[嵌入式AI从0开始到入土]嵌入式AI系列教程
注:等我摸完鱼再把链接补上
可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。
第1期 昇腾Altas 200 DK上手
第2期 下载昇腾案例并运行
第3期 官方模型适配工具使用
第4期 炼丹炉的搭建(基于Ubuntu23.04 Desktop)
第5期 炼丹炉的搭建(基于wsl2_Ubuntu22.04)
第6期 Ubuntu远程桌面配置
第7期 下载yolo源码及样例运行验证
第8期 在线Gpu环境训练(基于启智ai协作平台)
第9期 转化为昇腾支持的om离线模型
第10期 jupyter lab的使用
第11期 yolov5在昇腾上推理
第12期 yolov5在昇腾上应用
第13期_orangepi aipro开箱测评
第14期 orangepi_aipro小修补含yolov7多线程案例
未完待续…
文章目录
- [嵌入式AI从0开始到入土]嵌入式AI系列教程
- 前言
- 一、opencv安装
- 1、下载源码
- 2、配置cmake
- 3、编译
- 4、安装
- 5、验证安装
- 二、torch_npu的安装
- 1、克隆torch_npu代码仓
- 2、构建镜像
- 3、进入Docker容器
- 4、编译torch_npu
- 5、安装
- 6、验证安装
- 三、sampleYOLOV7MultiInput案例
- 1、环境准备
- 2、下载模型和数据
- 3、转换模型
- 4、编译程序
- 5、运行推理
- 6、查看推理结果
- 四、问题
- 1、自动休眠问题
- 2、 vnc配置
- 3、dialog: command not found
- 3、apt autoremove
- 4、apt upgrade在firebox卡住
- 5、jupyter lab外部网络访问
- 6、jupyter需要输入密码或者token
- 总结
前言
注:本文基于orangepi_aipro于2023.2.3公布的ubuntu_desktop镜像
拿到手有段时间了,小问题还是比较的多的,整体上和Atlas 200i DK A2差不多。
emmm,没错,连产品名也套娃了。

说明:本文是作者测试成功并生成完善的镜像后写的,因此截图会比较少,存粹是因为为了一张图需要重走一遍,而一遍需要好几个小时,也可能需要好几遍才能把图凑齐。因此只挑重点截图了。
一、opencv安装
虽然镜像内带了opencv4.5.4,但是opencv应该是从4.7.0开始支持CANN后端的。这里我参考opencv官方github仓库的Wiki,重新编译了支持cann的opencv4.9.0,见文章顶部的资源。
至于为什么要换版本,看下图
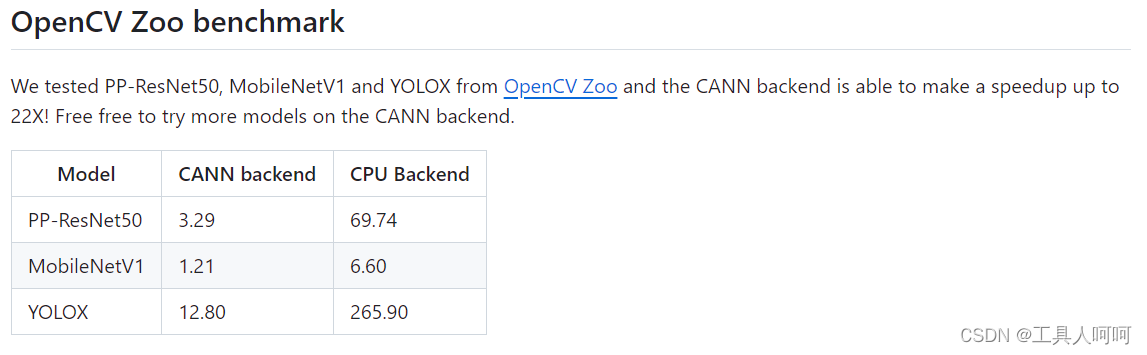
使用我提供的资源时,请将其放置于/home/HwHiAiUser目录下,进入/home/HwHiAiUser/opencv4/build目录,执行第四步即可
1、下载源码
git clone https://github.com/fengyuentau/opencv.git
cd opencv
git checkout cann_backend_221010
git clone https://gitee.com/opencv/opencv.git #也可以直接使用gitee镜像
2、配置cmake
这里是大坑
cd opencv
mkdir build
cd build
cmake -D WITH_CANN=ON\
-D PYTHON3_EXECUTABLE=/usr/local/miniconda3/bin/python3.9 \
-D CMAKE_INSTALL_PREFIX=/usr \
-D BUILD_opencv_python3=ON \
-D BUILD_opencv_gapi=OFF \
-D PYTHON3_LIBRARY=/usr/local/miniconda3/lib/libpython3.so \
-D PYTHON3_INCLUDE_DIR=/usr/local/miniconda3/lib/ \
-D PYTHON3_NUMPY_INCLUDE_DIRS=/usr/local/miniconda3/lib/python3.9/site-packages/numpy/core/include \
..
