Deep Learning for Person Re-identification: A Survey and Outlook
论文地址https://arxiv.org/pdf/2001.04193
1. 摘要
we categorize it into the closed-world and open-world settings.
-
closed-world:学术环境下
-
open-world :实际应用场景下
2. 引言
引言部分主要讨论了跨非重叠摄像头的行人重识别(Re-ID)问题,强调其在智能监控系统中的重要性和挑战。作者提到Re-ID面临的挑战,如视角变化、低分辨率、光照变化等,并指出早期研究主要集中在手工特征构建和距离度量学习上。随着深度学习的发展,虽然在一些标准数据集上取得了显著进展,但实际应用与研究场景之间仍存在较大差距。此外,作者提出了一个新的基线方法AGW和一个新的评估指标mINP,旨在推动未来的Re-ID研究,并讨论了一些未来的研究方向,以期缩小封闭世界和开放世界应用之间的差距。
2.1 构建一个ReID系统需要的五个步骤
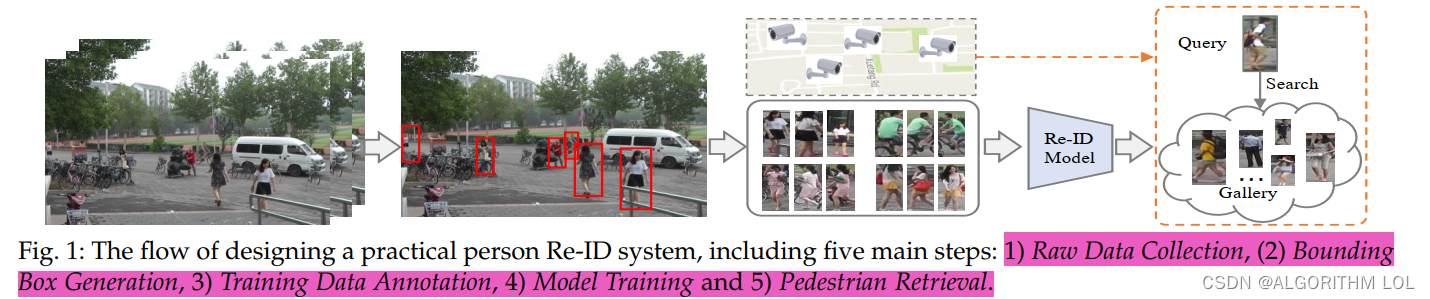
-
原始数据采集
-
生成边界框:框出其中的行人,借助算法:person detection or tracking algorithms
-
对训练数据进行标注:标注这些个体在不同摄像头下的相同身份。这意味着,对于给定的个体,需要在不同摄像头捕获的图像中识别出该个体,并为其分配相同的标识符。
-
训练模型(核心):
-
feature representation learning
-
distance metric learning
-
their combinations
-
-
检索:给定一个疑犯(查询对象)和一个图库集,我们使用上一阶段学习的Re-ID模型提取特征表示。通过对计算的查询到库的相似性进行排序,获得检索到的排名列表。(Some methods have also investigated the ranking optimization to improve the retrieval performance)
2.2 学术环境与实际应用场景对比
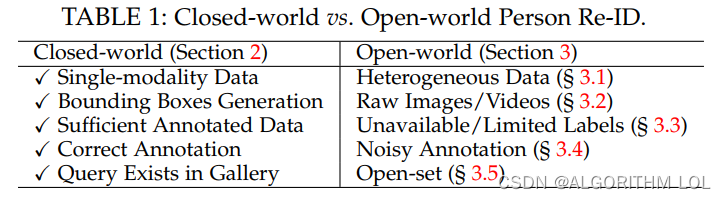
| 学术环境 | 实际应用场景 | |
|---|---|---|
| 数据 | all the persons are represented by images/videos captured by single-modality visible cameras in the closed-world setting | process heterogeneous data, which are infrared images [21], [60], sketches [61], depth images [62], or even text descriptions |
| 人物框选 | generated bounding boxes ——已经框选好的 | require end-to-end person search from the raw images or videos ——端到端也就是要自己处理 |
| 标注 | 大量且已经标注好 | 少量或没有标注 |
| 标注正确性 | assume that all the annotations are correct, with clean labels | annotation noise |
| query是否在gallery | assume that the query must occur in the gallery set by calculating the CMC [68] and mAP | query person may not appear in the gallery set [69], [70], or we need to perform the verification rather than retrieval [26]. This brings us to the open-set person Re-ID |
3. CLOSED-WORLD PERSON RE-IDENTIFICATION
假设条件:
-
单一模态捕捉的图像或视频
-
人物已经被框选,大多数是同一人
-
有足够的标注
-
标注正确
-
query person肯定在
-
gallery set.
standard closed-world Re-ID system 三个主要组件:
-
Feature Representation Learning ——focuses on developing the feature construction strategies
-
Deep Metric Learning——which aims at designing the training objectives with different loss functions or sampling strategies
-
Ranking Optimization ——concentrates on optimizing the retrieved ranking list.
