一.基础部分
go语言的值类型和引用类型?
值类型:int、float、bool、string和数组这些类型都属于值类型。
值类型的变量直接指向存在内存中的值,值类型的变量的值存储在栈中。当使用 = 将一个变量的值赋给另一个变量时,如 j = i ,实际上是在内存中将 i 的值进行了拷贝。可以通过 &i 获取变量 i 的内存地址,值拷贝。
引用类型:切片(slice)类型, map类型 ,管道(channel)类型 , 接口(interface)类型。
引用类型拥有更复杂的存储结构:(1)分配内存 (2)初始化
go struct 能不能比较
需要具体情况具体分析,如果struct中含有不能被比较的字段类型,就不能被比较,如果struct中所有的字段类型都支持比较,那么就可以被比较。
不可被比较的类型:
- slice,因为slice是引用类型,除非是和nil比较
- map,和slice同理,如果要比较两个map只能通过循环遍历实现
- 函数类型
其他的类型都可以比较。
还有两点值得注意:
- 结构体之间只能比较它们是否相等,而不能比较它们的大小。
- 只有所有属性都相等而属性顺序都一致的结构体才能进行比较。
为什么引用类型不能比较 ?
引用类型,如果你要比较的话,是想去比较他的值还是说他的地址?这就相当于在比较的时候会有歧义产生,因此 Go 从语言层面上直接杜绝了引用类型的比较;
就像两个 slice,如果要去实现他们的 == 比较,你是想去比较 len 是否相等?还是 cap 是否相同?还是底层数组的地址是否相同?还是每个元素的值是否相同?
所以说歧义很大的,就干脆不支持比较了。
当然引用类型可以和 nil 进行 比较
golang 中 make 和 new 的区别?
共同点:
- 给变量分配内存;
- make 与 new对堆栈分配处理是相同的,编译器优先进行逃逸分析,逃逸的才分配到堆上
不同点:
- 作用变量类型不同,new给string、int、数组 分配内存,make给切片、map、channel分配内存;
- 返回类型不一样,new 返回指向变量的指针,make 返回变量本身;
- new 分配的空间被清零。make 分配空间后,会进行初始化;
for range 的时候它的地址会发生变化么?
在 for a,b := range c 遍历中, a 和 b 在内存中只会存在一份,即之后每次循环时遍历到的数据都是以值覆盖的方式赋给 a 和 b,a,b 的内存地址始终不变。
由于有这个特性,for 循环里面如果开协程,不要直接把 a 或者 b 的地址传给协程。
解决办法:在每次循环时,创建一个临时变量。
rune 类型
rune 是类型 int32 的别名,在所有方面都等价于它,用来区分字符值跟整数值。
在 Go 语言中,字符可以被分成两种类型处理:
- 对占 1 个字节的英文类字符,可以使用 byte(或者unit8);
- 对占 1 ~ 4 个字节的其他字符,可以使用 rune(或者int32),如中文、特殊符号等。

s := "Go语言编程"
// byte
fmt.Println([]byte(s)) // 输出:[71 111 232 175 173 232 168 128]
// rune
fmt.Println([]rune(s)) // 输出:[71 111 35821 35328]
反射
关于反射(reflect )在 Golang 中文标准库中是这样介绍的:
reflect 包实现了运行时反射,允许程序操作任意类型的对象。
典型用法是用静态类型 interface{} 保存一个值,然后
- 通过调用 TypeOf 获取其动态类型信息,该函数返回一个Type类型值。
- 调用 ValueOf 函数返回一个 Value 类型值,该值代表运行时的数据。
- Zero 接受一个 Type 类型参数并返回一个代表该类型零值的 Value 类型值。
上面提到的 reflect.TypeOf 和 reflect.ValueOf 函数就能完成这里的转换,如果我们认为 Go 语言的类型和反射类型处于两个不同的『世界』,那么这两个函数就是连接这两个世界的桥梁。

package main
import (
"fmt"
"reflect"
)
func main() {
author := "draven"
fmt.Println("TypeOf author:", reflect.TypeOf(author))
fmt.Println("ValueOf author:", reflect.ValueOf(author))
}
// 结果
// TypeOf author: string
// ValueOf author: draven
反射优点:
- 反射就是在程序运行的过程中,可以对一个未知类型的数据进行操作的过程
- 可以减少重复代码
缺点:
- 反射会消耗性能,使程序运行缓慢
调用函数传入结构体时,应该传值还是指针?
go 里面只存在只存在值传递(要么是该值的副本,要么是指针的副本),不存在引用传递。之所以对于引用类型的传递可以修改原内容数据,是因为在底层默认使用该引用类型的指针进行传递,但是也是使用指针的副本,依旧是值传递。
值类型:int、float、bool、string和数组这些类型都属于值类型。
值类型的变量直接指向存在内存中的值,值类型的变量的值存储在栈中。当使用 = 将一个变量的值赋给另一个变量时,如 j = i ,实际上是在内存中将 i 的值进行了拷贝。可以通过 &i 获取变量 i 的内存地址,值拷贝。
引用类型:特指 slice、map、channel 这三种预定义类型。
引用类型拥有更复杂的存储结构:(1)分配内存 (2)初始化
Go 的 select 底层数据结构和一些特性?
go 的 select 为 golang 提供了多路 IO 复用机制,和其他 IO 复用一样,用于检测是否有读写事件是否 ready。
select 结构组成主要是由 case 语句和执行的函数组成 select 实现的多路复用是:每个线程或者进程都先到注册和接受的 channel(装置)注册,然后阻塞,然后只有一个线程在运输,当注册的线程和进程准备好数据后,装置会根据注册的信息得到相应的数据。
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func1 () {
time.Sleep(time.Second)
ch1 <- 1
}()
go func2 () {
ch2 <- 3
}()
select {
case i := <-ch1:
fmt.Printf("从ch1读取了数据%d", i)
case j := <-ch2:
fmt.Printf("从ch2读取了数据%d", j)
}
}
select 的特性
1)select 操作至少要有一个 case 语句,出现读写 nil 的 channel 该分支会忽略,在 nil 的 channel 上操作则会报错。
2)select 仅支持管道,而且是单协程操作。
3)每个 case 语句仅能处理一个管道,要么读要么写。
4)多个 case 语句的执行顺序是随机的。
5)存在 default 语句,select 将不会阻塞,但是存在 default 会影响性能。
6)select 是异步阻塞的
7)对于空的select{},会引起死锁
select 的场景
- 竞争选举
这个是最常见的使用场景,多个通道,有一个满足条件可以读取,就可以“竞选成功”
select {
case i := <-ch1:
fmt.Printf("从ch1读取了数据%d", i)
case j := <-ch2:
fmt.Printf("从ch2读取了数据%d", j)
case m := <- ch3
fmt.Printf("从ch3读取了数据%d", m)
...
