COPNER: Contrastive Learning with Prompt Guiding for Few-shot Named Entity Recognition
原文与代码链接: https://github.com/AndrewHYC/COPNER
一、项目结构
二、代码分析
1.定义参数
配置训练环境
parser.add_argument('--gpu', default='0',
help='the gpu number for traning')
parser.add_argument('--seed', type=int, default=42,
help='random seed')
训练任务定义
parser.add_argument('--mode', default='inter',
help='training mode, must be in [inter, intra, supervised, i2b2, conll, wnut, mit-movie]')
parser.add_argument('--task', default='cross-label-space',
help='training task, must be in [cross-label-space, domain-transfer, in-label-space]')
parser.add_argument('--trainN', default=5, type=int,
help='N in train')
parser.add_argument('--N', default=5, type=int,
help='N way')
parser.add_argument('--K', default=1, type=int,
help='K shot')
parser.add_argument('--Q', default=1, type=int,
help='Num of query per class')
parser.add_argument('--support_num', default=0, type=int,
help='the id number of support set')
parser.add_argument('--zero_shot', action='store_true',
help='')
parser.add_argument('--only_test', action='store_true',
help='only test')
parser.add_argument('--load_ckpt', default=None,
help='load ckpt')
parser.add_argument('--ckpt_name', type=str, default='',
help='checkpoint name.')
模型配置
parser.add_argument('--pretrain_ckpt', default='./premodel/roberta-wwm-ext-base',
help='bert pre-trained checkpoint: bert-base-uncased / bert-base-cased')
parser.add_argument('--prompt', default=1, type=int, choices=[0,1,2],
help='choice in [0,1,2]:\
0: Continue Prompt\
1: Partition Prompt\
2: Queue Prompt')
parser.add_argument('--pseudo_token', default='[S]', type=str,
help='pseudo_token')
parser.add_argument('--max_length', default=64, type=int,
help='max length')
parser.add_argument('--ignore_index', type=int, default=-1,
help='label index to ignore when calculating loss and metrics')
parser.add_argument('--struct', action='store_true',
help='StructShot parameter to re-normalizes the transition probabilities')
parser.add_argument('--tau', default=1, type=float,
help='the temperature rate for contrastive learning')
parser.add_argument('--struct_tau', default=0.32, type=float,
help='the tau in the viterbi decode')
训练配置
parser.add_argument('--batch_size', default=16, type=int,
help='batch size')
parser.add_argument('--test_bz', default=1, type=int,
help='test or val batch size')
parser.add_argument('--train_iter', default=10000, type=int,
help='num of iters in training')
parser.add_argument('--val_iter', default=200, type=int,
help='num of iters in validation')
parser.add_argument('--test_iter', default=5000, type=int,
help='num of iters in testing')
parser.add_argument('--val_step', default=200, type=int,
help='val after training how many iters')
parser.add_argument('--adapt_step', default=5, type=int,
help='adapting how many iters in validing or testing')
parser.add_argument('--adapt_auto', action='store_true',
help='adapting how many iters in validing or testing')
parser.add_argument('--threshold_alpha', default=0.1, type=float,
help='Gradient descent change threshold for early stopping')
parser.add_argument('--threshold_beta', default=0.5, type=float,
help='loss threshold for early stopping')
parser.add_argument('--lr', default=1e-4, type=float,
help='learning rate of Training')
parser.add_argument('--adapt_lr', default=None, type=float,
help='learning rate of Adapting')
parser.add_argument('--grad_iter', default=1, type=int,
help='accumulate gradient every x iterations')
parser.add_argument('--early_stopping', type=int, default=3000,
help='iteration numbers to stop without performance increasing')
parser.add_argument('--use_sgd_for_lm', action='store_true',
help='use SGD instead of AdamW for BERT.')
2.主函数
调用参数,配置预训练模型
def main():
trainN = opt.trainN if opt.trainN is not None else opt.N # opt.trainN = opt.N = 5
N = opt.N # 5
K = opt.K # 1
Q = opt.Q # 1
max_length = opt.max_length # 64
if opt.adapt_lr is None and opt.lr: # opt.adapt_lr = None / opt.lr = 1e-4
opt.adapt_lr = opt.lr
print("{}-way-{}-shot Few-Shot NER".format(N, K))
print('task: {}'.format(opt.task))
print('mode: {}'.format(opt.mode))
print('prompt: {}'.format(opt.prompt))
print("support: {}".format(opt.support_num))
print("max_length: {}".format(max_length))
print("batch_size: {}".format(opt.test_bz if opt.only_test else opt.batch_size))
set_seed(opt.seed)
print('loading model and tokenizer...')