2.1 Feature Representation Learning
four main categories
-
Global Feature ——global feature representation vector for each person image without additional annotation cues
-
Local Feature (§ 2.1.2), it aggregates part-level local features to formulate a combined representation for each person image
-
Auxiliary Feature (§ 2.1.3), it improves the feature representation learning using auxiliary information, e.g., attributes [71], [72], [78], GAN generated images [42], etc
-
Video Feature (§ 2.1.4), it learns video representation for video-based Re-ID [7] using multiple image frames and temporal information [73], [74

2.1.1 Global Feature Representation Learning
-
joint learning framework consisting of a singleimage representation (SIR) and cross-image representation (CIR) training process as a multi-class classification problem by treating each identity as a distinct class.
-
Attention Information.
-
Attention information in person re-identification refers to techniques used to enhance feature learning by focusing on specific parts of the data. It includes pixel-level attention which emphasizes individual pixels, part-level attention which focuses on different regions of a person's image, and spatial or background suppression to reduce noise from irrelevant areas. It also includes context-aware attention for handling multiple person images, which improves the feature learning by considering the relationships between different images or sequences. These attention mechanisms contribute to more accurate identification by highlighting relevant features and suppressing irrelevant ones.
Global Feature Representation Learning in person re-identification primarily focuses on extracting a comprehensive feature vector for the entire person image. It utilizes networks originally designed for image classification and applies them to re-ID, leveraging fine-grained cues for learning distinctive features.
2.1.2 Local Feature Representation Learning
Local Feature Representation Learning aims to be robust against issues such as misalignment of person images. It divides the body into parts or regions and extracts features from these specific areas. This method helps in accurately matching body parts across different images and is especially useful in dealing with variations in pose or when parts of the body are occluded.
2.1.3 Auxiliary Feature Representation Learning
usually requires additional annotated information (e.g., semantic attributes [71]) or generated/augmented training samples to reinforce the feature representation
-
Semantic Attributes: These are descriptive characteristics such as "male," "short hair," "wearing a red hat," etc., which can be used to provide additional context and improve the accuracy of feature representation. The learning models may use these semantic attributes to distinguish between individuals more effectively, especially in semi-supervised learning settings where not all data may be labeled.语义属性:这些是描述性特征,例如“男性”、“短发”、“戴红帽子”等,可用于提供额外的上下文并提高特征表示的准确性。学习模型可以使用这些语义属性来更有效地区分个体,尤其是在并非所有数据都可以标记的半监督学习环境中。
-
Viewpoint Information: This takes into account the angle from which the person is captured across different cameras. By considering the viewpoint, models can learn to recognize the same individual from various angles, which is crucial for robust Re-ID across multiple cameras.视点信息:这考虑了在不同摄像机上捕捉人物的角度。通过考虑视点,模型可以学会从不同角度识别同一个人,这对于跨多个摄像头进行强大的 Re-ID 至关重要。
-
Domain Information: Treating images from different cameras as distinct domains, this approach aims to extract a globally optimal feature set that accounts for cross-camera variations. This could involve aligning features across these domains to ensure consistent identification.域信息:将来自不同相机的图像视为不同的域,此方法旨在提取考虑跨相机变化的全局最优特征集。这可能涉及对这些域的要素进行对齐,以确保一致的标识。
-
GAN Generation: The use of Generative Adversarial Networks (GANs) to create synthetic images helps in addressing cross-camera variations and enhances the robustness of the model. These generated images can provide additional data points for training, particularly useful when actual images are scarce or when trying to model different environmental conditions.GAN生成:使用生成对抗网络(GAN)创建合成图像有助于解决跨相机变化问题,并增强模型的鲁棒性。这些生成的图像可以为训练提供额外的数据点,当实际图像稀缺或尝试对不同的环境条件进行建模时,特别有用。
-
Data Augmentation: Custom data augmentation methods such as random resizing, cropping, and flipping are used to artificially expand the dataset, making the trained model more generalizable and less prone to overfitting. More sophisticated techniques might include generating occluded samples or applying random erasing strategies to simulate a wider variety of real-world conditions that the Re-ID system may encounter.数据增强:使用随机调整大小、裁剪和翻转等自定义数据增强方法,人为地扩展数据集,使训练后的模型更具泛化性,不易出现过度拟合。更复杂的技术可能包括生成遮挡样本或应用随机擦除策略来模拟 Re-ID 系统可能遇到的更多实际情况。
2.1.4 Video Feature Representation Learning
additional challenges
-
accurately capture the temporal information.