-
不要更改
CMAKE_INSTALL_PREFIX参数,会导致python import或者cmake include报错找不到文件 -
请确保cmake后生成如下图所示的配置
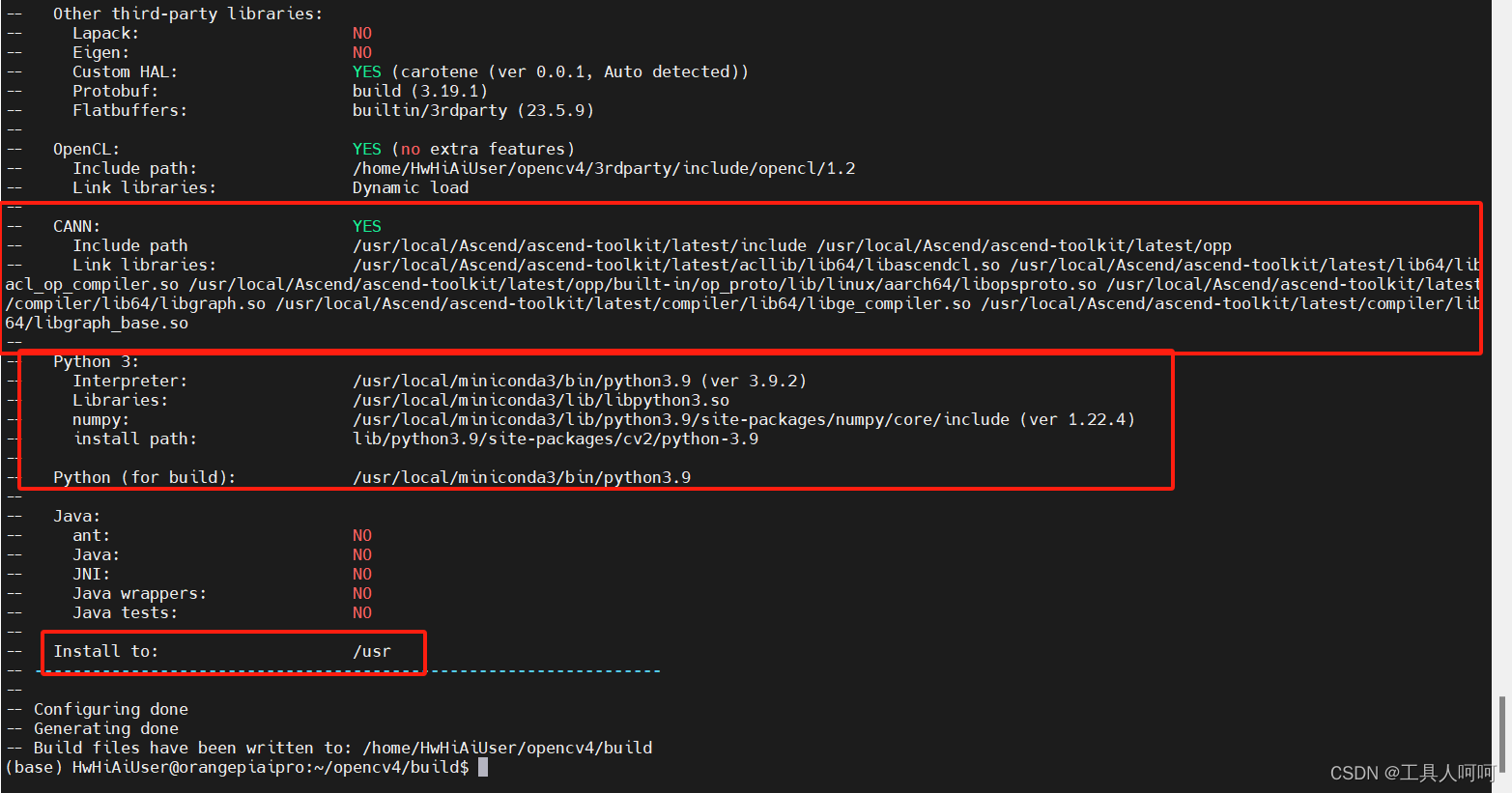
-
如非必要,在生成配置后,不要更改opencv文件夹包括内部文件的位置,否则将会导致错误。
-
如果你的python不是使用的官方镜像miniconda的base环境,需要在配置时修改为自己的路径
3、编译
make -j$(nproc) #-j$(nproc) 表示使用所有可用的 CPU 核心来并行编译
- 这里一定要在开发板上编译,大约需要2小时左右。
- 编译到97%后可能会报错
fatal error: Python.h: No such file or directory,实际上这个文件是在的,我尝试过各种方法,不仅没用,还导致从头开始编译。这里我用了一个最简单粗暴的方法,就是把/usr/local/miniconda3/include/python3.9整个文件夹内的东西都复制的到opencv/build文件夹内,完美解决。
4、安装
sudo make install
5、验证安装
新建mobilenetv1.py,执行python3 mobilenetv1.py
import numpy as np
import cv2 as cv
def preprocess(image):
out = image.copy()
out = cv.resize(out, (256, 256))
out = out[16:240, 16:240, :]
out = cv.dnn.blobFromImage(out, 1.0/255.0, mean=(0.485, 0.456, 0.406), swapRB=True)
out = out / np.array([0.229, 0.224, 0.225]).reshape(1, -1, 1, 1)
return out
def softmax(blob, axis=1):
out = blob.copy().astype(np.float64)
e_blob = np.exp(out)
return e_blob / np.sum(e_blob, axis=axis)
image = cv.imread("/path/to/image") # replace with the path to your image
input_blob = preprocess(image)
net = cv.dnn.readNet("/path/to/image_classification_mobilenetv1_2022apr.onnx") # replace with the path to the model
net.setPreferableBackend(cv.dnn.DNN_BACKEND_CANN)
net.setPreferableTarget(cv.dnn.DNN_TARGET_NPU)
net.setInput(input_blob)
out = net.forward()
prob = softmax(out, axis=1)
_, max_prob, _, max_loc = cv.minMaxLoc(prob)
print("cls = {}, score = {:.4f}".format(max_loc[0], max_prob))
或者使用c++版本
CMakeList.txt
cmake_minimum_required(VERSION 3.5.1)
project(cann_demo)
# OpenCV
find_package(OpenCV 4.6.0 REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
# PP-ResNet50
add_executable(ppresnet50 ppresnet50.cpp)
