车企
随着春节假期结束,各行各业也正式复工,但车企却未能迎来属于它们的"新年新气象"。
早在年前(12 月),就有新闻爆出,知名传统车企「广汽本田」为了加快转向电动车市场,宣布解雇中国合资企业广汽本田下的 900 名员工。

据悉,这是因为传统车企在 2023 前 10 个月的销量总计同比下降 18.5% 所做的决定。
那是否只要是站在"风口"的新能源车企,就活得很好呢?
也不是。
燃油车的销量持续下降,除了有电动车崛起的直接因素,当中还有消费降低,经济萎靡的宏观因素。而后者会对所有车企,甚至是消费品行业带来实则性的挑战。
年初九,当别人还沉浸在春节假期或开工红包的喜悦的时候,新能源造车新势力高合汽车宣布停工停产 6 个月。

取消年终奖、全员降薪、停工停产(仅发基本工资),高合汽车选择了大面积裁员的另一条道路。
高合汽车创始人、董事长兼 CEO 丁磊,职业初期在上汽担任高管,从业时间超过 20 年,他本人也亲身经历了中国汽车行业逐渐变强的全过程。
带着这种"天生骄傲"的履历,同时又手握丰富的行业资源。
高合汽车成立时就将自身定位为"高端电动车品牌",首款车的最高售价达到 80 万,一度被视为在电动车高端市场突破 BBA 封锁的先行者。
但可惜那个「只要把车造出来就不愁卖的时代」早就过去了。
现在新能源领域领跑的几家企业,依靠的并非只是单一的造车能力,还包括 软件技术、服务 和 产品力。
前者(造车能力)决定车企能否开得起来,而后者(软件技术/服务/产品力)则是决定车企能否活下去。
那些真正承担起新势力变革角色的车企,都有着它们的鲜明特点。传统车企虽然手握更多的造车资源,但如果只是简单宣布产能调整,并不能实现对新能源造车新势力们的"降维打击"。
因此,我并不看好广汽本田的这次变革。
传统车企想要挤进赛道,需要依托于更加激进的改革方案。
...
回归主线。
都说到了新能源车企了,那就来一道「蔚来」面试原题。
题目描述
平台:LeetCode
题号:792
给定字符串 s 和字符串数组 words, 返回 words[i] 中是 s 的子序列的单词个数 。
字符串的子序列是从原始字符串中生成的新字符串,可以从中删去一些字符(可以是""),而不改变其余字符的相对顺序。
例如, “ace” 是 “abcde” 的子序列。
示例 1:
输入: s = "abcde", words = ["a","bb","acd","ace"]
输出: 3
解释: 有三个是 s 的子序列的单词: "a", "acd", "ace"。
示例 2:
输入: s = "dsahjpjauf", words = ["ahjpjau","ja","ahbwzgqnuk","tnmlanowax"]
输出: 2
提示:
-
-
-
-
words[i]和s都只由小写字母组成。
预处理 + 哈希表 + 二分
朴素判定某个字符串是为另一字符串的子序列的复杂度为 ,对于本题共有 个字符串需要判定,每个字符串最多长为 ,因此整体计算量为 ,会超时。
不可避免的是,我们要对每个 进行检查,因此优化的思路可放在如何优化单个 的判定操作。
朴素的判定过程需要使用双指针扫描两个字符串,其中对于原串的扫描,会有大量的字符会被跳过(无效匹配),即只有两指针对应的字符相同时,匹配串指针才会后移。
我们考虑如何优化这部分无效匹配。
对于任意一个
而言,假设我们当前匹配到
位置,此时我们已经明确下一个待匹配的字符为
,因此我们可以直接在 s 中字符为
的位置中找候选。
具体的,我们可以使用哈希表 map 对 s 进行预处理:以字符
为哈希表的 key,对应的下标
集合为 value,由于我们从前往后处理 s 进行预处理,因此对于所有的 value 均满足递增性质。
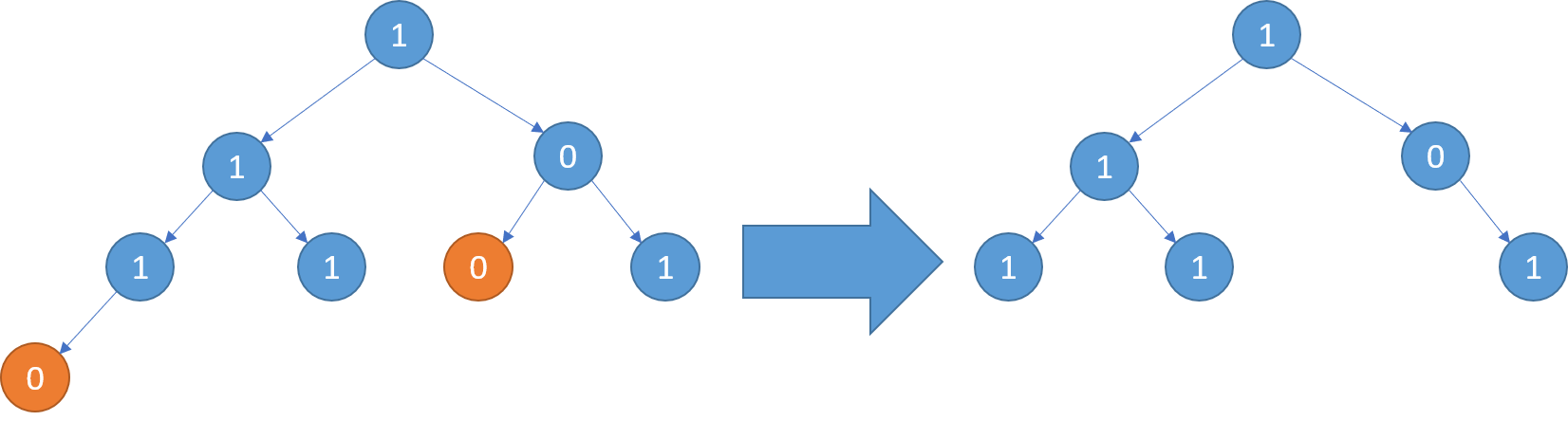
举个 🌰 : 对于 s = abcabc 而言,预处理的哈希表为 {a=[0,3], b=[1,4], c=[2,5]}
最后考虑如何判定某个
是否满足要求:待匹配字符串 w 长度为 m,我们从前往后对 w 进行判定,假设当前判待匹配位置为
,我们使用变量 idx 代表能够满足匹配
的最小下标(贪心思路)。
对于匹配的
字符,可以等价为在 map[w[i]] 中找到第一个大于 idx 的下标,含义在原串 s 中找到字符为 w[i] 且下标大于 idx 的最小值,由于我们所有的 map[X] 均满足单调递增,该过程可使用「二分」进行。
Java 代码:
class Solution {
public int numMatchingSubseq(String s, String[] words) {
int n = s.length(), ans = 0;
Map<Character, List<Integer>> map = new HashMap<>();
for (int i = 0; i < n; i++) {
