了解了基本的Linux文件文件系统的概念后,我们将更深入的了解一下Linux的其他方面的内容,那就是我们所使用的用户接口,也就是大家常听到的 Shell ,是一种Linux的命令接口,在 Linux 的世界中,默认使用的是 GNU 开发出来的 shell ,称为 BASH Shell,简单来说,我们之前使用的几个命令都是 bash 管理的,除此之外,bash还具备记录命令、文件或命令的补全功能、环境变量的使用等,下面我们会介绍bash的发展以及常用的特性.本章的内容,是一个呈上启一下的东西,在以后的主机维护中作用很大,务必掌握.
系统中的默认合法Shell
在Linux系统中,常用的shell可以在/etc/shells文件中查到.
● /bin/sh (已经被 /bin/bash 所取代)
● /bin/bash (就是 Linux 默认的 shell)
● /bin/ksh (Kornshell 由 AT&T Bell lab. 发展出来的,兼容于 bash)
● /bin/tcsh (整合 C Shell ,提供更多的功能)
● /bin/csh (已经被 /bin/tcsh 所取代)
● /bin/zsh (基于 ksh 发展出来的,功能更强大的 shell)
上面我们可以看到有很多Shell的程序,我们作为初学者,最应该掌握的就是Bash,因为他是系统的默认Shell,还有一些特殊的Shell这里没有列出,比如:/sbin/nologin这个无法登陆的Shell.
Bash-Shell的常用功能
既然 /bin/bash 是 Linux 默认的 shell 那么总是得了解一下这个Shell有哪些特性吧,bash 是 GNU 计划中重要的工具软件之一,目前也是 Linux 发行版的标准 shell ,bash 兼容于 sh ,下面我们看一下bash到底有哪些特点吧,好让我们以后的使用更加得心应手.
● 命令记忆功能(history)
在默认的Linux环境中,我认为Bash最赞的功能,就是它的命令记忆功能了,其默认的记忆功能,可达到记忆1000条命令,也就是说,你曾经执行过的命令1000条以内会被记录下来,超出部分会自动清除.
你或许会有个疑问,命令被记录到哪里了呢?其实我们的命令在退出终端是是记录在内存中的,当用户正式退出终端是会自动写入到,自己家目录,名字为.bash_history文件当中.虽然我们可以自己设置记录条数,但是建议设置条目小一些,因为一旦你的系统被黑客入侵,那么他可以通过翻阅你的命令执行找到一些核心数据.
● 命令与文件补全(TAB)
在使用Linux时,有时候我们会忘记一些命令的具体参数,此时我们可以通过命令补全功能,来实现补全.补全的按键是TAB.灵活运用命令补全功能,不但可以提高输入效率,还能减小误输入概率.实在是,棒棒哒!
● 命令别名(alias)
有时候我们需要给指定命令设置别名,比如说,一个命令过长,我们可以使用Bash提供的这一特性来将其简化一下.
● Bash程序脚本(Shell)
在Linux上面,Shell脚本发挥着及其强大的功能,我们的主机管理,日常维护,都离不开Shell脚本的支持.
● Shell通配符
除了以上功能外,BASH还支持很多简单的通配符,这对于我们的维护减小了很大的负担.
Bash-Shell常用命令
好了,看了这么多理论,是不是有点懵圈,没关系,我也懵了,不过接下来,我们来点干货,开始实战,看一下Bash常用的相关命令吧.前面的理论可以不看,会操作就行.
alias 设置别名
alias命令用来设置指令的别名,我们可以使用该命令可以将一些较长的命令进行简化,使用alias时,用户必须使用单引号’'将原来的命令引起来,防止特殊字符导致错误,alias命令的作用只局限于该次登入的操作,若要每次登入都能够使用这些命令别名,则可将相应的alias命令存放到bash的初始化文件 /etc/bashrc 中,如果是对指定用户生效则要写入用户家目录中的 ~/.bashrc 中.
这里我不得不罗嗦一下,关于不同类型命令的执行顺序,面试时可能会问到.
NO.1 用绝对路径或相对的方式执行命令
NO.2 别名命令
NO.3 bash 内置命令
NO.4 根据环境变量定义的目录查询找到的命令
[root@localhost ~]# alias --help
命令语法:[ alias [原命令]="新命令" ]
-p #打印已经设置的命令别名
[root@localhost ~]# unalias --help
命令语法:[ unalias [命令] ]
history 历史命令
history命令用于显示指定数目的指令命令,读取历史命令文件中的目录到历史命令缓冲区和将历史命令缓冲区中的目录写入命令文件,该命令单独使用时,仅显示历史命令,在命令行中,可以使用符号!执行指定序号的历史命令.例如:要执行第2个历史命令,则输入!2.
