' = 'kafka',
'topic' = 'mongo-kafka',
'properties.bootstrap.servers' = 'b-2.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-3.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-1.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092',
'properties.group.id' = 'mongo-kafka-group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'debezium-json'
);读取 DocumentDB 数据,写入 Kafka
insert into mongo_kafka SELECT * FROM mongo_products;创建下游 sink 表,从 kafka 读取消息,更新到目标 DocomentDB
CREATE TABLE mongo_sink (
_id STRING,
Item STRING,
Colors STRING,
Inventory STRING,
PRIMARY KEY(_id) NOT ENFORCED
)
WITH (
'connector' = 'mongodb',
'uri' = 'mongodb://milan:password@ping5.cluster-c7b8fns5un9o.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false',
'database' = 'inventory',
'collection' = 'products'
);
insert into mongo_sink SELECT * FROM mongo_kafka;在另外一个窗口运行 kafka 消费程序,可以看到有 DocumentDB 数据写入
$ ./kafka-console-consumer.sh --bootstrap-server b-2.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-3.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092,b-1.ping.uaramp.c22.kafka.us-east-1.amazonaws.com:9092 --topic mongo-kafka --from-beginning
{"before":null,"after":{"_id":"65976a473f3a210c022ffc55","Item":"Pen","Colors":"[\"Red\", \"Green\", \"Blue\", \"Black\"]","Inventory":"{\"OnHand\": 244, \"MinOnHand\": 72}"},"op":"c"}
{"before":null,"after":{"_id":"65976a473f3a210c022ffc56","Item":"Poster Paint","Colors":"[\"Red\", \"Green\", \"Blue\", \"Black\", \"White\"]","Inventory":"{\"OnHand\": 47, \"MinOnHand\": 50}"},"op":"c"}