}
- 超时处理(保证不阻塞)
因为select是阻塞的,我们有时候就需要搭配超时处理来处理这种情况,超过某一个时间就要进行处理,保证程序不阻塞。
select {
case str := <- ch1
fmt.Println("receive str", str)
case <- time.After(time.Second * 5):
fmt.Println("timeout!!")
}
- 阻塞main函数
有时候我们会让main函数阻塞不退出,如http服务,我们会使用空的select{}来阻塞main goroutine
package main
import (
"fmt"
"time"
)
func main() {
bufChan := make(chan int)
go func() {
for{
bufChan <-1
time.Sleep(time.Second)
}
}()
go func() {
for{
fmt.Println(<-bufChan)
}
}()
select{}
}
context 结构是什么样的?context 使用场景和用途?
Go 1.7 标准库引入 context,中文译作“上下文”,准确说它是 goroutine 的上下文,包含 goroutine 的运行状态、环境、现场等信息。
Go 的 Context 的数据结构包含 Deadline,Done,Err,Value
context 主要用来
- 在 goroutine 之间传递上下文信息,包括:取消信号、超时时间、截止时间、k-v 等
- 上下文控制
- 多个 goroutine 之间的数据交互等
- 超时控制:到某个时间点超时,过多久超时

在 Go context 用法中,我们常常将其与 select 关键字结合使用,用于监听其是否结束、取消等。
演示代码:
func main() {
parentCtx := context.Background()
ctx, cancel := context.WithTimeout(parentCtx, 1*time.Millisecond)
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err())
}
}
// context deadline exceeded
我们通过调用标准库 context.WithTimeout 方法针对 parentCtx 变量设置了超时时间,并在随后调用 select-case 进行 context.Done 方法的监听,最后由于达到了截止时间。因此逻辑上 select 走到了 context.Err 的 case 分支,最终输出 context deadline exceeded。
Go语言中的单引号、双引号和反引号
- 单引号
单引号在go语言中表示golang中的rune(int32)类型,单引号里面是单个字符,对应的值为改字符的ASCII值。
func main() {
a := 'A'
fmt.Println(a)
}
// 输出:
// 65
- 双引号
在 go 语言中双引号里面可以是单个字符也可以是字符串,双引号里面可以有转义字符,如\n、\r等,对应 go 语言中的 string类 型。
func main() {
a := "Hello golang\nI am random_wz."
fmt.Println(a)
}
// 输出:
// Hello golang
// I am random_wz.
- 反引号
反引号中的字符表示其原生的意思,在单引号中的内容可以是多行内容,不支持转义。
func main() {
a := `Hello golang\n:
I am random_wz.
Good.`
fmt.Println(a)
}
// 输出:
// Hello golang\n:
// I am random_wz.
// Good.
可以看到 \n 并没有被转义,而是被直接作为字符串输出。
二. 数组和切片
数组和切片的区别
相同点:
- 只能存储一组相同类型的数据结构
- 都是通过下标来访问,并且有容量长度,长度通过 len 获取,容量通过 cap 获取
- 函数传递中,数组切片都是值传递。
区别:
- 数组是定长,访问和复制不能超过数组定义的长度,否则就会下标越界,切片长度和容量可以自动扩容
- 数组是值类型,切片是引用类型,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是这底层数组存储数据,所以修改切片的时候修改的是底层数组中的数据。切片一旦扩容,指向一个新的底层数组,内存地址也就随之改变
- 定义方式不一样 、初始化方式不一样,数组需要指定大小,大小不改变
数组的定义
var a1 [3]int
var a2 [...]int{1,2,3}
切片的定义
var a1 []int
var a2 :=make([]int,3,5)
数组的初始化
a1 := [...]int{1,2,3}
a2 := [5]int{1,2,3}
切片的初始化
b:= make([]int,3,5)
Go 的 slice 底层数据结构和一些特性?
Go 的 slice 底层数据结构是由一个 array 指针指向底层数组,len 表示切片长度,cap 表示切片容量。slice 的主要实现是扩容:
- 对于 append 向 slice 添加元素时,假如 slice 容量够用,则追加新元素进去,slice.len++,返回原来的 slice。
- 当原容量不够,则 slice 先扩容,扩容之后 slice 得到新的 slice,将元素追加进新的 slice,slice.len++,返回新的 slice。
对于切片的扩容规则
- 当切片比较小时(容量小于 1024),则采用较大的扩容倍速进行扩容(新的扩容会是原来的 2 倍),避免频繁扩容,从而减少内存分配的次数和数据拷贝的代价。
- 当切片较大的时(原来的 slice 的容量大于或者等于 1024),采用较小的扩容倍速(新的扩容将扩大大于或者等于原来 1.25 倍),主要避免空间浪费
数组是如何实现用下标访问任意元素的
例如: a := [10]int{0}
计算机给数组a,分配了一组连续的内存空间。
比如内存块的首地址为 base_address=1000。
当计算给每个内存单元分配一个地址,计算机通过地址来访问数据。当计算机需要访问数组的某个元素的时候,会通过一个寻址公式来计算存储的内存地址。
三. map
Go map 的底层实现 ?

// Go map的一个header结构
type hmap struct {
count int // map的大小. len()函数就取的这个值
flags uint8 //map状态标识
B uint8 // 可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子即:map长度=6.5*2^B
//B可以理解为buckets已扩容的次数
noverflow uint16 // 溢出buckets的数量
hash0 uint32 // hash 种子
buckets unsafe.Pointer //指向最大2^B个Buckets数组的指针. count==0时为nil.