pretrain_ckpt = opt.pretrain_ckpt or 'bert-base-uncased'
config = BertConfig.from_pretrained(pretrain_ckpt)
tokenizer = BertTokenizer.from_pretrained(pretrain_ckpt)
opt.tokenizer = tokenizer
word_encoder = BERTWordEncoder.from_pretrained(pretrain_ckpt, config=config, args=opt)
加载数据集
if opt.task == 'cross-label-space':
opt.train = f'data/few-nerd/{opt.mode}/train.txt'
opt.dev = f'data/few-nerd/{opt.mode}/dev.txt'
opt.test = f'data/few-nerd/{opt.mode}/test.txt'
opt.train_word_map = opt.dev_word_map = opt.test_word_map = FEWNERD_WORD_MAP
print(f'loading train data: {opt.train}')
train_data_loader = get_loader(opt.train, tokenizer, word_map = opt.train_word_map,
N=trainN, K=1, Q=Q, batch_size=opt.batch_size, max_length=max_length, # K=1 for training
ignore_index=opt.ignore_index, args=opt, train=True)
print(f'loading eval data: {opt.dev}')
val_data_loader = get_loader(opt.dev, tokenizer, word_map = opt.dev_word_map,
N=N, K=K, Q=Q, batch_size=opt.test_bz, max_length=max_length,
ignore_index=opt.ignore_index, args=opt)
print(f'loading test data: {opt.test}')
test_data_loader = get_loader(opt.test, tokenizer, word_map = opt.test_word_map,
N=N, K=K, Q=Q, batch_size=opt.test_bz, max_length=max_length,
ignore_index=opt.ignore_index, args=opt)
3.get_loader
N=5 K=1 for training, Q=1 batch_size=16 ignore_index=-1 opt.train_word_map = opt.dev_word_map = opt.test_word_map = FEWNERD_WORD_MAP
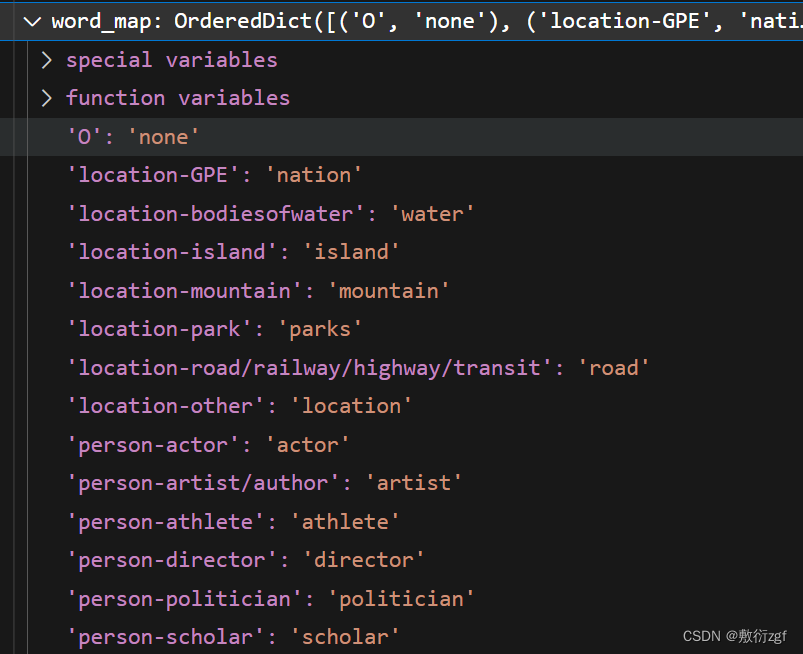
FEWNERD_WORD_MAP
先初始化定义一个OrderedDict,然后按照键值对插入,此时dict可以记录插入字典的顺序
from collections import OrderedDict
# # Few-NERD
FEWNERD_WORD_MAP = OrderedDict()
FEWNERD_WORD_MAP['O'] = 'none'
FEWNERD_WORD_MAP['location-GPE'] = 'nation'
FEWNERD_WORD_MAP['location-bodiesofwater'] = 'water'
FEWNERD_WORD_MAP['location-island'] = 'island'
FEWNERD_WORD_MAP['location-mountain'] = 'mountain'
FEWNERD_WORD_MAP['location-park'] = 'parks'
FEWNERD_WORD_MAP['location-road/railway/highway/transit'] = 'road'
FEWNERD_WORD_MAP['location-other'] = 'location'
FEWNERD_WORD_MAP['person-actor'] = 'actor'
FEWNERD_WORD_MAP['person-artist/author'] = 'artist'
FEWNERD_WORD_MAP['person-athlete'] = 'athlete'
FEWNERD_WORD_MAP['person-director'] = 'director'
FEWNERD_WORD_MAP['person-politician'] = 'politician'
FEWNERD_WORD_MAP['person-scholar'] = 'scholar'
FEWNERD_WORD_MAP['person-soldier'] = 'soldier'
FEWNERD_WORD_MAP['person-other'] = 'person'
FEWNERD_WORD_MAP['organization-company'] = 'company'
FEWNERD_WORD_MAP['organization-education'] = 'education'
FEWNERD_WORD_MAP['organization-government/governmentagency'] = 'government'
FEWNERD_WORD_MAP['organization-media/newspaper'] = 'media'
FEWNERD_WORD_MAP['organization-politicalparty'] = 'parties'
