1 bfs广度优先搜索
1.1 是什么
1.2怎么实现
2案例学习
2.1.走迷宫
2.2.P1443 马的遍历
2.3. 九宫重排(看答案学的,实在写不来)
2.4.青蛙跳杯子(学完九宫重排再做bingo)
2.5. 长草
3.总结
1 bfs广度优先搜索
【Python搜索算法】广度优先搜索(BFS)算法原理详解与应用,示例+代码_广度优先算法的路径搜索代码-CSDN博客
1.1 是什么
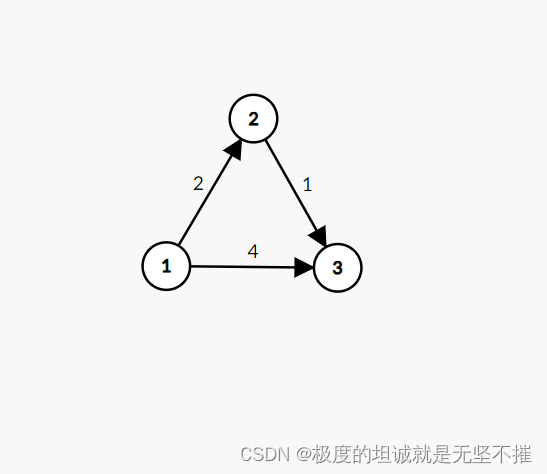
看了其他大佬的分享之后,我理解的广度优先搜索是一种图遍历的算法,简单来说是他的访问规则是一层一层的访问,先访问距离节点近的数据,再逐层拓展访问远的数据。与广度优先搜索密切相关的数据类型叫做队列。队列我们可以理解为是日常生活中排队所形成的队形,先进先出是队列最大的特点。
1.2怎么实现
BFS算法的步骤如下:
- 初始化:选择一个起始节点,将其标记为已访问,并将其放入队列中(作为起始节点)。
- 进入循环:重复以下步骤,直到队列为空。 a. 从队列中取出一个节点。 b. 访问该节点。 c. 将所有未访问的相邻节点加入队列。 d. 标记已访问的节点,以避免重复访问。
- 结束循环:当队列为空时,表示已经遍历完整个图。
算法原理:
BFS的工作原理是通过队列数据结构来管理待访问的节点。它从起始节点开始,然后逐一访问该节点的相邻节点,并将它们加入队列。然后,它从队列中取出下一个节点进行访问,以此类推。这确保了节点按照它们的距离从起始节点逐层遍历,因此BFS可以用于查找最短路径。
BFS是一个宽度优先的搜索,它在查找最短路径等问题中非常有用。它不会陷入深度过深的路径,因为它会优先探索距离起始节点更近的节点。
总结:广度优先搜索一般来说都会有一个队列去存储节点,同时也会有一个数组去记录访问的状态。
2案例学习
2.1.走迷宫

输入:
5 5
1 0 1 1 0
1 1 0 1 1
0 1 0 1 1
1 1 1 1 1
1 0 0 0 1
1 1 5 5 输出:
8说明一下这道题的思路,这道题非常直观体现了BFS,并且是最基本的BFS。那代码的思路是怎么样的呢?我们来捋一下。
一开始所说的队列其实就是列表,只是用到了队列的特点,也就是说队列其实就是类似于列表,只是这个算法的思路用到了队列的特点,一开始我想得太复杂了,总以为队列是一个很高级的容器,其实简单理解就是列表。
那根据BFS的算法思路:
- 初始化:将迷宫的起点作为起始节点 queue=[(x1-1,y1-1,step)]
- 进入循环:循环终止的条件是什么,当列表为空就终止了 while queue: 怎么取出列表的第一个元素,这个时候就是队列的特点,先进先出,怎么体现在列表中,进去就是存入,出来就是删除 x,y,step=queue.pop(0) 这里页需要注意走迷宫有上下左右四个方向对应的就是坐标的变化,这也是我对子节点的一个理解
同时已经访问过的点也要做好标记
我当时还有一个特别想不懂的,哈哈哈哈哈哈,想起来感觉自己特别蠢哈哈哈哈哈。
怎么着,我想着每一个节点都有四个子节点,那意味着线路会不一样,怎么就知道那一个的step是最小的,结果我看到那个判断的出口就一下子大悟了,最短路径嘛,那早点满足出口条件的不就是最短路径嘛
n, m = map(int,input().split())
data = []
d = [[1,0],[-1,0],[0,1],[0,-1]]
for i in range(n):
l = list(map(int,input().split()))
data.append(l)
x1, y1, x2, y2 = map(int,input().split())
def bfs(x1,y1,step):
queue=[(x1-1,y1-1,step)]
while queue:
x,y,step=queue.pop(0)
if x==x2-1 and y==y2-1:
return step
for xx,yy in d:
dx = x+xx
dy = y+yy
if 0<= dx <n and 0<= dy <m and data[dx][dy] :
data[dx][dy]=0
queue.append((dx,dy,step+1))
return -1
print(bfs(x1,y1,0))2.2.P1443 马的遍历

做好久了但是还是没有完全通过,怎么办可以帮忙看看嘛
n, m, x, y= map(int,input().split())
d = [[-1,2],[-2,1],[-2,-1],[-1,-2],[1,2],[2,1],[2,-1],[1,-2]]
data = []
result = [[0 for _ in range(m)]for _ in range(n)]
for i in range(1,n+1):
for j in range(1,m+1):