历史命令是被保存在内存中的,当退出或者登录shell时,会自动保存或读取.在内存中,历史命令仅能够存储1000条历史命令,该数量是由环境变量HISTSIZE进行控制.
[root@localhost ~]# history --help
命令语法:[ history [选项] ]
-c #清空当前历史命令
-a #将历史命令缓冲区中命令写入历史命令文件中
-r #将历史命令文件中的命令读入当前历史命令缓冲区
-w #将当前历史命令缓冲区命令写入历史命令文件中
"!n" #重复执行第n条历史命令
"!!" #重复执行上一条命令
"!字符" #重复执行最近一条以此字符开头的命令
ulimit 磁盘限制
ulimit命令用来限制系统用户对shell资源的访问,想象一个状况:我的 Linux 主机里面同时登陆了十个人,这十个人不知怎么搞的,同时开启了 100 个文件,每个文件的大小约 10MBytes,请问一下,我的 Linux 主机的内存要有多大才够,10*100*10 = 10000 MBytes = 10GBytes这样我们的Linux就完蛋了,为了要预防这个情况的发生,所以我们的 bash 是可以『限制用户的某些系统资源』的,包括可以开启的文件数量,可以使用的 CPU 时间,可以使用的内存总量等等.
[root@localhost ~]# ulimit --help
命令语法:[ ulimit [选项] ]
-c #清空当前历史命令
-H #严格限制,不能超过此限制
-S #宽限模式,可超过,超过后有警告
-a #列出所有系统限额信息
-f #此Shell可创建的最大容量,默认KB
-d #进程可用最大断裂内存(seqment)容量
-l #可用于锁定的内存(lock)量
-t #可使用最大CPU时间,(单位为秒)
-u #单一用户可使用最大进程数量
来看一下它的结果的解析吧.
[root@localhost ~]# ulimit -a
core file size (blocks, -c) 0 #core文件的最大值为100 blocks
data seg size (kbytes, -d) unlimited #进程的数据段可以任意大
scheduling priority (-e) 0
file size (blocks, -f) unlimited #文件可以任意大
pending signals (-i) 98304 #最多有98304个待处理的信号
max locked memory (kbytes, -l) 32 #一个任务锁住的物理内存的最大值为32KB
max memory size (kbytes, -m) unlimited #一个任务的常驻物理内存的最大值
open files (-n) 1024 #一个任务最多可以同时打开1024的文件
pipe size (512 bytes, -p) 8 #管道的最大空间为4096字节
POSIX message queues (bytes, -q) 819200 #POSIX的消息队列的最大值为819200字节
real-time priority (-r) 0
stack size (kbytes, -s) 10240 #进程的栈的最大值为10240字节
cpu time (seconds, -t) unlimited #进程使用的CPU时间
max user processes (-u) 98304 #当前用户同时打开的进程(包括线程)的最大个数为98304
virtual memory (kbytes, -v) unlimited #没有限制进程的最大地址空间
file locks (-x) unlimited #所能锁住的文件的最大个数没有限制
Bash-Shell操作环境
是否记得我们登陆主机的时候,屏幕上头会有一些说明文字,告知我们的 Linux 版本啊什么的,还有登陆的时候我们还可以给予用户一些信息或者欢迎文字,此外,我们习惯的环境变量、命令别名等等的,是否可以登陆就主动的帮我配置好,这些都是需要注意的,下面我们就来介绍一下吧.
关于Bash的登陆tty终端提示信息
其实我们的Bash也有登陆提示信息的,细心的你也会发现,当我们登陆Linux系统时,默认会提示,Linux的版本等相关信息,这些登陆tty的相关信息是在 /etc/issue 这个配置文件中保存的,我们可以看一下它的结构.