FEWNERD_WORD_MAP['organization-religion'] = 'religion'
FEWNERD_WORD_MAP['organization-showorganization'] = 'show'
FEWNERD_WORD_MAP['organization-sportsleague'] = 'league'
FEWNERD_WORD_MAP['organization-sportsteam'] = 'team'
FEWNERD_WORD_MAP['organization-other'] = 'organization'
FEWNERD_WORD_MAP['building-airport'] = 'airport'
FEWNERD_WORD_MAP['building-hospital'] = 'hospital'
FEWNERD_WORD_MAP['building-hotel'] = 'hotel'
FEWNERD_WORD_MAP['building-library'] = 'library'
FEWNERD_WORD_MAP['building-restaurant'] = 'restaurant'
FEWNERD_WORD_MAP['building-sportsfacility'] = 'facility'
FEWNERD_WORD_MAP['building-theater'] = 'theater'
FEWNERD_WORD_MAP['building-other'] = 'building'
FEWNERD_WORD_MAP['art-broadcastprogram'] = 'broadcast'
FEWNERD_WORD_MAP['art-film'] = 'film'
FEWNERD_WORD_MAP['art-music'] = 'music'
FEWNERD_WORD_MAP['art-painting'] = 'painting'
FEWNERD_WORD_MAP['art-writtenart'] = 'writing'
FEWNERD_WORD_MAP['art-other'] = 'art'
FEWNERD_WORD_MAP['product-airplane'] = 'airplane'
FEWNERD_WORD_MAP['product-car'] = 'car'
FEWNERD_WORD_MAP['product-food'] = 'food'
FEWNERD_WORD_MAP['product-game'] = 'game'
FEWNERD_WORD_MAP['product-ship'] = 'ship'
FEWNERD_WORD_MAP['product-software'] = 'software'
FEWNERD_WORD_MAP['product-train'] = 'train'
FEWNERD_WORD_MAP['product-weapon'] = 'weapon'
FEWNERD_WORD_MAP['product-other'] = 'product'
FEWNERD_WORD_MAP['event-attack/battle/war/militaryconflict'] = 'war'
FEWNERD_WORD_MAP['event-disaster'] = 'disaster'
FEWNERD_WORD_MAP['event-election'] = 'election'
FEWNERD_WORD_MAP['event-protest'] = 'protest'
FEWNERD_WORD_MAP['event-sportsevent'] = 'sport'
FEWNERD_WORD_MAP['event-other'] = 'event'
FEWNERD_WORD_MAP['other-astronomything'] = 'astronomy'
FEWNERD_WORD_MAP['other-award'] = 'award'
FEWNERD_WORD_MAP['other-biologything'] = 'biology'
FEWNERD_WORD_MAP['other-chemicalthing'] = 'chemistry'
FEWNERD_WORD_MAP['other-currency'] = 'currency'
FEWNERD_WORD_MAP['other-disease'] = 'disease'
FEWNERD_WORD_MAP['other-educationaldegree'] = 'degree'
FEWNERD_WORD_MAP['other-god'] = 'god'
FEWNERD_WORD_MAP['other-language'] = 'language'
FEWNERD_WORD_MAP['other-law'] = 'law'
FEWNERD_WORD_MAP['other-livingthing'] = 'organism'
FEWNERD_WORD_MAP['other-medical'] = 'medical'
def get_loader(filepath, tokenizer, N, K, Q, batch_size, max_length, word_map,
ignore_index=-1, args=None, num_workers=4, support_file_path=None, train=False):
if train:
dataset = SingleDatasetwithEpisodeSample(N, 1, filepath, tokenizer, max_length,
ignore_label_id=ignore_index,
args=args, word_map=word_map)
return data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=num_workers,