-
unavoidable outlier tracking frames within the videos
-
handle the varying lengths of video sequences
2.1.5 Architecture Design
设计不同架构来解决
2.2 Deep Metric Learning
2.2.1 Loss Function Design
identity loss, verification loss and triplet loss
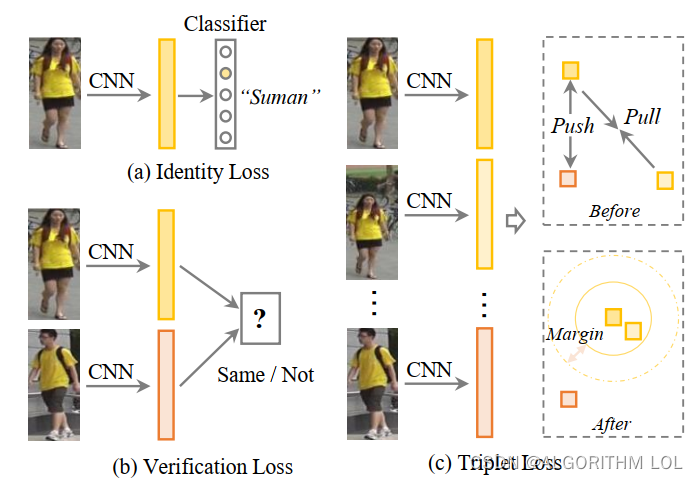
Re-ID领域中常用的四种损失函数及其作用:
-
Identity Loss(身份损失):
-
将人员Re-ID的训练过程视为一个图像分类问题,其中每个身份被视为一个独立的类别。
-
在测试阶段,使用池化层或嵌入层的输出作为特征提取器。
-
使用softmax函数计算输入图像被正确识别为其类别的概率,并通过交叉熵计算身份损失。
-
身份损失在训练过程中自动挖掘难样本,简单易训练,且通常与标签平滑等策略结合使用以提高模型的泛化能力。
-
-
Verification Loss(验证损失):
-
优化成对关系,使用对比损失或二元验证损失来改善相对成对距离的比较。
-
对比损失关注于增强样本对之间的欧氏距离比较,通过最大化同一身份内样本的相似性和不同身份样本的差异性。
-
二元验证损失区分图像对的正负,关注于识别输入图像对是否属于同一身份。
-
-
Triplet Loss(三元组损失):
-
将Re-ID模型训练过程视为一个检索排序问题,确保同一身份的样本对距离小于不同身份样本对的距离。
-
三元组包含一个锚点样本、一个正样本(与锚点同一身份)和一个负样本(不同身份),通过预定义的边际参数优化这三者之间的距离。
-
为了提高训练的效果,采用了各种信息三元组挖掘方法,以选择更具信息量的三元组进行训练。
-
-
OIM Loss(在线实例匹配损失):
-
设计了一个包含存储实例特征的内存库,通过内存库优化在线实例匹配。
-
