文章目录
- 1 直接使用 核心代码
- 2 工程代码实现
- 2.1 DDPM
- 2.2 训练
三大模型VAE,GAN, DIffusion扩散模型 是生成界的重要模型,但是最近一段时间扩散模型被用到的越来越多的,最近爆火的OpenAI的
Sora文生视频模型其实也是用了这种的方式,因而我打算系统回顾扩散系列知识,并注重代码的分析,感兴趣可以关注这一系列的博客,先介绍基础版本的,之后介绍扩散进阶的相关知识。
扩散模型很多的讲解上来会讲解很多的数学,会让人望而却步,但其实扩散在实际使用的时候并不复杂,我会先从代码的角度告诉大家怎么实操,再介绍数学推理
扩散要弄明白训练和推理两个过程~这节主要分析训练过程
1 直接使用 核心代码
基础版本的扩散核心就两句话
(1) DDPM前向扩散得到加噪后的图片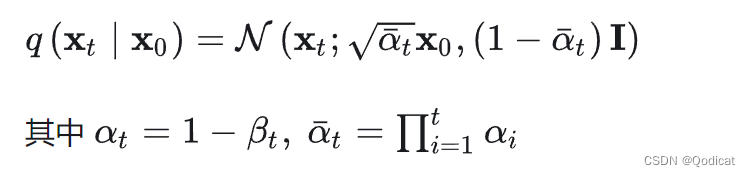
得到标记,对应一个核心公式**
(2) DDPM反向利用Unet网络预测加的噪声
实际上抽象一下,忽略细节,训练部分代码就主要以下部分
import torch
from torch import nn
n_steps=1000#假设我们最大的加噪步数是1000
x0=torch.ones(128,1,28,28) #模拟输入,1个batch有128张图片,通道数1,宽度高度为28
eta = torch.randn_like(x0) #生成初始随机噪声,形状和模拟输入一样
t= torch.randint(0, n_steps, (128,))#t是加噪时间,注意这里的t是随机生成的0到1000的128个随机数
noisy_imgs = ddpm(x0, t, eta) #前向加噪 输入原始输入图片和随机的t,得到128个加噪后的图像,扩散模型核心的第一句话
eta_theta = ddpm.backward(noisy_imgs, t.reshape(n, -1)) #反向预测,给定图和t,得到预测噪声,扩散模型核心的第二句话
loss = nn.mse(eta_theta, eta) #计算噪声和实际的噪声之间的差异作为损失
optim.zero_grad()
loss.backward()
optim.step()
2 工程代码实现
当然上面是一个简略版本,实际中肯定要考虑较多的细节问题~
先来实现DDPM
2.1 DDPM
我们申明一个这样一个类MyDDPM
class MyDDPM(nn.Module):
def __init__(self, network, n_steps=200, min_beta=10 ** -4, max_beta=0.02, device=None, image_chw=(1, 28, 28)):
super(MyDDPM, self).__init__()
self.n_steps = n_steps #扩散时间总步数
self.device = device
self.image_chw = image_chw #image_chw 用于表示图像的通道数、高度和宽度。这里通道数1,宽度高度为28
self.network = network.to(device)
self.betas = torch.linspace(min_beta, max_beta, n_steps).to(
device) # beta预先算出来了
self.alphas = 1 - self.betas #alphas也预先算出来
self.alpha_bars = torch.tensor([torch.prod(self.alphas[:i + 1]) for i in range(len(self.alphas))]).to(device) #alphas_bars也预先算出来了 前i个乘积
def forward(self, x0, t, eta=None):
n, c, h, w = x0.shape #[批大小,通道数,图片高,图片宽]
a_bar = self.alpha_bars[t] #t的大小和批大小相等
if eta is None:
eta = torch.randn(n, c, h, w).to(self.device)
noisy_img = a_bar.sqrt().reshape(n, 1, 1, 1) * x0 + (1 - a_bar).sqrt().reshape(n, 1, 1, 1) * eta
return noisy_img
def backward(self, x, t):