[root@localhost ~]# cat /etc/issue
\S
Kernel \r on an \m
上图可以看到,里面默认有三行,issue里面的内容,是可以使用反斜杠作为变量调用的,我们下面来具体看一下它所支持的的代码.
| 代码 | issue内的各代码的意义 |
|---|---|
| \d | 本地端时间的日期 |
| \l | 显示第几个终端机接口 |
| \m | 显示硬件等级 |
| \n | 显示主机网络名称 |
| \o | 显示domain name |
| \r | 操作系统版本 |
| \t | 显示本地端的时间 |
| \s | 显示操作系统名称 |
| \v | 显示操作系统版本 |
如果我们想定制自己的登陆界面的话,我们可以修改这个配置文件,制作出属于自己的登陆界面.此时你还需要注意的是,除了issue文件外,还有一个issue.net的配置文件,这个是提供给telnet的远程登陆程序用的,当用户用telnet方式登陆主机时,就会自动读取 /etc/issue.net 这个配置文件里的信息,并输出到屏幕上.
关于Bash通过SSH登陆的提示信息
如果,你想让通过SSH登陆的用户,登陆成功后取得一些信息的话,那么可以讲信息加入到 /etc/motd 这个文件里,当用户下次登陆时,就会默认显示里面的内容.
例如,我们写入警告信息,让每个登陆用户下次登陆自动显示.
[root@localhost ~]# cat /etc/motd
===============================================================
警告:您的操作已被记录
===============================================================
接下来我们通过 ssh 来模拟登陆一下,看一下效果.
[root@localhost ~]# ssh root@192.168.1.10
root@192.168.1.10 password:
Last failed login: Sat Nov 24 15:28:30 EST 2018 from 192.168.1.20 on ssh:notty
There was 1 failed login attempt since the last successful login.
Last login: Sat Nov 24 15:26:36 2018 from 192.168.1.20
================================================================
警告:您的操作已被记录
===============================================================
Bash的环境配置文件,与相关调用顺序
你是否会觉得奇怪,怎么我们什么动作都没有进行,但是一进入 bash 就取得一堆有用的变量了,这是因为系统有一些环境配置文件案的存在,让 bash 在启动时直接读取这些配置文件,以规划好 bash 的操作环境,而这些配置文件又可以分为全体系统的配置文件以及用户个人偏好配置文件.接下来,我们就来看看常用的配置文件以及调用顺序吧.
/etc/profile这是一个系统全局配置文件,每个用户登录取得Bash时一定会读取次配置文件,加载一些配置参数,当此配置文件执行的时候还会调用其他的配置文件,比如下面的这几个.
/etc/profile首先调用/etc/inputrc其实这个文件并没有被运行,/etc/profile 会主动的判断使用者有没有自定义输入的按键功能,如果没有的话,/etc/profile 就会决定配置『INPUTRC=/etc/inputrc』这个变量,此一文件内容为 bash 的热键啦、[tab]要不要有声音啦等等的数据.不建议修改这个文件
/etc/profile其次调用/etc/profile.d/.sh这个目录内有很多文件,只要在 /etc/profile.d/ 这个目录内且扩展名为 .sh 并且使用者能够具有读权限那么该文件就会被 /etc/profile调用,如果你需要帮所有使用者配置一些共享的命令别名时,可以在这个目录底下自行创建扩展名为 .sh 的文件,并将所需要的数据写入即可.
上面的说明,我们可以看出,其实只有 /etc/profile 被调用啦,但是 /etc/profile 还会调用出其他的配置文件,所以让我们的 bash 操作接口变的非常的友善啦.
~./bash_profilebash 在读完了整体环境配置的 /etc/profile 并借此调用其他配置文件后,接下来则是会读取使用者的个人配置文件.所读取的个人偏好配置文件其实主要有三个,依序分别是:
~/.bash_profile-->~/.bash_login-->~/.prifile
其实 bash 只会读取上面三个文件的其中一个,而读取的顺序则是依照上面的顺序,也就是说,如果 ~/.bash_profile 存在,那么其他两个文件不论有无存在,都不会被读取.如果 ~/.bash_profile 不存在才会去读取 ~/.bash_login,而前两者都不存在才会读取 ~/.profile 的意思.
~/.bash_history默认的情况下,我们的历史命令就记录在这里,而这个文件能够记录多少数据,则与 HISTFILESIZE 这个变量有关,每次登陆 bash 后,bash 会先读取这个文件,将所有的历史命令读入内存,因此当我们登陆 bash 后就可以查看以前使用过的命令啦.
