文章目录
- 一、前言
- 关于Percona
- 二、Percona Toolkit
- 安装 percona-toolkit:
- pt-archiver 归档命令的使用
- 格式:
- 示例:
- 三、归档步骤:
- 1)、创建归档数据库和归档表
- 方式一(推荐):
- 这种方式的优缺点:
- 方式二(不推荐):
- 这种方式的优缺点:
- 存储过程
- 2)、编写shell脚本
- 1、造测试数据
- 创建表
- 编写存储过程
- 2、Shell脚本
- 通用模板:
- 3、添加到定时任务计划
- 四、相关链接:
- 五、关于转载
一、前言
一个完整的项目,除了开发阶段,还有运维移交阶段,运维移交往往需要考虑数据库后续的归档机制,比如:将1年前的数据归档到另外一台服务器的归档库。有些业务表数据量比较大,为了更快的查询速度更好的用户体验,可能会对某张特定的表做归档处理,只保留最近1个月的数据,定时将历史数据迁移到归档库。这个时候可以使用Percona Toolkit工具的 pt-archiver归档命令实现上述归档功能。
关于Percona
Percona是一家广受认可的世界级开源数据库软件、支持和服务公司,致力于通过专业知识和开源软件的独特组合,助力企业数据库和应用更顺畅地运行。Percona与许多行业内的众多全球品牌合作,打造一致的体验,帮助监控、管理、保护和优化任何基础设施上的数据库环境。
简而言之:Percona官网有很多与数据库相关的开源工具,包括 数据归档神器: Prcona Toolkit.
二、Percona Toolkit
访问 Percona 公司 开源下载地址,找到 Percona Toolkit 工具。里面有详细的用户手册和使用文档。
安装 percona-toolkit:
# 查看当前系统是什么版本的Linux系统
cat /etc/redhat-release
• 对于 Debian or Ubuntu 系统安装命令如下:
sudo apt-get install percona-toolkit
•对于 RHEL or CentOS 系统安装命令如下:
sudo yum install percona-toolkit
如果下载失败提示No package percona-toolkit available.,可以直接用wget命令直接下载官方网对应的 percona-toolkit-3.x.x_x86_64.tar.gz包,包路径看上图官方下载链接。
# 1. 下载最新版 3.5.5 Percona Toolkit工具编译包
wget "https://downloads.percona.com/downloads/percona-toolkit/3.5.5/binary/tarball/percona-toolkit-3.5.5_x86_64.tar.gz"
# 1.1 解压
tar -xf percona-toolkit-3.5.5_x86_64.tar.gz
#2.检查和安装与Perl相关的模块
##PT工具是使用Perl语言编写和执行的,所以需要系统中有Perl环境
# 2.1 依赖包检查命令为:
rpm -qa perl-DBI perl-DBD-MySQL perl-Time-HiRes perl-IO-Socket-SSL
# 2.2 如果有依赖包确实,可以使用下面的命令安装:
yum -y install perl-DBI
yum -y install perl-DBD-MySQL
yum -y install perl-Time-HiRes
yum -y install perl-IO-Socket-SSL
yum -y install perl-Digest-MD5
# 3.进入目录安装
cd percona-toolkit-3.5.5
# 3.1 查看安装手册
cat INSTALL
# 3.2 依次执行命令安装:
perl Makefile.PL
make
make test
make install ## PS: 安装成功后,默认 pt相关命令安装在 /usr/local/bin 目录
# 3.3 进入bin目录,查看pt命令是否存在
cd /usr/local/bin
# 3.4 查看 pt 命令是否正常
pt-table-checksum --version
## 如果提示"pt-table-checksum: command not found",执行如下命令
echo $PATH
## 确保 /usr/local/bin 在系统的路径中,如不在,则添加环境变量
vim ~/.bash_profile
## 添加以下行,保存退出
export PATH=$PATH:/usr/local/bin
## 执行source命令重新加载文件,使其生效
source ~/.bash_profile
## 再次执行 pt-table-checksum --version,如果提示"Can't locate Digest/MD5.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at /usr/local/bin/pt-table-checksum line 789.BEGIN failed--compilation aborted at /usr/local/bin/pt-table-checksum line 789" 则表示没有安装 "perl-Digest-MD5"
## 执行命令安装:
yum -y install perl-Digest-MD5
## 再次执行 pt-table-checksum --version ,提示版本号,则表示安装成功。
pt-archiver 归档命令的使用