oldbuckets unsafe.Pointer //指向扩容之前的buckets数组,并且容量是现在一半.不增长就为nil
nevacuate uintptr // 搬迁进度,小于nevacuate的已经搬迁
extra *mapextra // 可选字段,额外信息
}
//额外信息
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
//在编译期间会产生新的结构体,bucket
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}
hmap:
buckets中包含了哈希中最小细粒度单元bucket桶,数据通过hash函数均匀的分布在各个bucket中,buckets这个参数,它存储的是指向buckets数组的一个指针,当bucket(桶为0时)为nil。我们可以理解为,hmap指向了一个空bucket数组
bmap(bucket)
bucket(桶),每一个bucket最多放8个key和value,最后由一个overflow字段指向下一个bmap,注意key、value、overflow字段都不显示定义,而是通过maptype计算偏移获取的。
- 它的tophash 存储的是哈希函数算出的哈希值的高八位。是用来加快索引的。因为把高八位存储起来,这样不用完整比较key就能过滤掉不符合的key,加快查询速度当一个哈希值的高8位和存储的高8位相符合,再去比较完整的key值,进而取出value。
- 第二部分,存储的是key 和value,就是我们传入的key和value,注意,它的底层排列方式是,key全部放在一起,value全部放在一起。当key大于128字节时,bucket的key字段存储的会是指针,指向key的实际内容;value也是一样。
这样排列好处是在key和value的长度不同的时候,可以消除padding带来的空间浪费。并且每个bucket最多存放8个键值对。 - 第三部分,存储的是当bucket溢出时,指向的下一个bucket的指针

查找和插入
了解查找和插入过程,必须要先知道高位hash和低位hash值
哈希函数会将传入的key值进行哈希运算,得到一个唯一的值。
比如key1的hash值为:1123456789876543210 若将前八位hash值取出“11234567”部分就叫做“高位哈希值”。Go取后B位hash值为“低位hash值”
高位哈希值:是用来确定当前的bucket(桶)有没有所存储的数据的。
低位哈希值:是用来确定,当前的数据存在了哪个bucket(桶)
查找过程如下:
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 取哈希值高位在tophash数组中查询
- 如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行比较
- 当前bucket没有找到,则继续从下个overflow的bucket中查找。
- 如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
新元素插入过程如下:
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果没找到将key,将key插入
如图:
- 算出hash值2.取高低位hash值

- 通过低位hash找到对应bucket桶,再通过高位hash找到对应key值(此处可能有hash冲突和扩容),
**查找hahs冲突:**若找到对应高位hash值,但key值不一致,则线性向下或通过扩展指针(数组到末尾了)查找key值。
**插入hash冲突:**先查找,若存在重复高位hash值,则线性向下寻空位插入。若当前kv数组已满,则扩展bucket,插入

渐进式扩容
扩容的前提条件
为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。
触发扩容的条件有二个:
- 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
当溢出桶过多时: - 当 B < 15 时,如果overflow的bucket数量超过 2^B
- 当 B >= 15 时,overflow的bucket数量超过 2^15
简单来讲,新加入key的hash值后B位都一样,使得个别桶一直在插入新数据,进而导致它的溢出桶链条越来越长。如此一来,当map在操作数据时,扫描速度就会变得很慢。及时的扩容,可以对这些元素进行重排,使元素在桶的位置更平均一些。
等量扩容
由于map中不断的 put 和delete key,桶中可能会出现很多断断续续的空位,这些空位会导致连接的bmap溢出桶很长,导致扫描时间边长。这种扩容实际上是一种整理,把后置位的数据整理到前面。这种情况下,元素会发生重排,但不会换桶。

增量扩容
这种2倍扩容是由于当前桶数组确实不够用了,发生这种扩容时,元素会重排,可能会发生桶迁移。
当负载因子过大时,就新建一个 bucket,新的 bucket 长度是原来的 2 倍,然后旧 bucket 数据搬迁到新的 bucket。
考虑到如果 map 存储了数以亿计的 key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问 map 时都会触发一次搬迁,每次搬迁2 个键值对。
B=0,其溢出桶上限也为2^0 =1,触发条件进行buckets扩容,则根据后B位hash值进行元素重排

map 是否并发安全?
map默认是并发不安全的,同时对map进行并发读写时,程序会panic。
实现map线程安全,有两种方式:
- 使用读写锁map+sync.RWMutex
- 使用sync.Map
map 循环是有序的还是无序的?
无序的, map 因扩容⽽重新哈希时,各键值项存储位置都可能会发生改变,顺序自然也没法保证了,所以官方避免大家依赖顺序,直接打乱处理。就是 for range map 在开始处理循环逻辑的时候,就做了随机播种
golang 哪些类型可以作为map key
在golang规范中,可比较的类型都可以作为map key,包括:
- boolean 布尔值
- numeric 数字 包括整型、浮点型,以及复数
- string 字符串
- pointer 指针 两个指针类型相等,表示两指针指向同一个变量或者同为nil
- channel 通道 两个通道类型相等,表示两个通道是被相同的make调用创建的或者同为nil
- interface 接口 两个接口类型相等,表示两个接口类型 的动态类型 和 动态值都相等 或者 两接口类型 同为 nil
- structs、arrays 只包含以上类型元素
不能作为map key 的类型包括: - slices
- maps
- functions
map取一个key,然后修改这个值,原map数据的值会不会变化
map属于引用类型,所以取一个key,然后修改这个值,原map数据的值会发生变化
map 中删除一个 key,它的内存会释放么?
如果删除的元素是值类型,如int,float,bool,string以及数组和struct,map的内存不会自动释放
如果删除的元素是引用类型,如指针,slice,map,chan等,map的内存会自动释放,但释放的内存是子元素应用类型的内存占用
将map设置为nil后,内存被回收。
nil map 和空 map 有何不同?
nil map 未初始化
空 map 是长度为空
- 可以对未初始化的map进行取值,但取出来的东西是空:
var m1 map[string]string
fmt.Println(m1["1"])
- 不能对未初始化的map进行赋值,这样将会抛出一个异常:
var m1 map[string]string
m1["1"] = "1"
// panic: assignment to entry in nil map
- 通过fmt打印map时,空map和nil map结果是一样的,都为map[]。所以,这个时候别断定map是空还是nil,而应该通过map == nil来判断。
四. goroutine
为什么不要大量使用goroutine
大量创建goroutine,势必会消耗大量的系统资源(如内存、CPU等),从而可能导致系统崩溃。避免不必要的麻烦,应该合理创建goroutine的数量。
多个 goroutine 对同一个 map 写会 panic,异常是否可以用 defer 捕获?
可以捕获异常,但是只能捕获一次,Go语言,可以使用多值返回来返回错误。不要用异常代替错误,更不要用来控制流程。在极个别的情况下,才使用Go中引入的 Exception 处理:defer, panic, recover Go中,对异常处理的原则是:多用error包,少用panic
defer func() {
if err := recover(); err != nil {
// 打印异常,关闭资源,退出此函数
fmt.Println(err)
}
}()
2 个协程交替打印字母和数字
package main
import (
"fmt"
)
func main() {
limit := 26
numChan := make(chan int, 1)
charChan := make(chan int, 1)
mainChan := make(chan int, 1)
charChan <- 1
go func() {
for i := 0; i < limit; i++ {
<-charChan
fmt.Printf("%c\n", 'a'+i)
numChan <- 1
}
}()
go func() {
for i := 0; i < limit; i++ {
<-numChan
fmt.Println(i)
charChan <- 1
}
mainChan <- 1
}()
<-mainChan
close(charChan)
close(numChan)
close(mainChan)
}
为什么需要协程池?