OIM损失通过比较输入特征与内存库中存储的特征之间的相似度,处理大量非目标身份的实例。
-
这种方法在无监督领域自适应Re-ID中也得到了应用,通过控制相似度空间的温度参数优化实例匹配分数。
-
2.2.2 Training strategy
训练策略(Training strategy)是机器学习和深度学习中一组用于指导模型训练过程的方法和技术。它包括各种技巧和方法,旨在提高模型的学习效率、性能和泛化能力。
-
批量采样策略的挑战:
-
由于每个身份标注的训练图像数量差异很大,以及正负样本对之间严重不平衡,设计有效的训练策略变得具有挑战性。
-
-
身份采样:
-
处理样本不平衡问题的最常见策略是身份采样。在这种策略下,每个训练批次会随机选取一定数量的身份,然后从每个选定的身份中采样几张图像。这种批量采样策略保证了有效的正负样本挖掘。
-
-
适应性采样:
-
为了处理正负样本之间的不平衡问题,流行的方法是适应性采样,通过调整正负样本的贡献来应对不平衡,例如采样率学习(SRL)和课程采样等。
-
-
样本重权:
-
另一种方法是样本重权,通过使用样本分布或相似性差异来调整样本权重。这有助于平衡训练过程中样本的影响,提高模型对不同样本的区分能力。
-
-
高效的参考约束:
-
设计了高效的参考约束来将成对/三元组相似性转化为样本到参考的相似性,这不仅解决了不平衡问题,而且增强了区分性,并且对异常值具有鲁棒性。
-
-
多损失动态训练策略:
-
通过适应性地重新加权身份损失和三元组损失,动态组合多个损失函数,可以提取它们之间的共享组件。这种多损失训练策略导致了一致的性能提升。
-
2.3 Ranking Optimization
2.3.1 Re-ranking
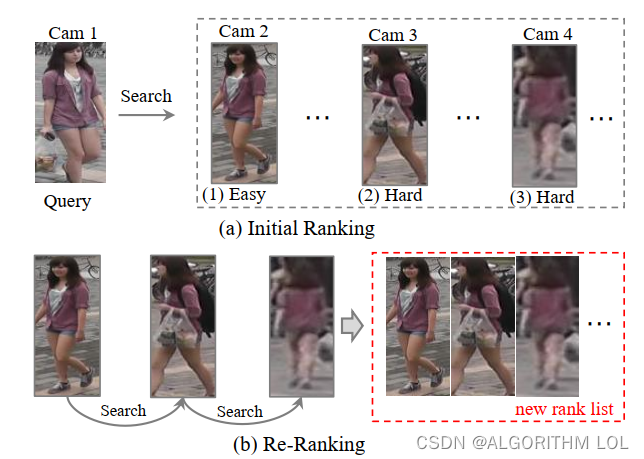
通过不同的技术和方法(如重排、查询适应性和人机交互)来实现更准确的排名顺序。这些方法能够根据不同的情境和需求,灵活地优化排名结果,从而提高检索的准确性和效率。
2.3.2 Rank Fusion