将 Mysql的行数据归档到另一个表或者文件中,(可自行决定是否删除源数据)。
格式:
pt-archiver [OPTIONS] --source DSN --where WHERE
示例:
这个命令是使用 Percona Toolkit 工具中的 pt-archiver 命令进行数据归档的示例。
# 归档“归档表最新一条记录(NULL时默认2022-12-20 00:00:00) 至 当前时间-7天” 的数据
## 按条件归档,不删除源数据, 批量插入
pt-archiver --source h=127.0.0.1,P=3306,u=root,p=root,D=zgh_ms,t=app_log,A=utf8mb4 \
--dest h=127.0.0.1,P=3306,u=root,p=root,D=zgh_ms_archiver,t=app_log,A=utf8mb4 \
--charset=utf8 --where "create_time BETWEEN IFNULL((SELECT MAX(create_time) FROM zgh_ms_archiver.app_log), '2022-12-20 00:00:00') AND DATE_SUB(NOW(), INTERVAL 7 DAY)" \
--progress=10000 --txn-size=5000 --limit=5000 --statistics --no-delete --ask-pass
# 按条件归档,删除元源表数据,非批量插入,非批量删除 (参数加 `--dry-run`,只打印需要执行的sql语句,不真正执行)
pt-archiver --source h=127.0.0.1,P=3306,u=root,p=root,D=zgh_ms,t=app_log,A=utf8mb4 --dest h=127.0.0.1,P
=3306,u=root,p=root,D=zgh_ms_archiver,t=app_log,A=utf8mb4 --charset=utf8 --where "create_time BETWEEN IFNULL((SELECT MAX(create_time) FROM zgh_ms_archiver.app_user), '2022-12-20 00:00:00') AND DATE_SUB(NOW(), INTERVAL 20 DAY)" --progress=1000 --txn-size=1000 --limit=1000 --statistics --bulk-insert --purge --ignore
# PS 执行归档之前,需要先手动创建归档数据库和归档表,DDL要保持一致
这个命令的作用是将源数据库中 zgh_ms.app_log 表的选择create_time字段在最近7天内,且大于等于2022年12月20日的数据归档到目标数据库中 zgh_ms_archiver.app_log 表中。注意确保在运行命令之前已经创建了目标数据库和表。
下面是对各个参数的解释:
--source h=127.0.0.1,P=3306,u=root,p=root,D=zgh_ms,t=app_log,A=utf8mb4:
h=127.0.0.1:源数据库的主机名或 IP 地址。P=3306:源数据库的端口号。u=root:连接到源数据库的用户名。p=root:连接到源数据库的密码。D=zgh_ms:源数据库中的数据库名称。t=app_log:源数据库中的表名。A=utf8mb4:源数据库中的字符集设定。
--dest h=127.0.0.1,P=3306,u=root,p=root,D=zgh_ms_archiver,t=app_log,A=utf8mb4:
h=127.0.0.1:目标数据库的主机名或 IP 地址。P=3306:目标数据库的端口号。u=root:连接到目标数据库的用户名。p=root:连接到目标数据库的密码。D=zgh_ms_archiver:目标数据库中的数据库名称。t=app_log:目标数据库中的表名。A=utf8mb4:目标数据库中的字符集设定。
--charset=utf8:指定字符集为 UTF-8。
--where "create_time BETWEEN IFNULL((SELECT MAX(create_time) FROM zgh_ms_archiver.app_log), '2022-12-20 00:00:00') AND DATE_SUB(NOW(), INTERVAL 7 DAY)":
DATE_SUB(NOW(), INTERVAL 7 DAY):这是一个函数, 用于计算(当前系统时间 -7天)的时间。- 指定迁移数据的条件,这里是选择满足特定日期范围的数据进行迁移。具体的条件是"
create_time BETWEEN IFNULL((SELECT MAX(create_time) FROM zgh_ms_archiver.app_log), ‘2022-12-20 00:00:00’) AND DATE_SUB(NOW(), INTERVAL 7 DAY)",意思是选择create_time字段在最近7天内,且大于等于2022年12月20日的数据。
--progress=10000:每处理 10000 行数据时输出进度报告。
--txn-size=5000:每个事务中处理的最大行数,用于控制事务的大小。
--limit=5000:每个查询中返回的记录数的限制。
--statistics:输出统计信息,包括处理的行数和花费的时间等。
--no-delete:在归档操作完成后不删除源数据库中的记录。
