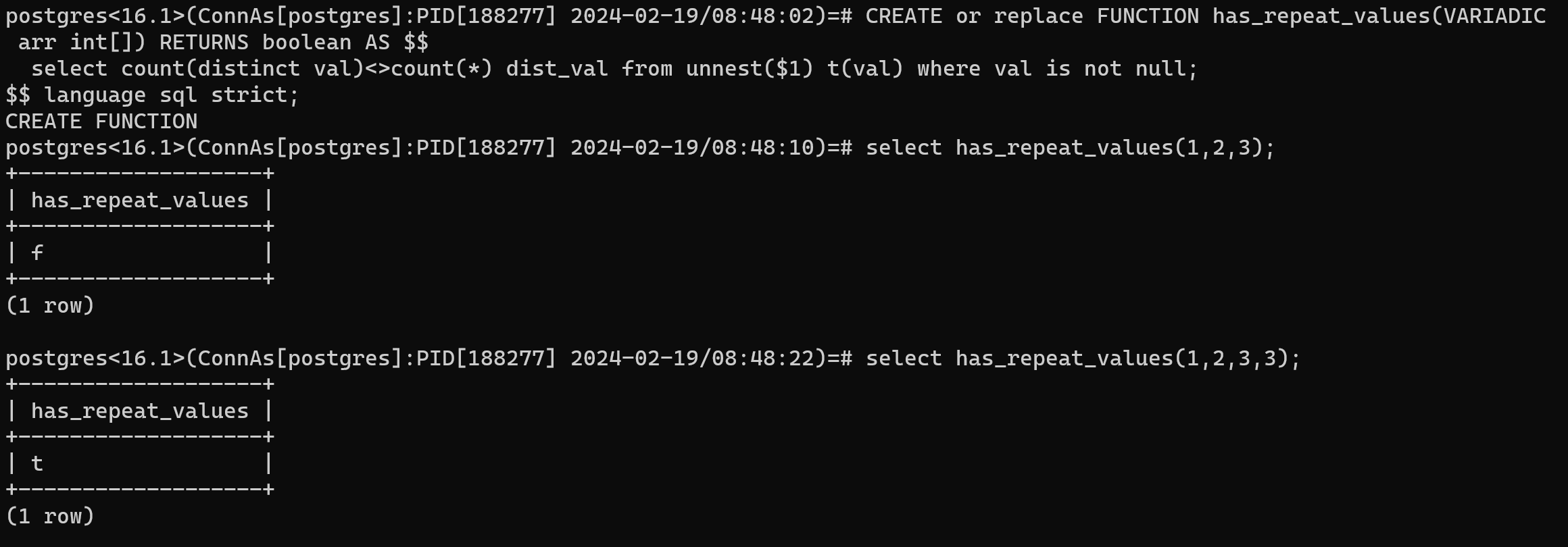
在进行排列组合的时候,每一次需要知道是否有重复的值,并过滤出已经排列过的值。这个可以创建支持可变参数的函数来实现。下边的函数用到了聚合判断,并且可变参数使用variadic标记的数组。
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:48:02)=# CREATE or replace FUNCTION has_repeat_values(VARIADIC arr int[]) RETURNS boolean AS $$
select count(distinct val)<>count(*) dist_val from unnest($1) t(val) where val is not null;
$$ language sql strict;
CREATE FUNCTION
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:48:10)=# select has_repeat_values(1,2,3);
+-------------------+
| has_repeat_values |
+-------------------+
| f |
+-------------------+
(1 row)
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:48:22)=# select has_repeat_values(1,2,3,3);
+-------------------+
| has_repeat_values |
+-------------------+
| t |
+-------------------+
(1 row)
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:56:47)=# select has_repeat_values(1,2,3,null);
+-------------------+
