爬虫介绍
# 爬虫的概念:
通过编程技术(python:request,selenium),获取互联网中的数据(app,小程序,网站),数据清洗(xpaht,lxml)后存到库中(mysql,redis,文件,excel,mongodb)
# 基本思路:
通过编程语言,模拟发送http请求,获取数据,解析,入库
# 过程:爬取过程,解析过程,会遇到反扒
抓app,小程序,会通过抓包工具(charles,Fiddler),抓取手机发送的所有请求
# 爬虫协议:
君子协议:https://xxx/robots.txt
# 百度是个大爬虫:
百度/谷歌搜索引擎,启动了一个爬虫,一刻不停的在互联网中爬取网站,存到库中(es)
用户在百度输入框中,输入搜索内容,去百度的库中搜索,返回给前端,前端点击,去了真正的地址
seo 优化:不花钱,搜索关键词的结果,排的靠前
-伪静态
sem 优化:花钱买关键词
requests模块介绍
# requests模块:模拟发送http请求模块,封装了urlib3(python内置的发送http请求的模块)
爬虫会用
后端: 向其他api接口发送请求
同步
# requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
# 第三方: pip3 install requests
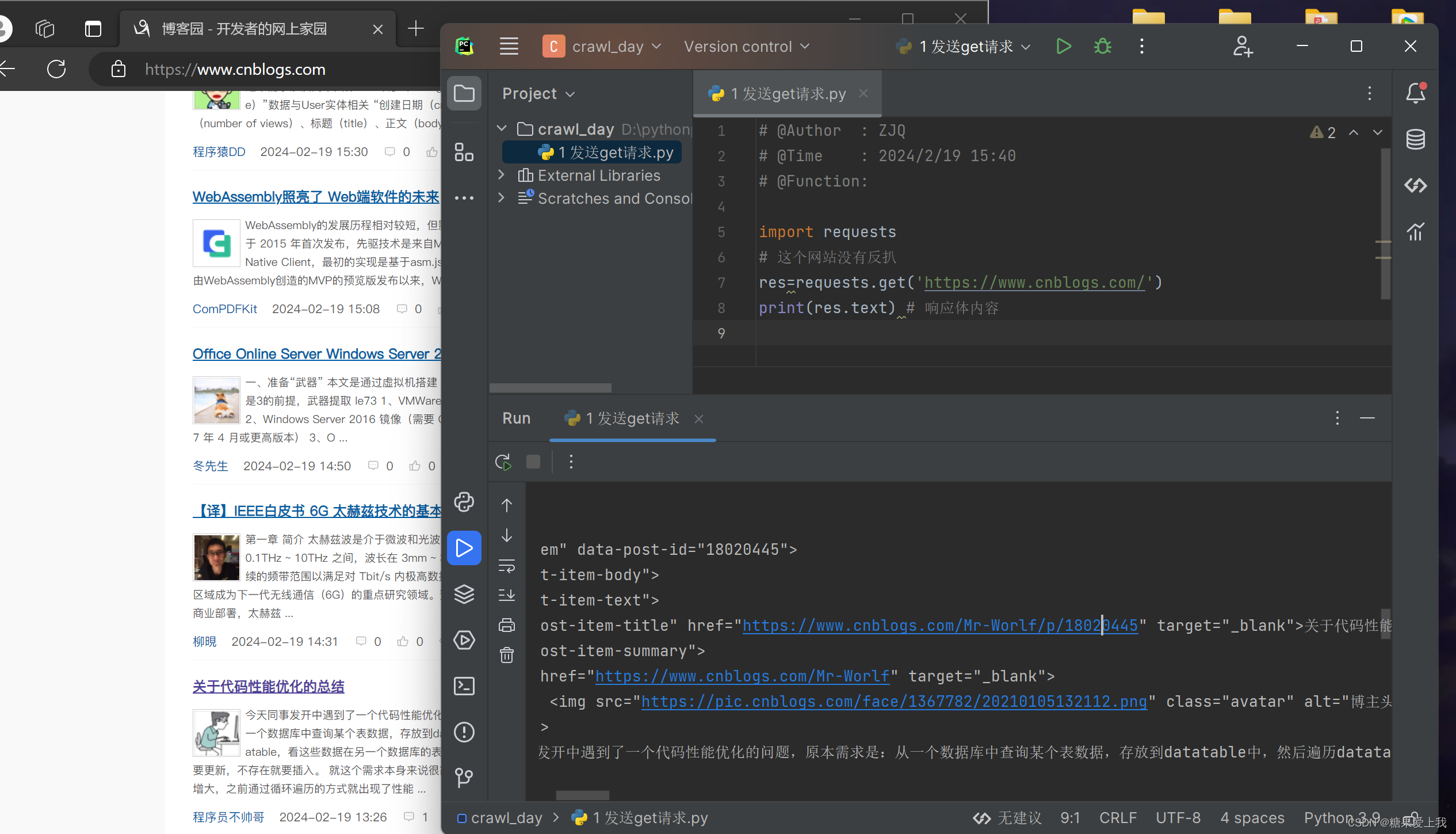
requests发送get请求
# requests可以模拟发送http请求,有的时候,网站会禁止
禁止的原因是:模拟的不像,有的东西没带
# http请求:请求头中没带东西,没带cookie,客户端类型,referer...import requests res=requests.get('https://www.cnblogs.com/') # 这个网站没有反扒 print(res.text) # 响应体内容
携带get参数
# 携带get参数方式一:
import requests res=requests.get('https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=上海&query=肯德基&output=json') print(res.text)# 携带get参数方式二:
import requests params = { 'ak': '6E823f587c95f0148c19993539b99295', 'region': '上海', 'query': '肯德基', 'output': 'json', } res = requests.get('https://api.map.baidu.com/place/v2/search',params=params) print(res.text) # 响应体内容# url 编码和解码:
from urllib.parse import quote,unquote s='上海' # %E4%B8%8A%E6%B5%B7 print(quote(s)) print(unquote('%E4%B8%8A%E6%B5%B7'))
携带请求头
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } res = requests.get('https://dig.chouti.com/',headers=headers) print(res.text)
发送post请求携带cookie
# 是否登录:有个标志
前后端混合项目:登录信息-->放在cookie中了
前后端分离项目:登录信息--》后端规定的--》放在请求头的# 方式一:放在请求头中