~/.bash_logout当系统用户注销时,系统会读取此配置文件,你可以去读取一下这个文件的内容,默认的情况下注销时bash 只是帮我们清掉屏幕的信息而已.不过,你也可以将一些备份或者是其他你认为重要的工作写在这个文件中(例如清空缓存盘),那么当你离开 Linux 的时候,就可以解决一些烦人的事情.
具体的调用情况,下面一张图,搞定.
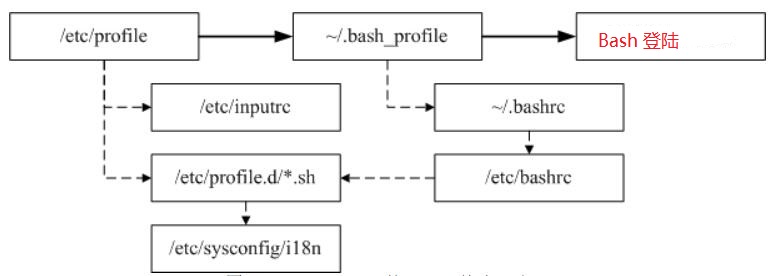
1.首先执行主配置下的:
/etc/profile
2.执行主配置目录下的:/etc/profile.d/*.sh
3.执行当前家目录下的:~/.bash_profile
4.执行当前家目录下的:~/.bashrc
5.最后执行主配置下的:/etc/bashrc
以上就是,系统加载环境变量的全部过程!
Shell快捷键与通配符
Bash 常用快捷键
Bashe这个默认shell支持一些,比较常用的快捷键,这些快捷键,对于命令行下的操作,大有好处,你应该好好掌握这些按键.
| 快捷键 | 作用 |
|---|---|
| ctrl+A | 将光标移动到命令开头 |
| ctrl+E | 将光标移动到命令结尾 |
| ctrl+C | 强制终止当前命令 |
| ctrl+L | 清屏 |
| ctrl+U | 删除或剪切光标之前的命令 |
| ctrl+K | 删除或剪切光标之后的命令 |
| ctrl+Y | 粘贴,ctrl+U或ctrl+K的内容 |
| ctrl+R | 在历史命令中搜索,按下后会出现搜索命令 |
| ctrl+D | 退出当前终端 |
| ctrl+Z | 暂停,并放入后台 |
| ctrl+S | 暂停屏幕输出 |
| ctrl+Q | 恢复屏幕输出 |
Bash 常用通配符
| 通 配 符 | 作 用 |
|---|---|
| ? | 匹配任意一个字符 |
| * | 匹配0个或多个任意字符,也就是可以匹配任何内容 |
| [] | 匹配括号内的任意一个字符 例如:[abc],在abc中任选一个 |
| [-] | 匹配一定范围的字符 例如:[a-z],在a-z之间的都可以被匹配 |
| [^] | 逻辑非,匹配不包括,括号内的字符 |
| 1 | 匹配开头是,括号内的字符 |
| [] | 匹配开头不是,括号内的字符 |
**实例1:**使用 ? 匹配任意一个字符,匹配开头任意一个字符,只能匹配一个字符.
[root@localhost ~]# ls
123 1233 12333 abbc abc abcc abccc admin lyshark multiuser rui sec wang
[root@localhost ~]# ls ?ang
wang
**实例2:**使用 * 匹配0个或多个任意字符,也就是可以匹配任何内容
[root@localhost ~]# ls
123 1233 12333 abbc abc abcc abccc admin lyshark multiuser rui sec wang
[root@localhost ~]# ls *
123 1233 12333 abbc abc abcc abccc admin lyshark multiuser rui sec wang
[root@localhost ~]# ls *ang
wang
**实例3:**使用 [-] 匹配范围,匹配一个范围
[root@localhost ~]# ls
123 1233 12333 abbc abc abcc abccc admin lyshark lyssark multiuser rui sec wang
[root@localhost ~]# ls lys[a-z]ark
lyshark lyssark
**实例4:**使用 ^[] 匹配开头是0-9的任意字符
[root@localhost ~]# ls
123 1233 12333 abbc abc abcc abccc admin lyshark lyssark multiuser rui sec wang
[root@localhost ~]# ls [0-9]*
123 1233 12333
**实例5:**使用 ^[^] 匹配开头不是0-9的任意字符
[root@localhost ~]# ls
123 1233 12333 abbc abc abcc abccc admin lyshark lyssark multiuser rui sec wang
[root@localhost ~]# ls [^0-9]*
abbc abc abcc abccc admin lyshark lyssark multiuser rui sec wang
bash 特殊通配符
| 符 号 | 作 用 |
|---|---|
| ‘’ | 单引号:在单引号中的内容,全部会脱意,它是脱意字符. |
| “” | 双引号:双引号内,拥有$调用变量,引用命令,和转义符的特殊含义. |
| `` | 反引号:反引号内会被当成命令解析,先执行 |
| $() | $加括号:同反引号作用相同,执行解析命令 |
| () | 小括号:用于命令执行,小括号中的命令会在子shell中执行 |
