以实现爬虫一个简单的(SimFIR (doctrp.top))网址为例,需要遵循几个步骤:
1. 分析网页结构
- 首先,需要分析该网页的结构,了解图片是如何存储和组织的。这通常涉及查看网页的HTML源代码,可能还包括CSS和JavaScript文件。
- 检查图片URL的模式,看看是否有规律可循,这将有助于编写爬虫时定位和下载图片。
2. 编写爬虫代码
- 使用Python中的库,如
requests来访问网页,BeautifulSoup来解析HTML。 - 编写代码以遍历网页,定位图片链接,并将它们下载到您的本地存储。
3. 实现畸变矫正
- 选择适合的畸变矫正算法。需要使用像OpenCV这样的图像处理库。
- 编写代码以批量读取下载的图片,应用畸变矫正算法,并保存矫正后的图片。
4. 自动化和优化
- 使整个过程自动化,以便只需运行一个脚本即可完成从爬取到矫正的整个流程。
- 确保您的代码在处理大量数据时效率高并且稳定。
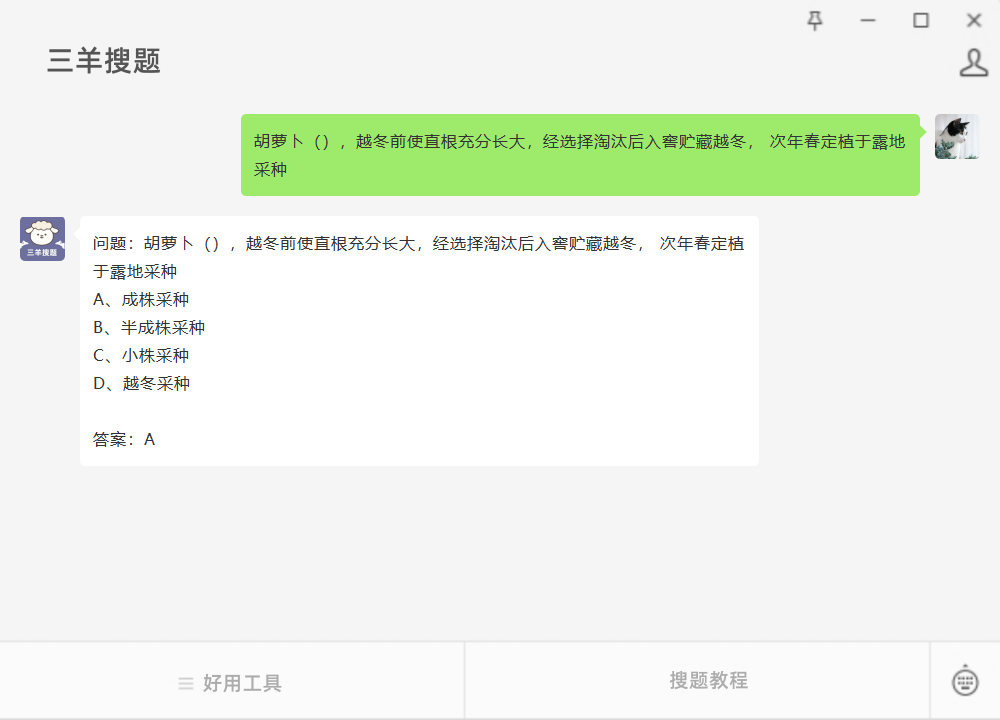
实战开始
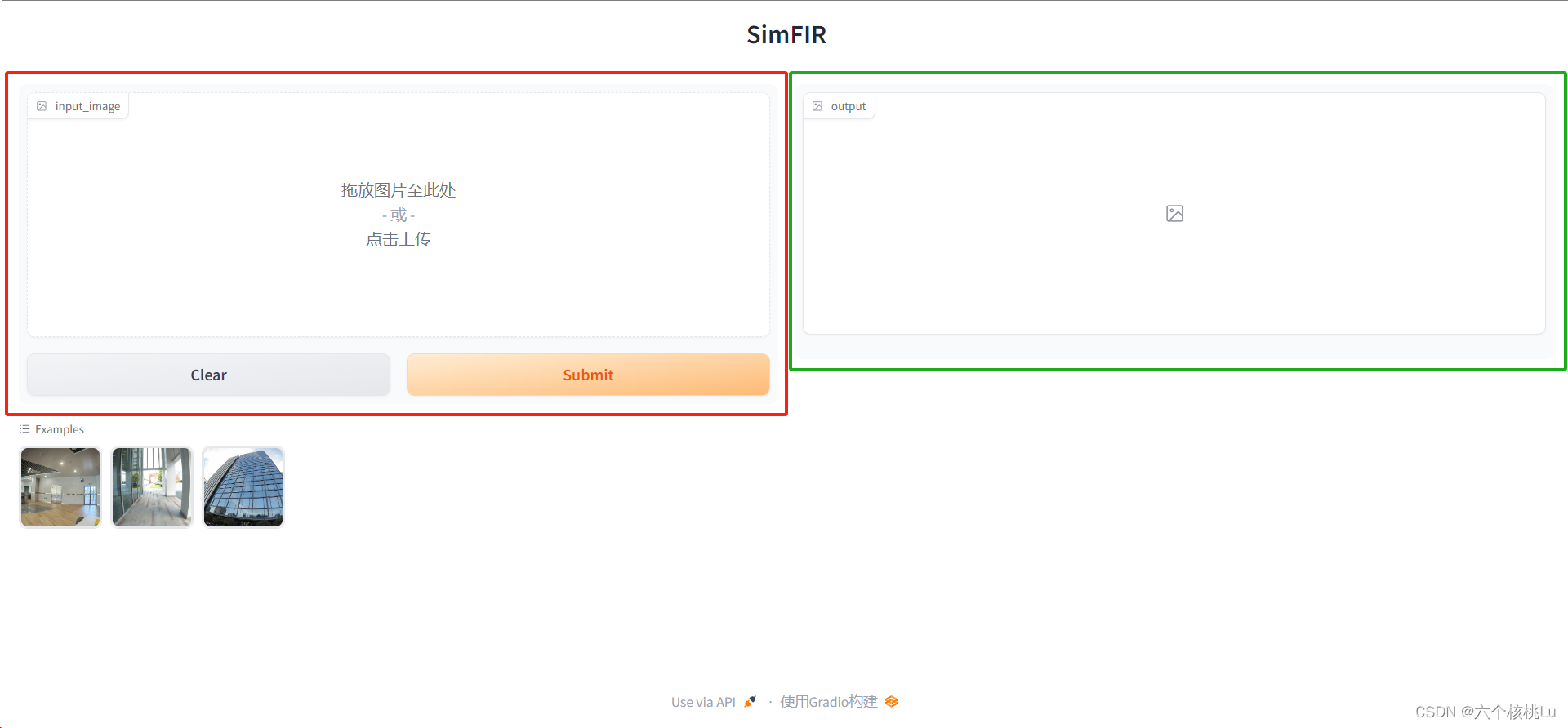
观察到红色框内"点击上传"处上传文件,然后点击按钮"Submit"实现文件上传;转换后的图片会显示在绿色框内,可点击"Download"按钮下载。
1)找到正确的URL
通常这些信息可以从网络请求中找到,使用浏览器的开发者工具观察网络请求。在浏览器中打开开发者工具(通常可以通过按F12或右键检查来打开),然后尝试正常上传一个文件。在"网络"(Network)选项卡中,可以监控到所有由网页发出的HTTP请求。找到文件上传时的请求,可以看到请求的URL、方法、请求头和请求体等信息。这里的URL就是上传接口的URL。
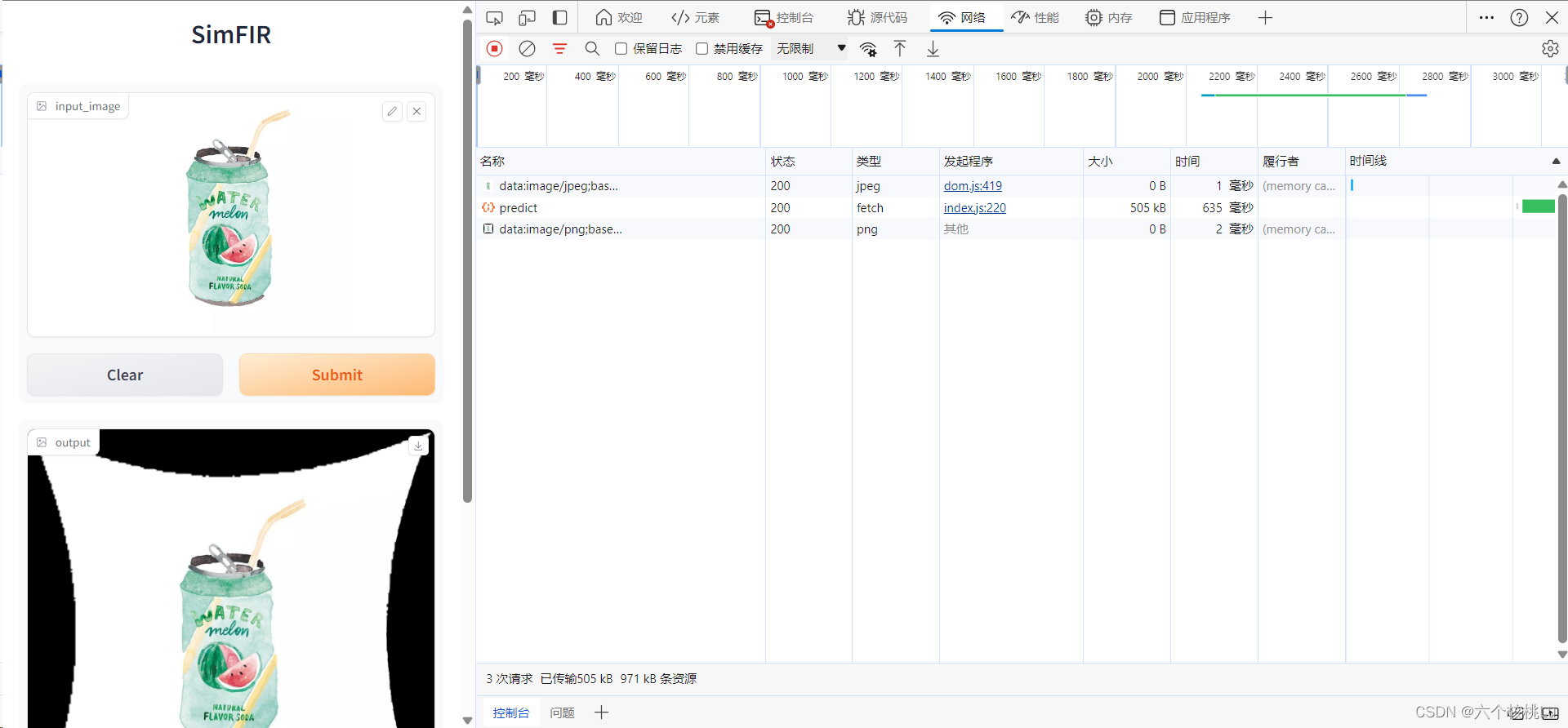
可以看到几个请求:
- 一个 data:image/jpeg;base64, 开头的请求,这是一个 Base64 编码的图片数据,可能是上传的图片。