{"before":null,"after":{"_id":"65976a473f3a210c022ffc57","Item":"Spray Paint","Colors":"[\"Black\", \"Red\", \"Green\", \"Blue\"]","Inventory":"{\"OnHand\": 47, \"MinOnHand\": 50, \"OrderQnty\": 36}"},"op":"c"}登录目标 DocumentDB,可以看到目标数据库成功从 kafka 导入数据
mongosh --host ping5.cluster-c7b8fns5un9o.us-east-1.docdb.amazonaws.com:27017 --username milan --password xxxx --retryWrites=false
rs0 [direct: primary] inventory> db.products.find()
[
{
_id: ObjectId('65976a473f3a210c022ffc55'),
Colors: '["Red", "Green", "Blue", "Black"]',
Inventory: '{"OnHand": 244, "MinOnHand": 72}',
Item: 'Pen'
},
{
_id: ObjectId('65976a473f3a210c022ffc56'),
Colors: '["Red", "Green", "Blue", "Black", "White"]',
Inventory: '{"OnHand": 47, "MinOnHand": 50}',
Item: 'Poster Paint'
},
{
_id: ObjectId('65976a473f3a210c022ffc57'),
Colors: '["Black", "Red", "Green", "Blue"]',
Inventory: '{"OnHand": 47, "MinOnHand": 50, "OrderQnty": 36}',
Item: 'Spray Paint'
}
]在源数据库进行插入、更新、删除,变化数据都可以很快同步到目标数据库,以 Flink 和 Kafka 构建跨区域 DocomentDB 复制成功。
目前 Flink mongodb cdc connector 还不支持 DDL 操作,例如 drop(),可以观察到 Flink 任务中,DocumentDB 到 kafka 任务失败。
高可用测试
EMR 的框架可以实现高可用机制,主节点可以使用 3 个节点高可用,多个核心和任务节点,结合调度机制,也能实现节点和任务的高可用。Flink 有 checkpoint 机制,可以设置为本地目录或者 S3,周期性产生数据快照用于恢复,如果任务失败会一直重试,直到超过最大重试次数。默认配置下,模拟节点故障,重启某个核心节点。此时无论是否启用 Flink checkpoint,重启任务所在节点都会造成任务中断。解决办法,EMR Configuration 加入 Flink 高可用配置。
[
{
"Classification": "yarn-site",
"Properties": {
"yarn.resourcemanager.am.max-attempts": "10"
}
},
{
"Classification": "flink-conf",
"Properties": {
"high-availability": "zookeeper",
"high-availability.storageDir": "hdfs:///user/flink/recovery",
"high-availability.zookeeper.path.root": "/flink",