collate_fn=single_collate_fn)
else:
if args.task in ['cross-label-space']:
dataset = PairDatasetwithEpisodeSample(N, K, Q, filepath, tokenizer, max_length,
ignore_label_id=ignore_index,
args=args, word_map=word_map)
return data.DataLoader(dataset=dataset,
batch_size=1,
shuffle=True,
pin_memory=True,
num_workers=num_workers,
collate_fn=pair_collate_fn)
elif args.task in ['domain-transfer']:
dataset = PairDatasetwithFixedSupport(N, filepath, support_file_path, tokenizer, max_length,
ignore_label_id=ignore_index,
args=args, word_map=word_map)
return data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=num_workers,
collate_fn=pair_collate_fn)
elif args.task in ['in-label-space']:
dataset = SingleDatasetwithRamdonSample(filepath, tokenizer, max_length,
ignore_label_id=ignore_index,
args=args, word_map=word_map)
return data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=num_workers,
collate_fn=single_collate_fn)
4.SingleDatasetwithEpisodeSample
继承自 PairDatasetwithEpisodeSample 类,该类用于处理单数据集的示例采样。
class SingleDatasetwithEpisodeSample(PairDatasetwithEpisodeSample):
def __init__(self, N, K, filepath, tokenizer, max_length, word_map, ignore_label_id=-1, args=None):
if not os.path.exists(filepath):
print("[ERROR] Data file does not exist!")
assert(0)
self.class2sampleid = {}
self.word_map = word_map
self.word2class = OrderedDict()
for key, value in self.word_map.items():
self.word2class[value] = key
self.BOS = '[CLS]'
self.EOS = '[SEP]'
self.max_length = max_length
self.ignore_label_id = ignore_label_id
self.samples, self.classes = self.__load_data_from_file__(filepath)
self.sampler = SingleFewshotSampler(N, K, self.samples, classes=self.classes)
self.prompt = args.prompt
self.tokenizer = tokenizer
self.pseudo_token = args.pseudo_token
self.tokenizer.add_special_tokens({'additional_special_tokens': [args.pseudo_token]})
def __getitem__(self, index):
target_classes, support_idx = self.sampler.__next__()
# add 'none' and make sure 'none' is labeled 0
distinct_tags = [self.word_map['O']] + target_classes
prompt_tags = distinct_tags.copy()
random.shuffle(prompt_tags)
self.tag2label = {tag:idx for idx, tag in enumerate(distinct_tags)}
self.label2tag = {idx:self.word2class[tag] for idx, tag in enumerate(distinct_tags)}
support_set = self.__populate__(support_idx, distinct_tags, prompt_tags, savelabeldic=True)
return support_set
def __len__(self):
return 1000000
- init方法:初始化类的实例。参数包括 N、K、filepath、tokenizer、max_length、word_map、ignore_label_id 和 args。在初始化过程中,首先检查给定的文件路径是否存在,然后设置一些实例变量,如 word_map、BOS、EOS、max_length、ignore_label_id 等。随后从文件中加载数据,并使用 SingleFewshotSampler 对象创建一个采样器。最后设置一些额外变量,如 prompt、tokenizer、pseudo_token 等;