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36', 'Cookie': 'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJiNjEzOGM2OS02ZWRlLTQ3MWItODI4Yy03YTg2ZTE3M2E3NjEiLCJleHBpcmUiOiIxNzEwOTAxNjM1MTMxIn0.JluPFMn3LLUGKeTFPyw7rVwR-BWLiG9V6Ss0RGDHjxw; Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1708309636; __snaker__id=miaeDoa9MzunPIo0; gdxidpyhxdE=lMhl43kDvnAOqQQcQs9vEoTiy8k90nSwfT3DkVSzGwu3uAQWI9jqa2GcIUvryeOY0kX6kfPuhJUAGrR6ql0iv%2F6mCzqh6DHE1%5CP%2BaIXeUQgLcfqlklCcq2V9CgWbvQRGeRaduwzkcPYwf6CXZiW9a87NxU%2BRlYq57Zq01j2gMK0BaX%2FK%3A1708310847499; token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNzEwOTAxOTY5NTM2In0.eseWTCMqp-yHa7rWgSvPhnWVhhQAgqGIvIgLGbvcBcc; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1708309982' } data = { 'linkId': '41566118' # 文章id } # 没有登录---》返回的数据不是咱们想要的 res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data) print(res.text)# 方式二:放在cookie中
cookie特殊,后期用的频率很高
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36', } data = { 'linkId': '41566118' } cookie = { 'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNzEwOTAxOTY5NTM2In0.eseWTCMqp-yHa7rWgSvPhnWVhhQAgqGIvIgLGbvcBcc' } # 没有登录---》返回的数据不是咱们想要的 res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data, cookies=cookie) print(res.text)
post请求携带参数
# post请求有三种编码方式:
json,urlencoded,form-data
# 方式一:data参数是urlencoded
以data字典形式携带urlencoded编码,最终会被编码为name=lqz&age=19放在请体中
import requests res=requests.post('地址',data={'name':'lqz','age':19}) # res=requests.post('地址',data=b'name=lqz&age=19')# 方式二:json编码:json
# 以json字典形式携带json编码,最终它会被编码为{'name':'lqz','age':19}放在请体中import requests res=requests.post('地址',json={'name':'lqz','age':19})
模拟登录