--bulk-insert:使用批量插入模式进行数据插入操作,提高归档性能。
--ask-pass:在命令行中提示输入密码。
三、归档步骤:
1)、创建归档数据库和归档表
要求 源库与归档库保持一致;源数据库与归档数据库保持一致;
方式一(推荐):
# 查询 zgh_ms 数据库中所有的表结构
SELECT CONCAT('SHOW CREATE TABLE zgh_ms.', table_name, ';') AS ddl_statement
FROM information_schema.tables
WHERE table_schema = 'zgh_ms';
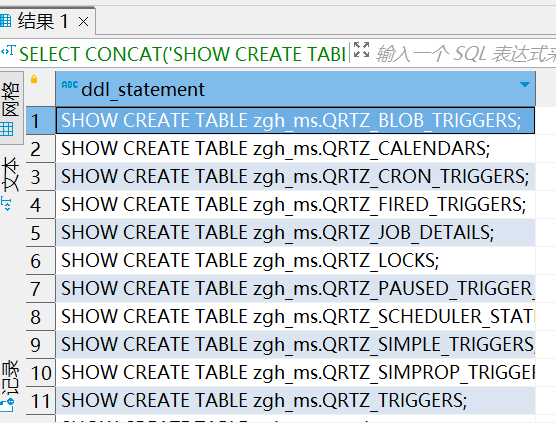
将 ddl_statement sql语句拷贝出来,手动执行SHOW CREATE TABLE A库.a1表; sql语句,可以得到每个数据库的建表DDL语句,拷贝出来然后执行DDL建表。
这种方式的优缺点:
- 优点 :创建的DDL表结构跟源数据库表结构一致,有主键和索引、备注信息。
- 缺点:如果表多起来,一条条手动copy出来比较繁琐,容易搞漏。
方式二(不推荐):
使用 存储过程,通过 如下格式的sql语句快速复制并创建表结构
CREATE TABLE IF NOT EXISTS zgh_ms_archiver.schedule_job_log AS SELECT * FROM zgh_ms.schedule_job_log where 1=0;
这种方式的优缺点:
- 优点 :一键执行,快速批量的创建所有表结构,所有表都有。
- 缺点:创建的DDL表结构跟源数据库表结构不完全一致,每个表都丢失了有主键和索引(字段和备注信息还在)。主键还要自己一个个手动添加。
存储过程
-- 参数 (source_db源数据库,dest_db目标数据库)
-- 示例: CALL create_empty_tables('zgh_ms','zgh_ms_archiver'); zgh_ms是源数据库,zgh_ms_archiver是目标归档库
-- 简单逻辑:通过拼接这种格式"CREATE TABLE IF NOT EXISTS dest_db.A表 AS SELECT * FROM source_db.A表 where 1=0;" 的sql语句,快速复制创建表结构
-- 缺点: 这种创建表结构的方式会丢失主键、索引,需要额外手动添加主键,有需要的情况下可以重建索引。
CREATE DEFINER=`root`@`%` PROCEDURE `zgh_ms_archiver`.`create_empty_tables`(IN source_db TEXT, IN dest_db TEXT)
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE ddl_statement TEXT;
DECLARE cur CURSOR FOR
SELECT CONCAT('CREATE TABLE IF NOT EXISTS ',dest_db,'.', table_name, ' AS SELECT * FROM ',source_db,'.', table_name, ' where 1=0;') AS ddl_statement
FROM information_schema.tables
-- COLLATE 关键字,将字符集和校对规则设置成一致的
WHERE table_schema COLLATE utf8_general_ci = source_db COLLATE utf8_general_ci;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
OPEN cur;
read_loop: LOOP
FETCH cur INTO ddl_statement;
IF done THEN
LEAVE read_loop;
END IF;
SET @ddl_stmt = ddl_statement;
PREPARE stmt FROM @ddl_stmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END LOOP;
CLOSE cur;
END
2)、编写shell脚本
- 数据归档:利用
Percona Toolkit数据库命令行工具,编写pt-archiver语句实现归档。- 多表归档:编写
shell脚本,顺序执行 多条pt-archiver语句,实现批量归档多表。- 定期归档:通过Linux 系统的
cron定时任务功能,定期执行步骤2的shell脚本实现定期归档。PS : 要求 编写的
pt-archiver语句考虑历史数据的问题,不能重复插入或错漏。where语句条件,建议根据归档表的最后一条create_time时间作为每次归档指针的起点。
1、造测试数据
创建表
# 日志表
CREATE TABLE `app_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(50) DEFAULT NULL COMMENT '用户名',
`operation` varchar(50) DEFAULT NULL COMMENT '用户操作',
`method` varchar(200) DEFAULT NULL COMMENT '请求方法',
`params` longtext COMMENT '请求参数',
`time` bigint(20) NOT NULL COMMENT '执行时长(毫秒)',