| {} | 中括号:用于命令执行,中括号中的命令会在当前shell中执行 |
| [] | 大括号:用于测试变量 |
| # | 警号:在shell脚本中,警号表示注释 |
| $ | $符号:用于调用变量值 |
| \ | 转义符:用于转义\之后的内容不被执行 |
单引号与双引号: 单引号当中的特殊字符被脱意了,而双引号也是脱意,但是$和\不会脱意
[root@localhost ~]# name=lyshark
[root@localhost ~]# echo '$name'
$name
[root@localhost ~]# echo "$name"
lyshark
[root@localhost ~]# echo "{{{ lyshark"
{{{ lyshark
单引号与反引号: 单引号和双引号会脱意,在双引号中的反引号会执行
[root@localhost ~]# echo 'date'
date
[root@localhost ~]# echo "date"
date
[root@localhost ~]# echo '`date`'
`date`
[root@localhost ~]# echo "`date`"
Sun Sep 23 22:56:34 EDT 2018
[root@localhost ~]# echo $(date)
Sun Sep 23 22:56:46 EDT 2018
**反引号与 ( ) ∗ ∗ 关于反引号 , 和 ()** 关于反引号,和 ()∗∗关于反引号,和()两种都是命令执行
[root@localhost /]# echo ls
ls
[root@localhost /]# echo `ls`
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
[root@localhost /]# echo $(ls)
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
关于小括号,中括号,和大括号的说明
● ()执行一串命令时,需要重新开一个子shell进行执行
● {}执行一串命令时,是在当前shell执行
● ()和{}都是把一串的命令放在括号里面,并且命令之间用;号隔开
● ()最后一个命令可以不用分号
● {}最后一个命令要用分号
● {}的第一个命令和左括号之间必须要有一个空格
● ()里的各命令不必和括号有空格
小括号: ()执行命令时,新开一个子shell执行
[root@localhost ~]# name=lyshark
[root@localhost ~]# ( name=bash;echo $name )
bash
[root@localhost ~]# echo $name
lyshark
中括号:{}执行命令时,会在当前shell中执行
[root@localhost ~]# name=lyshark
[root@localhost ~]# { name=bash;echo $name; }
bash
[root@localhost ~]# echo $name
bash
[root@localhost ~]#
Shell的数据流重定向
|设备|设备文件名 | 文件描述符 | 类型 |
|:---------|:----------|:---------|
| 键盘 | /dev/stdin | 0 | 标准输入 |
| 显示器 | /dev/stdout | 1 | 标准正确输出 |
| 显示器 | /dev/stderr | 2 | 标准错误输出 |
| 垃圾桶 | /dev/null | 3 | 垃圾桶 |
| 类型 | 符号 | 作用 |
|---|---|---|
| 标准输出重定向 | 命令 > 文件 | 以覆盖的方式,把命令的正确输出输出到指定文件或设备中 |
| 命令 >> 文件 | 以追加的方式,把命令的正确输出输出到指定的文件或设备当中 | |
| 标准错误输出重定向 | 错误命令 2 > 文件 | 以覆盖方式,把命令的错误输出输出到指定的文件或设备中 |
| 错误命令 2>> 文件 | 以追加的方式,把命令的错误输出输出到指定文件或设备中 | |
| 正确输出和错误输出同时保存 | 命令 > 文件 2>&1 | 以覆盖的方式,把正确输出和错误输出同时保存到一个文件中 |
| 命令 >> 文件 2>&1 | 以追加的方式,把正确输出和错误输出同时保存到一个文件中 | |
| 命令 &>文件 | 以覆盖的方式,把正确输出和错误输出同时保存到同一个文件中 | |
| 命令 &>>文件 | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中 | |
| 命令 >> 文件1 2>>文件2 | 把正确的输出追加到文件1中,把错误输出追加到文件2中 |
本小结内容相当的简单,这里就不再介绍了.结束
Bash-Shell管道命令
sort 排序命令
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出,sort命令既可以从特定的文件,也可以从stdin中获取输入.