# 登录接口通过post请求,登录后能拿到登录信息,再发请求携带登录信息就是登录状态
可见即可爬
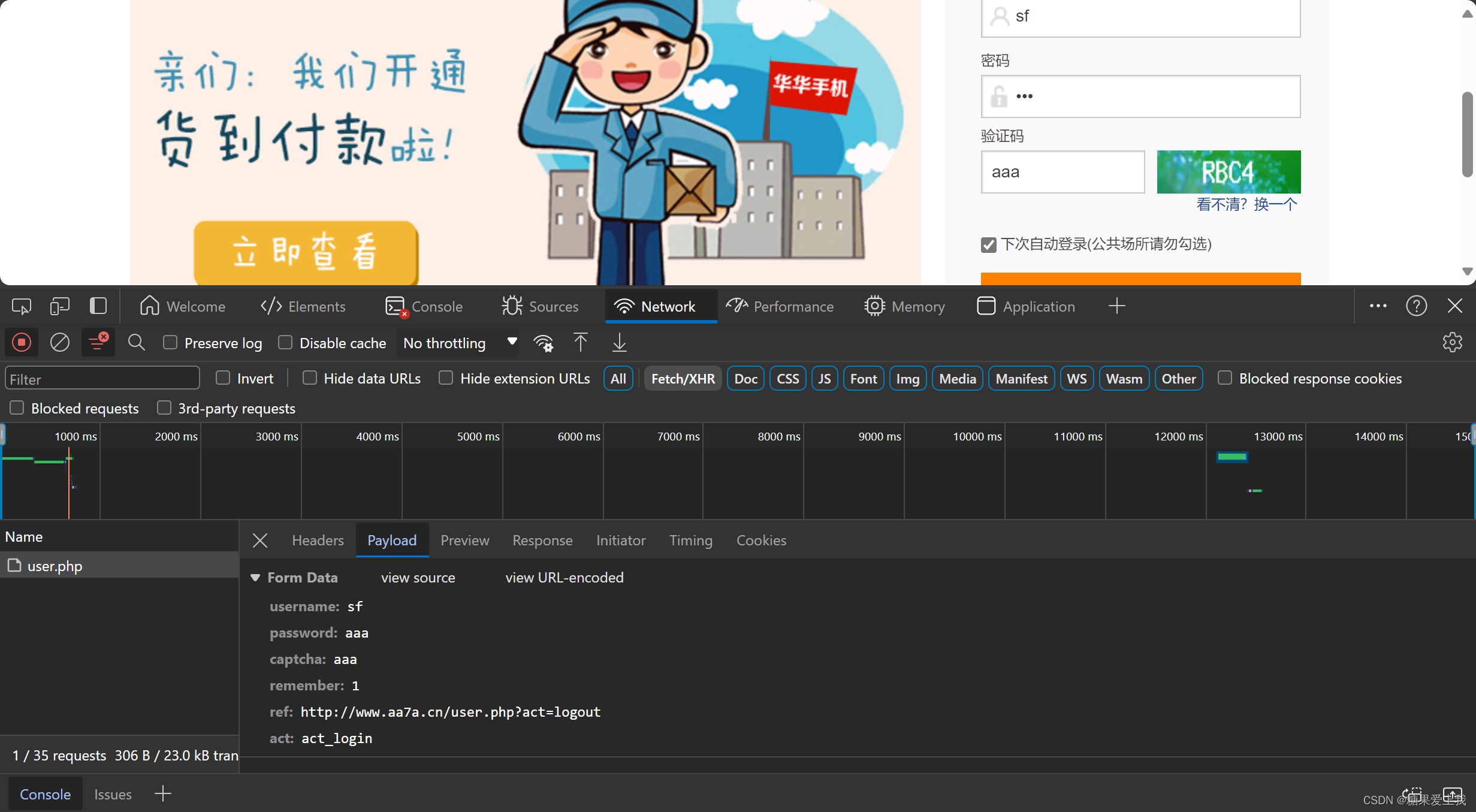
import requests data = { 'username': '616564099@qq.com', 'password': 'lqz123', 'captcha': '3333', 'remember': '1', 'ref': ' http://www.aa7a.cn/', # 登录成功,重定向到这个地址 'act': 'act_login', } header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } res = requests.post('http://www.aa7a.cn/user.php', headers=header, data=data) print(res.text) # 登录成功的cookie cookies=res.cookies print(cookies) # 向首页发送请求--->携带cookie便是登录状态 res=requests.get('http://www.aa7a.cn/',cookies=cookies) print('616564099@qq.com' in res.text)
响应对象
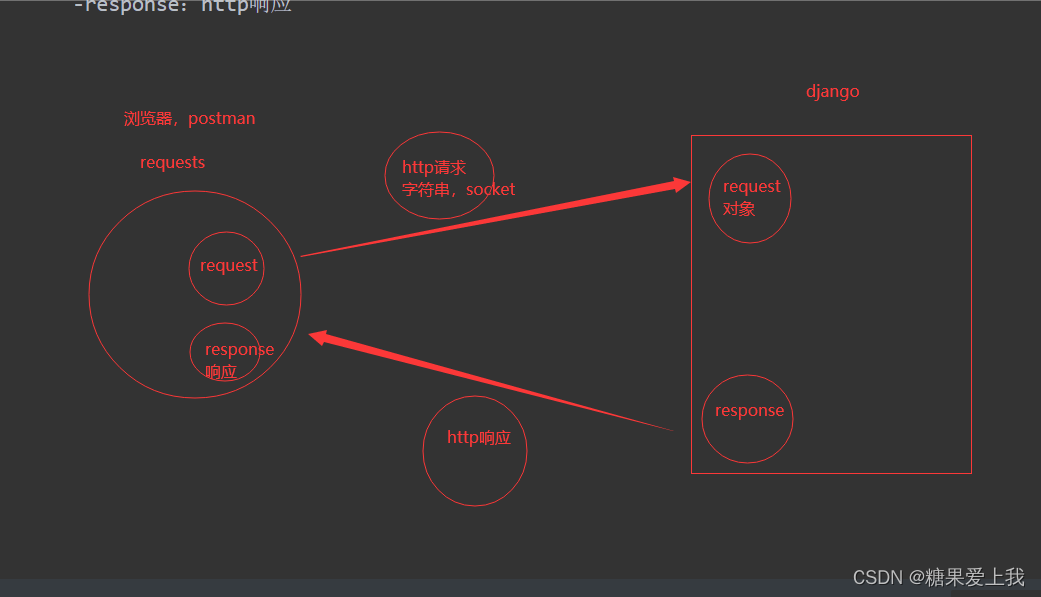
# 使用requests模块发送请求: request对象请求头,请求参数,请求体
本质就是http请求,被包装成一个对象
# 响应回来:response对象有http响应,cookie,响应头,响应体...
request:http请求
response:http响应
# 爬取普通图片:import requests header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } respone = requests.get('https://www.jianshu.com/',headers=header)# 如果下载图片,视频:
图片防盗链,通过referer做的,请求头中有个referer参数,上次访问的地址
import requests header={ 'Referer':'https://www.tupianzj.com/' } res=requests.get('https://img.lianzhixiu.com/uploads/allimg/180514/9-1P514153131.jpg',headers=header) print(res.content) with open('美女.jpg','wb') as f: f.write(res.content) # 图片,视频---》迭代着把数据保存到本地 # with open('code.jpg','wb') as f: # for line in res.iter_content(chunk_size=1024): # f.write(line)# respone属性:
print(respone.text) # 响应体---》字符串形式 print(respone.content) # 响应体---》bytes格式 print(respone.status_code) # 响应状态码 print(respone.headers) # 响应头 print(respone.cookies) # 响应的cookie print(respone.cookies.get_dict()) # cookiejar对象--->转成字典格式 print(respone.cookies.items()) # cookie的value值 print(respone.url) # 请求地址 print(respone.history) # 访问历史---》重定向,才会有 print(respone.encoding) # 编码格式 response.iter_content() # 图片,视频---》迭代着把数据保存到本地