虽然go语言自带“高并发”的标签,其并发编程就是由groutine实现的,因其消耗资源低(大约2KB左右,线程通常2M左右),性能高效,开发成本低的特性而被广泛应用到各种场景,例如服务端开发中使用的HTTP服务,在golang net/http包中,每一个被监听到的tcp链接都是由一个groutine去完成处理其上下文的,由此使得其拥有极其优秀的并发量吞吐量。
但是,如果无休止的开辟Goroutine依然会出现高频率的调度Groutine,那么依然会浪费很多上下文切换的资源,导致做无用功。所以设计一个Goroutine池限制Goroutine的开辟个数在大型并发场景还是必要的。
简单的协程池
package main
import (
"fmt"
"time"
)
/* 有关Task任务相关定义及操作 */
//定义任务Task类型,每一个任务Task都可以抽象成一个函数
type Task struct {
f func() error //一个无参的函数类型
}
//通过NewTask来创建一个Task
func NewTask(f func() error) *Task {
t := Task{
f: f,
}
return &t
}
//执行Task任务的方法
func (t *Task) Execute() {
t.f() //调用任务所绑定的函数
}
/* 有关协程池的定义及操作 */
//定义池类型
type Pool struct {
EntryChannel chan *Task //对外接收Task的入口
worker_num int //协程池最大worker数量,限定Goroutine的个数
JobsChannel chan *Task //协程池内部的任务就绪队列
}
//创建一个协程池
func NewPool(cap int) *Pool {
p := Pool{
EntryChannel: make(chan *Task),
worker_num: cap,
JobsChannel: make(chan *Task),
}
return &p
}
//协程池创建一个worker并且开始工作
func (p *Pool) worker(work_ID int) {
//worker不断的从JobsChannel内部任务队列中拿任务
for task := range p.JobsChannel {
//如果拿到任务,则执行task任务
task.Execute()
fmt.Println("worker ID ", work_ID, " 执行完毕任务")
}
}
//让协程池Pool开始工作
func (p *Pool) Run() {
//1,首先根据协程池的worker数量限定,开启固定数量的Worker,
// 每一个Worker用一个Goroutine承载
for i := 0; i < p.worker_num; i++ {
fmt.Println("开启固定数量的Worker:", i)
go p.worker(i)
}
//2, 从EntryChannel协程池入口取外界传递过来的任务
// 并且将任务送进JobsChannel中
for task := range p.EntryChannel {
p.JobsChannel <- task
}
//3, 执行完毕需要关闭JobsChannel
close(p.JobsChannel)
fmt.Println("执行完毕需要关闭JobsChannel")
//4, 执行完毕需要关闭EntryChannel
close(p.EntryChannel)
fmt.Println("执行完毕需要关闭EntryChannel")
}
//主函数
func main() {
//创建一个Task
t := NewTask(func() error {
fmt.Println("创建一个Task:", time.Now().Format("2006-01-02 15:04:05"))
return nil
})
//创建一个协程池,最大开启3个协程worker
p := NewPool(3)
//开一个协程 不断的向 Pool 输送打印一条时间的task任务
go func() {
for {
p.EntryChannel <- t
}
}()
//启动协程池p
p.Run()
}
五. channel
channel 的底层实现原理
channel主要用于进程内各 goroutine 间通信,如果需要跨进程通信,建议使用分布式系统的方法来解决。
chan数据结构:
type hchan struct {
qcount uint // 当前队列中剩余元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小
closed uint32 // 标识关闭状态
elemtype *_type // 元素类型
sendx uint // 队列下标,指示元素写入时存放到队列中的位置
recvx uint // 队列下标,指示元素从队列的该位置读出
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
lock mutex // 互斥锁,chan不允许并发读写
}
环形队列
chan内部实现了一个环形队列作为其缓冲区,队列的长度是创建chan时指定的。
下图展示了一个可缓存6个元素的channel示意图:

- dataqsiz指示了队列长度为6,即可缓存6个元素;
- buf指向队列的内存,队列中还剩余两个元素;
- qcount表示队列中还有两个元素;
- sendx指示后续写入的数据存储的位置,取值[0, 6);
- recvx指示从该位置读取数据, 取值[0, 6);
channel 读写原理
创建channel
创建channel的过程实际上是初始化hchan结构。其中类型信息和缓冲区长度由make语句传入,buf的大小则与元素大小和缓冲区长度共同决定。
创建channel的伪代码如下所示:
func makechan(t *chantype, size int) *hchan {
var c *hchan
c = new(hchan)
c.buf = malloc(元素类型大小*size)
c.elemsize = 元素类型大小
c.elemtype = 元素类型
c.dataqsiz = size
return c
}
向channel写数据
向一个channel中写数据简单过程如下:
- 如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G(队列),并把数据写入,最后把该G唤醒,结束发送过程;
- 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入 G,将当前G 加入 sendq,进入睡眠,等待被读goroutine 唤醒;
从channel读数据
从一个channel读数据简单过程如下:
- 如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束读取过程;
- 如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾部,把G唤醒,结束读取过程;
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
- 将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒;
关闭channel
关闭channel时会把recvq中的G全部唤醒,本该写入 G 的数据位置为nil。把 sendq 中的 G 全部唤醒,但这些 G 会 panic。
除此之外,panic出现的常见场景还有:
- 关闭值为 nil 的channel
- 关闭已经被关闭的 channel
- 向已经关闭的 channel 写数据
对已经关闭的channel进行读写操作会发生什么?
读已关闭的channel
读已经关闭的channel无影响。
如果在关闭前,通道内部有元素,会正确读到元素的值;如果关闭前通道无元素,则会读取到通道内元素类型对应的零值。
若遍历通道,如果通道未关闭,读完元素后,会报死锁的错误。
fatal error: all goroutines are asleep - deadlock!
