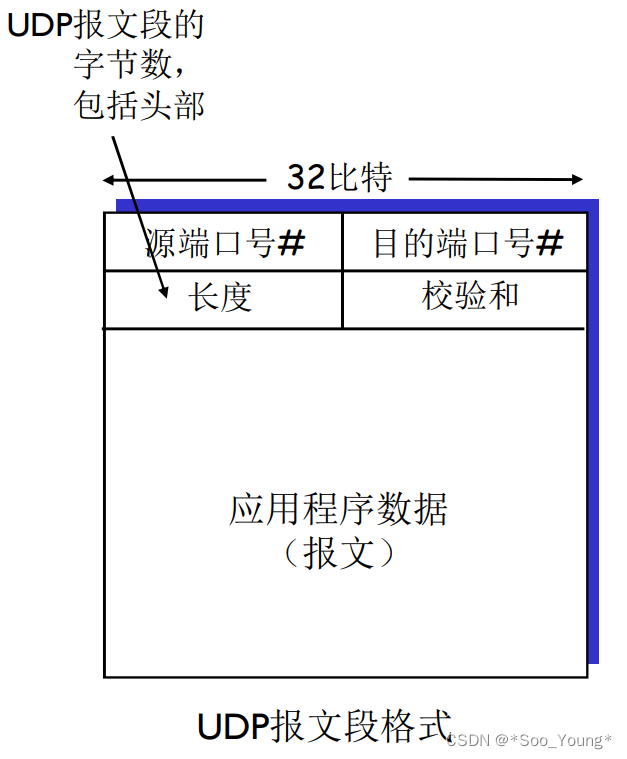
flink sql 实战实例 及延伸问题
- Flink SQL 计算用户分布
- Flink SQL 计算 DAU
- 多topic 数据更新mysql topic接入mysql
- 引入 upsert-kafka-connector 以1.14.4版本为例
- 数据倾斜问题:
- 让你使用用户心跳日志(20s 上报一次)计算同时在线用户、DAU 指标,你怎么设计链路?
- 多维高阶聚合
- FlinkSql Upsert 与 Primary Key
- flinksql Hive 流批一体
- Streaming Sink
- Streaming Source
- Hive Dialect
- Filesystem Connector
Flink SQL 计算用户分布
⭐ 需求:上游是一个 kafka 数据源,数据内容是用户 QQ 等级变化明细数据(time,uid,level)。需要你求出当前每个等级的用户数。
- 如果需要可以打开 minibatch
select
level
, count(1) as uv
, max(time) as time
from (
select
uid
, level
, time
, row_number() over (partition by uid order by time desc) rn
from source
) tmp
where rn =1
group by
level
Flink SQL 计算 DAU
⭐ 需求:数据源:用户心跳日志(uid,time,type)。计算分 Android,iOS 的 DAU,最晚一分钟输出一次当日零点累计到当前的结果。
SELECT
window_start
, window_end
, platform
, sum(bucket_dau) as dau
from (
SELECT
window_start
, window_end
, platform
, count(distinct uid) as bucket_dau
FROM TABLE(
CUMULATE(
TABLE user_log,
DESCRIPTOR(time),
INTERVAL '60' SECOND
, INTERVAL '1' DAY))
GROUP BY
window_start
, window_end
, platform
, MOD(HASH_CODE(user_id), 1024)
) tmp
GROUP by
window_start
, window_end
, platform
优点:如果是曲线图的需求,可以完美回溯曲线图。
缺点:大窗口之间如果有数据乱序,有丢数风险;并且由于是 watermark 推动产出,所以数据产出会有延迟。
或或或或或或或或或或或或或或或或或或或或或或或
-- 如果需要可以打开 minibatch
select
platform
, count(1) as dau
, max(time) as time
from (
select
uid
, platform
, time
, row_number() over (partition by uid, platform, time / 24 / 3600 / 1000 order by time desc) rn
from source
) tmp
where rn = 1
group by
platform
优点:计算快。
缺点:任务发生 failover,曲线图不能很好回溯。没法支持 cube 计算。
或或或或或或或或或或或或或或或或或或或或或或或
-- 如果需要可以打开 minibatch
SELECT
max(time) as time
, platform
, sum(bucket_dau) as dau
from (
SELECT
max(time) as time
, platform
, count(distinct uid) as bucket_dau
FROM source
GROUP BY
platform
, MOD(HASH_CODE(user_id), 1024)
) t
GROUP by
platform
优点:计算快,支持 cube 计算。
缺点:任务发生 failover,曲线图不能很好回溯。
多topic 数据更新mysql topic接入mysql
-- 作业开发逻辑
-- mysql -h数据库 -ubigdata_rw -pe20ycoy3yp09qij0kj8ngpcgxyywgmc9
-- -Dyarn.application.queue=stream_data -Dyarn.provided.lib.dirs=/streamx/flink/flink-1.12.5/lib/
CREATE TABLE Direction_Wind_create_source (
properties ROW< area VARCHAR,comment_count BIGINT,share_count BIGINT,like_count BIGINT,user_id VARCHAR,app_id BIGINT,feed_type BIGINT ,feed_id VARCHAR,`timestamp` VARCHAR >
, proctime AS PROCTIME()
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'Direction_Wind_create_feed',
'connector.properties.bootstrap.servers'='Direction_Wind-hadoop-hdp-kafka-01:9092,Direction_Wind-hadoop-hdp-kafka-02:9092,Direction_Wind-hadoop-hdp-kafka-03:9092',
'connector.startup-mode' = 'latest-offset',
'update-mode' = 'append',
'format.type' = 'json',