- 一个名为 predict 的请求,这很可能是触发图片处理的 API 调用。
- 一个字体请求,看起来与图片上传和下载无关。
- 一个 data:image/png;base64, 开头的请求,这可能是处理后的图片。
从这些信息来看,处理后的图片可能是直接作为 Base64 编码的数据嵌入在某个API响应中的。如果 predict 请求是用来处理图片的,那么需要查看这个请求的详细内容,包括它的响应体。响应体中可能包含了处理后的图片的 Base64 编码数据。
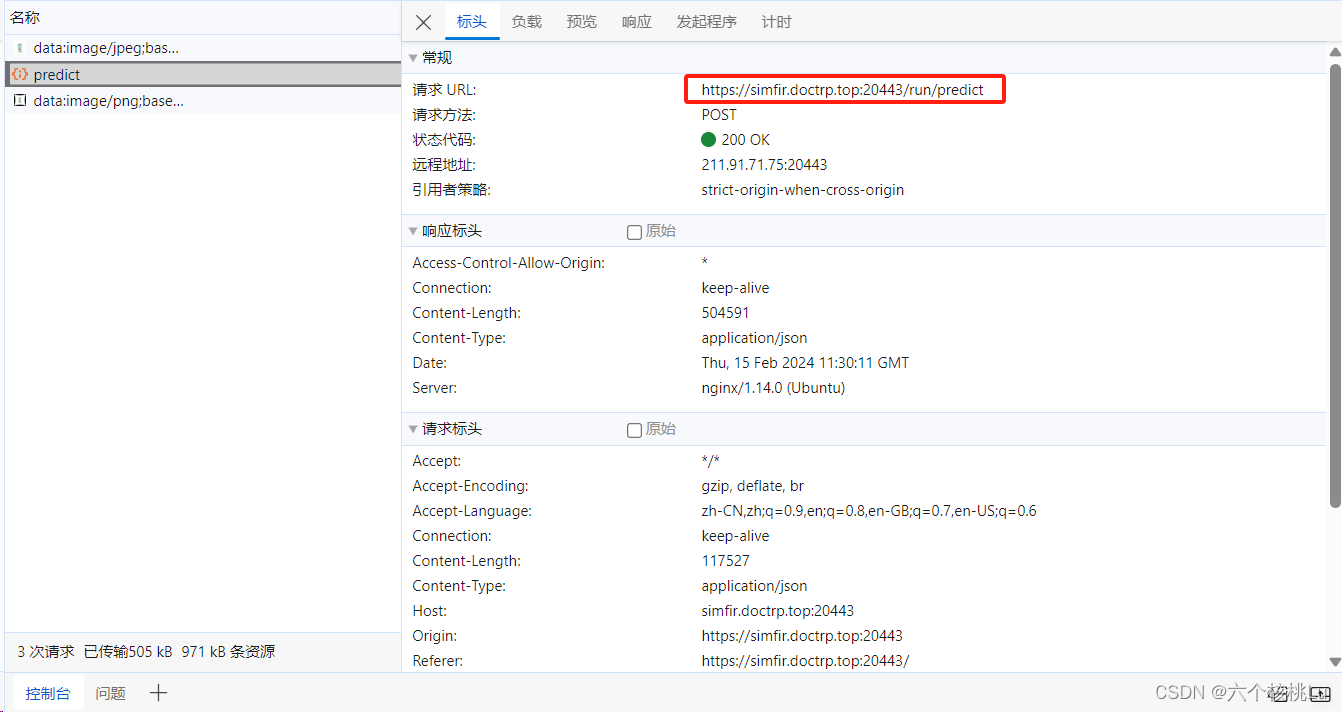
可以看到请求了predict的URL:
2)观察服务器期望的数据形式
在编程过程中,可以打印print(response.text),观察服务器的期望。
session = requests.Session()
response = session.post("https://simfir.doctrp.top:20443/run/predict", json={'data': [base64.b64encode(image_file.read()).decode('utf-8')]}, verify=False)
# 检查响应
if response.ok:
else:
print('获取处理后的图片失败,状态码:', response.status_code)
print(response.text)发现服务器期望在 data 字段中接收一个列表。这意味着需要将图片数据作为列表的元素发送,即使只有一个图片。服务器返回的是一个列表,那么从列表中提取图像数据。
接受到的processed_image_data_list[0]在解码中无法正确解码图片,困惑我好久,最后注意到是因为前面包含了'data:image/png;base64,'字段,然后去除字段就可以正常编码了。
3)代码实现
注释详细,简单易懂:
import requests
import time
import base64
import os