`ip` varchar(64) DEFAULT NULL COMMENT 'IP地址',
`status` tinyint(4) NOT NULL COMMENT '任务状态 0:成功 1:失败',
`error` varchar(2000) DEFAULT NULL COMMENT '失败信息',
`retry` tinyint(4) NOT NULL DEFAULT '0' COMMENT '已重试的次数',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `app_log_create_time_IDX` (`create_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=20000621 DEFAULT CHARSET=utf8mb4 COMMENT='APP调用日志(记录与第三方系统交互的执行日志)';
编写存储过程
描述:通过存储过程,批量插入测试数据。
简单逻辑: 开启事务,事务内循环拼接insert语句,batch_size条提交1次事务,一共插入total条记录。
-- 参数:(batch_size批量提交数量,total总插入数 )
-- 示例:CALL batch_insert_app_log_testData(1000,10000); 1000条记录提交一下,共插入1w条记录
-- 简单逻辑: 开启事务,事务内循环拼接insert语句,batch_size条提交1次事务,一共插入total条记录。
CREATE DEFINER=`root`@`%` PROCEDURE `zgh_ms`.`batch_insert_app_log_testData`(IN batch_size INT, IN total INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE commit_counter INT DEFAULT 0; -- 记录提交的计数
START TRANSACTION; -- 开始事务
WHILE i <= total DO
IF commit_counter = batch_size THEN
COMMIT; -- 执行提交
START TRANSACTION; -- 开始下一批次的事务
SET commit_counter = 0;
END IF;
-- 构建插入数据
SET @username = CONCAT('username', i);
SET @operation = CONCAT('operation', i);
SET @method = CONCAT('method', i);
SET @params = CONCAT('params', i);
SET @ip = CONCAT('ip', i);
-- 执行插入操作
INSERT INTO app_log (username, operation, method, params, time, ip, status, error, retry, create_time, update_time)
VALUES (@username, @operation, @method, @params, i, @ip, 0, '', 0, NOW(), NOW());
SET i = i + 1;
SET commit_counter = commit_counter + 1;
END WHILE;
COMMIT; -- 提交最后一批数据
SELECT CONCAT('Data inserted successfully! 插入 ', total, ' 条数据') AS message;
END
执行sql语句,批量插入2kw条数据,每5000条insert语句提交一次事务。
CALL batch_insert_app_log_testData(5000,2000*10000);
2、Shell脚本
vim mysql-zgh_ms_archiver.sh,创建shell脚本(详见下面的模板):wq保存并退出chmod +x mysql-zgh_ms_archiver.sh给脚本执行权限sh mysql-zgh_ms_archiver.sh &后台执行脚本
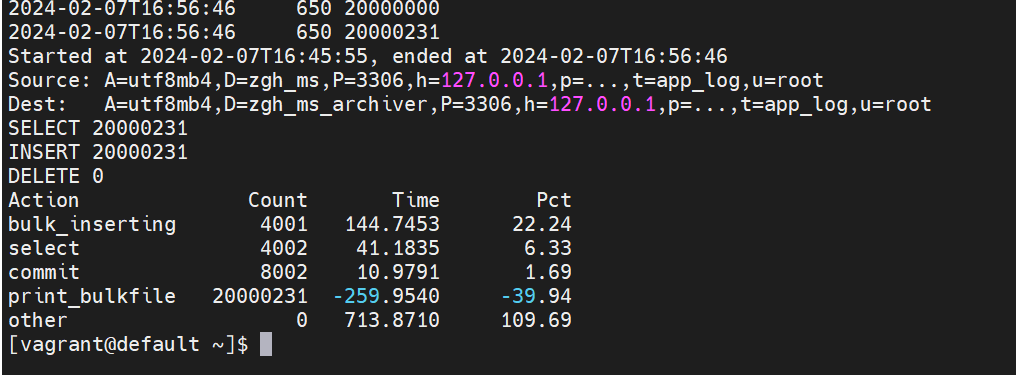
执行效果示意图:
通用模板:
#!/bin/bash
# 指定pt-archiver命令的安装路径
BASE_PATH=/usr/local/bin/
# 获取当前系统时间
CURRENT_TIME=$(date +"%Y-%m-%d %H:%M:%S")
# 定义日志文件路径 "数据库名+日期"作为日志文件名
LOG_FILE="archiver-$SOURCE_DATABASE-$(date +"%Y-%m-%d_%H-%M-%S").log"
echo "归档配置初始化开始..." >> $LOG_FILE
# 定义 pt-archiver 参数变量
SOURCE_HOST="127.0.0.1"
SOURCE_PORT="3306"
SOURCE_USER="root"
SOURCE_PASSWORD="root"
SOURCE_DATABASE="zgh_ms"
SOURCE_CHARSET="utf8mb4"
DEST_HOST="127.0.0.1"
DEST_PORT="3306"
DEST_USER="root"
DEST_PASSWORD="root"
DEST_DATABASE="zgh_ms_archiver"
DEST_CHARSET="utf8mb4"