[root@localhost ~]# sort --help
语法格式:[ sort [选项] ]
-a #显示所有文件,包括隐藏文件,连同.与..的文件也列出来
-f #忽略大小写
-b #忽略每行前的空白部分
-n #以数值型进行排序,默认使用字符串类型排序
-r #反向排序
-u #删除重复行(=下面的uniq)
-t #指定分隔符,默认分割符是制表符
-k n[,m] #按照指定字段范围排序,从n字段开始到m字段结束
实例1: sort 命令默认使用每行开头第一个字符进行排序
[root@localhost ~]# sort /etc/passwd
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
....省略....
实例2: 进行反向排序则需要加 -r 选项
[root@localhost ~]# sort -r /etc/passwd
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
root:x:0:0:root:/root:/bin/bash
....省略....
实例3: 按照指定的排序字段进行字符排序,使用 -t 指定分割符,并且使用 -k 指定段号
[root@localhost ~]# sort -t ":" -k 3 /etc/passwd #以:作为分隔符,排序是按照第三段排列
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
....省略....
实例4: 上面的例子,排序方式是字符排序,而加上 -n 之后成为了数值排序
[root@localhost ~]# sort -n -t ":" -k 3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
....省略....
[root@localhost ~]# sort -n -t ":" -k 3,4 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
....省略....
wc 字数统计
wc命令用来计算数字,利用wc指令我们可以计算文件的Byte数、字数或是列数,若不指定文件名称,或是所给予的文件名为"-" 则wc指令会从标准输入设备读取数据.
[root@localhost ~]# wc --help
语法格式:[ wc [选项] 文件名 ]
-c #统计字数(字符)
-w #统计单词数(字符串)
-l #统计行数
uniq 取消重复行
uniq命令用于报告或忽略文件中的重复行,一般与sort命令结合使用.
[root@localhost ~]# uniq --hlep
语法格式:[ uniq [选项] ]
-i #忽略大小写
-c #在每列旁边显示该行重复出现的次数
-d #仅显示重复出现的行列
-f #忽略比较指定的栏位
-s #忽略比较指定的字符
-u #仅显示出一次的行列
-w #指定要比较的字符
实例1: 单独过滤,不排序,uniq命令只能过滤紧挨着的重复行
[root@localhost ~]# cat lyshark.log
123123
123123
qwrtyyu
sasdfgh
1234wsx
123123
ffffgh
123123
[root@localhost ~]# cat lyshark.log |uniq
123123
qwrtyyu
sasdfgh
1234wsx
123123
ffffgh
123123
实例2: 先排序再过滤,既可以过滤掉所有重复行
[root@localhost ~]# cat lyshark.log
123123
123123
qwrtyyu
sasdfgh
1234wsx
123123
ffffgh
123123
[root@localhost ~]# cat lyshark.log | sort |uniq
123123
1234wsx
ffffgh
qwrtyyu
sasdfgh
tr 文本转换命令
tr命令可以对来自标准输入的字符进行替换、压缩和删除,它可以将一组字符变成另一组字符,经常用来编写优美的单行命令,作用很强大.
[root@localhost ~]# tr --hlep
语法格式:[ tr [选项] ]
-d #删除信息中的,SET1这个字符串.
-s #替换掉重复字符串
-c #取代所有不属于第一字符集的字符
-t #先删除第一字符集较第二字符集多出的字符
实例1: 将last命令中的小写字符,全部变成大写(小写->大写)
[root@localhost ~]# who
root pts/0 2018-11-25 07:43 (192.168.1.20)
[root@localhost ~]# who | tr '[a-z]' '[A-Z]'
ROOT PTS/0 2018-11-25 07:43 (192.168.1.20)
实例2: 将 /etc/passwd 中的冒号全部删除
[root@localhost ~]# cat /etc/passwd | tr -d ":"
rootx00root/root/bin/bash
binx11bin/bin/sbin/nologin
daemonx22daemon/sbin/sbin/nologin
admx34adm/var/adm/sbin/nologin
lpx47lp/var/spool/lpd/sbin/nologin
....省略....
col 文本过滤器
col命令是一个标准输入文本过滤器,它从标注输入设备读取文本内容,并把内容显示到标注输出设备.在许多UNIX说明文件里,都有RLF控制字符.当我们运用shell特殊字符>和>> 把说明文件的内容输出成纯文本文件时,控制字符会变成乱码,col命令则能有效滤除这些控制字符.