"high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}",
"yarn.application-attempts": "10"
}
}
]重启 EMR 核心节点,Flink 任务重新初始化,任务继续运行,实现高可用,适合长期运行 CDC 任务。
性能测试
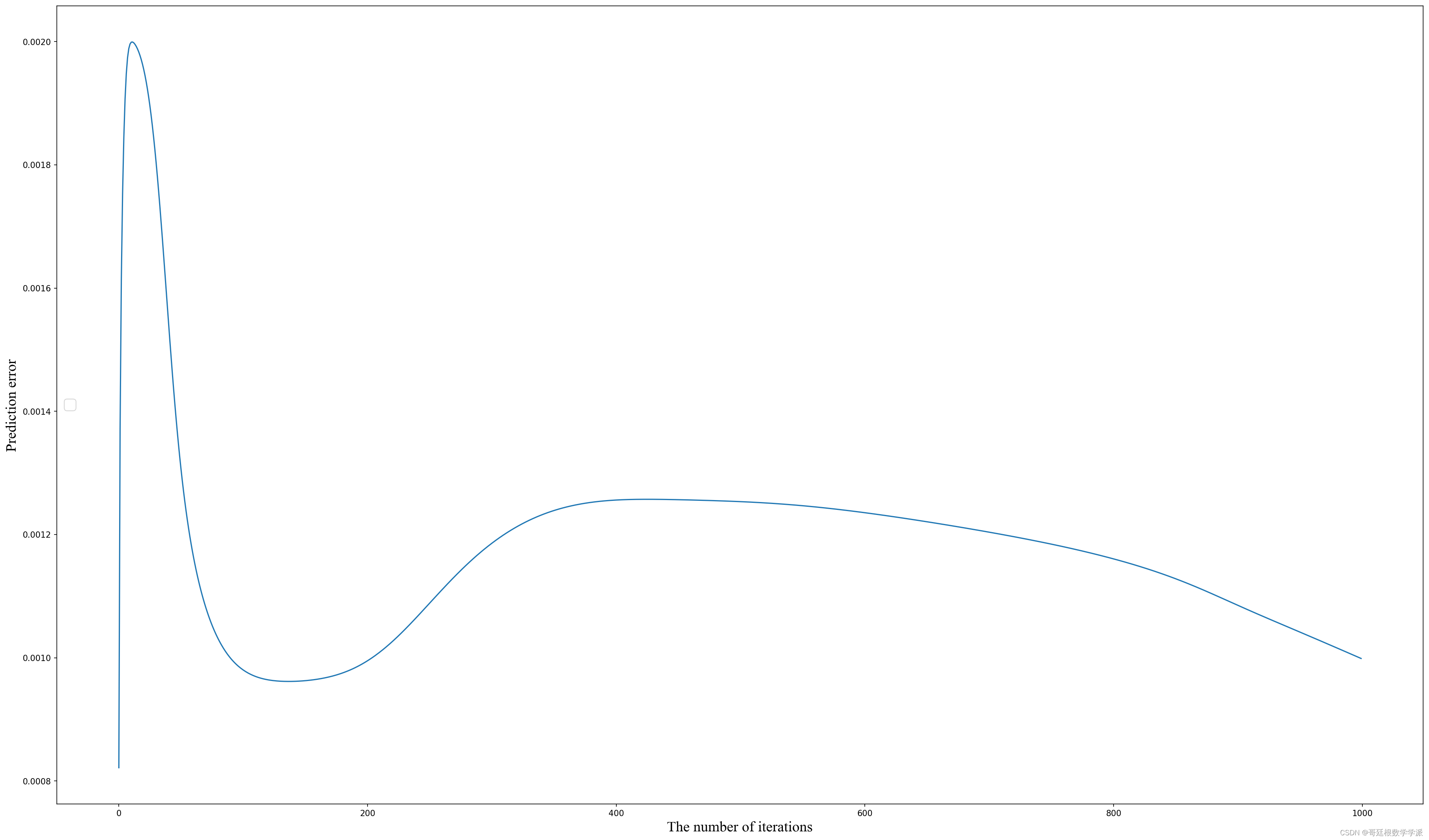
以上验证了复制功能和高可用性,如果源数据库写请求很高,也需要注意性能是否可以满足要求。此性能测试中,向源数据库快速插入 1000 万条数据,采用批量提交以提高写入性能,实际写入性能约 1 万条/秒。目标端如果不做任何设置,写入性能大约 600 条/秒,与源端写入性能有较大差距。通过 Flink UI 和日志,以及组件分开验证,分析性能瓶颈位于 Flink 读取 kafka 之后写入目标 DocumentDB 的 sink 部分。可适当提高 Kafka 分区数以提高总体性能。实测 4 个分区,目标端可以达到 1400 条/秒。
Kafka 只在单个分区内有序,在多个分区时无序,要注意不同分区之间的顺序,特别是 Update 操作。可以使用 Flink watermark 机制,在设定的时间段内,到达水位线的操作都可以被合并处理,以此来保证多分区下的消息顺序。
测试环境
客户端 EC2:Amazon Linux 2,python2,r6i.xlarge
数据库 DocumentDB 同功能测试,跨区域,源 us-west-2,目标 us-east-1
编写源数据库写入程序,参考:
https://github.com/milan9527/documentdb/blob/main/docdb-flink-insert.py
源 DocumentDB 开启 change stream
db.adminCommand({modifyChangeStreams: 1,
database: "test",
collection: "",
enable: true});写入测试数据,10M 行
python3 docdb-flink-insert.py创建 4 个分区的 kafka topic
./kafka-topics.sh --bootstrap-server b-2.pingaws.ecxlst.c22.kafka.us-east-1.amazonaws.com:9092,b-3.pingaws.ecxlst.c22.kafka.us-east-1.amazonaws.com:9092,b-1.pingaws.ecxlst.c22.kafka.us-east-1.amazonaws.com:9092 --replication-factor 3 --partitions 4 --create --topic docdb-bench修改 EMR Flink Configuration 并行度 parallelism=4
提交 Flink 任务,使用 2 slot,状态存储于 rocksdb,checkpoint 位于 S3。测试中 checkpoint 无论使用 S3还是 hdfs,性能相差不大,这和变化的数据有关,以实际测试为参考。
flink-yarn-session -d -jm 2048 -tm 4096 -s 2 \
-D state.backend=rocksdb \
-D state.backend.incremental=true \
-D state.checkpoint-storage=filesystem \
-D state.checkpoints.dir=s3://milan9527/flink/flink-checkponts/ \