| has_repeat_values |
+-------------------+
| f |
+-------------------+
(1 row)
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:58:20)=# select has_repeat_values(1,2,3,null,null);
+-------------------+
| has_repeat_values |
+-------------------+
| f |
+-------------------+
(1 row)
然后是如何使用这个函数结合查询语句对一组数据进行排列组合。
先创建一个测试的表,里边存放要进行排列组合的数据。
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:52:26)=# create table test_data(id int);
CREATE TABLE
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:52:27)=# insert into test_data select generate_series(1,4);
INSERT 0 4
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:52:40)=# select * from test_data;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
+----+
(4 rows)
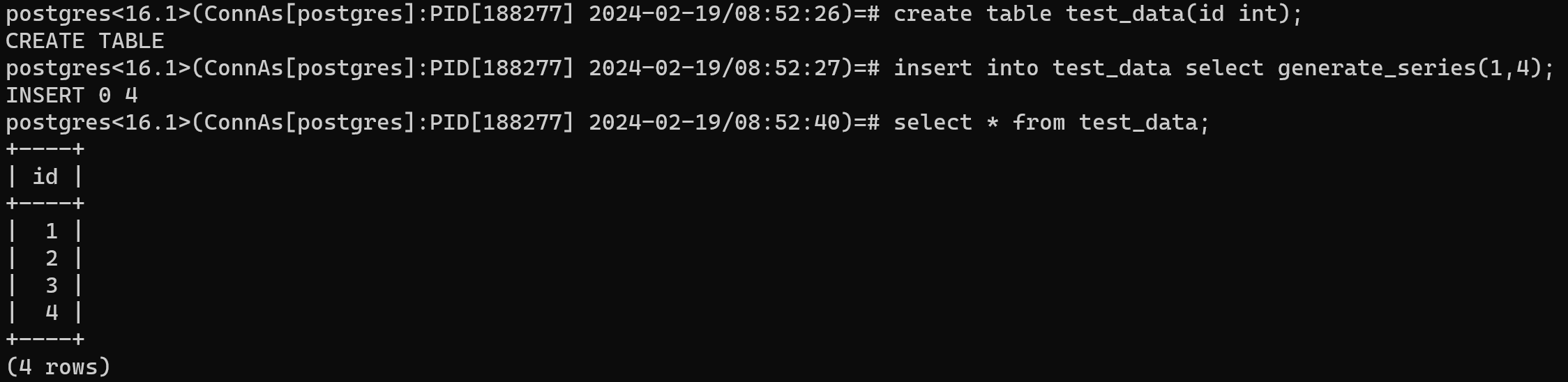
例如,一张表里有1234这四个值。想使用四个值做排列组合。
根据4的阶乘可以得到,总共应该有24种,阶乘可以使用factorial函数。
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:52:46)=# select factorial(4);