在实际应用中,不同的检索或识别算法可能对同一数据集有不同的理解和表现,某些算法在特定情境下表现良好,而在其他情境下表现可能较差。排名融合通过合理地结合这些算法产生的结果,旨在充分利用每种方法的优势,从而提供一个综合考虑了多种视角和信息的更准确、更可靠的排名结果。
2.4 Datasets and Evaluation
数据集:
GitHub - NEU-Gou/awesome-reid-dataset: Collection of public available person re-identification datasets
评估指标:
-
累积匹配特性(CMC):
-
CMC曲线或CMC-k指标(又称Rank-k匹配准确率)反映了在前k个检索结果中找到正确匹配的概率。当每个查询仅对应一个正确结果时,CMC提供了一个准确的评估。然而,在包含多个正确匹配项的大型摄像头网络中,CMC可能无法完全反映模型跨多个摄像头的区分能力。
-
-
平均平均精确度(mAP):
-
mAP衡量的是在有多个正确匹配项时的平均检索性能,它在图像检索领域被广泛使用。对于Re-ID评估,mAP可以解决两个系统在查找第一个正确匹配(可能是容易的匹配)时表现相同,但在检索其他难度较大的匹配项时能力不同的问题。
-
-
FLOPs(浮点操作次数每秒):
-
FLOPs是衡量模型复杂度和运算效率的指标,特别是在计算资源受限的训练/测试设备上,FLOPs成为了一个重要的考量因素。它反映了执行某个操作或运行模型一次所需的浮点运算次数。
-
-
网络参数大小:
-
网络参数大小指的是构成模型的参数总量,这直接影响模型的存储需求和计算复杂度。在资源受限的环境中,参数越少的模型越受欢迎,因为它们占用的内存少,运行速度可能更快。
-
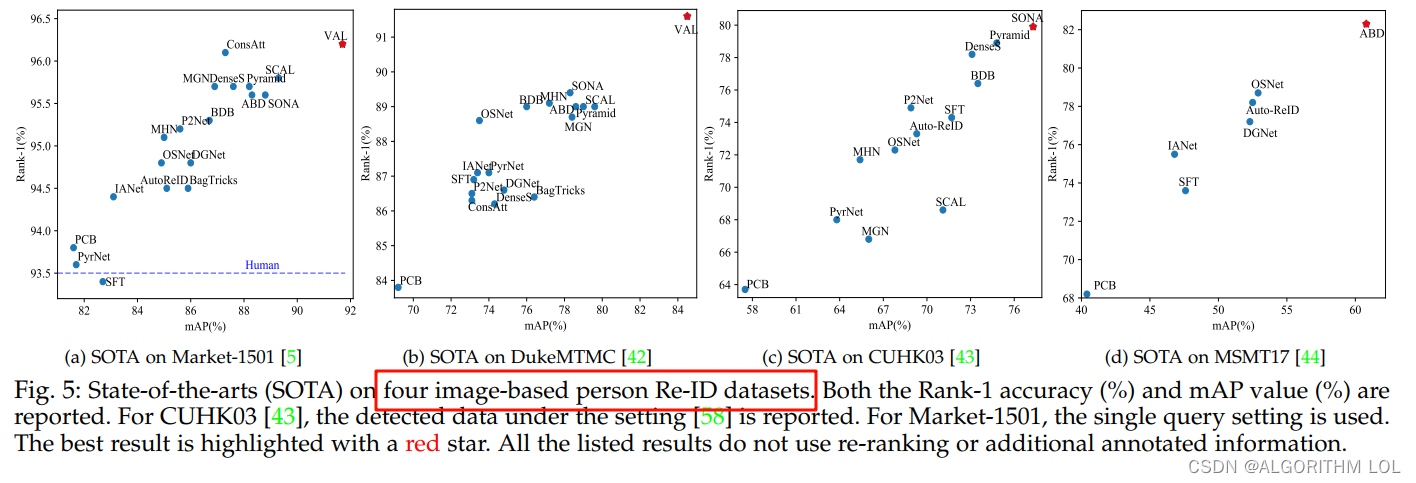
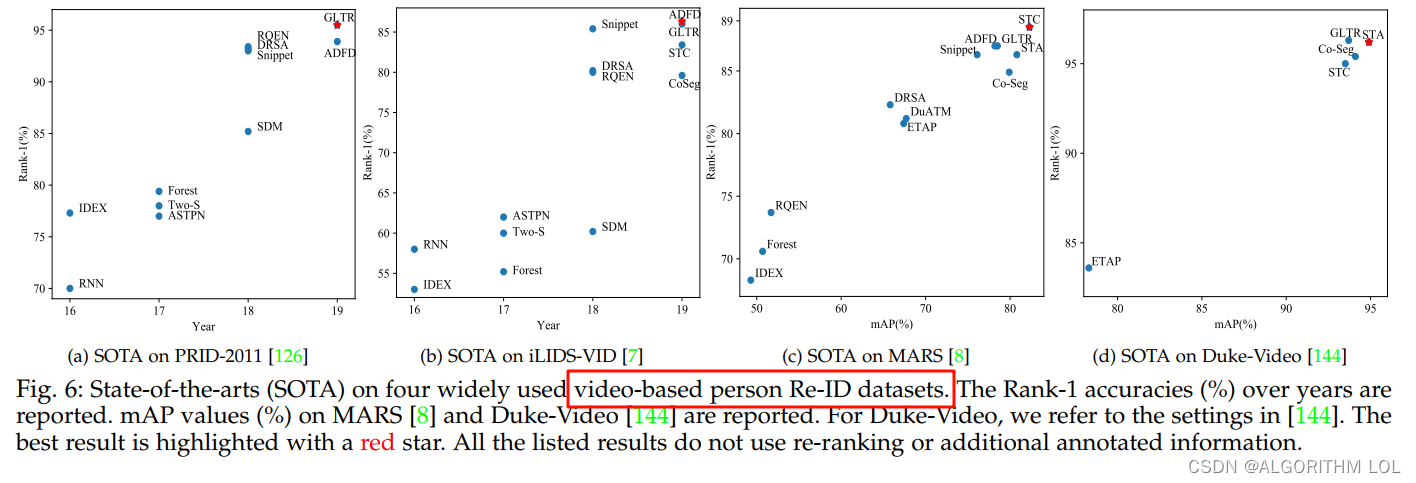
一些代表性方法








![[word] word正反面打印应该怎么设置呢? #知识分享#学习方法#职场发展](https://img-blog.csdnimg.cn/img_convert/d98fba371371a81fec8032c58e56cfb8.jpeg)