ssl 认证
# http和 https:
http:超文本传输协议
https:安全的超文本传输协议,防止被篡改,截取...
https=http+ssl/tls
必须有证书:才能通信import requests header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } respone = requests.get('https://www.jianshu.com/',headers=header,verify=False) # respone = requests.get('https://www.jianshu.com/',headers=header,cert=('/path/server.crt','/path/key')) print(respone.text)
使用代理
# 代理有正向代理和向代理
# 大神写了开源的免费代理:
原理:有些网站提供免费的代理,通过爬虫技术爬取别人的免费代理,验证过后自己用
加入自己的id访问不了,可以使用免费代理生成id再去访问
import requests res = requests.get('http://demo.spiderpy.cn/get/?type=https') print(res.json()) print(res.json()['proxy']) # 112.30.155.83:12792 header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } # respone = requests.get('https://www.jianshu.com/', headers=header, proxies={'https': res.json()['proxy']}) respone = requests.get('https://www.jianshu.com/', headers=header) print(respone.text)
超时设置,异常处理,上传文件
# 超时:
import requests respone=requests.get('https://www.baidu.com',timeout=0.0001) print(respose.text)# 异常处理:
import requests from requests.exceptions import * #可以查看requests.exceptions获取异常类型 try: r=requests.get('http://www.baidu.com',timeout=0.00001) except RequestException: print('Error') # except ConnectionError: #网络不通 # print('-----') # except Timeout: # print('aaaaa')# 上传文件:
import requests files={'file':open('a.jpg','rb')} respone=requests.post('http://httpbin.org/post',files=files) print(respone.status_code)