准备
这是Numpy数据处理的示例演绎系列文章的第三篇,我的前两篇文章为:
政安晨:【示例演绎】【Python】【Numpy数据处理】快速入门(一)![]() https://blog.csdn.net/snowdenkeke/article/details/136125773
https://blog.csdn.net/snowdenkeke/article/details/136125773
政安晨:【示例演绎】【Python】【Numpy数据处理】快速入门(二)![]() https://blog.csdn.net/snowdenkeke/article/details/136127590
https://blog.csdn.net/snowdenkeke/article/details/136127590
小伙伴们准备好环境后,咱们开始。
数组的索引和切片、合并与拆分、复制和排序、查找和筛选,以及改变数组结构、数组I/O等,这些是数组操作的基本技术。
其中最抽象的是查找和筛选,但这也是数组操作中最重要、最精髓的一部分,在数组操作中用好查找和筛选才能避免使用循环,这是数组操作的最高境界。
索引和切片
在Numpy中,索引和切片是常用的操作用于获取和修改数组中的元素。
索引是指通过指定元素的位置来访问数组中的值。
Numpy中的索引是从0开始的,可以使用方括号来指定索引位置。
例如,对于一个一维数组,可以使用array[index]来访问特定位置的值。
切片是指通过指定范围来访问数组中的一部分元素。
Numpy使用start:stop:step的形式来指定切片的范围。其中,start表示切片开始位置(包含),stop表示切片结束位置(不包含),step表示步长,默认为1。可以使用冒号来省略某个参数。
例如,对于一个一维数组,可以使用array[start:stop:step]来获取数组中指定范围的元素。
索引和切片也可以用于多维数组。
对于二维数组,可以使用array[row_index, column_index]来访问特定位置的值;
对于多维数组,可以使用array[index1, index2, index3, ...]来指定多个维度的索引位置。
除了获取值,索引和切片还可以用于修改数组中的元素,可以通过给特定位置赋值来修改该位置的值。
需要注意的是,Numpy中的索引和切片操作都返回一个新的数组,而不是原始数组的视图,如果需要修改原始数组,需要使用array.copy()方法创建一个副本。
先准备一些代码:
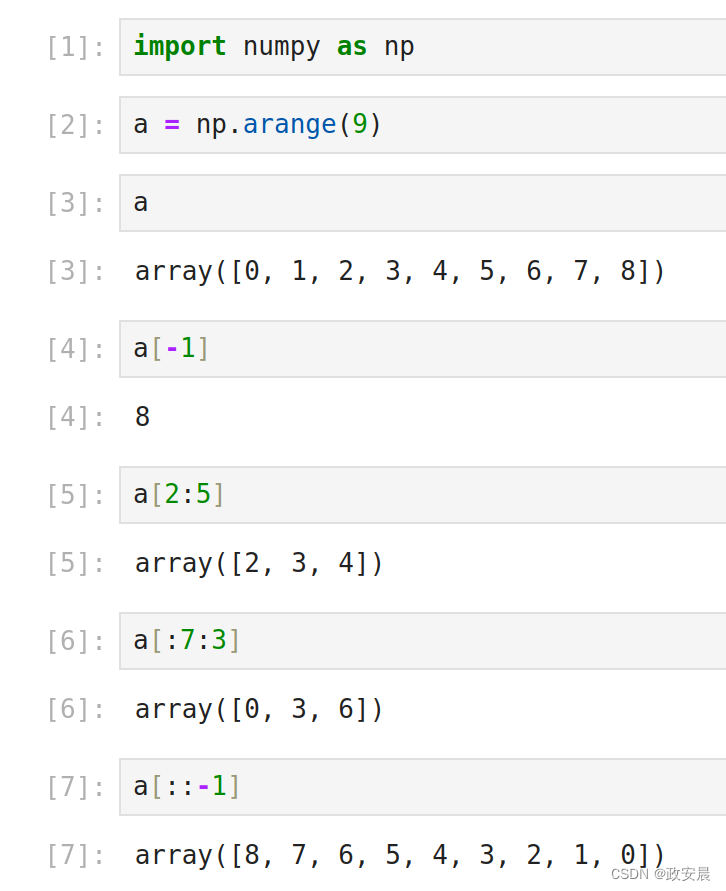
a = np.arange(9)
# 最后一个元素
a[-1]
# 返回第2到第5个元素
a[2:5]
# 返回第0到第7个元素,步长为3
a[:7:3]
# 返回逆序的数组
a[::-1] 执行如下:
对于多维数组操作,NumPy数组比Python的列表更加灵活、强大。
假设有一栋楼,共2层,每层的房间都是3行4列,那我们可以用一个三维数组来保存每个房间的居住人数(也可以是房间面积等其他数值信息)。
# 2层3行4列
a = np.arange(24).reshape(2,3,4)
a
# 虽然可以这样索引
a[1][2][3]
# 但这样才是规范的用法
a[1,2,3]
# 所有楼层的第0行第0列
a[:,0,0]
# 1层的所有房间,等价于a[0]或a[0,...]
a[0,:,:]
# 所有楼层所有排的第1到第3列
a[:,:,1:3]
# 2层每一行的最后一个房间
a[1,:,-1] 执行如下:

上述代码可以看出,对多维数组索引或切片得到的结果的维度不是确定的。
特别注意:切片返回的数组不是原始数据的副本,而是指向与原始数组相同的内存区域。数组切片不会复制内部数组数据,只是产生了原始数据的一个新视图。
代码如下:
a = np.arange(12).reshape(3,4)
a
# 数组b是数组a的切片
b = a[1:,2:]
b
# 改变数组b的值,也会同时影响数组a
b[:,:] = 99
b
a执行:

上述代码中,数组b是数组a的切片,当改变数组b的元素时,数组a也同时发生了改变,这就证明了切片返回的数组不是一个独立数组,而是指向与原始数组相同的内存区域。
改变数组结构
NumPy之所以拥有极高的运算速度,除了并行、广播和矢量化等技术因素外,其数组存储顺序和数组视图相互独立也是一个很重要的原因。
正因为如此,改变数组结构自然是非常便捷的操作,改变数组结构的操作通常不会改变所操作的数组本身的存储顺序,只是生成了一个新的视图。
np. resize( )函数是个例外,它不返回新的视图,而是真正改变了数组的存储顺序。
ndarray自带多个改变数组结构的方法,在大部分情况下学会ndarray.reshape( )函数即可,我们在前面已经多次用到该函数,在某些情况下,翻滚轴函数numpy.rollaxis( )才是最佳的选择,需要多花一些时间去了解它。
以下是改变数组结构的几个常用函数:
ndarray.reshape( ):按照指定的结构(形状)返回数组的新视图,不改变原数组。
ndarray.ravel( ):返回多维数组一维化的视图,不改变原数组。
ndarray.transpose( ):返回行变列的视图,不改变原数组。
ndarray.resize( ):按照指定的结构(形状)改变原数组,无返回值。
numpy.rollaxis( ):翻滚轴,返回新的视图,不改变原数组。
接下来继续演绎这几个改变数组结构的函数的用法:
a = np.arange(12)
# reshape()函数返回数组a的一个新视图,但不会改变数组a
b = a.reshape((3,4))
a.shape
b.shape
b is a
b.base is a
# resize()函数没有返回值,但真正改变了数组a的结构
a.resize([4,3])
a.shape
# 返回多维数组一维化的视图,但不会改变原数组
a.ravel()
# 返回行变列的视图,但不会改变原数组
a.transpose()
# 返回行变列的视图,等价于transpose()函数
a.T
# 翻滚轴,1轴变0轴
np.rollaxis(a, 1, 0) 咱们构建一个列表:

演绎reshape:

演绎resize:

继续演绎:

翻滚轴函数有一个很容易理解的应用,就是用它来实现图像的通道分离,下面的代码生成了一个宽为800像素、高为600像素的彩色随机噪声图,使用翻滚轴函数可以将其分离成RGB三个颜色通道。最后两行代码导入pillow模块,从而可以直观地看到这幅噪声图。
img = np.random.randint(0, 256, (600, 800, 3), dtype=np.uint8)
img.shape
# 将图像数据分离成RGB三个颜色通道
r, g, b = np.rollaxis(img, 2, 0)
r.shape, g.shape, b.shape
# 导入pillow模块的Image
from PIL import Image
# 显示随机生成的噪声图
Image.fromarray(img).show() 演绎如下:

将图像数据分离:
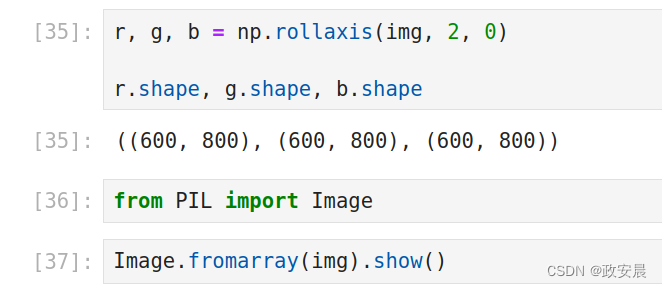
这是上述代码随机生成的图像:

合并
NumPy数组一旦创建就不能再改变其元素数量。
如果要动态改变数组元素数量,只能通过合并或拆分的方法生成新的数组,对于刚上手NumPy的程序员来说,最大的困惑就是不能使用append( )函数向数组内添加元素,甚至都找不到append( )函数。其实,NumPy仍然保留了append( )函数,只不过这个函数不再是数组的函数,而是升级到最外层的NumPy命名空间了,并且该函数的功能不再是追加元素,而是合并数组,其代码如下:
np.append([[1, 2, 3]], [[4, 5, 6]])
np.append([[1, 2, 3]], [[4, 5, 6]], axis=0)
np.append([[1, 2, 3]], [[4, 5, 6]], axis=1)演绎:

不过,append( )函数还不够好用,推荐使用stack( )函数及其兄弟函数:hstack( )水平合并函数、vstack( )垂直合并函数和dstack( )深度合并函数。
接下来演绎这三个函数的用法:
a = np.arange(4).reshape(2,2)
b = np.arange(4,8).reshape(2,2)
# 水平合并
np.hstack((a,b))
# 垂直合并
np.vstack((a,b))
# 深度合并
np.dstack((a,b)) 演绎:

stack( )函数使用axis轴参数指定合并的规则,请演绎下面例子中axis轴参数的用法。
a = np.arange(60).reshape(3,4,5)
b = np.arange(60).reshape(3,4,5)
a.shape, b.shape
np.stack((a,b), axis=0).shape
np.stack((a,b), axis=1).shape
np.stack((a,b), axis=2).shape
np.stack((a,b), axis=3).shape演绎如下:

拆分
因为数组切片非常简单,所以数组拆分应用较少,拆分是合并的逆过程,最常用的函数是split( ),其代码如下:
a = np.arange(16).reshape(2,4,2)
# 水平方向拆分成2部分
np.hsplit(a, 2)
# 垂直方向拆分成2部分
np.vsplit(a, 2)
# 深度方向拆分成2部分
np.dsplit(a, 2) 演绎,水平方向拆分成2部分:
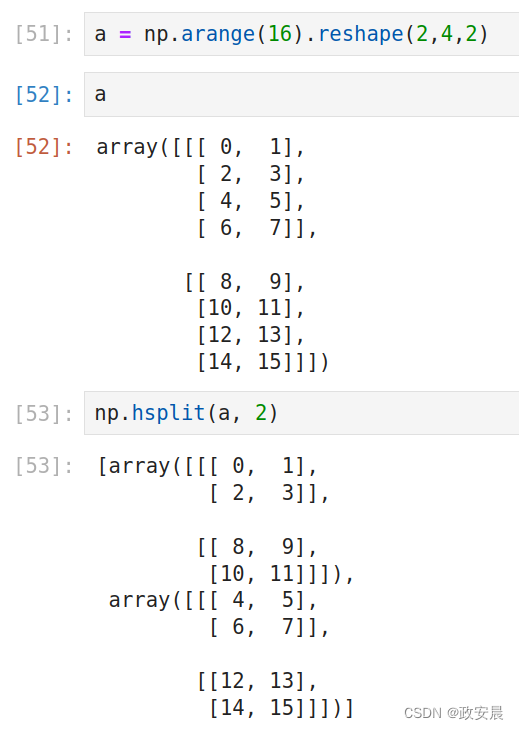
演绎,垂直方向拆分成2部分:

演绎,深度方向拆分成2部分:

复制
改变数组结构返回的是原数组的一个新视图,而不是原数组的副本,浅复制(view)和深复制(copy)则是创建原数组的副本,但二者之间也有细微差别:
浅复制(view)是共享内存,深复制(copy)是独享内存。
代码如下:
a = np.arange(6).reshape((2,3))
b = a.view()
b is a
b.base is a
b.flags.owndata
c = a.copy()
c is a
c.base is a
c.flags.owndata演绎上述代码第一部分:

演绎上述代码第二部分:
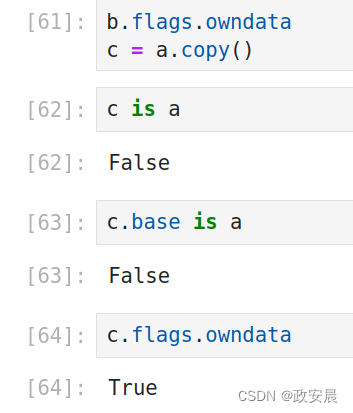
排序
NumPy数组有两个排序函数,一个是sort( ),另一个是argsort( ),sort( )函数返回输入数组的排序副本,argsort( )函数返回的是数组值从小到大的索引号,从函数原型看,这两个函数的参数完全一致。
numpy.sort(arr, axis=-1, kind='quicksort', order=None)
numpy.argsort(arr, axis=-1, kind='quicksort', order=None)第1个参数arr,是要排序的数组;
第2个参数axis,也就是轴,指定排序的轴,默认值-1表示没有指定排序轴,返回结果将沿着最后的轴排序;
第3个参数kind,表示排序方法,默认为“quicksort”(快速排序),其他选项还有“mergesort”(归并排序)和“heapsort”(堆排序);
第4个参数order,指定用于排序的字段,前提是数组包含该字段。
a = np.random.random((2,3))
a
# 返回行内从小到大排序的索引号(列排序),相当于axis=1(最后的轴)
np.argsort(a)
# 返回行内从小到大排序的一个新数组(列排序)
np.sort(a)
# 返回列内从小到大排序的一个新数组(行排序)
np.sort(a,axis=0)演绎如下:

下面演绎的是排序字段的使用,先定义一个新的数据类型dt,它类似于一个字典,有姓名name和年龄age两个键值对,姓名的长度为10个字符,年龄的数据类型是整型。
代码如下:
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("zh",21),("wang",25),("li",17), ("zhao",27)], dtype = dt)
# 如果指定姓名排序,结果是李王张赵
np.sort(a, order='name')
# 如果指定年龄排序,结果则是李张王赵
np.sort(a, order='age') 演绎如下:

查找
这里约定查找是返回数组中符合条件的元素的索引号,或返回和数组具有相同结构的布尔型数组,元素符合条件在布尔型数组中对应True,否则对应False,查找分为最大值和最小值查找、非零元素查找、使用逻辑表达式查找和使用where条件查找这4种方式。
1. 最大值和最小值查找
下面的代码演示了返回数组中最大值和最小值的索引号,如果是多维数组,这个索引号是数组转成一维之后的索引号:
a = np.random.random((2,3))
a
np.argmax(a)
np.argmin(a)演绎:
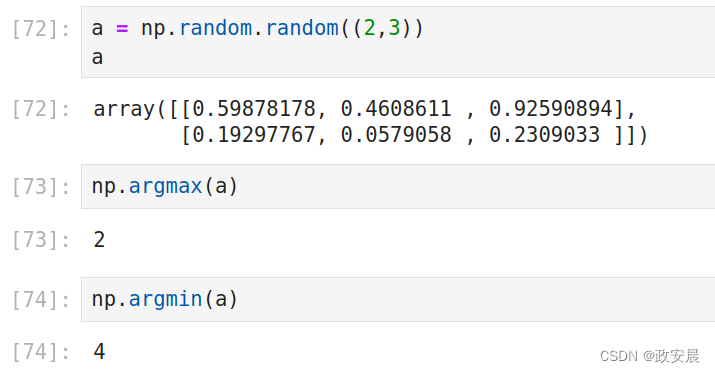
2. 非零元素查找
下面的代码演示了返回数组中非零元素的索引号,返回的结果是一个元组:
a = np.random.randint(0, 2, (2,3))
a
np.nonzero(a)演绎:

3. 使用逻辑表达式查找
下面的代码演示了使用逻辑表达式查找符合条件的元素,返回结果是一个和原数组结构相同的布尔型数组,元素符合条件在布尔型数组中对应True,否则对应False。
代码如下:
a = np.arange(10).reshape((2,5))
a
(a>3)&(a<8)演绎如下:

4. 使用where条件查找
np.where( )函数返回数组中满足给定条件的元素的索引号,其结构为元组,元组的第k个元素对应符合条件的元素在数组k轴上的索引号。这句话可以简单理解为,一维数组返回一个元素的元组,二维数组返回两个元素的元组,依此类推。np.where( )函数还可以用于替换符合条件的元素。
代码如下:
a = np.arange(10)
a
np.where(a < 5)
a = a.reshape((2, -1))
a
np.where(a < 5)
# 满足条件的元素不变,其他元素乘10
np.where(a < 5, a, 10*a) 演绎如下:

筛选
筛选是返回符合条件的元素。
筛选条件有三种表示方式:
一是使用np.where( )函数返回的Python元组。
二是使用逻辑表达式返回的布尔型数组。
三是使用整型数组。
其代码如下:
a = np.random.random((3,4))
a
# 返回大于0.5的元素(使用np.where()函数返回的Python元组)
a[np.where(a>0.5)]
# 返回大于0.3且小于0.7的元素(使用逻辑表达式返回的布尔型数组)
a[(a>0.3)&(a<0.7)]
# 返回整型数组指定的项(使用整型数组)
a[np.array([2,1])]
a = a.ravel()
# 返回整型数组指定的项(使用整型数组)
a[np.array([3,5,7,11])]
# 返回整型数组指定的项(使用整型数组)
a[np.array([[3,5],[7,11]])] 演绎如下:
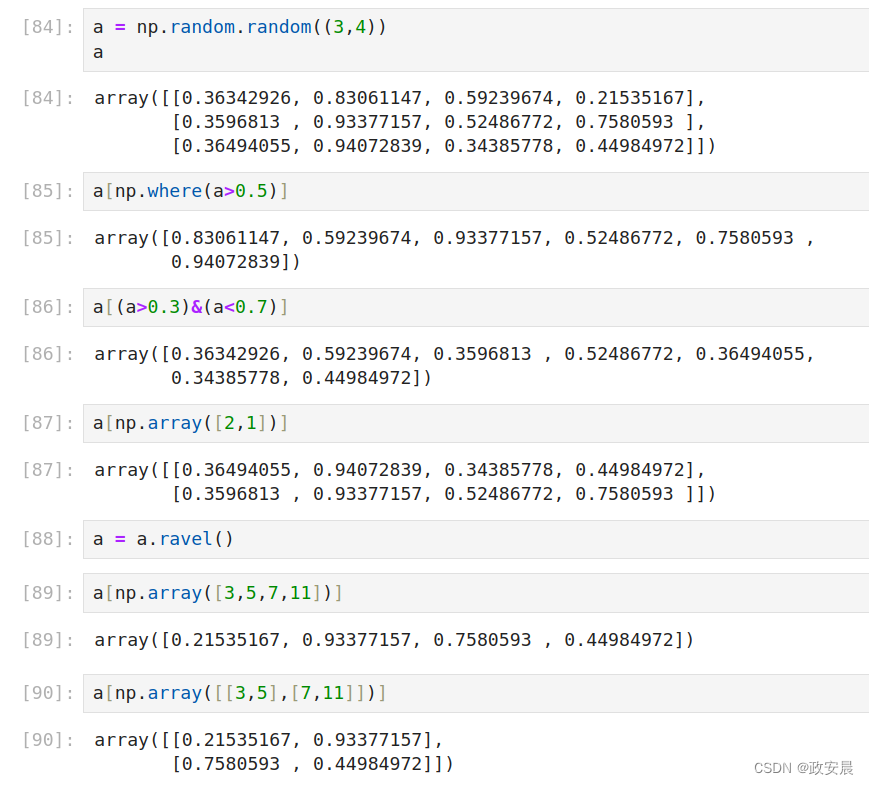
告一段落
咱们先演绎到这里,基本完成了Numpy对数组操作的感知。