写已关闭的通道
会引发panic: send on closed channel
关闭已关闭的通道
会引发panic: close of closed channel
总结: 对于一个已初始化,但并未关闭的通道来说,收发操作一定不会引发 panic。但是通道一旦关闭,再对它进行发送操作,就会引发 panic。如果我们试图关闭一个已经关闭了的通道,也会引发 panic。
有缓冲和无缓冲通道 channel
ch1:=make(chan int) 无缓冲
在向chan写入数据时,会阻塞当前协程,直到其他协程从该chan中读取了数据。
ch2:=make(chan int,1) 有缓冲
向chan写入数据时,若chan未满不会阻塞协程,满时阻塞线程直至缓冲有空间可写入。
ch <- x //发送语句
x = <-ch //接收语句
<-ch //接收语句,丢弃结果
通道类型的值本身就是并发安全的。
channel的应用场景
channel适用于数据在多个协程中流动的场景,有很多实际应用:
1.超时处理:
select {
case <-time.After(time.Second):
}
2.定时任务
select {
case <- time.Tick(time.Second)
}
3.解耦生产者和消费者
可以将生产者和消费者解耦出来,生产者只需要往channel发送数据,而消费者只管从channel中获取数据。
4.控制并发数
以爬虫为例,比如需要爬取1w条数据,需要并发爬取以提高效率,但并发量又不过过大,可以通过channel来控制并发规模,比如同时支持5个并发任务:
ch := make(chan int, 5)
for _, url := range urls {
go func() {
ch <- 1
worker(url)
<- ch
}
}
六. GPM
G 是 Goroutine 的缩写,相当于操作系统的进程控制块 (process control block)。它包含:函数执行的指令和参数,任务对象,线程上下文切换,字段保护,和字段的寄存器。
M 是一个线程,每个 M 都有一个线程的栈。
P (处理器,Processor) 是一个抽象的概念,不是物理上的CPU。当一个P有任务,需要创建或者唤醒一个系统线程去处理它队列中的任务。P决定同时执行的任务的数量,GOMAXPROCS 限制系统线程执行用户层面的任务的数量。
GO 调度器的调度过程:首先创建一个 G 对象,然后 G 被保存在 P 的本地队列或者全局队列(global queue)。这时 P 会唤醒一个 M 。P 按照它的执行顺序继续执行任务。M 寻找一个空闲的 P,如果找得到,将 G 与自己绑定。然后 M 执行一个调度循环:调用 G 对象 -> 执行 -> 清理线程 -> 继续寻找Goroutine。
在 M 的执行过程中,上下文切换随时发生。当切换发生,任务的执行现场需要被保护,这样在下一次调度执行可以进行现场恢复。M的栈保存在G对象中,只有现场恢复需要的寄存器(SP,PC等),需要被保存到G对象。
如果G对象还没有被执行,M可以将G重新放到P的调度队列,等待下一次的调度执行。当调度执行时,M可以通过G的vdsoSP, vdsoPC 寄存器进行现场恢复。
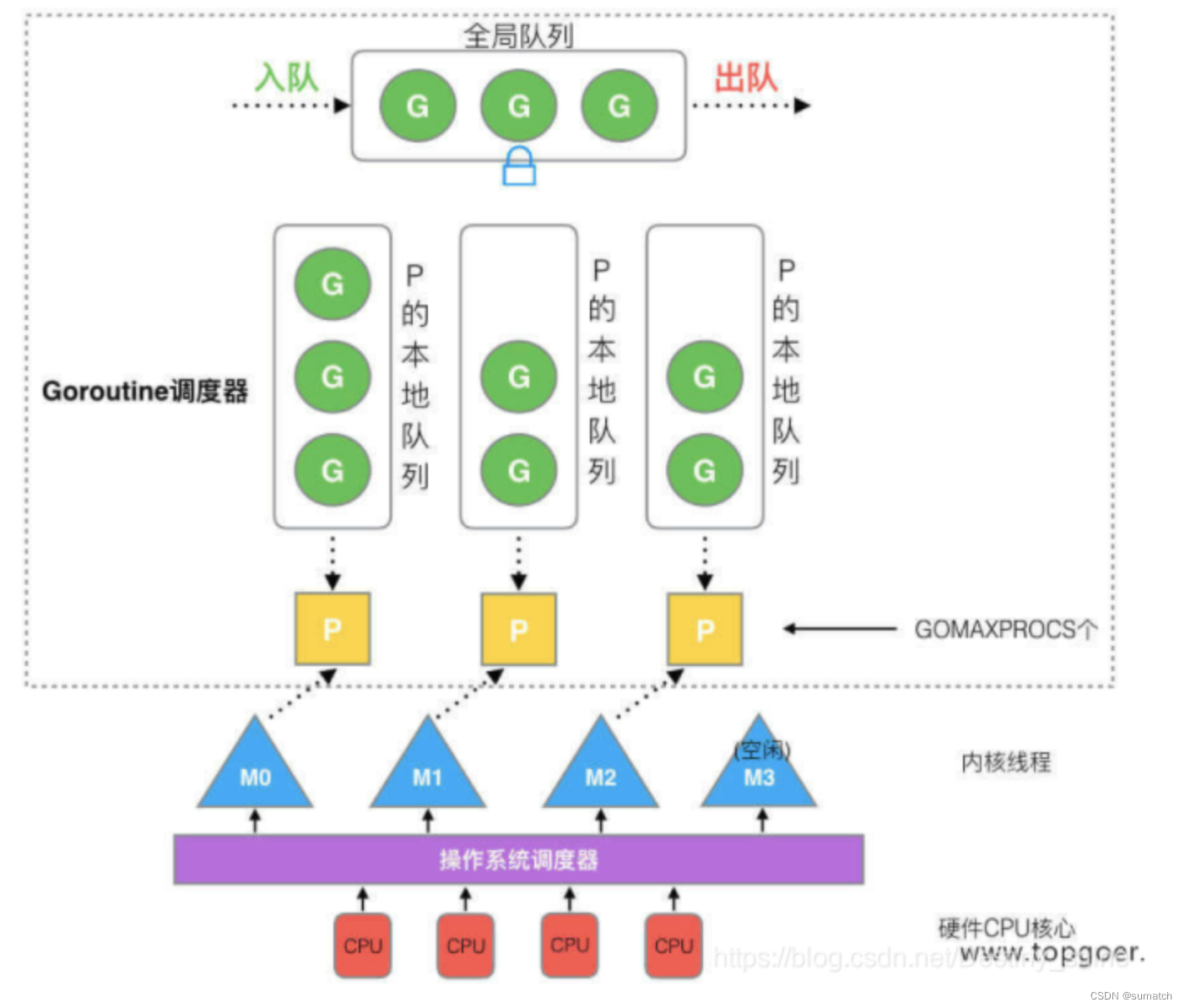
P队列 P有2种类型的队列:
本地队列:本地的队列是无锁的,没有数据竞争问题,处理速度比较高。
全局队列:是用来平衡不同的P的任务数量,所有的M共享P的全局队列。
线程清理 G的调度是为了实现P/M的绑定,所以线程清理就是释放P上的G,让其他的G能够被调度。
主动释放(active release):典型的例子是,执行G任务时,发生了系统调用(system call),这时M会处于阻塞(Block)状态。调度器会设置一个超时时间,来释放P。
被动释放(passive release):如果系统调用发生,监控程序需要扫描处于阻塞状态的P/M。 这时,超时之后,P资源会回收,程序被安排给队列中的其他G任务。
M 和 P 的数量问题?