'connector.properties.group.id' = 'dynamicRelease_bigdata_Direction_Wind_sql_test',
'format.derive-schema' = 'true'
);
CREATE TABLE Direction_Wind_like_source (
properties ROW< area VARCHAR,comment_count BIGINT,share_count BIGINT,like_count BIGINT,user_id VARCHAR,app_id BIGINT,feed_type BIGINT ,feed_id VARCHAR,`timestamp` VARCHAR >
, proctime AS PROCTIME()
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'Direction_Wind_like_feed',
'connector.properties.bootstrap.servers'='Direction_Wind-hadoop-hdp-kafka-01:9092,Direction_Wind-hadoop-hdp-kafka-02:9092,Direction_Wind-hadoop-hdp-kafka-03:9092',
'connector.startup-mode' = 'latest-offset',
'update-mode' = 'append',
'format.type' = 'json',
'connector.properties.group.id' = 'dynamicRelease_bigdata_Direction_Wind_sql_test',
'format.derive-schema' = 'true'
);
CREATE TABLE Direction_Wind_comment_source (
properties ROW< area VARCHAR,comment_count BIGINT,share_count BIGINT,like_count BIGINT,user_id VARCHAR,app_id BIGINT,feed_type BIGINT ,feed_id VARCHAR,`timestamp` VARCHAR >
, proctime AS PROCTIME()
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'Direction_Wind_comment_feed',
'connector.properties.bootstrap.servers'='Direction_Wind-hadoop-hdp-kafka-01:9092,Direction_Wind-hadoop-hdp-kafka-02:9092,Direction_Wind-hadoop-hdp-kafka-03:9092',
'connector.startup-mode' = 'latest-offset',
'update-mode' = 'append',
'format.type' = 'json',
'connector.properties.group.id' = 'dynamicRelease_bigdata_Direction_Wind_sql_test',
'format.derive-schema' = 'true'
);
CREATE TABLE Direction_Wind_share_source (
properties ROW< area VARCHAR,comment_count BIGINT,share_count BIGINT,like_count BIGINT,user_id VARCHAR,app_id BIGINT,feed_type BIGINT ,feed_id VARCHAR,`timestamp` VARCHAR >
, proctime AS PROCTIME()
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'Direction_Wind_share_feed',
'connector.properties.bootstrap.servers'='Direction_Wind-hadoop-hdp-kafka-01:9092,Direction_Wind-hadoop-hdp-kafka-02:9092,Direction_Wind-hadoop-hdp-kafka-03:9092',
'connector.startup-mode' = 'latest-offset',
'update-mode' = 'append',
'format.type' = 'json',
'connector.properties.group.id' = 'dynamicRelease_bigdata_Direction_Wind_sql_test',
'format.derive-schema' = 'true'
);
CREATE TABLE Direction_Wind_create_sink (
feed_id VARCHAR
,user_id VARCHAR
,feed_type VARCHAR
,time_stamp timestamp(3)
,area VARCHAR
, PRIMARY KEY (feed_id) NOT ENFORCED
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://数据库:3306/bireport?useUnicode=true&characterEncoding=UTF-8&useSSL=false',
'connector.用户' = 'bigdata_all',
'connector.pass@word' = '密码',
'connector.table' = 'Direction_Wind_dynamic_test',