target_link_libraries(ppresnet50 ${OpenCV_LIBS})
# MobileNetV1
add_executable(mobilenetv1 mobilenetv1.cpp)
target_link_libraries(mobilenetv1 ${OpenCV_LIBS})
# YOLOX
add_executable(yolox yolox.cpp)
target_link_libraries(yolox ${OpenCV_LIBS})
mobilenetv1.cpp
#include <iostream>
#include <vector>
#include "opencv2/opencv.hpp"
void preprocess(const cv::Mat& src, cv::Mat& dst)
{
src.convertTo(dst, CV_32FC3);
cv::cvtColor(dst, dst, cv::COLOR_BGR2RGB);
// center crop
cv::resize(dst, dst, cv::Size(256, 256));
cv::Rect roi(16, 16, 224, 224);
dst = dst(roi);
dst = cv::dnn::blobFromImage(dst, 1.0/255.0, cv::Size(), cv::Scalar(0.485, 0.456, 0.406));
cv::divide(dst, cv::Scalar(0.229, 0.224, 0.225), dst);
}
void softmax(const cv::Mat& src, cv::Mat& dst, int axis=1)
{
using namespace cv::dnn;
LayerParams lp;
Net netSoftmax;
netSoftmax.addLayerToPrev("softmaxLayer", "Softmax", lp);
netSoftmax.setPreferableBackend(DNN_BACKEND_OPENCV);
netSoftmax.setInput(src);
cv::Mat out = netSoftmax.forward();
out.copyTo(dst);
}
int main(int argc, char** argv)
{
using namespace cv;
Mat image = imread("/path/to/image"); // replace with the path to your image
Mat input_blob;
preprocess(image, input_blob);
dnn::Net net = dnn::readNet("/path/to/image_classification_mobilenetv1_2022apr.onnx"); // replace with the path to the model
net.setPreferableBackend(dnn::DNN_BACKEND_CANN);
net.setPreferableTarget(dnn::DNN_TARGET_NPU);
net.setInput(input_blob);
Mat out = net.forward();
Mat prob;
softmax(out, prob, 1);
double min_val, max_val;
Point min_loc, max_loc;
minMaxLoc(prob, &min_val, &max_val, &min_loc, &max_loc);
std::cout << cv::format("cls = %d, score = %.4f\n", max_loc.x, max_val);
return 0;
}
二、torch_npu的安装
这里我参考了官方文档
注意,需要提前安装docker
sudo apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