p默认cpu内核数
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来
goroutine 的自旋占用资源如何解决
自旋锁是指当一个线程在获取锁的时候,如果锁已经被其他线程获取,那么该线程将循环等待,然后不断地判断是否能够被成功获取,直到获取到锁才会退出循环。
自旋的条件如下:
1)还没自旋超过 4 次,
2)多核处理器,
3)GOMAXPROCS > 1,
4)p 上本地 goroutine 队列为空。
mutex 会让当前的 goroutine 去空转 CPU,在空转完后再次调用 CAS 方法去尝试性的占有锁资源,直到不满足自旋条件,则最终会加入到等待队列里。
进程、线程、协程有什么区别?
进程:是应用程序的启动实例,每个进程都有独立的内存空间,不同的进程通过进程间的通信方式来通信。
线程:从属于进程,每个进程至少包含一个线程,线程是 CPU 调度的基本单位,多个线程之间可以共享进程的资源并通过共享内存等线程间的通信方式来通信。
协程:为轻量级线程,与线程相比,协程不受操作系统的调度,协程的调度器由用户应用程序提供,协程调度器按照调度策略把协程调度到线程中运行
Go 中主协程如何等待其余协程退出?
答:Go 的 sync.WaitGroup 是等待一组协程结束,sync.WaitGroup 只有 3 个方法
- Add()是添加计数
- Done()减去一个计数
- Wait()阻塞直到所有的任务完成。
- Go 里面还能通过有缓冲的 channel 实现其阻塞等待一组协程结束,这个不能保证一组 goroutine 按照顺序执行,可以并发执行协程。Go 里面能通过无缓冲的 channel 实现其阻塞等待一组协程结束,这个能保证一组 goroutine 按照顺序执行,但是不能并发执行。
七. 锁
channel 和锁的对比
并发问题可以用channel解决也可以用Mutex解决,但是它们的擅长解决的问题有一些不同。
channel关注的是并发问题的数据流动,适用于数据在多个协程中流动的场景。
而mutex关注的是是数据不动,某段时间只给一个协程访问数据的权限,适用于数据位置固定的场景。
Mutex 是悲观锁还是乐观锁?
答:Mutex是悲观锁
悲观锁: 当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制【Pessimistic Concurrency Control,缩写“PCC”,又名“悲观锁”】。
乐观锁: 乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量。
Mutex 有几种模式?
sync.Mutex 有两种模式,正常模式和饥饿模式。
正常模式: 等待的 goroutines 按照 FIFO(先进先出)顺序排队,但是 goroutine 被唤醒之后并不能立即得到 mutex 锁,它需要与新到达的 goroutine 争夺 mutex 锁。因为新到达的 goroutine 已经在 CPU上运行了,所以被唤醒的 goroutine 很大概率是争夺 mutex 锁是失败 的。出现这样的情况时候,被唤醒goroutine 需要排队在队列的前面。
如果被唤醒的 goroutine 有超过 1ms 没有获取到 mutex 锁,那么它就会变为饥饿模式。在饥饿模式中,mutex 锁直接从解锁的 goroutine 交给队列前面的 goroutine。新达到的 goroutine 也不会去争夺mutex 锁(即使没有锁,也不能去自旋),而是到等待队列尾部排队。正常模式有更好的性能,因为goroutine 可以连续多次获得 mutex 锁。
饥饿模式: 锁的所有权将从 unlock 的 gorutine 直接交给交给等待队列中的第一个。新来的 goroutine将不会尝试去获得锁,即使锁看起来是 unlock 状态,也不会去尝试自旋操作,而是放在等待队列的尾部。
mutex 切换回正常模式的条件:等待队列中的最后一个 goroutine 的等待时间不超过 1ms。
饥饿模式能阻止尾部延迟的现象,对于预防队列尾部 goroutine 一致无法获取mutex锁的问题。
八. 并发
怎么控制并发数?
第一,有缓冲通道
根据通道中没有数据时读取操作陷入阻塞和通道已满时继续写入操作陷入阻塞的特性,正好实现控制并发数量。
func main() {
count := 10 // 最大支持并发
sum := 100 // 任务总数
wg := sync.WaitGroup{} //控制主协程等待所有子协程执行完之后再退出。
c := make(chan struct{}, count) // 控制任务并发的chan
defer close(c)
for i:=0; i<sum;i++{
wg.Add(1)
c <- struct{}{} // 作用类似于waitgroup.Add(1)
go func(j int) {
defer wg.Done()
fmt.Println(j)
<- c // 执行完毕,释放资源
}(i)
}
wg.Wait()
}
第二,三方库实现的协程池
panjf2000/ants 或者 Jeffail/tunny
import (
"log"
"time"
"github.com/Jeffail/tunny"
)
func main() {
pool := tunny.NewFunc(10, func(i interface{}) interface{} {
log.Println(i)
time.Sleep(time.Second)
return nil
})
defer pool.Close()
for i := 0; i < 500; i++ {
go pool.Process(i)
}
time.Sleep(time.Second * 4)
}
九. GC
常见的垃圾回收算法:
引用计数: 对每个对象维护一个引用计数,当引用该对象的对象被销毁时,引用计数减1,当引用计数器为0时回收该对象。
优点:对象可以很快的被回收,不会出现内存耗尽或达到某个阀值时才回收。
缺点:不能很好的处理循环引用,而且实时维护引用计数,有也一定的代价。
代表语言:Python、PHP
标记-清除: 从根变量开始遍历所有引用的对象,引用的对象标记为"被引用",没有被标记的进行回收。
优点:解决了引用计数的缺点。
缺点:需要STW,即要暂时停掉程序运行。
代表语言:Golang(其采用三色标记法)
分代收集: 按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,而短的放入新生代,不同代有不能的回收算法和回收频率。
优点:回收性能好
缺点:算法复杂
代表语言: JAVA
Golang 三色标记法
- 初始状态下所有对象都是白色的。
- 从根节点开始遍历所有对象,把遍历到的对象变成灰色对象
- 遍历灰色对象,将灰色对象引用的对象也变成灰色,然后将遍历过的灰色对象变成黑色对象。
- 循环步骤3,直到灰色对象全部变黑色。
- 回收所有白色对象(垃圾)。
Go垃圾回收,什么时候触发
主动触发(手动触发),通过调用 runtime.GC 来触发GC,此调用阻塞式地等待当前GC运行完毕。
被动触发,分为两种方式:
1)使用步调(Pacing)算法,其核心思想是控制内存增长的比例,每次内存分配时检查当前内存分配量是否已达到阈值(环境变量GOGC):默认100%,即当内存扩大一倍时启用GC。即内存是上次清扫时的两倍时触发。
2)使用系统监控,当超过两分钟没有产生任何GC时,强制触发 GC。
十. 内存
谈谈内存泄漏,什么情况下内存会泄漏?怎么定位排查内存泄漏问题?