'connector.write.flush.max-rows' = '1',
'connector.write.flush.interval' = '2s'
-- 'connector' = 'print'
);
INSERT INTO Direction_Wind_create_sink
select * from (
SELECT properties.feed_id as feed_id
,properties.user_id as user_id
,cast(properties.feed_type as varchar) as feed_type
-- ,TO_DATE(properties.`timestamp`) as time_stamp
,TO_TIMESTAMP(FROM_UNIXTIME(cast(properties.`timestamp` as bigint))) as time_stamp
,properties.area as area
,ROW_NUMBER() OVER (PARTITION BY properties.feed_id ORDER BY properties.`timestamp` asc) as rowNum
FROM Direction_Wind_create_source
) where rowNum = 1
;
CREATE TABLE Direction_Wind_like_sink (
feed_id VARCHAR
,like_count BIGINT
,feed_type VARCHAR
,area VARCHAR
, PRIMARY KEY (feed_id) NOT ENFORCED
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://数据库:3306/bireport?useUnicode=true&characterEncoding=UTF-8&useSSL=false',
'connector.用户' = 'bigdata_all',
'connector.pass@word' = '密码',
'connector.table' = 'Direction_Wind_dynamic_test',
'connector.write.flush.max-rows' = '1',
'connector.write.flush.interval' = '2s'
-- 'connector' = 'print'
);
INSERT INTO Direction_Wind_like_sink
select * from (
SELECT properties.feed_id as feed_id
,properties.like_count as like_count
,cast(properties.feed_type as varchar) as feed_type
,properties.area as area
,ROW_NUMBER() OVER (PARTITION BY properties.feed_id ORDER BY properties.`timestamp` asc) as rowNum
FROM Direction_Wind_like_source
) where rowNum = 1
;
CREATE TABLE Direction_Wind_comment_sink (
feed_id VARCHAR
,comment_count BIGINT
,feed_type VARCHAR
,area VARCHAR
, PRIMARY KEY (feed_id) NOT ENFORCED
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://数据库:3306/bireport?useUnicode=true&characterEncoding=UTF-8&useSSL=false',
'connector.用户' = 'bigdata_all',
'connector.pass@word' = '密码',
'connector.table' = 'Direction_Wind_dynamic_test',
'connector.write.flush.max-rows' = '1',
'connector.write.flush.interval' = '2s'
-- 'connector' = 'print'
);
INSERT INTO Direction_Wind_comment_sink
select * from (
SELECT properties.feed_id as feed_id
,properties.comment_count as comment_count
,cast(properties.feed_type as varchar) as feed_type
,properties.area as area
,ROW_NUMBER() OVER (PARTITION BY properties.feed_id ORDER BY properties.`timestamp` asc) as rowNum
FROM Direction_Wind_comment_source
) where rowNum = 1
;
CREATE TABLE Direction_Wind_share_sink (
feed_id VARCHAR
,use_count BIGINT
,feed_type VARCHAR
,area VARCHAR
, PRIMARY KEY (feed_id) NOT ENFORCED
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://数据库:3306/bireport?useUnicode=true&characterEncoding=UTF-8&useSSL=false',
'connector.用户' = 'bigdata_all',
'connector.pass@word' = '密码',