[root@localhost ~]# col --help
语法格式:[ tr [选项] ]
-x #将TAB键转换为对等的空格
-b #过滤掉所有的控制字符,包括RLF和HRLF
join 连接文件
join命令用来将两个文件中,制定栏位内容相同的行连接起来.找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备.
[root@localhost ~]# join --help
语法格式:[ join [选项] ]
-t #默认以空格符分割数据
-i #忽略大小写差异
-1 #代表第一个文件用那个字段来分析
-2 #代表第二个文件用那个字段来分析
实例: 将/etc/passwd和/etc/shadow相同的行,连接在一起
[root@localhost ~]# head -n 3 /etc/passwd /etc/shadow
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
==> /etc/shadow <==
root:$6$gMIJWbnKgxk.lpzY$t3l0u.PNORfSTrjLIdizynMF5uA8LwnSth1tGS/2/89sPiMjVMGdKBPtmUNPYeaeeNRky..xh9Y7FS6LGqSu1/::0:99999:7:::
bin:*:17492:0:99999:7:::
daemon:*:17492:0:99999:7:::
[root@localhost ~]# join -t ":" /etc/passwd /etc/shadow |head -n 3
root:x:0:0:root:/root:/bin/bash:$6$gMIJWbnKgxk.lpzY$t3l0u.PNORfSTrjLIdizynMF5uA8LwnSth1tGS/2/89sPiMjVMGdKBPtmUNPYeaeeNRky..xh9Y7FS6LGqSu1/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin:*:17492:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin:*:17492:0:99999:7:::
paste 连接文件
这个命令,相对于join就简单多了,paste是直接将两个文件贴在一起,且中间以TAB隔开而已.
[root@localhost ~]# paste --help
语法格式:[ paste [选项] ]
-d #后面可接分隔符,默认是TAB来分割
实例: 实现文本的连接
[root@localhost ~]# paste /etc/passwd /etc/shadow | head -n 3
root:x:0:0:root:/root:/bin/bash root:$6$gMIJWbnKgxk.lpzY$t3l0u.PNORfSTrjLIdizynMF5uA8LwnSth1tGS/2/89sPiMjVMGdKBPtmUNPYeaeeNRky..xh9Y7FS6LGqSu1/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:17492:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:17492:0:99999:7:::
expand 转空格
expand命令用于将文件的制表符(TAB)转换为空白字符(space),将结果显示到标准输出设备.
[root@localhost ~]# expand --help
语法格式:[ expand [选项] ]
-t #后面接数字,转换成几个空格
split 文本切割
split命令可以将一个大文件分割成很多个小文件,有时需要将文件分割成更小的片段,比如为提高可读性,生成日志等.
[root@localhost ~]# split --help
语法格式:[ split [选项] [大小] [文件] ]
-b #后面可跟切割大小,可跟b,m,k
-l #以行数来进行切割
xargs 代数转换
xargs命令是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具,它擅长将标准输入数据转换成命令行参数,xargs能够处理管道或者stdin并将其转换成特定命令的命令参数.xargs也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行.xargs的默认命令是echo,空格是默认定界符,这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代.xargs是构建单行命令的重要组件之一.
[root@localhost ~]# xargs --help
[小例子]
[root@localhost ~]# echo "-lh" |ls
anaconda-ks.cfg
[root@localhost ~]# echo "-lh" |xargs ls
total 4.0K
-rw-------. 1 root root 1.2K Sep 18 09:12 anaconda-ks.cfg
实例1: 通过使用 xargs 将多行文本转换成单行
[root@localhost ~]# cat lyshark.log
a b c d e f g
h i j k l m n
[root@localhost ~]# cat lyshark.log | xargs
a b c d e f g h i j k l m n
实例2: 通过 xargs -n 指定每行打印的行数
[root@localhost ~]# cat lyshark.log
a b c d e f g
h i j k l m n
[root@localhost ~]# cat lyshark.log | xargs -n3
a b c
d e f
g h i
j k l
m n
实例3: 通过 xargs -d 指定一个限定符
[root@localhost ~]# echo "nameXnameXnameXname" | xargs -dX
name name name name
[root@localhost ~]# echo "nameXnameXnameXname" | xargs -dX -n2
name name
name name
↩︎