- getitem方法:根据给定的索引,获取采样数据。通过采样器获取目标类别和支持集索引,然后创建不同标签序列和随机标签序列。接着根据标签生成一些支持集数据,并返回支持集数据。
load_data_from_file
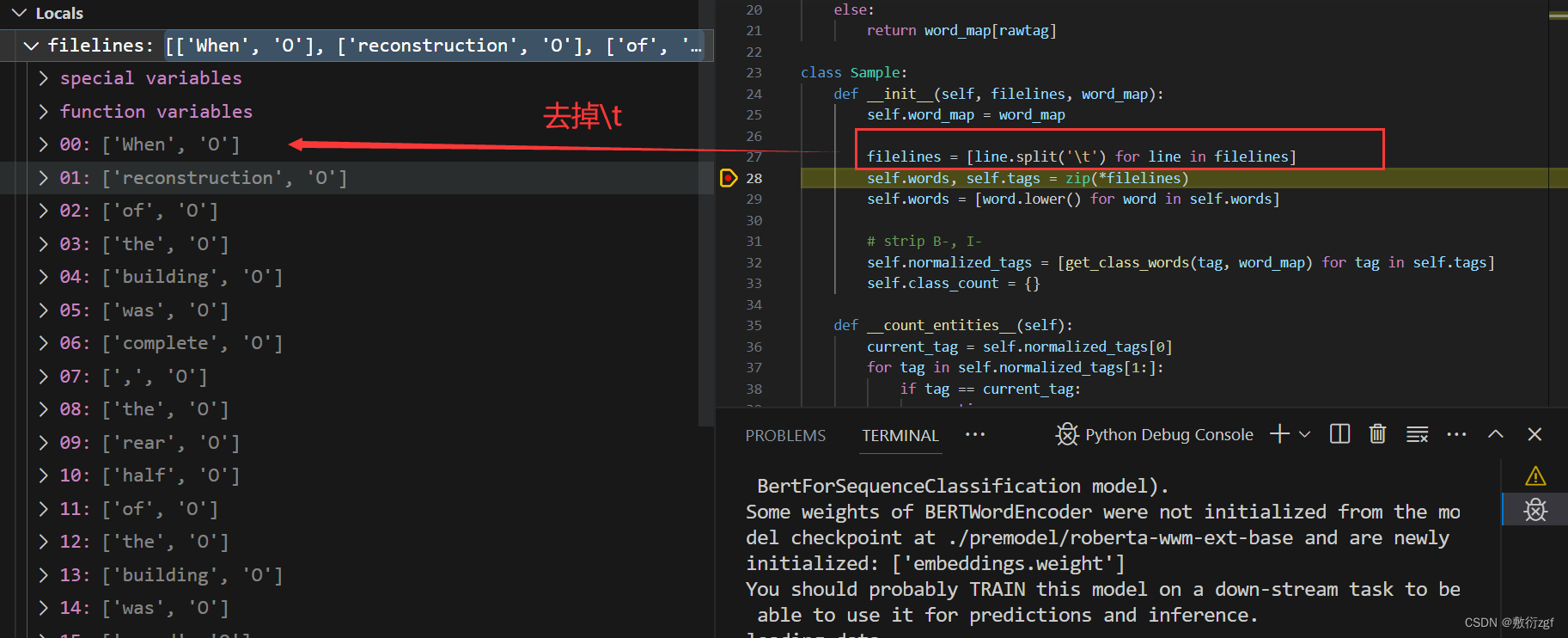
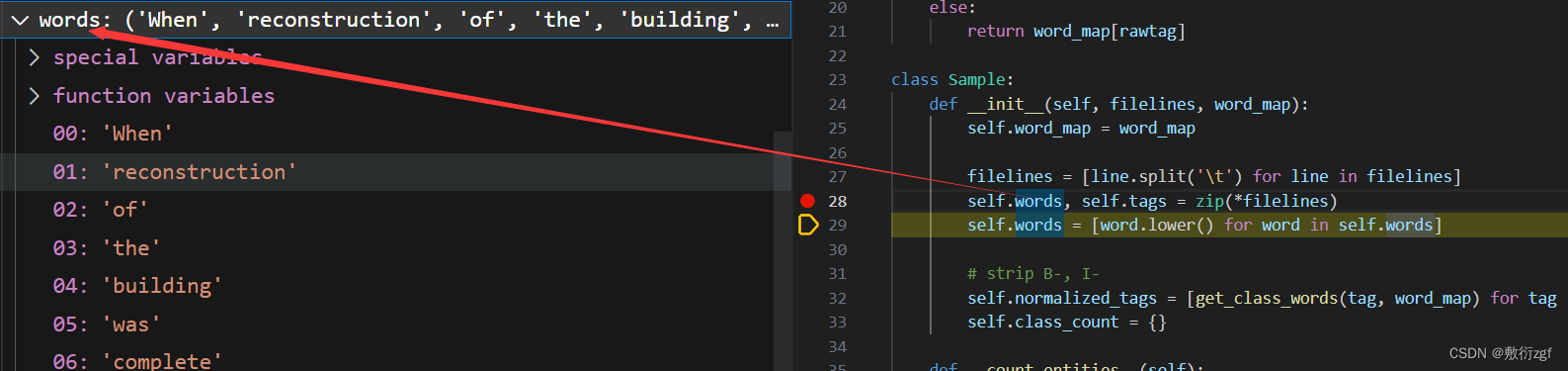
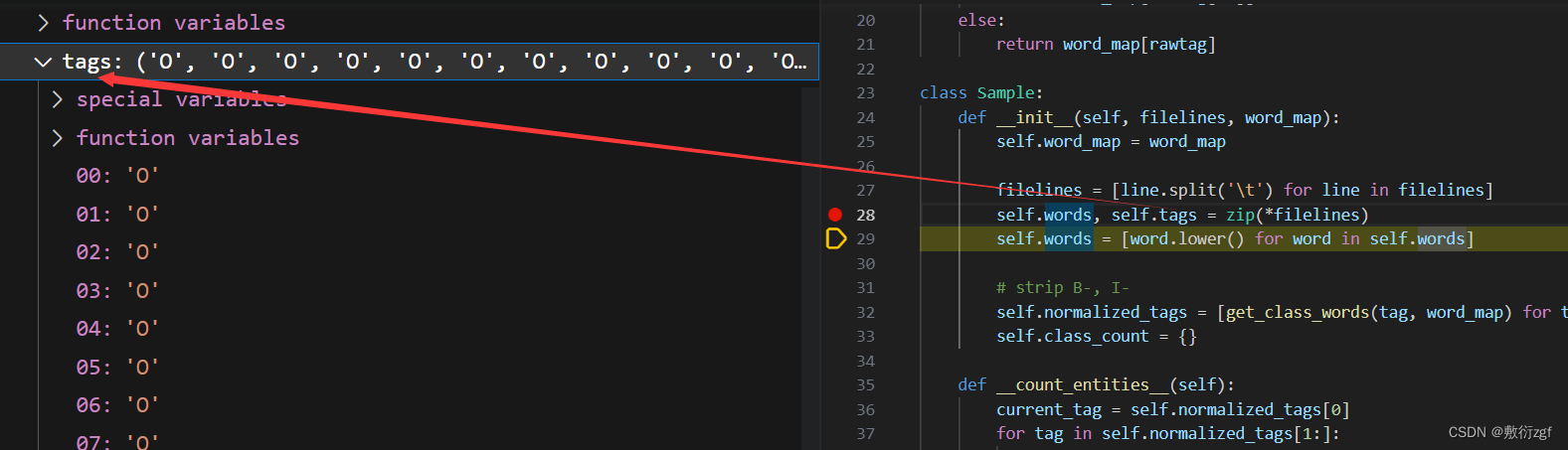
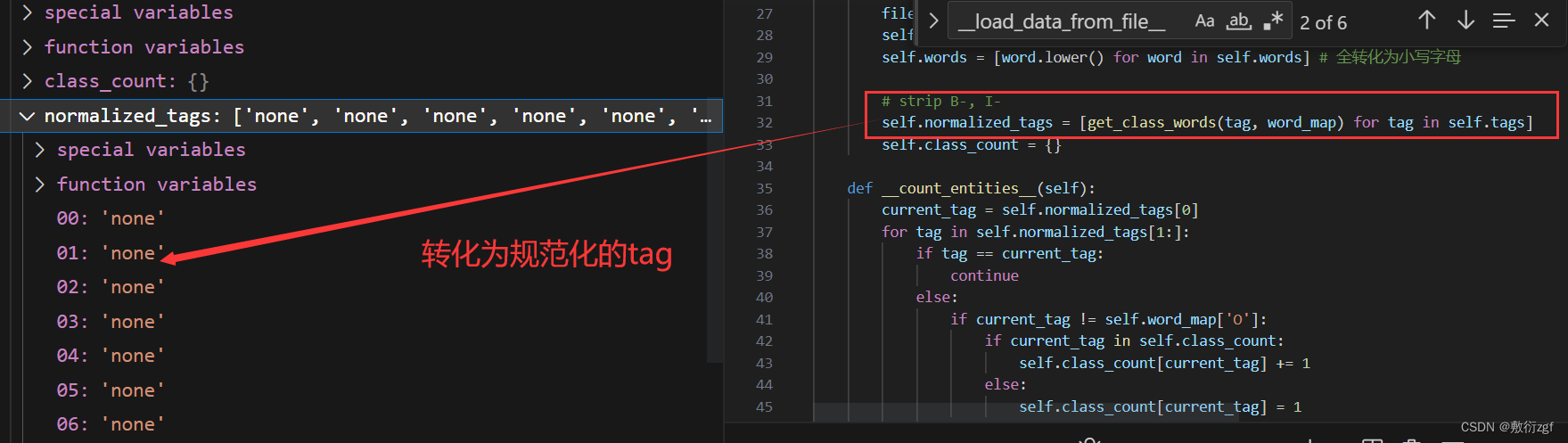
def __load_data_from_file__(self, filepath):
samples = [] # 存储样本
classes = [] # 存储类别
with open(filepath, 'r', encoding='utf-8')as f:
lines = f.readlines()
samplelines = []
index = 0
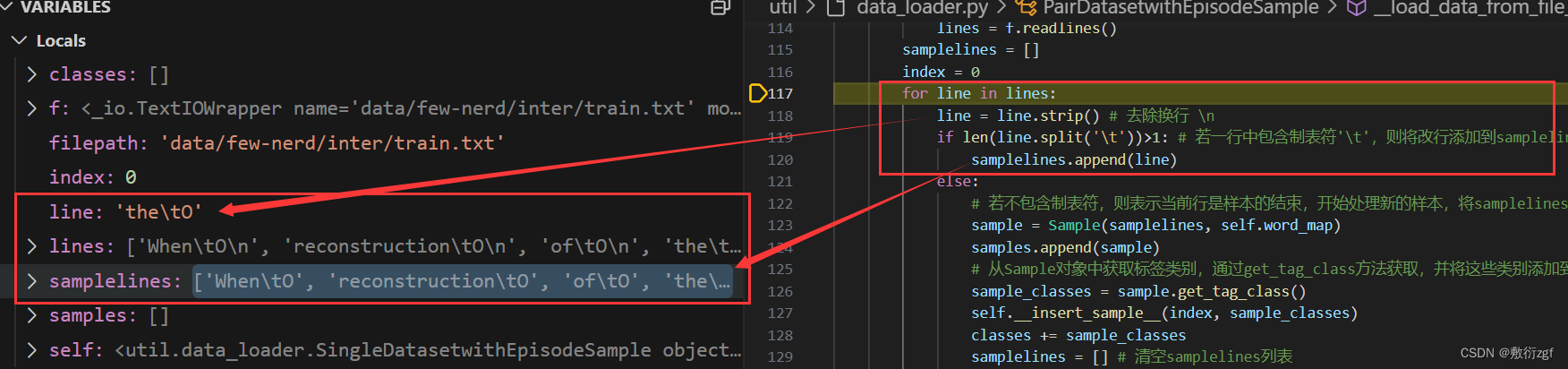
for line in lines:
line = line.strip()
if len(line.split('\t'))>1: # 若一行中包含制表符'\t',则将改行添加到samplelines列表中,表示这一行是样本数据的一部分
samplelines.append(line)
else:
# 若不包含制表符,则表示当前行是样本的结束,开始处理新的样本,将samplelines列表中的数据用于创建一个Sample对象
sample = Sample(samplelines, self.word_map)
samples.append(sample)
# 从Sample对象中获取标签类别,通过get_tag_class方法获取,并将这些类别添加到classes列表中
sample_classes = sample.get_tag_class()
self.__insert_sample__(index, sample_classes)
classes += sample_classes
samplelines = [] # 清空samplelines列表
index += 1 # 将index加1
classes = list(set(classes)) # 遍历完成后将classes列表转换为集合,去除重复的类别
return samples, classes
SingleFewshotSampler
class SingleFewshotSampler(PairFewshotSampler):
def __init__(self, N, K, samples, classes=None, random_state=0):
'''
N: int, how many types in each set
K: int, how many instances for each type in data set
samples: List[Sample], Sample class must have `get_class_count` attribute
classes[Optional]: List[any], all unique classes in samples. If not given, the classes will be got from samples.get_class_count()
random_state[Optional]: int, the random seed
'''
self.K = K
self.N = N
self.samples = samples
self.__check__() # check if samples have correct types
if classes:
self.classes = classes
else:
self.classes = self.__get_all_classes__()
random.seed(random_state)
def __next__(self):
'''
randomly sample one episode set
'''
episode_class = {'k':self.K}
episode_idx = []
target_classes = random.sample(self.classes, self.N)
candidates = self.__get_candidates__(target_classes)
while not candidates:
target_classes = random.sample(self.classes, self.N)
candidates = self.__get_candidates__(target_classes)
# greedy search for episode set
while not self.__finish__(episode_class):
index = random.choice(candidates)
if index not in episode_idx:
if self.__valid_sample__(self.samples[index], episode_class, target_classes):
self.__additem__(index, episode_class)
episode_idx.append(index)
return target_classes, episode_idx
这段代码定义了一个名为 SingleFewshotSampler 的类,它继承自 PairFewshotSampler。SingleFewshotSampler 的目的是从一个包含多种类别(types)的数据集中采样少数样本(few-shot),以用于训练或测试。