'connector.table' = 'Direction_Wind_dynamic_test',
'connector.write.flush.max-rows' = '1',
'connector.write.flush.interval' = '2s'
-- 'connector' = 'print'
);
INSERT INTO Direction_Wind_share_sink
select * from (
SELECT properties.feed_id as feed_id
,properties.share_count as use_count
,cast(properties.feed_type as varchar) as feed_type
,properties.area as area
,ROW_NUMBER() OVER (PARTITION BY properties.feed_id ORDER BY properties.`timestamp` asc) as rowNum
FROM Direction_Wind_share_source
) where rowNum = 1
;
这里要注意,如果去重直接用group by的方式,在批处理中还好,流式处理中,这部分数据会存放到内容中,并且越积越大,没有ttl,时间一长就会oom了,
Flink SQL Deduplicate 写法,row_number partition by user_id order by proctime asc,此 SQL 最后生成的算子只会在第一条数据来的时候更新 state,后续访问不会更新 state TTL,因此 state 会在用户设置的 state TTL 时间之后过期。 所以按理说 这种去重方式 不会百分百 有用,只能保持一段时间的 去重,感觉是不对的,正在测试中。
经过测试 在flink 1.12 版本时,flinksql的upsert into 功能 ,也就是 这种写法
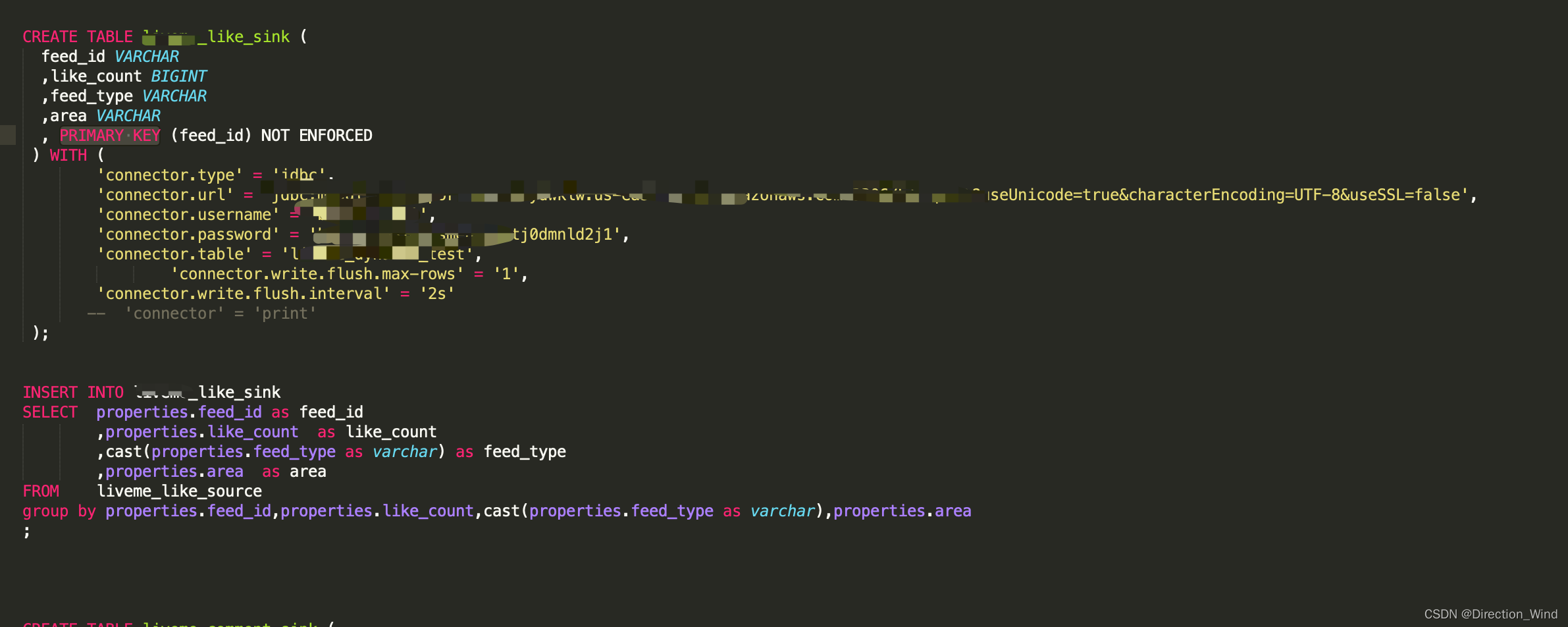
是可以实现 update 功能的,但 必须要 group by 数据才行,并且要求把 把所有select 语句中的字段 都加入到 group by 语句,但这么写,又会导致 state 不停增大,过一段时间就会 OOM
引入 upsert-kafka-connector 以1.14.4版本为例
基本工作机制:
- source:

- sink:

tenv.executeSql(
"CREATE TABLE upsert_kafka ("
+ "province STRING, "
+ "pv BIGINT, "
+ "PRIMARY KEY (province) NOT ENFORCED"
+ ") WITH ("
+ "'connector' = 'upsert-kafka', "
+ "'topic' = 'upsert_kafka2', "
+ "'properties.bootstrap.servers' = 'doitedu:9092', "
+ "'key.format' = 'csv', "
+ "'value.format' = 'csv'"
+ ")"
);
DataStreamSource<Row> stream = env.fromElements(
Row.ofKind(RowKind.INSERT, "sx", 1),
Row.ofKind(RowKind.INSERT, "sx", 2),
Row.ofKind(RowKind.INSERT, "gx", 1),
Row.ofKind(RowKind.INSERT, "sx", 2),
Row.ofKind(RowKind.INSERT, "gx", 2)
);
tenv.createTemporaryView("s", stream, Schema.newBuilder()
.column("f0", DataTypes.STRING().notNull())
.column("f1", DataTypes.INT())
.build());
// 将查询结果(changelog 流),写入 kafka
tenv.executeSql("insert into upsert_kafka select f0, sum(f1) as pv from s group by f0");
写入的数据为

// 从 kafka 再读出上面的 changelog 结果 tenv.executeSql(" select * from upsert_kafka").print();
tenv.executeSql("select * from upsert_kafka").print();
读出的数据为

数据倾斜问题:
⭐ 场景:拿计算直播间的同时在线观看用户数来说,大 v 直播间的人数会比小直播间的任务多几个量级,因此如果计算一个直播间的数据需要注意这种业务数据倾斜的特点
⭐ 解决方案:计算这种数据时,我们可以先按照直播间 id 将数据进行打散,如下 SQL 案例所示(DataStream 也是相同的解决方案),内层打散,外层合并:
select
id
, sum(bucket_uv) as uv
from (
select
id
, count(distinct uid) as bucket_uv
from source
group by
id
, mod(uid, 1000) -- 将大 v 分桶打散
)
group by id
⭐ 数据任务处理时参数\代码处理逻辑导致倾斜:
⭐ 场景:比如有时候虽然用户已经按照 key 进行分桶计算,但是【最大并发度】设置为 150,【并发度】设置为 100,会导致 keygroup 在 sub-task 的划分不均匀(其中 50 个 sub-task 的 keygroup 为 2 个,剩下的 50 个 sub-task 为 1 个)导致数据倾斜。
⭐ 解决方案:设置合理的【最大并发度】【并发度】,【最大并发度】最好为【并发度】的倍数关系,比如【最大并发度】1024,【并发度】512
⭐ 我已经设置【数据分桶打散】+【最大并发为并发 n 倍】,为啥还出现数据倾斜?
