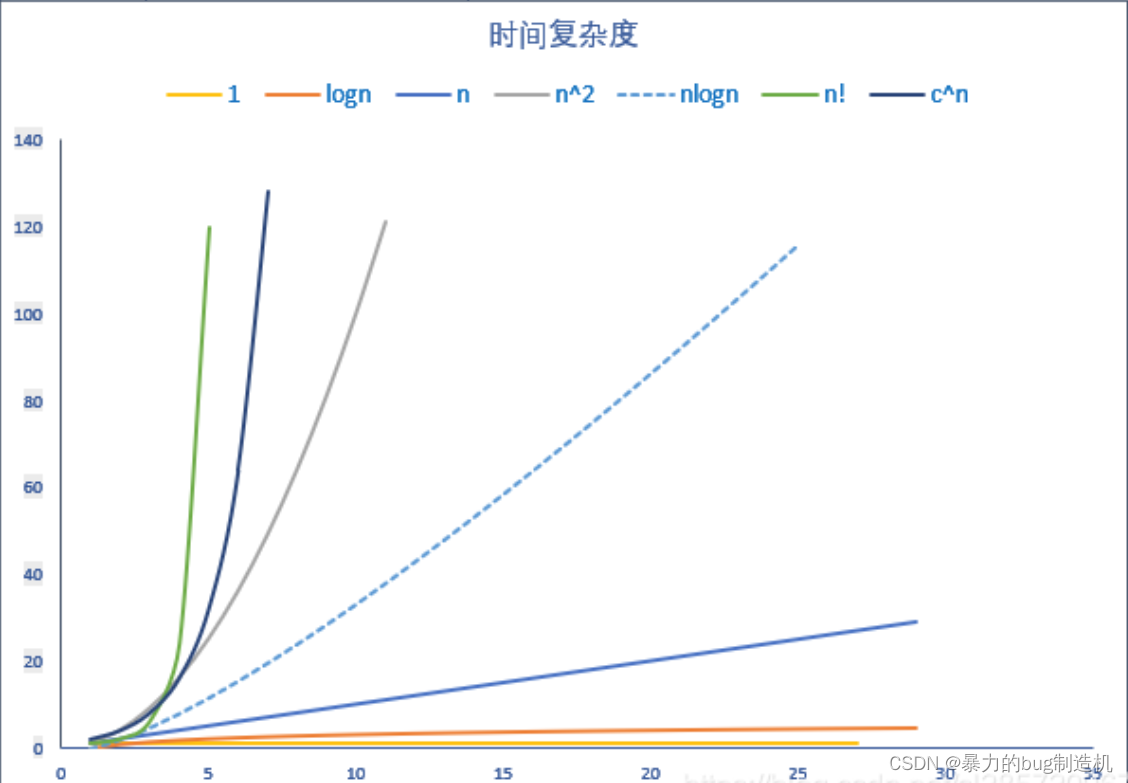
贪心算法
贪心(Greedy)算法的原理很容易理解:把整个问题分解成多个步骤,在每个步骤都选取当前步骤的最优方案,直到所有步骤结束;每个步骤都不考虑对后续步骤的影响,在后续步骤中也不再回头改变前面的选择。
贪心算法虽然简单,但它有广泛的应用。例如图论中的最小生成树(Minimal Spanning Tree,MST)算法、单源最短路径算法(Dijkstra)都是贪心算法的典型应用。
贪心算法的主要问题是不一定能得到最优解,因为局部最优并不总是能导致全局最优,而竞赛题基本都是求全局最优解的。
一个问题是否能用贪心算法求解,有时很容易判断,有时不那么容易判断。例如常见的最少硬币支付问题,能否用贪心算法求解取决于硬币的面值。
最少硬币支付问题:
假设有3种面值的硬币,分别是1元、2元、5元,数量不限;需要支付M元,问怎么支付,才能使硬币数量最少?
用贪心算法求解,第一步先用面值最大的5元硬币,第二步用面值第二大的2元硬币,最后用面值最小的1元硬币。在这个解决方案中,硬币数量总数是最少的,使用贪心算法得到的结果是全局最优的。但是如果是其他面值的硬币,则使用贪心算法就不一定能得到全局最优解。
例如,假设硬币面值有5种,分别是1元、2元、4元、5元、6元。要支付M = 9元,如果用贪心算法,则答案是6 + 2 + 1,需要3个硬币,而全局最优解是5 + 4,只需要两个硬币。

DP不是本文的讲解范围,这里只是拓展一下解题技巧。
贪心算法没有固定的算法框架,关键是如何选择贪心策略。贪心策略必须具备无后效性,即某个状态以后的过程不会影响以前的状态,只与当前状态有关。贪心题是蓝桥杯大赛的常见题型。有的贪心题考验参赛人员的思维能力,有的贪心题结合了其他算法,贪心题可能很难。下面通过一些例题介绍一下贪心算法的应用。
例题1.翻硬币