# 禁用由于未验证的SSL证书引发的警告
requests.packages.urllib3.disable_warnings()
# 指定服务器的URL
url = 'https://simfir.doctrp.top:20443/'
# 图片的本地路径,需要发送到服务器的图片
local_image_path = '1.jpg'
# 处理图像的服务器端点
processed_image_endpoint = url + 'run/predict'
# 创建一个会话,这在需要维持会话状态时很有用,例如进行多次请求
session = requests.Session()
# 以二进制读取模式打开本地图片文件
with open(local_image_path, 'rb') as image_file:
# 将图片文件编码为base64字符串,这是将二进制内容转换为可以通过JSON发送的文本格式的一种方式
image_encoded = base64.b64encode(image_file.read()).decode('utf-8')
# 准备请求数据,将编码的图片数据放入data字段中
data_to_send = {'data': [image_encoded]}
# 向服务器发送POST请求,并附上编码的图片数据,verify=False表示忽略SSL证书验证
response = session.post(processed_image_endpoint, json=data_to_send, verify=False)
# 检查响应状态码是否表明请求成功
if response.ok:
# 假设服务器会返回JSON格式的响应,并且包含了处理后的图像数据
processed_image_data_list = response.json().get('data')
# 检查返回的数据是否是列表形式
if processed_image_data_list and isinstance(processed_image_data_list, list):