⭐ 场景:你的【数据分桶】和【最大并发数】之间可能是不均匀的。因为 Flink 会将 keyby 的 key 拿到之后计算 hash 值,然后根据 hash 值去决定发送到那个 sub-task 去计算。这是就有可能出现你的【数据分桶】key 经过 hash 计算完成之后,并不能均匀的发到所有的 keygroup 中。比如【最大并发数】4096,【数据分桶】key 只有 1024 个,那么这些数据必然最多只能到 1024 个 keygroup 中,有可能还少于 1024,从而导致剩下的 3072 个 keygroup 没有任何数据
⭐ 解决方案:其实可以利用【数据分桶】key 和【最大并行度】两个参数,在 keyby 中实现和 Flink key hash 选择 keygroup 的算法一致的算法,在【最大并发数】4096,【数据分桶】为 4096 时,做到分桶值为 1 的数据一定会发送到 keygroup1 中,2 一定会发到 keygroup2 中,从而缓解数据倾斜。
最大并行度的设置:最大并行度可以自己设置,也可以框架默认生成;默认的算法是取当前算子并行度的 1.5 倍和 2 的 7 次方比较,取两者之间的最大值,然后用上面的结果和 2 的 15 次方比较,取其中的最小值为默认的最大并行度,非常不建议自动生成,建议用户自己设置。
让你使用用户心跳日志(20s 上报一次)计算同时在线用户、DAU 指标,你怎么设计链路?
⭐ 有提到将用户上线标记为 1,下线标记为 0 的,然后将上线下线数据发到消息队列用实时计算引擎统计的
⭐ 有提到将用户心跳日志借助 Session Window Dynamic Gap 计算的
多维高阶聚合

FlinkSql Upsert 与 Primary Key
在flink1.11 及以后,flinksql 与blink 做了merge 所以有重大变更
流计算的一个典型场景是把聚合的数据写入到 Upsert Sink 中,比如 JDBC、HBase,当遇到复杂的 SQL 时,时常会出现:

UpsertStreamTableSink 需要上游的 Query 有完整的 Primary Key 信息,不然就直接抛异常。这个现象涉及到 Flink 的 UpsertStreamTableSink 机制。顾名思义,它是一个更新的 Sink,需要按 Key 来更新,所以必须要有 Key 信息。
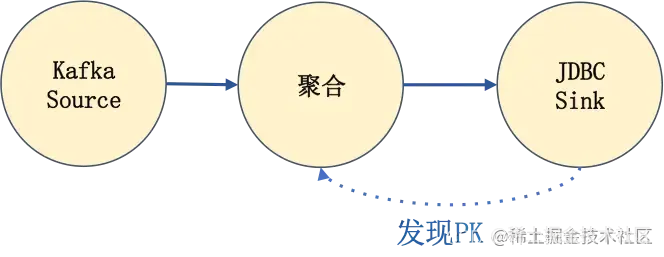
如何发现 Primary Key?一个方法是让优化器从 Query 中推断,如下图发现 Primary Key 的例子。
这种情况下在简单 Query 当中很好,也满足语义,也非常自然。但是如果是一个复杂的 Query,比如聚合又 Join 再聚合,那就只有报错了。不能期待优化器有多智能,很多情况它都不能推断出 PK,而且,可能业务的 SQL 本身就不能推断出 PK,所以导致了这样的异常。
怎么解决问题?Flink 1.11 彻底的抛弃了这个机制,不再从 Query 来推断 PK 了,而是完全依赖 Create table 语法。比如 Create 一个 jdbc_table,需要在定义中显式地写好 Primary Key(后面 NOT ENFORCED 的意思是不强校验,因为 Connector 也许没有具备 PK 的强校验的能力)。当指定了 PK,就相当于就告诉框架这个Jdbc Sink 会按照对应的 Key 来进行更新。如此,就跟 Query 完全没有关系了,这样的设计可以定义得非常清晰,如何更新完全按照设置的定义来。
CREATE TABLE jdbc_table (
id BIGINT,
...