go中的内存泄漏一般都是goroutine泄漏,就是goroutine没有被关闭,或者没有添加超时控制,让goroutine一只处于阻塞状态,不能被GC。
内存泄露有下面一些情况
- 如果goroutine在执行时被阻塞而无法退出,就会导致goroutine的内存泄漏,一个goroutine的最低栈大小为2KB,在高并发的场景下,对内存的消耗也是非常恐怖的。
- 互斥锁未释放或者造成死锁会造成内存泄漏
- time.Ticker是每隔指定的时间就会向通道内写数据。作为循环触发器,必须调用stop方法才会停止,从而被GC掉,否则会一直占用内存空间。
- 字符串的截取引发临时性的内存泄漏
func main() {
var str0 = "12345678901234567890"
str1 := str0[:10]
}
- 切片截取引起子切片内存泄漏
func main() {
var s0 = []int{0,1,2,3,4,5,6,7,8,9}
s1 := s0[:3]
}
- 函数数组传参引发内存泄漏
【如果我们在函数传参的时候用到了数组传参,且这个数组够大(我们假设数组大小为100万,64位机上消耗的内存约为800w字节,即8MB内存),或者该函数短时间内被调用N次,那么可想而知,会消耗大量内存,对性能产生极大的影响,如果短时间内分配大量内存,而又来不及GC,那么就会产生临时性的内存泄漏,对于高并发场景相当可怕。】
排查方式: 一般通过 pprof 是 Go 的性能分析工具,在程序运行过程中,可以记录程序的运行信息,可以是 CPU 使用情况、内存使用情况、goroutine 运行情况等,当需要性能调优或者定位 Bug 时候,这些记录的信息是相当重要。
Go 内存分配

Golang 程序在启动时,会向操作系统申请一定区域的内存,分为栈(Stack)和堆(Heap)。
- 栈内存会随着函数的调用分配和回收;
- 堆内存由程序申请分配,由垃圾回收器(Garbage Collector)负责回收。
性能上,栈内存的使用和回收更迅速一些;
尽管Golang 的 GC 很高效,但也不可避免的会带来一些性能损耗。因此,Go 优先使用栈内存进行内存分配。在不得不将对象分配到堆上时,才将特定的对象放到堆中。
堆和栈都是编程语言里的虚拟概念,并不是说在物理内存上有堆和栈之分,两者的主要区别是栈是每个线程或者协程独立拥有的,从栈上分配内存时不需要加锁。而整个程序在运行时只有一个堆,从堆中分配内存时需要加锁防止多个线程造成冲突,同时回收堆上的内存块时还需要运行可达性分析、引用计数等算法来决定内存块是否能被回收,所以从分配和回收内存的方面来看栈内存效率更高。
1.因为栈比堆更高效,不需要 GC,因此 Go 会尽可能的将内存分配到栈上。
2.当分配到栈上可能引起非法内存访问等问题后,会使用堆,主要场景有:
- 当一个值可能在函数被调用后访问,这个值极有可能被分配到堆上。
- 当编译器检测到某个值过大,这个值会被分配到堆上。
- 当编译时,编译器不知道这个值的大小(slice、map…)这个值会被分配到堆上。
内存逃逸
1)本该分配到栈上的变量,跑到了堆上,这就导致了内存逃逸。
2)栈是高地址到低地址,栈上的变量,函数结束后变量会跟着回收掉,不会有额外性能的开销。
3)变量从栈逃逸到堆上,如果要回收掉,需要进行 gc,那么 gc 一定会带来额外的性能开销。编程语言不断优化 gc 算法,主要目的都是为了减少 gc 带来的额外性能开销,变量一旦逃逸会导致性能开销变大。
内存逃逸的情况如下:
1)方法内返回局部变量指针。
2)向 channel 发送指针数据。
3)在闭包中引用包外的值。
4)在 slice 或 map 中存储指针。
5)切片(扩容后)长度太大。
6)在 interface 类型上调用方法。
Channel 分配在栈上还是堆上?
Channel被设计用来实现协程间通信的组件,其作用域和生命周期不可能仅限于某个函数内部,所以golang直接将其分配在堆上。
哪些对象分配在堆上,哪些对象分配在栈上?
Go 通过编译阶段的逃逸分析来判断变量应该被分配到栈还是堆上,总结以下几点:
- 栈比堆更高效,不需要 GC,因此 Go 会尽可能的将内存分配到栈上。Go 的协程栈可以自动扩
容和缩容 - 当分配到栈上可能会引起非法内存访问等问题,则会使用堆,如:
- 当一个值在函数被调用后访问 (即作为返回值返回变量地址),这个值极有可能被分配到堆
上 - 当编译器检测到某个值过大,这个值被分配到堆上(栈扩容和缩容有成本)
- 当编译时,编译器不知道这个值的大小(slice、map等引用类型)这个值会被分配到堆上
- 当一个值在函数被调用后访问 (即作为返回值返回变量地址),这个值极有可能被分配到堆
最后,不要去猜值在哪,只有编译器和编译器开发者知道
介绍一下大对象小对象,为什么小对象多了会造成 gc 压力?
