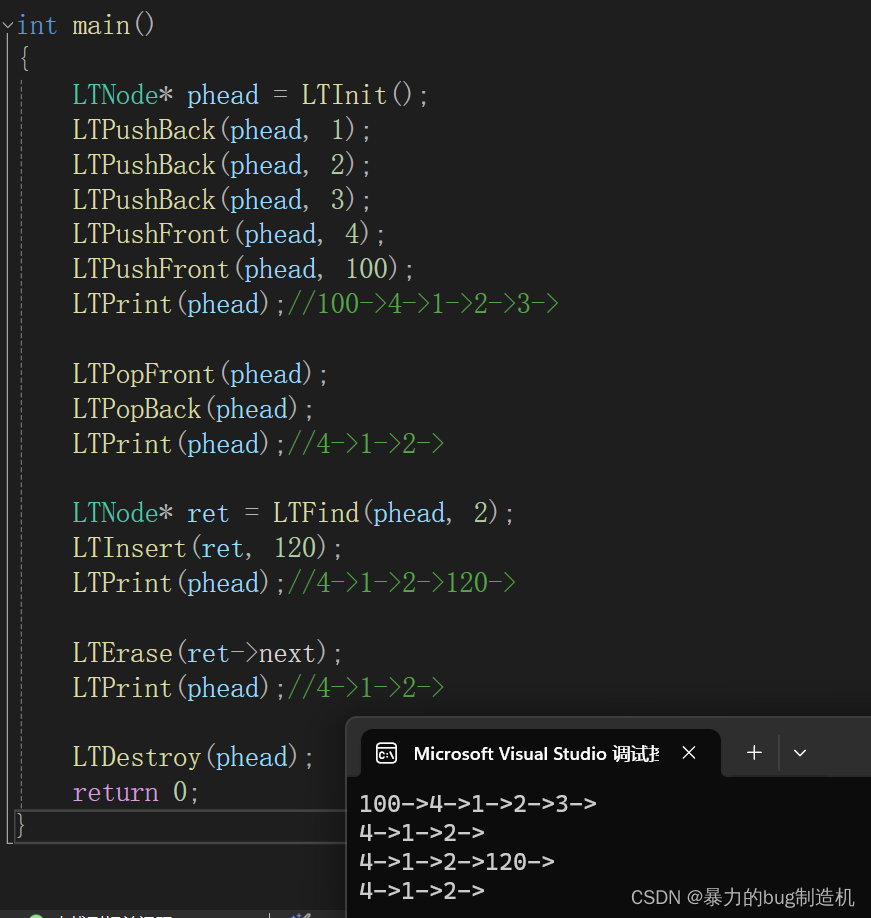
并发:假的多任务
并行:真的多任务
实现多线程用——threading模块
import threading
import time
def shuru():
for i in range(1,4):
print("正在输入")
time.sleep(1)
def shuchu():
for i in range(1,4):
print("正在输出")
time.sleep(1)
t = threading.Thread(target=shuru)
t2 = threading.Thread(target=shuchu)
t.start()
t2.start()在遇到start时,才会运行。 (创建一个Thread不会创建一个线程)
start调用后才会创建

这个就是个简单的多线程,但是如果我们用,输入代表,输入网站url,输出为下载到文件。
这就是混乱的,就会不好满足。
2.查看线程数量。
threading.enumerate()
3.传参
t2 = threading.Thread(target=shuchu,args=(10,))
args传入的是一个“元组”
<指名道姓的传参>
t2 = threading.Thread(target=shuchu,kwargs={'num1':44,'num':10})
注意形式
=========================================================================
创建线程的另一种方式:(如果想要线程,线程之间共享数据,用上面的方法就会不好)
用类的方式去实现。
import threading
import time
class Task(threading.Thread):
def run(self):
while True:
print("qqqq")
time.sleep(1)
t = Task()
t.start()
print(len(threading.enumerate()))
while True:
print("ppp")
time.sleep(1)

可以看出有两个线程。
一但start()就会到run方法里面去——这里只会去执行run里面。想要用别的方法,就在run里面 去调用
队列(Queue)——为什么要用——就是要配合,就像,先生产,再消费。也就是说,就像提取网络图片,是先拿到网址,然后请求,然后保存的。是有先后顺序的。
可以让多个线程之间实现数据共享,可以实现先,存入,然后先出去。
1.先进先出-queue.Queue()
这里的put和get,会等待。直到有数据。没有数据时就会一直等待
import queue
list_m = queue.Queue()
list_m.put('123')
print(list_m.get()) 
存入然后打印
import queue
list_m = queue.Queue()
list_m.put('123')
list_m.put('456')
list_m.put('789')
print(list_m.get())
print(list_m.get())
print(list_m.get())

先进先出。
2.先进后出——queue.LifoQueue()
import queue
list_m = queue.LifoQueue()
list_m.put('123')
list_m.put('456')
list_m.put('789')
print(list_m.get())
print(list_m.get())
print(list_m.get())
3.优先级—— queue.PriorityQueue()
数字越小优先级越高
import queue
list_m = queue.PriorityQueue()
list_m.put((1,'123'))
list_m.put((7,'456'))
list_m.put((2,'789'))
print(list_m.get())
print(list_m.get())
print(list_m.get())
下来进入正题:关于多线程网站的爬取 ——BeautifulSoup+threading

简单说一下下面代码的思路:
1.先建立,两个queue.Queue队列,用来存放url(这个是页数) 和html(这个是书名的网址)
2.让把目录的网站都放在url队列里
3.然后再建立三个线程去,获得html,直到 url_queue.get()获取完成,机会阻塞。这个线程就停了
4.然后建立两个去保存标题
import queue
import time
import random
import threading
import requests
from bs4 import BeautifulSoup
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1,50+1)
]
def craw(url):
r= requests.get(url)
return r.text
def parse(html):
#class="post-item-title"
soup = BeautifulSoup(html,'html.parser')
links = soup.find_all('a',class_='post-item-title')
return [(link["href"],link.get_text())for link in links]
def do_craw(url_queue:queue.Queue,html_queue:queue.Queue):
while True:
url = url_queue.get()
html = craw(url)
html_queue.put(html)
time.sleep(random.randint(1,2))#随机的睡眠一到两秒
def do_parse(html_queue:queue.Queue,fout):
while True:
html = html_queue.get()
results = parse(html)
for result in results:
fout.write(str(result)+"\n")
time.sleep(random.randint(1,2))#随机的睡眠一到两秒
if __name__=="__main__":
url_queue=queue.Queue()
html_queue = queue.Queue()
for url in urls:
url_queue.put(url)
#生产者线程
for idx in range(3):
t=threading.Thread(target=do_craw,args=(url_queue,html_queue))
t.start()
#消费者线程
fout = open("03.data.txt","w")
for idx in range(2):
t=threading.Thread(target=do_parse,args=(html_queue,fout))
t.start()主要用到几个函数:
其中两个要去线程的函数:
1.def do_parse(html_queue:queue.Queue,fout):
2.def do_craw(url_queue:queue.Queue,html_queue:queue.Queue):

将你的线程对象给,这个函数。也就是实现了,线程之间的数据的共享
你给的其实就是列表,然后你给进去然后,一个一个get。直到get结束