# 每处理 $PROGRESS 行数据时输出进度报告
PROGRESS=10000
# 每个事务中处理的最大行数,用于控制事务的大小
TXN_SIZE=1000
# 每个查询中返回的记录数的限制
LIMIT=1000
# 归档间隔时间
INTERVAL_DAY=365
echo "###############################################################" >> $LOG_FILE
# 定义需要归档的表名
TABLES=("app_log" "schedule_job_log")
# 归档条件的指定的字段
ARCHIVER_FIELD=create_time
echo "归档条件的指定字段: $ARCHIVER_FIELD 相关的表,归档配置初始化开始..." >> $LOG_FILE
echo -e "\n" >> $LOG_FILE
echo "源数据库库名:$SOURCE_DATABASE ,数据库编码:$SOURCE_CHARSET" >> $LOG_FILE
echo "目标归档库库名:$DEST_DATABASE ,数据库编码:$DEST_CHARSET" >> $LOG_FILE
echo "归档配置:" >> $LOG_FILE
echo " --progress=$PROGRESS :每处理 $PROGRESS 行数据时输出进度报告;" >> $LOG_FILE
echo " --txn-size=$TXN_SIZE :每个事务中处理的最大行数,用于控制事务的大小;" >> $LOG_FILE
echo " --limit=$LIMIT :每个查询中返回的记录数的限制;" >> $LOG_FILE
echo " --statistics:输出统计信息,包括处理的行数和花费的时间等;" >> $LOG_FILE
echo " --no-delete:在归档操作完成后不删除源数据库中的记录;" >> $LOG_FILE
echo " --bulk-insert:使用批量插入模式进行数据插入操作,提高归档性能;" >> $LOG_FILE
echo -e "\n\n\n" >> $LOG_FILE
# 循环执行 pt-archiver 语句
for table in "${TABLES[@]}"
do
SOURCE_TABLE=$table
DEST_TABLE=$table
# 归档条件
WHERE_CLAUSE="$ARCHIVER_FIELD BETWEEN IFNULL((SELECT MAX($ARCHIVER_FIELD) FROM zgh_ms_archiver.$DEST_TABLE), '2022-12-20 00:00:00') AND DATE_SUB(NOW(), INTERVAL $INTERVAL_DAY DAY)"
echo "=======【归档字段:$ARCHIVER_FIELD (不删除源表数据,批量插入),start】=======" >> $LOG_FILE
echo "源表名:$SOURCE_TABLE,归档表名: $DEST_TABLE" >> $LOG_FILE
echo -e "\n" >> $LOG_FILE
COMMON="$BASE_PATH/pt-archiver --source h=$SOURCE_HOST,P=$SOURCE_PORT,u=$SOURCE_USER,p=$SOURCE_PASSWORD,D=$SOURCE_DATABASE,t=$SOURCE_TABLE,A=$SOURCE_CHARSET \
--dest h=$DEST_HOST,P=$DEST_PORT,u=$DEST_USER,p=$DEST_PASSWORD,D=$DEST_DATABASE,t=$DEST_TABLE,A=$DEST_CHARSET \
--charset=utf8 --where \"$WHERE_CLAUSE\" \
--progress=$PROGRESS --txn-size=$TXN_SIZE --limit=$LIMIT --statistics --no-delete --bulk-insert --ask-pass"
# 将命令写入日志文件
echo "归档命令: $COMMON" >> $LOG_FILE
echo -e "\n" >> $LOG_FILE
echo "归档执行中,请稍等..." >> $LOG_FILE
# 执行归档命令
eval $COMMON >> $LOG_FILE
echo "表名: $table 归档完成" >> $LOG_FILE
echo "=======【归档字段:$ARCHIVER_FIELD (不删除源表数据,批量插入),end】=======" >> $LOG_FILE
echo -e "\n\n\n" >> $LOG_FILE
done
echo "###############################################################" >> $LOG_FILE
3、添加到定时任务计划
# 查看已有的定时任务列表
crontab -l
# 编辑定时任务列表
crontab -e
比如:
# 每个月的1号凌晨3点执行归档脚本
0 3 1 * * /bin/bash /mydata/xxx/archiver/mysql-zgh_ms_archiver.sh >/dev/null 2>&1 &
四、相关链接:
-
Percona Toolkit 3.5.6 安装手册
-
Percona Toolkit 各命令使用手册
五、关于转载
转载请注明出处和链接地址,谢谢。