data.append([i,j])
from collections import deque
def bfs(x,y,a,b,step,visit):
queue = deque([(x,y,step)])
while len(queue) != 0:
x1, y1, step = queue.popleft()
if x1 == a and y1 == b:
return step
for xx,yy in d:
dx = x1+xx
dy = y1+yy
if dx < 1 or dx > n or dy < 1 or dy > m:
continue
if visit[dx][dy] == 0:
visit[dx][dy] = 1
queue.append((dx, dy, step + 1))
return -1
for i,j in data:
visit = [[0 for _ in range(m + 1)] for _ in range(n + 1)]
visit[x][y] = 1
ans = bfs(x,y,i,j,0,visit)
result[i-1][j-1] = ans
for i in result:
for j in i:
print(j,end='\t')
print('\n',end='')
2.3. 九宫重排(看答案学的,实在写不来)
6.九宫重排 - 蓝桥云课 (lanqiao.cn)
我当时自己做的时候就在纠结到底是移动格子还是移动数字,很显然,如果要移动数字那每个数字都需要移动,但是移动格子的话我们只需要对这个格子进行操作就可以了。所以移动格子是最佳方案。
以下是我自己写的错误代码,真的是错的离谱,纪念一下我稀里糊涂的脑子
start = input()
end = input()
map1 = [[0 for _ in range(3)] for _ in range(3)]
map2 = [[0 for _ in range(3)] for _ in range(3)]
k1, k2 = 0, 0
for i in range(3):
for j in range(3):
map1[i][j] = start[k1]
if start[k1] == '.':
a, b = i, j
k1 += 1
for i in range(3):
for j in range(3):
map2[i][j] = end[k2]
k2 += 1
d = [[1,0],[-1,0],[0,1],[0,-1]]
def bfs(a,b,step):
global map1
visit = [[0 for _ in range(3)] for _ in range(3)]
queue = [(a,b,step)]
visit[a][b] = 1
while queue:
x, y, step = queue.pop(0)
if map1 == map2:
return step
for xx,yy in d:
dx = x+xx
dy = y+yy
if dx<0 or dx>2 or dy<0 or dy>2:
continue
if visit[dx][dy] == 0:
visit[dx][dy] = 1
map1[x][y],map1[dx][dy] = map1[dx][dy],map1[x][y]
queue.append((dx,dy,step+1))
return -1
print(bfs(a,b,0))
别人大佬的代码代码写的真好
蓝桥杯:九宫格重排【BFS】【Python】_重排九宫问题bfs-CSDN博客
当然我在别人的代码上加上了一些修改以及注释,主要是得自己看得懂
我也反思了一下自己写的代码思路和别人的,我在一维和二维的变换上处理的十分混乱,导致自己都不知道到底是个什么事儿,因为我也知道是去移动格子,然后交换,但是我就很混乱。当然我的思路还有一些错误。
别人的代码思路这一点我真是没想到,就是用字典的键值对去存储每一次移动格子后所形成的新字符串的步数,一旦相等了就可以直接返回。
start = input()
end = input()
from collections import deque
def bfs():
# 创建容器并初始化
# 创建字典存储每次变换字符串的步数
dic = {}
dic[start] = 0
# 创建队列
queue = deque()
queue.append(start)
d = [[1, 0], [-1, 0], [0, 1], [0, -1]]
# 进入循环
while queue:
now_start = list(queue.popleft())
# 循环结束出口
if "".join(now_start) == end:
return dic["".join(now_start)]
point = now_start.index('.')