- 初始化函数 init: N: 每个集合中类型的数量。 K: 每个类型在数据集中的样本数量。 samples: 一个样本列表,每个样本必须有一个 get_class_count 属性。classes: 样本中所有独特类别的列表。如果没有提供,则从样本的 get_class_count() 中获取。
- random_state: 随机种子,用于保证可重复性。
- check 方法: 检查 samples 是否具有正确的类型。
- get_all_classes 方法: 如果没有提供 classes,则通过调用每个样本的 get_class_count 方法来获取所有独特的类别。
- next 方法: 随机采样一个样本集(episode set)。
episode_class: 存储采样的类别的字典。
episode_idx: 存储被采样的样本索引的列表。
target_classes: 从所有类别中随机选取的类别列表,数量为 N。
candidates: 根据 target_classes 获取的可选样本索引列表。
如果 candidates 为空,会重新随机选择类别,直到找到有候选样本的类别。使用贪心搜索(greedy search)构建一个样本集,直到满足某个条件(由 finish 方法确定)。
finish 方法: 判断是否已经完成一个样本集的构建。具体的完成条件在 finish 方法中定义,但代码中这个方法没有给出。
additem 方法: 向 episode_class 中添加一个样本。
get_candidates 方法: 根据目标类别 target_classes 获取候选样本索引列表。
valid_sample 方法: 判断给定的样本是否有效,即是否满足采样器对于样本的要求。
整体来看,这个类是为了实现一种特定类型的少样本学习(few-shot learning)策略,其中每个类别只随机选择少数样本进行训练。代码中的某些方法(如 finish 和 valid_sample)没有给出具体实现,所以无法完全确定这个采样器的所有行为。
5.加载模型类CopNER
model = COPNER(word_encoder, opt, opt.train_word_map if not opt.only_test else opt.test_word_map)
class COPNER(FewShotNERModel):
def __init__(self, word_encoder, args, word_map):
FewShotNERModel.__init__(self, word_encoder, ignore_index=args.ignore_index)
self.tokenizer = args.tokenizer
self.tau = args.tau
# 初始化损失函数loss_fct为CrossEntropyLoss,用于分类问题,并设置忽略索引
self.loss_fct = CrossEntropyLoss(ignore_index=args.ignore_index)
self.method = 'euclidean'
self.class2word = word_map
self.word2class = OrderedDict()
for key, value in self.class2word.items():
self.word2class[value] = key
def __dist__(self, x, y, dim, normalize=False):
if normalize: # 对向量进行归一化处理
x = F.normalize(x, dim=-1)
y = F.normalize(y, dim=-1)
if self.method == 'dot': # 点积
sim = (x * y).sum(dim)
elif self.method == 'euclidean': # 欧氏距离
sim = -(torch.pow(x - y, 2)).sum(dim)
elif self.method == 'cosine': # 余弦相似度
sim = F.cosine_similarity(x, y, dim=dim)
return sim / self.tau
def get_contrastive_logits(self, hidden_states, inputs, valid_mask, target_classes): # 获取对比损失
class_indexs = [self.tokenizer.get_vocab()[tclass] for tclass in target_classes] # 获取目标类别的索引列表class_indexs
class_rep = []
for iclass in class_indexs:
class_rep.append(torch.mean(hidden_states[inputs.eq(iclass), :].view(-1, hidden_states.size(-1)), 0))
class_rep = torch.stack(class_rep).unsqueeze(0) # 计算每个类别的代表性向量class_rep
token_rep = hidden_states[valid_mask != self.tokenizer.pad_token_id, :].view(-1, hidden_states.size(-1)).unsqueeze(1)
logits = self.__dist__(class_rep, token_rep, -1)
return logits.view(-1, len(target_classes))
def forward(self,
input_ids,
labels,
valid_masks,
target_classes,
sentence_num,
):
# 验证输入数据的尺寸是否一致
assert input_ids.size(0) == labels.size(0) == valid_masks.size(0), \
print('[ERROR] inputs and labels must have same batch size.')