先分析翻动的具体操作。
(1)只有一个硬币不同。例如位置a的硬币不同,那么翻动它时,会改变与它相邻的硬币b,现在变成了硬币b不同,回到了“只有一个硬币不同”的情况。也就是说,如果只有一个硬币不同,无法求解。
(2)有两个硬币不同。这两个硬币位于任意两个位置,从左边的不同硬币开始翻动,一直翻动到右边的不同硬币,结束。
(3)有3个硬币不同。左边两个不同硬币,可以用操作(2)完成翻动;但是最后一个硬币需要使用操作(1),无法完成。
总结这些操作,得到以下结论。
(1)有解的条件。初始字符串s和目标字符串t必定有偶数个字符不同。
(2)贪心操作。从头开始遍历字符串,遇到不同的字符就翻动,直到最后一个字符。下面证明这个贪心操作是局部最优也是全局最优。
代码:
#include<bits/stdc++.h>
using namespace std;
int main() {
string s,t;
cin >> s >> t;
int ans=0;
for(int i=0; i<s.length(); i++)
if(s[i] != t[i]) {
// s[i] = (s[i] =='*'? 'o': '*'); //多余,我们求的是最小操作步数
s[i+1] = (s[i+1]== '*'? 'o': '*'); //翻下一个就行了
ans++;
}
cout << ans;
}字符串函数
求解字符串的题目,最好使用系统提供的库函数。本节将介绍C++常用的字符串函数:
代码(讲解在注释中):
#include<bits/stdc++.h>
using namespace std;
int main() {
string str ="123456789abcdefghiaklmn";
for(int i=0; i<10; i++) cout<<str[i]<< " "; //把str看成一个字符串数组
cout << endl;
//find()函数
cout<<"123的位置:"<<str.find("123")<<endl; //输出:123的位置: 0
cout<<"34在str[2]到str[n-1]中的位置:"<<str.find("34",2)<<endl; //输出:34在str[2]到str[n-1]中的位置: 2
cout<<"ab在str[0]到str[12]中的位置:"<<str.rfind("ab",12)<<endl;
//输出:ab在str[0]到str[12]中的位置: 9
//substr()函数
cout<<"str[3]及以后的子串:"<<str.substr(3)<<endl;
//输出:str[3]及以后的子串:456789abcdefghiaklmn
cout<<"从str[2]开始的4个字符:"<<str.substr(2,4)<<endl; //若小于限制长度,则报错
//输出:从str[2]开始的4个字符:3456
//find()函数
str.replace(str.find("a"), 5, "@#"); //用str替换指定字符串从起始位置pos开始长度为len的字符 string& replace (size_t pos, size_t len, const string& str);
cout<<str<<endl; //输出:123456789@#fghiaklmn
//insert()函数
str.insert(2, "***");
cout<<"从2号位置插入: "<<str<<endl; //输出:从2号位置插入:12***3456789@#fghiaklmn
//添加字符串:append()函数
str.append("$$$");
cout<<"在字符串str后面添加字符串: "<<str<<endl; //输出:在字符串str后面添加字符串:12***3456789@#fghiaklmn$$$
//求字符串长度
cout<<str.size()<<endl;//26
cout<<str.length()<<endl;//26
//交换字符串:swap()函数
string str1="aaa",str2="bbb";
swap(str1, str2);
cout<<str1<< " " <<str2<<endl;//bbb aaa
//字符串比较:compare()函数,若相等,则输出0;若不等,则输出1
cout<<str1.compare(str2)<<endl; //1
if(str1==str2) cout <<"=="; //直接比较也行
if(str1!=str2) cout <<"!="; //!=
return 0;
}例题1.标题统计

分析:用string定义变量,一个一个地读入字符串,字符串之间是用空格分开的。
代码:
#include<bits/stdc++.h>
using namespace std;
int main() {
string s;
int ans=0;
while(cin >> s) ans += s.size();
cout << ans;
return 0;
}朴素模式匹配算法
模式匹配(Pattern Matching)问题:在一篇长度为n的文本S中,查找某个长度为m的关键词P,称S为母串,P为模式串。
P可能出现多次,都需要找到。例如在S = abcxyz123bqrst12dg123gdsa中查找P=123,P出现了两次。
最优的模式匹配算法复杂度是什么?由于至少需要检索文本S的n个字符和关键词P的m个字符,所以复杂度至少是O(m + n)。
最简单的是朴素模式匹配算法,这是一种暴力法,从S的第1个字符开始,逐个匹配P的每个字符,如果发现不同,就从S的下一个字符重新开始匹配。
例如S =abcxyz123,P = 123。第1轮匹配:比较S[0]~S[2]= abc和P[0]~P[2]= 123。发现第1个字符就不同,即P[0]≠S[0],这种情况称为“失配”,后面的P[1]、P[2]就不用比较了,如图9.1所示。