# Run each image through the network for each timestep t in the vector t.
# The network returns its estimation of the noise that was added.
return self.network(x, t)
这段代码定义了一个名为MyDDPM的类,它是nn.Module的子类。
在MyDDPM类的构造函数__init__中,有以下几个重要的属性和操作:
n_steps:扩散时间总步数,表示模型在每个输入上进行的扩散步数。device:设备,表示模型在哪个设备上运行(如CPU或GPU)。image_chw:图像通道数、高度和宽度的元组,用于表示图像的形状。在这里,通道数为1,高度和宽度为28。network:神经网络模型,用于估计添加的噪声。betas:通过使用torch.linspace函数在min_beta和max_beta之间生成n_steps个均匀间隔的值,得到一个表示扩散系数的张量。alphas:通过将1减去betas得到的张量,表示衰减系数。alpha_bars:通过计算alphas的前i+1个元素的乘积,得到一个表示衰减系数累积乘积的张量。
MyDDPM类还定义了两个方法:
forward方法用于前向传播。它接受输入x0、时间步t和可选的噪声eta作为参数。在该方法中,首先获取输入x0的形状,并根据时间步t获取对应的衰减系数a_bar。如果未提供噪声eta,则使用torch.randn函数生成一个与输入形状相同的噪声张量。然后,根据衰减系数和噪声,计算得到带有噪声的图像张量,并返回该张量作为输出。backward方法用于反向传播。它接受输入x和时间步t作为参数,并通过调用network模型对每个时间步t的输入x进行处理,得到估计的添加噪声。最后,返回估计的噪声张量作为输出。
2.2 训练
有了DDPM我们就可以进行训练了(实际上这里的network我们先当做一个黑盒,在下一节讲解结构,network实现的效果就是输入某一时刻的t,和该时刻加噪后的图像,输出预测的噪声结果,该结果和前向生成的噪声做损失函数~优化参数)
def training_loop(ddpm, loader, n_epochs, optim, device, display=False, store_path="ddpm_model.pt"):
mse = nn.MSELoss()
best_loss = float("inf")
n_steps = ddpm.n_steps
for epoch in tqdm(range(n_epochs), desc=f"Training progress", colour="#00ff00"):
epoch_loss = 0.0
for step, batch in enumerate(tqdm(loader, leave=False, desc=f"Epoch {epoch + 1}/{n_epochs}", colour="#005500")):
# Loading data
x0 = batch[0].to(device) #[128,1,1,28]
n = len(x0)
# Picking some noise for each of the images in the batch, a timestep and the respective alpha_bars
eta = torch.randn_like(x0).to(device)
t = torch.randint(0, n_steps, (n,)).to(device) #注意这里的t是随机生成的
# Computing the noisy image based on x0 and the time-step (forward process)
noisy_imgs = ddpm(x0, t, eta) #经过前向过程 y一次得到一个批次的
# Getting model estimation of noise based on the images and the time-step
eta_theta = ddpm.backward(noisy_imgs, t.reshape(n, -1))
loss = mse(eta_theta, eta) #预测噪声和给出的噪声之间的差异
optim.zero_grad()
loss.backward()
optim.step()
epoch_loss += loss.item() * len(x0) / len(loader.dataset)
# Display images generated at this epoch
if display:
show_images(generate_new_images(ddpm, device=device), f"Images generated at epoch {epoch + 1}")
log_string = f"Loss at epoch {epoch + 1}: {epoch_loss:.3f}"
# Storing the model
if best_loss > epoch_loss:
best_loss = epoch_loss
torch.save(ddpm.state_dict(), store_path)
log_string += " --> Best model ever (stored)"
print(log_string)
-
函数定义:
def training_loop(ddpm, loader, n_epochs, optim, device, display=False, store_path="ddpm_model.pt"):- 这个函数接受多个参数:
ddpm是一个对象,loader是一个数据加载器,n_epochs是训练的轮数,optim是优化器,device是设备(如CPU或GPU),display是一个布尔值,用于控制是否显示生成的图像,store_path是模型存储的路径。 - 函数没有返回值。
- 这个函数接受多个参数:
-
导入模块:
mse = nn.MSELoss()- 这里导入了
nn模块,并创建了一个MSELoss的实例对象mse。
- 这里导入了
-
初始化变量:
best_loss = float("inf") n_steps = ddpm.n_stepsbest_loss被初始化为正无穷大,用于跟踪最佳损失值。n_steps从ddpm对象中获取,表示模型的步数。
-
训练循环:
for epoch in tqdm(range(n_epochs), desc=f"Training progress", colour="#00ff00"): epoch_loss = 0.0 for step, batch in enumerate(tqdm(loader, leave=False, desc=f"Epoch {epoch + 1}/{n_epochs}", colour="#005500")): # Loading data x0 = batch[0].to(device) #[128,1,1,28] n = len(x0) ...- 外部循环是训练的轮数,使用
range(n_epochs)生成一个迭代器,并使用tqdm函数包装,以显示训练进度条。 - 内部循环是对数据加载器中的批次进行迭代,使用
enumerate函数包装,并使用tqdm函数包装,以显示每个批次的进度条。 - 在每个批次中,首先从批次中加载数据,并将其移动到指定的设备上。
x0是批次中的第一个元素,表示输入数据。n是批次的大小。
- 外部循环是训练的轮数,使用
-
数据处理和模型训练:
eta = torch.randn_like(x0).to(device) t = torch.randint(0, n_steps, (n,)).to(device) noisy_imgs = ddpm(x0, t, eta) eta_theta = ddpm.backward(noisy_imgs, t.reshape(n, -1)) loss = mse(eta_theta, eta) optim.zero_grad() loss.backward() optim.step()eta是一个与x0形状相同的随机张量,用于添加噪声。t是一个随机生成的整数张量,表示时间步骤。noisy_imgs是通过将x0和t作为输入,使用ddpm对象进行前向传播得到的噪声图像。eta_theta是通过将noisy_imgs和t进行反向传播,使用ddpm对象得到的噪声估计。loss是通过计算eta_theta和eta之间的均方误差(MSE)得到的损失。optim.zero_grad()用于清除优化器的梯度。loss.backward()用于计算损失相对于模型参数的梯度。optim.step()用于更新模型参数。
-
显示生成的图像和存储模型:
if display: show_images(generate_new_images(ddpm, device=device), f"Images generated at epoch {epoch + 1}") ... if best_loss > epoch_loss: best_loss = epoch_loss torch.save(ddpm.state_dict(), store_path) log_string += " --> Best model ever (stored)" ... print(log_string)- 如果
display为True,则调用show_images函数显示生成的图像。 generate_new_images函数用于生成新的图像样本。- 如果当前轮的损失比之前的最佳损失更低,则将模型参数保存到指定的路径。
- 最后,打印训练日志字符串。
- 如果