PRIMARY KEY (id) NOT ENFORCED
)
flinksql Hive 流批一体
首先看传统的 Hive 数仓。一个典型的 Hive 数仓如下图所示。一般来说,ETL 使用调度工具来调度作业,比如作业每天调度一次或者每小时调度一次。这里的调度,其实也是一个叠加的延迟。调度产生 Table1,再产生 Table2,再调度产生 Table3,计算延时需要叠加起来
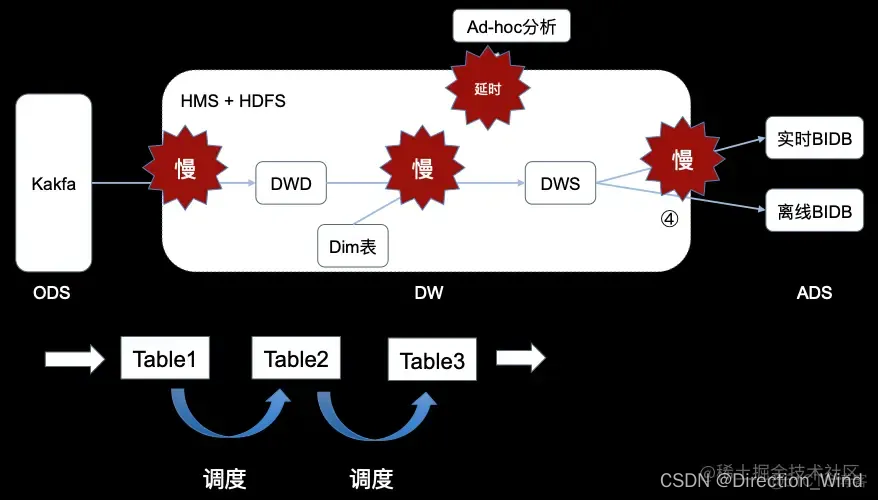
问题是慢,延迟大,并且 Ad-hoc 分析延迟也比较大,因为前面的数据入库,或者前面的调度的 ETL 会有很大的延迟。Ad-hoc 分析再快返回,看到的也是历史数据。
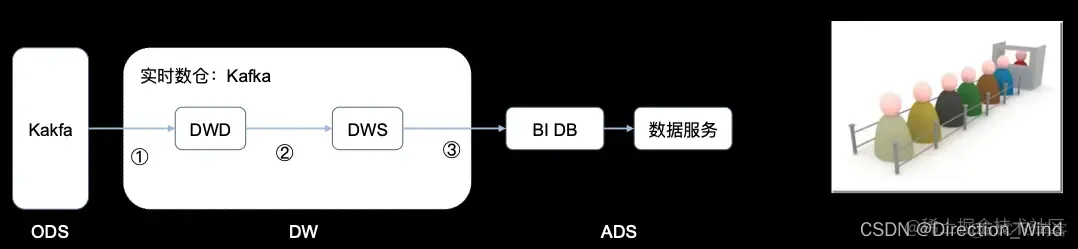
所以现在流行构建实时数仓,从 Kafka 读计算写入 Kafka,最后再输出到 BI DB,BI DB 提供实时的数据服务,可以实时查询。Kafka 的 ETL 为实时作业,它的延时甚至可能达到毫秒级。实时数仓依赖 Queue,它的所有数据存储都是基于 Queue 或者实时数据库,这样实时性很好,延时低。但是:
第一,基于 Queue,一般来说就是行存加 Queue,存储效率其实不高。
第二,基于预计算,最终会落到 BI DB,已经是聚合好的数据了,没有历史数据。而且 Kafka 存的一般来说都是 15 天以内的数据,没有历史数据,意味着无法进行 Ad-hoc 分析。所有的分析全是预定义好的,必须要起对应的实时作业,且写到 DB 中,这样才可用。对比来说,Hive 数仓的好处在于它可以进行 Ad-hoc 分析,想要什么结果,就可以随时得到什么结果。
能否结合离线数仓和实时数仓两者的优势,然后构建一个 Lambda 的架构?