assert len(sentence_num) == len(target_classes)
# 通过词编码器获得隐藏状态hidden_states
hidden_states = self.word_encoder(input_ids) # logits, (encoder_hs, decoder_hs)
loss = None
logits = []
current_num = 0
# 对于每个句子,计算对比损失,若处于训练状态,累加损失
for i, num in enumerate(sentence_num):
current_hs = hidden_states[current_num: current_num+num]
current_input_ids = input_ids[current_num: current_num+num]
current_labels = labels[current_num: current_num+num]
current_valid_masks = valid_masks[current_num: current_num+num]
current_target_classes = target_classes[i]
current_num += num
contrastive_logits = self.get_contrastive_logits(current_hs,
current_input_ids,
current_valid_masks,
current_target_classes)
current_logits = F.softmax(contrastive_logits, -1)
if self.training:
contrastive_loss = self.loss_fct(contrastive_logits, current_labels[current_valid_masks != self.tokenizer.pad_token_id].view(-1))
loss = contrastive_loss if loss is None else loss + contrastive_loss
current_logits = current_logits.view(-1, current_logits.size(-1))
logits.append(current_logits)
# 计算每个句子的logits,并将其堆叠起来
logits = torch.cat(logits, 0)
_, preds = torch.max(logits, 1) # 预测结果
# 返回平均损失
if loss:
loss /= len(sentence_num)
return logits, preds, loss
6.实现少样本命名实体识别(NER)的框架
framework = FewShotNERFramework(opt, train_data_loader, val_data_loader, test_data_loader,
train_fname=opt.train if opt.struct else None,
viterbi=True if opt.struct else False)
FewShotNERFramework
class FewShotNERFramework:
def __init__(self, args, train_data_loader, val_data_loader, test_data_loader, viterbi=False, train_fname=None):
'''
train_data_loader: DataLoader for training.
val_data_loader: DataLoader for validating.
test_data_loader: DataLoader for testing.
viterbi: Whether to use Viterbi decoding.
train_fname: Path of the data file to get abstract transitions.
'''
self.args = args
self.train_data_loader = train_data_loader
self.val_data_loader = val_data_loader
self.test_data_loader = test_data_loader
self.viterbi = viterbi
if viterbi: # 是否使用维特比解码器来进行序列标注任务的解码
abstract_transitions = get_abstract_transitions(train_fname, args)
self.viterbi_decoder = ViterbiDecoder(self.args.N+2, abstract_transitions, tau=args.struct_tau)
get_abstract_transitions
def get_abstract_transitions(train_fname, args):
"""
Compute abstract transitions on the training dataset for StructShot
"""
samples = SingleDatasetwithRamdonSample(train_fname, None, None, word_map=args.train_word_map, args=args).samples
tag_lists = [sample.tags for sample in samples]
s_o, s_i = 0., 0.
o_o, o_i = 0., 0.
i_o, i_i, x_y = 0., 0., 0.
for tags in tag_lists:
if tags[0] == 'O': s_o += 1
else: s_i += 1
for i in range(len(tags)-1):
p, n = tags[i], tags[i+1]
if p == 'O':
if n == 'O': o_o += 1
else: o_i += 1
else:
if n == 'O':
i_o += 1
elif p != n:
x_y += 1
else:
i_i += 1
trans = []
trans.append(s_o / (s_o + s_i))
trans.append(s_i / (s_o + s_i))
trans.append(o_o / (o_o + o_i))
trans.append(o_i / (o_o + o_i))
trans.append(i_o / (i_o + i_i + x_y))
trans.append(i_i / (i_o + i_i + x_y))
trans.append(x_y / (i_o + i_i + x_y))
return trans
- 首先,函数根据数据加载方式(小样本数据或完整数据集)获取样本列表 samples;
- 然后,根据样本列表生成标签列表 tag_lists。对于小样本数据加载方式,直接从样本中提取支持集和查询集的标签。对于完整数据集加载方式,遍历所有样本,从中提取每个样本的标签;
- 接着,函数初始化并更新用于计算抽象转移概率的统计变量。具体地,对于每个标签序列:统计标签序列起始为 O 和 I 的次数;统计标签序列从 O 到 O 和从 O 到 I 的次数;统计标签序列从 I 到 O、从 I 到 I 和标签序列中不同标签相邻的次数;
- 最后,函数计算并返回标签序列的抽象转移概率列表 trans。其中,trans 列表中的每个元素表示一个抽象转移概率。
get_emmissions将模型输出的logits(即未归一化的得分)根据输入的标签列表进行分割,形成与标签对应的 emissions(发射概率)。
def __get_emmissions__(self, logits, tags_list):
# split [num_of_query_tokens, num_class] into [[num_of_token_in_sent, num_class], ...]
emmissions = []
current_idx = 0
for tags in tags_list:
emmissions.append(logits[current_idx:current_idx+len(tags)])
current_idx += len(tags)
assert current_idx == logits.size()[0]
return emmissions
viterbi_decode
def viterbi_decode(self, logits, query_tags):
emissions_list = self.__get_emmissions__(logits, query_tags)
pred = []
for i in range(len(query_tags)):
sent_scores = emissions_list[i].cpu()
sent_len, n_label = sent_scores.shape
sent_probs = F.softmax(sent_scores, dim=1)
start_probs = torch.zeros(sent_len) + 1e-6
sent_probs = torch.cat((start_probs.view(sent_len, 1), sent_probs), 1)
feats = self.viterbi_decoder.forward(torch.log(sent_probs).view(1, sent_len, n_label+1))
vit_labels = self.viterbi_decoder.viterbi(feats)
vit_labels = vit_labels.view(sent_len)
vit_labels = vit_labels.detach().cpu().numpy().tolist()
for label in vit_labels:
pred.append(label-1)
return torch.tensor(pred).cuda()
使用维特比解码器来对序列标签进行解码。首先,它将 logits 分割成与查询标签对应的 emissions。然后,对于每个句子,计算发射概率,并且结合转移概率使用维特比算法找出最有可能的标签序列。最后,将解码得到的标签序列转换为张量并返回。
7.调用训练方法
framework.train(model, prefix,
load_ckpt=opt.load_ckpt,
save_ckpt=ckpt,
val_step=opt.val_step,
train_iter=opt.train_iter,
warmup_step=int(opt.train_iter * 0.05),
val_iter=opt.val_iter,
learning_rate=opt.lr,
use_sgd_for_lm=opt.use_sgd_for_lm)
def train(self,
model,
model_name,
learning_rate=1e-4,
train_iter=30000,
val_iter=1000,
val_step=2000,
load_ckpt=None,
save_ckpt=None,
warmup_step=300,
grad_iter=1,
use_sgd_for_lm=False):
'''
model: a FewShotREModel instance
model_name: Name of the model
learning_rate: Initial learning rate
train_iter: Num of iterations of training
val_iter: Num of iterations of validating
val_step: Validate every val_step steps
load_ckpt: Path of the checkpoint to load
save_ckpt: Path of the checkpoint to save
warmup_step: Num of warmup steps
grad_iter: Accumulate gradients for grad_iter steps
use_sgd_for_lm: Whether to use SGD for the language model
'''
# Init optimizer
print('Use bert optim!')