+-----------+
| factorial |
+-----------+
| 24 |
+-----------+
(1 row)

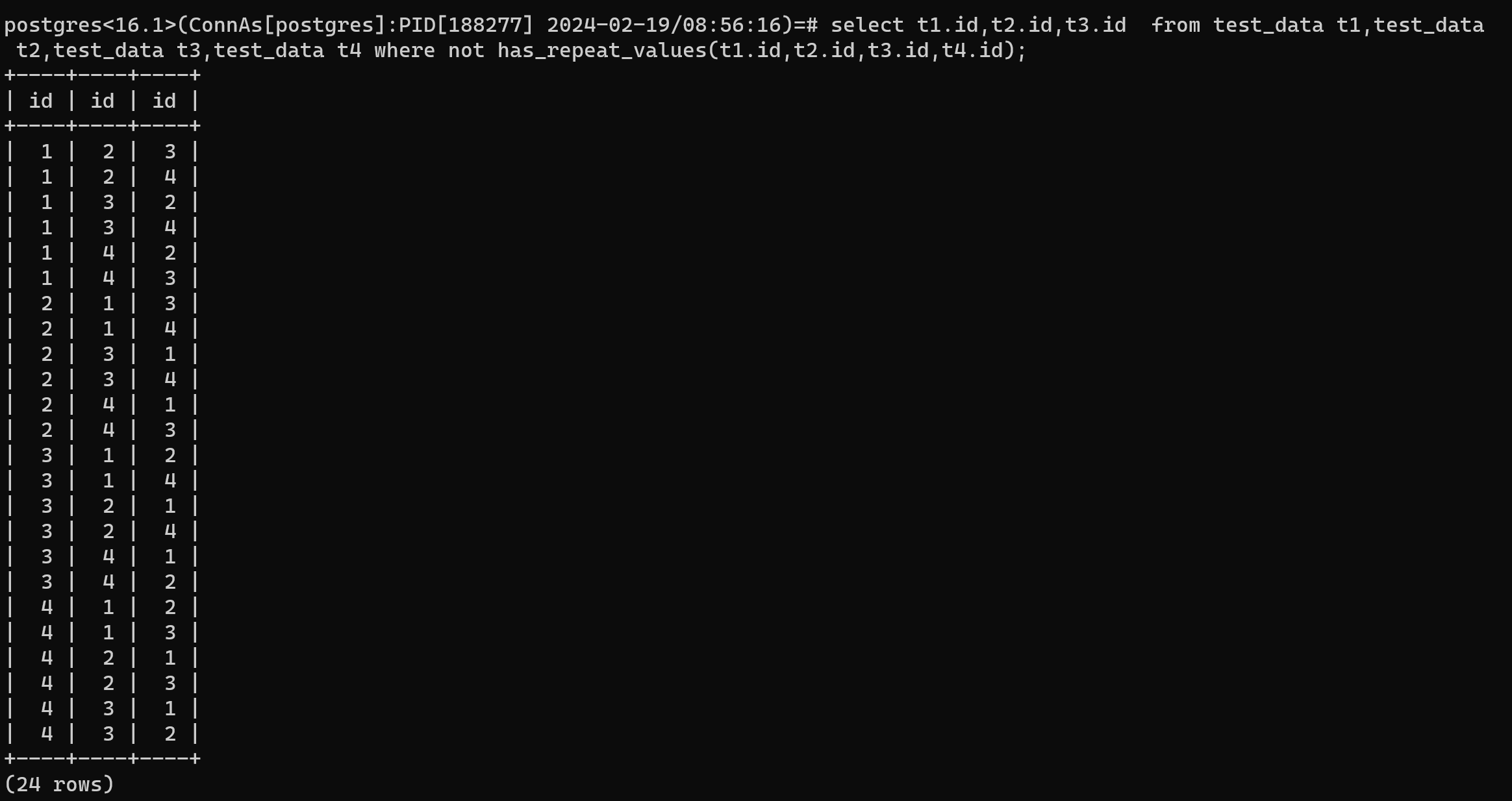
然后下边使用创建的判断是否有重复数据的函数以及使用SQL实现获取所有的排列组合。
postgres<16.1>(ConnAs[postgres]:PID[188277] 2024-02-19/08:56:16)=# select t1.id,t2.id,t3.id from test_data t1,test_data t2,test_data t3,test_data t4 where not has_repeat_values(t1.id,t2.id,t3.id,t4.id);
+----+----+----+
| id | id | id |
+----+----+----+
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 1 | 3 | 2 |
| 1 | 3 | 4 |
| 1 | 4 | 2 |
| 1 | 4 | 3 |
| 2 | 1 | 3 |
| 2 | 1 | 4 |
| 2 | 3 | 1 |
| 2 | 3 | 4 |
| 2 | 4 | 1 |
| 2 | 4 | 3 |
| 3 | 1 | 2 |
| 3 | 1 | 4 |
| 3 | 2 | 1 |
| 3 | 2 | 4 |
| 3 | 4 | 1 |
| 3 | 4 | 2 |
| 4 | 1 | 2 |
| 4 | 1 | 3 |
| 4 | 2 | 1 |
| 4 | 2 | 3 |
| 4 | 3 | 1 |
| 4 | 3 | 2 |
+----+----+----+
(24 rows)




![nginx upstream server主动健康检测模块添加https检测功能[完整版]](https://img-blog.csdnimg.cn/direct/cd8fcaae43b541ba964ca0235a8e30e9.png#pic_center)