List<Integer> list = map.getOrDefault(s.charAt(i), new ArrayList<>());
list.add(i);
map.put(s.charAt(i), list);
}
for (String w : words) {
boolean ok = true;
int m = w.length(), idx = -1;
for (int i = 0; i < m && ok; i++) {
List<Integer> list = map.getOrDefault(w.charAt(i), new ArrayList<>());
int l = 0, r = list.size() - 1;
while (l < r) {
int mid = l + r >> 1;
if (list.get(mid) > idx) r = mid;
else l = mid + 1;
}
if (r < 0 || list.get(r) <= idx) ok = false;
else idx = list.get(r);
}
if (ok) ans++;
}
return ans;
}
}
TypeScript 代码:
function numMatchingSubseq(s: string, words: string[]): number {
let n = s.length, ans = 0
const map = new Map<String, Array<number>>()
for (let i = 0; i < n; i++) {
if (!map.has(s[i])) map.set(s[i], new Array<number>())
map.get(s[i]).push(i)
}
for (const w of words) {
let ok = true
let m = w.length, idx = -1
for (let i = 0; i < m && ok; i++) {
if (!map.has(w[i])) {
ok = false
} else {
const list = map.get(w[i])
let l = 0, r = list.length - 1
while (l < r) {
const mid = l + r >> 1
if (list[mid] > idx) r = mid
else l = mid + 1
}
if (r < 0 || list[r] <= idx) ok = false
else idx = list[r]
}
}
if (ok) ans++
}
return ans
}
Python3 代码:
class Solution:
def numMatchingSubseq(self, s: str, words: List[str]) -> int:
dmap = defaultdict(list)
for i, c in enumerate(s):
dmap[c].append(i)
ans = 0
for w in words:
ok = True
idx = -1
for i in range(len(w)):
idxs = dmap[w[i]]
l, r = 0, len(idxs) - 1
while l < r :
mid = l + r >> 1
if dmap[w[i]][mid] > idx:
r = mid
else:
l = mid + 1
if r < 0 or dmap[w[i]][r] <= idx:
ok = False
break
else:
idx = dmap[w[i]][r]
ans += 1 if ok else 0
return ans
-
时间复杂度:令 n为s长度,m为words长度,l = 50为 长度的最大值。构造map的复杂度为 ;统计符合要求的 的数量复杂度为 。整体复杂度为 -
空间复杂度:
我是宫水三叶,每天都会分享算法知识,并和大家聊聊近期的所见所闻。
欢迎关注,明天见。
更多更全更热门的「笔试/面试」相关资料可访问排版精美的 合集新基地 🎉🎉
![洛谷 P1075 [NOIP2012 普及组] 质因数分解](https://img-blog.csdnimg.cn/direct/ccf98a2ac1b84976baec6912b93bdddc.png)




![[notice] A new release of pip is available: 23.2.1 -> 24.0](https://img-blog.csdnimg.cn/direct/d342cd66caec4413b3a7a4966ccd9330.png)

![杂题——1028: [编程入门]自定义函数求一元二次方程](https://img-blog.csdnimg.cn/direct/2c937da4125b43ba9f66215ea5a8abdc.png)