小于等于32k的对象就是小对象,其它都是大对象。一般小对象通过 mspan 分配内存;大对象则直接由 mheap 分配内存。通常小对象过多会导致GC三色法消耗过多的CPU。优化思路是,减少对象分配。
十一. defer
底层
每个 defer 语句都对应一个_defer 实例,多个实例使用指针连接起来形成一个单连表,保存在 gotoutine 数据结构中,每次插入_defer 实例,均插入到链表的头部,函数结束再一次从头部取出,从而形成后进先出的效果。
作用:
defer 延迟函数,释放资源,收尾工作;如释放锁、关闭文件、关闭链接、捕获panic;
避坑指南:defer函数紧跟在资源打开后面,否则defer可能得不到执行,导致内存泄露。
多个 defer 调用顺序是 后入先),defer 后的操作可以理解为压入栈中
返回机制
defer 可以修改返回值
defer、return、返回值三者的执行逻辑应该是:
return最先执行,return负责将结果写入返回值中;
接着defer开始执行一些收尾工作;
最后函数携带当前返回值(可能和最初的返回值不相同)退出。
无名返回值:
package main
import (
"fmt"
)
func a() int {
var i int
defer func() {
i++
fmt.Println("defer2:", i)
}()
defer func() {
i++
fmt.Println("defer1:", i)
}()
return i
}
func main() {
fmt.Println("return:", a())
}
// 结果:
// defer1: 1
// defer2: 2
// return: 0
解释:
返回值由变量 i 赋值,相当于返回值 = i = 0。第二个 defer 中 i++ = 1, 第一个 defer 中 i++ = 2,所以最终 i 的值是2。但是返回值已经被赋值了,即使后续修改 i 也不会影响返回值。最终返回值返回,所以 main 中打印 0。
有名返回值:
package main
import (
"fmt"
)
func b() (i int) {
defer func() {
i++
fmt.Println("defer2:", i)
}()
defer func() {
i++
fmt.Println("defer1:", i)
}()
return i //或者直接写成return
}
func main() {
fmt.Println("return:", b())
}
// 结果
// defer1: 1
// defer2: 2
// return: 2
解释:
这里已经指明了返回值就是i,所以后续对i进行修改都相当于在修改返回值,所以最终函数的返回值是2。
defer和recover捕获异常
Go程序抛出一个panic异常,在defer中通过recover捕获异常,然后处理
package main
import "fmt"
func test() {
//在函数退出前,执行defer
//捕捉异常后,程序不会异常退出
defer func() {
err := recover() //内置函数,可以捕捉到函数异常
if err != nil {
//这里是打印错误,还可以进行报警处理,例如微信,邮箱通知
fmt.Println("err错误信息:", err)
}
}()
//如果没有异常捕获,直接报错panic,运行时出错
num1 := 10
num2 := 0
res := num1 / num2
fmt.Println("res结果:", res)
}
func main() {
test()
fmt.Println("如果程序没退出,就走我这里")
}
defer用于关闭文件和互斥锁
关闭文件:
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.close()
return ReadAll()
}
关闭互斥锁
var mu sync.Mutex
var m = make(map[string]int)
func lookup(key string) int {
mu.Lock()
defer mu.Unlock()
return m[key]
}
调用os.Exit时defer不会被执行
func deferExit() {
defer func() {
fmt.Println("defer")
}()
os.Exit(0)
}
当调用 os.Exit() 方法退出程序时,defer 并不会被执行,上面的 defer 并不会输出。
十二. 面向对象
golang实现面向对象的封装、继承、多态
封装、继承、多态和抽象是面向对象的4个基本特征。
1)封装
- 基本介绍:封装就是把抽象出的字段和字段的操作封装在一起,数据被保护在内部,程序的其他包只有通过被授权的操作(方法)才能对字段进行操作。
- 优点:隐藏实现细节;可以对数据进行验证。
- 实现如下面代码所示,需要注意的是,在golang内,除了slice、map、channel和显示的指针类型属于引用类型外,其它类型都属于值类型。
- 引用类型作为函数入参传递时,函数对参数的修改会影响到原始调用对象的值;
- 值类型作为函数入参传递时,函数体内会生成调用对象的拷贝,所以修改不会影响原始调用对象。所以在下面GetName中,接收器使用 this *Person 指针对象定义。当传递的是小对象,且不需要更改调用对象时,使用值类型做为接收器;大对象或者需要更改调用对象时使用指针类型作为接收器。
type Person struct {
name string
age int
}
func NewPerson() Person {
return Person{}
}
func (p *Person) SetName(name string) {
p.name = name
}
func (p *Person) GetName() string {
return p.name
}
func (p *Person) SetAge(age int) {
p.age = age
}
func (p *Person) GetAge() int {
return p.age
}
func main() {
p := NewPerson()
p.SetName("xiaofei")
fmt.Println(p.GetName())
}
2)继承
- 基本介绍:当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出一个基结构体A,在A中定义这些相同的属性和方法。其他的结构体不需要重新定义这些属性和方法,只需嵌套一个匿名结构体A即可。
- 优点:可以解决代码复用,让编程更加靠近 人类思维。
- 实现:在golang中,如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现继承特性。
- 同时,一个struct还可以嵌套多个匿名结构体,那么该struct可以直接访问嵌套的匿名结构体的字段和方法,从而实现多重继承。
type Student struct {
Person
StuId int
}
func (this *Student) SetId(id int) {
this.StuId = id
}
func (this *Student) GetId() int {
return this.StuId
}
func main() {
stu := Student{}
stu.SetName("xiaofei") // 可以直接访问Person的Set、Get方法
stu.SetAge(22)
stu.SetId(123)
fmt.Printf("I am a student,My name is %s, my age is %d, my id is %d", stu.GetName(), stu.GetAge(), stu.GetId)
}
3)抽象
将共同的属性和方法抽象出来形成一个不可以被实例化的类型,由于抽象和多态是相辅相成的,或者说抽象的目的就是为了实现多态。
4)多态
基本介绍:基类指针可以指向任何派生类的对象,并在运行时绑定最终调用的方法的过程被称为多态。
多态是运行时特性,而继承则是编译时特性。也就是说继承关系在编译时就已经确定了,而多态则可以实现运行时的动态绑定。
实现:
// 小狗和小鸟都是动物,都会移动和叫,它们共同的方法就可以提炼出来定义为一个抽象的接口。
type Animal interface {
Move()
Shout()
}
type Dog struct {
}
func (dog Dog) Move() {
fmt.Println("I am dog, I moved by 4 legs.")
}
func (dog Dog) Shout() {
fmt.Println("wang wang wang")
}
type Bird struct {
}
func (bird Bird) Move() {
fmt.Println("I am bird, I fly with 2 wings")
}
func (bird Bird) Shout() {
fmt.Println("ji ji ji ")
}
type ShowAnimal struct {
}
func (s ShowAnimal) Show(animal Animal) {
animal.Move()
animal.Shout()
}
func main() {
show := ShowAnimal{}
dog := Dog{}
bird := Bird{}
show.Show(dog)
show.Show(bird)
}