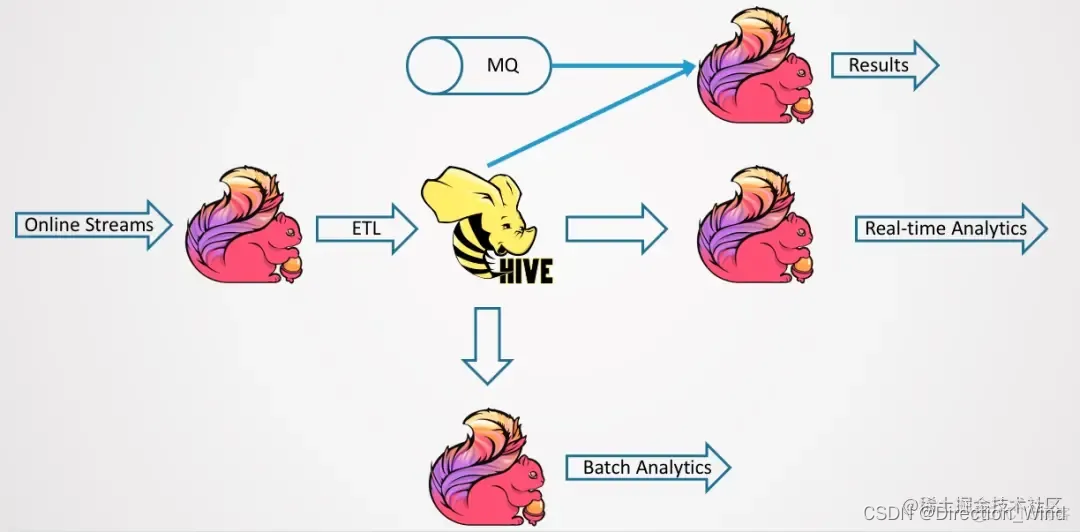
核心问题在于成本过高。无论是维护成本、计算成本还是存储成本等都很高。并且两边的数据还要保持一致性,离线数仓写完 Hive 数仓、SQL,然后实时数仓也要写完相应 SQL,将造成大量的重复开发。还可能存在团队上分为离线团队和实时团队,两个团队之间的沟通、迁移、对数据等将带来大量人力成本。如今,实时分析会越来越多,不断的发生迁移,导致重复开发的成本也越来越高。少部分重要的作业尚可接受,如果是大量的作业,维护成本其实是非常大的。
如何既享受 Ad-hoc 的好处,又能实现实时化的优势?一种思路是将 Hive 的离线数仓进行实时化,就算不能毫秒级的实时,准实时也好。所以,Flink 1.11 在 Hive 流批一体上做了一些探索和尝试,如下图所示。它能实时地按 Streaming 的方式来导出数据,写到 BI DB 中,并且这套系统也可以用分析计算框架来进行 Ad-hoc 的分析。这个图当中,最重要的就是 Flink Streaming 的导入。
Streaming Sink
早期 Flink 版本在 DataStreaming 层,已经有一个强大的 StreamingFileSink 将流数据写到文件系统。它是一个准实时的、Exactly-once 的系统,能实现一条数据不多,一条数据不少的 Sink。

具体原理是基于两阶段提交:
第一阶段:SnapshotPerTask,关闭需要 Commit 的文件,或者记录正在写的文件的 Offset。
第二阶段:NotifyCheckpointComplete,Rename 需要 Commit 的文件。注意,Rename 是一个原子且幂等的操作,所以只要保证 Rename 的 At-least-once,即可保证数据的 Exactly-once。
这样一个 File system 的 Writer 看似比较完美了。但是在 Hive 数仓中,数据的可见性是依赖 Hive Metastore 的,那在这个流程中,谁来通知 Hive Metastore 呢?