# 一维的下标转换为二维下标:
# 转换公式:x = index//二维数组的宽度 y = index%二维数组的宽度
x = point // 3
y = point % 3
step = dic["".join(now_start)]
for xx,yy in d:
dx = x+xx
dy = y+yy
if dx>=0 and dx<3 and dy>=0 and dy<3:
new_start = now_start.copy()
# 二维转一维
# 转换公式:index = x*二维数组的宽度 + y
new_start[point],new_start[dx*3+dy] = new_start[dx*3+dy],new_start[point]
if "".join(new_start) not in dic.keys():
# dic.setdefault("".join(new_start),step+1)
dic["".join(new_start)] = step+1
queue.append("".join(new_start))
return -1
print(bfs())
知识点笔记:



2.4.青蛙跳杯子(学完九宫重排再做bingo)
1.青蛙跳杯子 - 蓝桥云课 (lanqiao.cn)
那学完九宫重排之后写这道题就非常简单了,并且这道题还是一维的,不用转换,其他思路跟九宫重排一模一样。
题目中所说的三种动作,虽然说是青蛙的跳动,但是把当作杯子的跳动去处理就会简单很多,总之学完九宫重排之后这道题就是很简单了。
start = input()
end = input()
from collections import deque
def bfs():
d = [1, -1, 2, -2, 3, -3]
queue = deque()
queue.append(start)
dic = {}
dic[start] = 0
while queue:
now_start = list(queue.popleft())
point = now_start.index('*')
step = dic["".join(now_start)]
if "".join(now_start) == end:
return dic["".join(now_start)]
for xx in d:
dx = point+xx
new_start = now_start.copy()
if dx in range(0, len(start)):
new_start[point], new_start[dx] = new_start[dx], new_start[point]
if "".join(new_start) not in dic.keys():
dic["".join(new_start)] = step+1
queue.append("".join(new_start))
return -1
print(bfs())
2.5. 长草
0长草 - 蓝桥云课 (lanqiao.cn)
这道题一开始的思路是想到了非连通图的遍历,然后我就是这么一个思路,先找到一个初始化的点先进行广度优先搜索,只进行K层的搜索,但是我一直都无法找到怎样去把握让搜索测层数是我想要的,不知道这个怎么解决,在这里遇到了大问题,然后再遍历我的地图看看还有没有另外的点需要搜索的。所以这个思路就需要两个数组,一个是队列,一个是记录我的访问状态,但是我并没有解决。
然后就换了一个思路,将节点先依次入队,再对每一个节点进行广度优先搜索,这个就比较好控制,多少层那我就调用多少次的bfs。这里有一个点就在于我的while循环的出口是与队列的长度有关(或者是说节点的个数),因为队列只有把所有的节点都遍历完成之后才算。
总之这道题也是一道与之前有着一点区别的,也可以算作是遍历非连通图的一种方法。
n, m = map(int,input().split())
maps = []
for i in range(n):
l = list(input())
maps.append(l)
k = int(input())
from collections import deque
queue = deque()
for i in range(n):
for j in range(m):
if maps[i][j] == 'g':
queue.append((i,j))
d = [[1,0],[-1,0],[0,1],[0,-1]]
def bfs():
ans = len(queue)
while ans:
x1, y1 = queue.popleft()
for xx,yy in d:
dx = x1+xx
dy = y1+yy
# if dx<0 or dx>=n or dy<0 or dy>=m:
# continu
if 0<=dx<n and 0<=dy<m and maps[dx][dy] == '.':
maps[dx][dy] = 'g'
queue.append((dx,dy))
ans -= 1
for i in range(k):
bfs()
for i in maps:
print(''.join(i)) 
3.总结
学习还在继续,持续学习加油!!!!