# 获取列表中的第一个元素,即处理后的图像数据
encoded_data = processed_image_data_list[0]
# 假设数据以data:image/png;base64,开头,这需要被移除
encoded_data = encoded_data.split('data:image/png;base64,')[1].rstrip(' \n\r')
# 输出编码后的数据,用于调试
print(encoded_data)
# 如果编码数据长度不是4的倍数,则添加必要的'='填充字符
padding = '=' * (-len(encoded_data) % 4)
encoded_data_with_padding = encoded_data + padding
try:
# 尝试对带填充字符的base64字符串进行解码
image_data = base64.b64decode(encoded_data_with_padding)
# 指定输出图像的路径
output_image_path = os.path.join('output_image.png')
# 将解码后的图像数据写入到文件中
with open(output_image_path, 'wb') as file:
file.write(image_data)
# 打印成功消息
print('转换后的图片已成功保存到', output_image_path)
except base64.binascii.Error as e:
# 如果解码失败,打印错误信息
print("Base64 解码失败:", e)
else:
# 如果响应数据不是列表形式,打印错误信息
print('响应中未找到列表形式的图片数据')
else:
# 如果请求失败,打印状态码和错误信息
print('获取处理后的图片失败,状态码:', response.status_code)
print(response.text)
最终实现文件上传—> 处理文件—> 接收文件