-D state.checkpoints.num-retained=10 \
-D execution.checkpointing.interval=10s \
-D execution.checkpointing.mode=EXACTLY_ONCE \
-D execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \
-D execution.checkpointing.max-concurrent-checkpoints=1Flink SQL 建表和插入语句,参考之前功能测试部分,修改相应表和 Kafka 名字。
kafka 分区 = 4,flink 并行度设置为 4,slot = 2,此时每个 task 都能并行处理 kafka 消息,大幅提高 sink 写入性能。每秒从 600 提升到 1400 左右,可以满足普通请求量的需求。
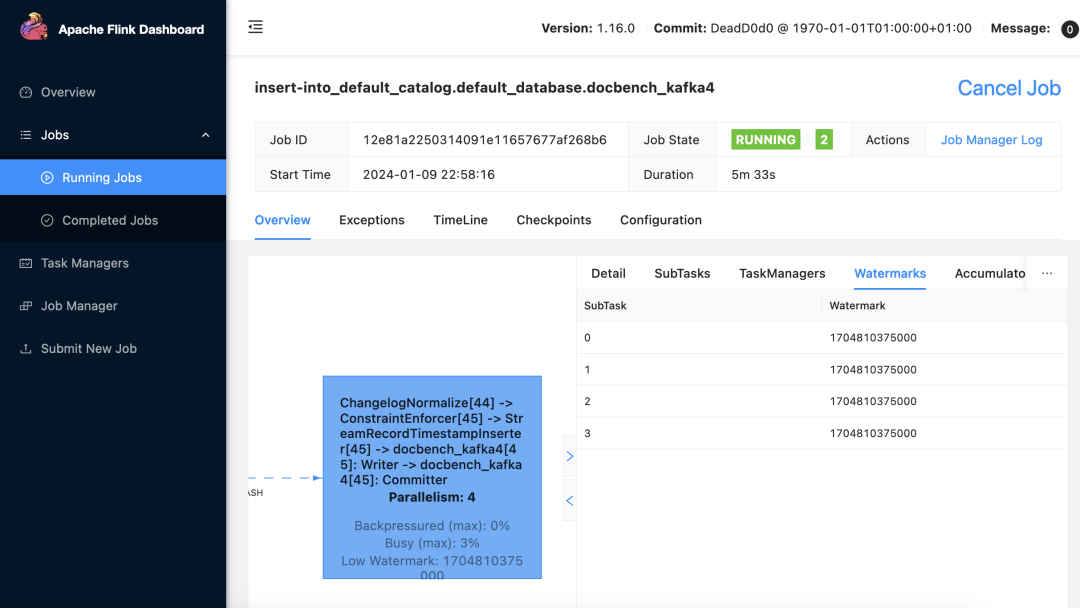
以下 Flink Web UI 显示,4 个子任务能同时处理数据,提高性能。

以下信息显示,Kafka 里的多个分区消息被同时处理,虽然存在滞后,但是已经比单分区性能提高很多。
$ ./kafka-consumer-groups.sh --bootstrap-server b-1.pingaws.ecxlst.c22.kafka.us-east-1.amazonaws.com:9092,b-2.pingaws.ecxlst.c22.kafka.us-east-1.amazonaws.com:9092,b-3.pingaws.ecxlst.c22.kafka.us-east-1.amazonaws.com:9092 --describe --group 'docdb-kafka-group'
Flink Kafka 任务 watermark 显示水位线数据
性能观察
Flink 方案可以在源 DocumentDB 数据库在普通请求量下(几千 QPS 以下),近似实时同步到目标 DocumentDB。如果需要提高目标数据库写入性能,可以调整 Kafka 分区数量,以及 Flink 并行度,结合 Flink watermark 机制实现有序写入。
方案总结
通过 Flink 和 Kafka,可以构建跨区域 DocumentDB 之间实时数据同步。各个组件都可以实现高可用,总体方案可以稳定运行。依靠 Flink 实时计算引擎,和 Kafka 的海量消息处理能力,即使在高业务量的场景,也可以实现 DocumentDB 之间近似实时的数据同步。
优化建议
EMR 主节点使用高可用配置。
Flink Checkpoint 需要设置以恢复失败的任务,使用 HDFS 会消耗较多的存储空间,如果使用 S3,还要低延迟,后续可以考虑 S3 Express One Zone 。
源数据库业务量比较低时,比如几百 QPS,Kafka 单个分区即可。
源数据库业务量多时,使用 Kafka 多分区,结合 Flink watermark 有序写入。
Flink 任务并行度最好和 Kafka 分区数量一致,并且有足够的 slot 可以运行任务。
监控源和目标数据库,EMR Flink/MSK Kafka 的性能指标,以及 Kafka 消息处理进度。
本篇作者

章平
亚马逊云科技数据库架构师。2014 年起就职于亚马逊云科技,先后加入技术支持和解决方案团队,致力于客户业务在云上高效落地。对于各类云计算产品和技术,特别是在数据库和大数据方面,拥有丰富的技术实践和行业解决方案经验。此前曾就职于 Sun,Oracle,Intel 等 IT 企业。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!