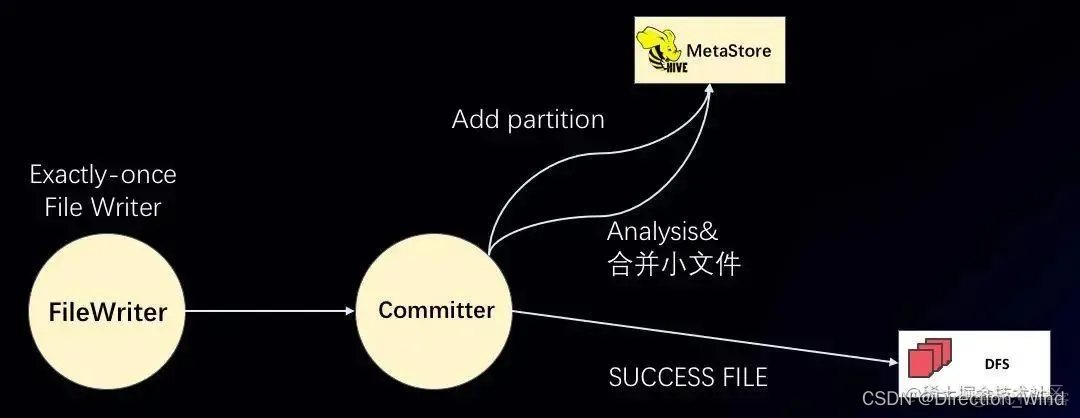
SQL 层在 StreamingFileSink,扩展了 Partition 的 Committer。
相当于不仅要进行 File 的 Commit,还要进行 Partition 的 Commit。如图所示,FileWriter 对应之前的 StreamingFileSink,它提供的是 Exactly-once 的 FileWriter。而后面再接了一个节点 PartitionCommitter。支持的 Commit Policy 有:
- 内置支持 Add partition 到 Hive metastore;
- 支持写 SuccessFile 到文件系统当中;
- 并且也可以自定义 Committer,比如可以 analysis partition、合并 partition 里面的小文件。
Committer 挂在 Writer 后, 由 Commit Trigger 决定什么时机来 commit :
-
默认的 commit 时机是,有文件就立即 commit。因为所有 commit 都是可重入的,所以这一点是可允许的。
-
另外,也支持通过 partition 时间和 Watermark 来共同决定的。比如小时分区,如果现在时间到 11 点,10 点的分区就可以 commit 了。Watermark 保证了作业当前的准确性。
Streaming Source
Hive 数仓中存在大量的 ETL 任务,这些任务往往是通过调度工具来周期性的运行,这样做主要有两个问题:
- 实时性不强,往往调度最小也是小时级。
- 流程复杂,组件多,容易出现问题。
针对这些离线的 ETL 作业,Flink 1.11 为此开发了实时化的 Hive 流读,支持:
- Partition 表,监控 Partition 的生成,增量读取新的 Partition。
- 非 Partition 表,监控文件夹内新文件的生成,增量读取新的文件。
甚至可以使用 10 分钟级别的分区策略,使用 Flink 的 Hive streaming source 和 Hive streaming sink ,可以大大提高 Hive 数仓的实时性到准实时分钟级,在实时化的同时,也支持针对 Table 全量的 Ad-hoc 查询,提高灵活性。
SELECT * FROM hive_table /*+ OPTIONS('streaming-source.enable'=’true’, 'streaming-source.consume-start-offset'='2020-05-20') */;
/*+ OPTIONS('streaming-source.enable' = 'true','streaming-source.partition.include' = 'latest',
'streaming-source.partition-order' = 'create-time','streaming-source.monitor-interval' = '1 h') */
另外除了 Scan 的读取方式,Flink 1.11 也支持了 Temporal Join 的方式,也就是以前常说的 Streaming Dim Join。
SELECT
o.amout, o.currency, r.rate, o.amount * r.rate
FROM
Orders AS o
JOIN LatestRates FOR SYSTEM_TIME AS OF o.proctime AS r
ON r.currency = o.currency
目前支持的方式是 Cache All,并且是不感知分区的,比较适合小表的情况。
Hive Dialect
Flink SQL 遵循的是 ANSI-SQL 的标准,而 Hive SQL 有它自己的 HQL 语法,它们之间的语法、语义都有些许不同。
如何让 Hive 用户迁移到 Flink 生态中,同时避免用户太大的学习成本?为此, Flink SQL 1.11 提供了 Hive Dialect,可以使得用户在 Flink 生态中使用 HQL 语言来计算。目前只支持 DDL,后续版本会逐步攻坚 Qeuries。
Filesystem Connector
Hive Integration 提供了一个重量级的集成,功能丰富,但是环境比较复杂。如果只是想要一个轻量级的 Filesystem 读写呢?
Flink table 在长久以来只支持一个 CSV 的 Filesystem Table,并且还不支持 Partition,行为上在某些方面也有些不符合大数据计算的直觉。
Flink 1.11 重构了整个 Filesystem connector 的实现:
- 结合 Partition,现在,Filesystem connector 支持 SQL 中 Partition 的所有语义,支持 Partition 的 DDL,支持 Partition Pruning,支持静态 / 动态 Partition 的插入,支持 Overwrite 的插入。
- 支持各种 Formats: ■ CSV ■ JSON ■ Aparch AVRO ■ Apache Parquet ■ Apache ORC
- 支持 Batch 的读写。
- 支持 Streaming sink,也支持 Partition commit,支持写 Success 文件。
用几句简单的 SQL,不用搭建 Hive 集成环境即可:
- 启动一个流作业写入 Filesystem 中,然后在 Hive 端即可查询到 Filesystem 上的数据,相比之前 Datastream 的作业,简单 SQL 即可搞定离线数据的入库。
- 通过 Filesystem Connector 来查询 Hive 数仓中的数据,功能没有 Hive 集成那么全,但是定义简单。