sudo apt install docker-ce
sudo systemctl start docker
sudo systemctl enable docker #设置Docker服务开机自启
sudo docker run hello-world #验证Docker是否安装成功
1、克隆torch_npu代码仓
git clone https://gitee.com/ascend/pytorch.git -b v2.1.0-5.0.0 --depth 1
2、构建镜像
cd pytorch/ci/docker/{arch} # {arch} for X86 or ARM
docker build -t manylinux-builder:v1 .
3、进入Docker容器
docker run -it -v /{code_path}/pytorch:/home/pytorch manylinux-builder:v1 bash
# {code_path} is the torch_npu source code path
4、编译torch_npu
cd /home/pytorch
bash ci/build.sh --python=3.9
5、安装
pip install ./torch_npu-2.1.0+gitb2bbead-cp39-cp39-linux_aarch64.whl
6、验证安装
终端执行
python
import torch
import torch_npu
x = torch.randn(2, 2).npu()
y = torch.randn(2, 2).npu()
z = x.mm(y)
print(z)
三、sampleYOLOV7MultiInput案例
官方镜像内置的是python案例,缺少c++案例,我们访问仓库,获取案例
git clone https://gitee.com/ascend/samples.git
为了压榨板子,我选取了sampleYOLOV7MultiInput这个案例
1、环境准备
cd sample_master/inference/modelInference/sampleYOLOV7MultiInput
sudo apt install libx11-dev
sudo apt-get install libjsoncpp-dev
sudo ln -s /usr/include/jsoncpp/json/ /usr/include/json
vim src/main.cpp
#添加
#include <fstream>
sudo ln -s /usr/include/opencv4/opencv2 /usr/include/opencv2 #这样就不用去将opencv版本了
这里readme中说需要安装x264,ffmpeg,opencv(3.x版本),但是经过我实测,镜像内都已经内置了。
2、下载模型和数据
cd data
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car0.mp4 --no-check-certificate
cd ../model
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/yolov7/yolov7x.onnx --no-check-certificate
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/yolov7/aipp.cfg --no-check-certificate
3、转换模型
atc --model=yolov7x.onnx --framework=5 --output=yolov7x --input_shape="images:1,3,640,640" --soc_version=Ascend310B4 --insert_op_conf=aipp.cfg
此处大约耗时10-15分钟。
4、编译程序