第2轮匹配:S往后移一个字符,比较S[1]~S[3]= bcx和P[0]~P[2]=123。发现P的第1个字符与S的第2个字符不同,即P[0]≠S[1],后面的P[1]、P[2]就不用比较了,如图9.2所示。

继续匹配,直到第7轮匹配,终于在S中完全匹配了一个P,如图9.3所示。

一共比较了6 + 3 = 9次:前6轮每次只比较了P的第1个字符,第7轮比较了P的3个字符。
这个例子比较特殊,因为P和S的字符基本都不一样。在每轮匹配时,往往第1个字符就不同,用不着继续匹配P后面的字符。计算复杂度差不多是O(n),这已经是字符串匹配能达到的最优复杂度了。所以,如果字符串S、P符合这样的特征,暴力法是很好的选择。
但是如果情况很“恶劣”,例如P的前m−1个都容易找到匹配,只有最后一个不匹配,那么复杂度就退化成O(nm)。例如S =aaaaaaaab,P =aab。
第1轮匹配:比较S[0]~S[2]=aaa和P[0]~P[2]=aab,前两个字符相同,第3个字符不同,即S[2]≠P[2],共比较了3次。i是指向S的指针,j是指向P的指针,在i=2、j=2处失配,如图9.4所示。

第2轮匹配:让i回溯到1,j回溯到0,重新开始比较S[1]~S[3]= aaa和P[0]~P[2]=aab,如图9.5所示。发现S[3]≠P[2],共比较了3次,在i=3、j=2处失配。

……
……
第7轮匹配:在S中完全匹配了一个P,如图9.6所示。

这7轮匹配共比较7×3 = 21次,远远超过上面例子中的9次。有没有更好的方法?后面介绍的KMP算法是在任何情况下都稳定、高效的算法。
这里先把朴素模式匹配算法的代码放在这参考:
int ViolentMatch(string text, string pattern) //text是文本串,pattern是关键字
{
int tLen = text.size(); //获取长度
int pLen = pattern.size();
int i = 0;
int j = 0;
while (i < tLen && j < pLen) //开始匹配
{
if (text[i] == pattern[j])
{
//如果当前字符匹配成功(即text[i] == pattern[j]),匹配下一个字符
i++;
j++;
}
else //如果当前字符匹配失败,pattern从头开始匹配
{
i = i - j + 1;
j = 0;
}
}
if (j == pLen) //当pattern全部匹配成功,返回匹配位置
return i - j;
else
return -1;
}
KMP算法
对于模式匹配,目前所学的最简单的是BF算法,即偏向于“暴力”匹配的方法。另外一种就是较为复杂KMP算法了。而俩者的区别在于:BF算法是时间复杂度相对高的,KMP则可以理解为用空间换时间。
KMP算法: KMP只需要将j值模式串中j的位置回溯到next[j]位,而免除了前面不需要的匹配,以此来换取时间。
相比一个一个比较,而KMP则在此基础上更加的简便了。
现在一步一步模拟一下KMP匹配的过程:
现在要在text中找temp:
string text = "ABAABAABBABAAABAABBABAAB";
string temp = "ABAABBABAAB";next[] = {0,0,1,1,2,0,1,2,3,4,5} //next数组已经给出
再给你一个公式:
移动位数 = 已匹配值 - 部分匹配值
(说人话:移动位数 = 已匹配值 - 最大公共元素长度) ---在匹配的过程中就会明白该怎么移动
1.第一步匹配与暴力没有区别,找到第一个都是A的点开始匹配:

可以看到,我们匹配到第6位的时候,匹配失败了,我们直接中断本次匹配
然后移动 已匹配值 - 最大公共元素长度
我们匹配了5位,对应的next[5]=2,那么我们就应该移动 5 - 2 =3位。
很好,我们现在又可以进行匹配了,匹配到第11位时,又匹配失败了,我们同样中断本次匹配并进行移动操作。如图:

继续套公式,我们需要移动 已匹配值 - 最大公共元素长度
我们匹配了10位,对应的next[10] = 4,那么我们移动10-4=6位。

如法炮制,我们继续进行匹配,匹配到第5位的时候又出错了,继续进行处理,移动 已匹配值 - 最大公共元素长度
我们匹配了4位,对应next[4] = 1,我们需要移动4 - 1 = 3 位。如图:

这次只匹配到了1位,移动已匹配值 - 最大公共元素长度,这次匹配了1位,对应next[1] = 0,我们要移动 1 - 0 = 1 位。

总结:在kmp算法中最重要的部分就是next[] 数组。它存放的是我们当前位置下的最大公共元素长度。
以待匹配文本"ABCDABD"来举例:
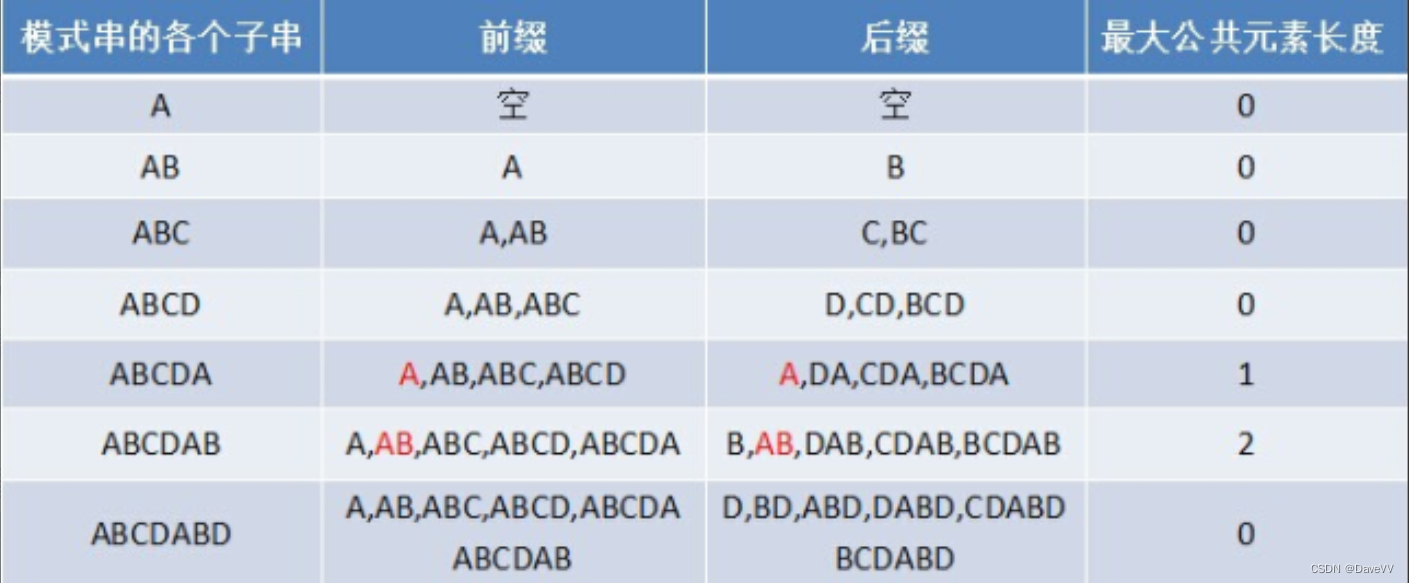
前缀后缀就是:把字符串的子串分解出来,从前到后(前缀),从后到前(后缀)的一个排列
!注意:(前缀得不到最后一位,后缀得不到最前一位)。
然后我们找出前缀和后缀中相同的子排列,将它们的长度保存到字符串子串的长度下的下标中去。
下面是实现代码:
#include <bits/stdc++.h>
using namespace std;
//在关键字中记录与前缀匹配的组合,记录在next数组
void make_next(string pattern, int *next)
{
int q, k; //q是匹配的位置 k是记录前缀开始的地方
int m = pattern.size(); //关键字的长度
next[0] = 0;
for (q = 1, k = 0; q < m; q++)
{
while (k > 0 && pattern[q] != pattern[k])
{
k = next[k - 1];
}
if (pattern[q] == pattern[k])
{
k++;
}
next[q] = k; //用于记录关键字中与前缀匹配的组合的位置
}
}
//kmp算法
int kmp(string text, string pattern, int *next)
{
int n = text.size(); //文本串的长度
int m = pattern.size(); //关键字的长度
make_next(pattern, next); //在关键字中记录与前缀匹配的组合,记录在next数组
int i, q;
for (i = 0, q = 0; i < n; i++)
{ //i --> text, q --> pattern
while (q > 0 && pattern[q] != text[i])
{
q = next[q - 1];
}
if (pattern[q] == text[i])
{
q++;
}
if (q == m)
{
return i - q + 1;
}
}
return -1; //整个文本串找完都没有找到字符串,返回-1
}
int main()
{
string text = "ABAABAABBABAAABAABBABAAB";
string temp = "ABAABBABAAB";
int len = temp.size();
int arr[len+1];
make_next(temp, arr);
cout << kmp(text, temp, arr);//13
return 0;
}