parameters_to_optimize = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
parameters_to_optimize = [
{'params': [p for n, p in parameters_to_optimize
if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in parameters_to_optimize
if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
if use_sgd_for_lm:
optimizer = torch.optim.SGD(parameters_to_optimize, lr=learning_rate)
else:
optimizer = AdamW(parameters_to_optimize, lr=learning_rate)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_step, num_training_steps=train_iter)
# load model
if load_ckpt:
state_dict = self.__load_model__(load_ckpt)['state_dict']
own_state = model.state_dict()
for name, param in state_dict.items():
if name not in own_state:
print('ignore {}'.format(name))
continue
print('load {} from {}'.format(name, load_ckpt))
own_state[name].copy_(param)
model.train()
# Training
iter_loss = 0.0
best_precision = 0.0
best_recall = 0.0
best_f1 = 0.0
iter_sample = 0
pred_cnt = 1e-9
label_cnt = 1e-9
correct_cnt = 0
last_step = 0
print("Start training...")
with tqdm(self.train_data_loader, total=train_iter, disable=False, desc="Training") as tbar:
for it, batch in enumerate(tbar):
if torch.cuda.is_available():
for k in batch:
if k != 'target_classes' and \
k != 'sentence_num' and \
k != 'labels' and \
k != 'label2tag':
batch[k] = batch[k].cuda()
label = torch.cat(batch['labels'], 0)
label = label.cuda()
logits, pred, loss = model(batch['inputs'],
batch['batch_labels'],
batch['valid_masks'],
batch['target_classes'],
batch['sentence_num'])
loss.backward()
if it % grad_iter == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# Calculate metrics
tmp_pred_cnt, tmp_label_cnt, correct = model.metrics_by_entity(pred, label)
iter_loss += self.item(loss.data)
pred_cnt += tmp_pred_cnt
label_cnt += tmp_label_cnt
correct_cnt += correct
iter_sample += 1
precision = correct_cnt / pred_cnt
recall = correct_cnt / label_cnt
f1 = 2 * precision * recall / (precision + recall + 1e-9) # 1e-9 for error'float division by zero'
tbar.set_postfix_str("loss: {:2.6f} | F1: {:3.4f}, P: {:3.4f}, R: {:3.4f}, Correct:{}"\
.format(self.item(loss.data), f1, precision, recall, correct_cnt))
if (it + 1) % val_step == 0:
precision, recall, f1, _, _, _, _ = self.eval(model, val_iter, word_map=self.args.dev_word_map)
model.train()
if f1 > best_f1:
# print(f'Best checkpoint! Saving to: {save_ckpt}\n')
# torch.save({'state_dict': model.state_dict()}, save_ckpt)
best_f1 = f1
best_precision = precision
best_recall = recall
last_step = it
else:
if it - last_step >= self.args.early_stopping:
print('\nEarly Stop by {} steps, best f1: {:.4f}%'.format(self.args.early_stopping, best_f1))
raise KeyboardInterrupt
if (it + 1) % 100 == 0:
iter_loss = 0.
iter_sample = 0.
pred_cnt = 1e-9
label_cnt = 1e-9
correct_cnt = 0
if (it + 1) >= train_iter:
break
print("\n####################\n")
print("Finish training {}, best f1: {:.4f}%".format(model_name, best_f1))
- 初始化变量: iter_loss 用于累计损失,best_precision、best_recall 和 best_f1 用于记录最佳精确度、召回率和F1分数。iter_sample、pred_cnt、label_cnt 和 correct_cnt 用于计算每个迭代步骤的样本数、预测数和正确预测数;
- 训练循环: 使用 tqdm 库来显示训练进度条,它提供了一个动态更新的进度条,显示当前迭代的进度和总迭代次数;
- 数据处理: 如果使用了GPU,则将除了标签和其他特定字段之外的所有批量数据移动到GPU上;
- 前向传播: model 通过输入数据 batch[‘inputs’] 产生 logits,然后通过softmax或其他激活函数得到 pred(预测)。同时计算损失 loss;
- 反向传播和优化: 通过调用 loss.backward() 执行反向传播,然后如果迭代次数 it % grad_iter 为0,则执行一步优化器更新 optimizer.step(),并更新学习率 scheduler.step()。之后,清空梯度 optimizer.zero_grad();
- 计算指标: 使用 model.metrics_by_entity 方法计算每个实体的精确度、召回率和F1分数;
- 更新进度条: 使用 tbar.set_postfix_str 更新进度条,显示当前的损失和F1分数等信息;
- 验证循环: 如果当前迭代次数模 val_step 为0,则进行一次验证,计算验证集上的精确度、召回率和F1分数;
- 保存最佳模型: 如果验证F1分数比当前最佳F1分数更高,则保存当前模型状态到 save_ckpt 指定的路径;
- 早停机制: 如果连续 self.args.early_stopping 次迭代验证F1分数没有提升,则提前停止训练;
- 重置变量: 每100次迭代重置损失和样本计数器;
- 训练结束: 当达到预定的训练迭代次数 train_iter 时,训练结束。打印最终结果: 打印模型名称和训练结束时的最佳F1分数。
三、模型训练







![【sgCreateTableData】自定义小工具:敏捷开发→自动化生成表格数据数组[基于el-table]](https://img-blog.csdnimg.cn/direct/6aba114194844c62b8bf03cba32ba571.gif)