vim scripts/sample_build.sh
#将29行处make修改为以下内容,来使用多线程编译
make -j$(nproc)

sudo bash scripts/sample_build.sh
5、运行推理
bash scripts/sample_run.sh
注意,此处不要使用root用户执行,否则可能会提示找不到libascendcl.so
6、查看推理结果
推理大约需要1分钟,输出的视频在out文件夹,可以下载至本地查看
四、问题
1、自动休眠问题
这个问题仅存在于ubuntu桌面镜像,经过和群友的讨论和测试,在不登陆桌面的情况下大约5分钟会自动休眠,且无法唤醒。
目前解决方案如下,注意,这种方法会直接禁用休眠
sudo systemctl status sleep.target
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
2、 vnc配置
vncserver
netstat -antup | grep vnc #查看vnc端口
vncserver -kill :3 #我们需要杀掉刚才启动的vnc服务,我这是3,视情况而定
vim .vnc/xstartup
#添加以下内容,否则没有桌面,是黑屏的
startxfce4 &
#修改完成后重新启动vnc
vncserver
在本地使用vncview等工具使用ip:端口的方式访问
3、dialog: command not found
这个错误多在使用apt命令的时候会遇到,在Linux系统中,尝试执行含有该命令的脚本或命令行操作时发生。
解决方案如下
sudo apt install dialog
3、apt autoremove
慎用,经大量测试,会导致卸载netplan.io,这将导致除你当前正在使用的网络外,其余的全部嗝屁。
解决方案
sudo apt-mark hold netplan.io
4、apt upgrade在firebox卡住
这个应该是snap导致的,如果你暂时不需要新版的firebox,使用以下指令跳过升级
sudo apt-mark hold firebox #升级时保留选定的软件包
当我们需要升级保留的软件包或者指定的软件包时执行
sudo apt-mark unhold firebox #删除保留设置
sudo apt --only-upgrade install package1 package2 #只升级指定的package
5、jupyter lab外部网络访问
这里使用镜像notebook文件夹内自带的start.sh只能在本地浏览器访问,因此我建议使用命令手动启动jupyter,记得把ip改成开发板的ip,或者将其写入start.sh文件内
jupyter lab --ip 192.168.3.200 --allow-root --no-browser
6、jupyter需要输入密码或者token
这个密码只能说防君子,还使得我们使用变得麻烦,因此我选择直接去掉
执行以下命令,二选一即可
jupyter notebook password #连续两次回车,密码就变成空白了,直接点登录即可
当然,作为终极懒人,这还是太麻烦了
jupyter lab --generate-config
vim /home/HwHiAiUser/.jupyter/jupyter_lab_config.py
#找到c.ServerApp.token这一行,修改为
c.ServerApp.token = ''
总结
不得不说,这个官方镜像小毛病还是挺多的,我已经打包了一份镜像,关注我B站动态获取。


![[BIZ] - 1.金融交易系统特点](https://img-blog.csdnimg.cn/direct/6489c57a78dd4a3986cb1269c4e6dd2e.png)


![[职场] 投资顾问是做什么? #知识分享#其他#微信](https://img-blog.csdnimg.cn/img_convert/a818181f73740cbe5876cf253ddfa21e.png)