文章目录
- 介绍
- 小结
介绍
从初代 GPT 到GPT-3,主要经历了下面几个关键时刻。
-
GPT:2018 年,OpenAl发布了这款基于Transformer架构的预训练语言模型,其参数数量为1.17亿(117M)。GPT运用单向自回归方法生成文本,先预训练大量无标签文本,再在特定任务上进行微调。GPT在多种 NLP任务上取得了显著进步。
-
GPT-2:2019年,OpenAI推出了GPT的升级版,拥有更多参数[15亿(1.5B)个],在训练数据量和模型复杂性上都有提升。GPT-2在文本生成方面表现优异,但其内容的真实性和连贯性也引发了滥用AI技术的担忧。
-
GPT-3:2020年,OpenAl再次升级发布的GPT-3,拥有1750亿(175B)个参数,成为当时世界上最大的预训练语言模型。GPT-3 在文本生成、摘要、问答、翻译等多个任务上表现出强大的性能优势。值得一提的是,GPT-3采用“零样本学习”或“少样本学习”,很多时候无须微调便可应对特定任务。
从GPT 到 GPT-3,GPT 系列模型确实越来越大,参数也越来越多(见下图),这也意味着它们能够处理的输入序列越来越长,生成的文本质量也越来越高。GPT-3能够生成非常流畅、准确的自然语言文本,且其生成的文本质量几乎可以和人类的写作相媲美。

GPT-3 参数数量增加到1750亿个带来的好处是,它能够更好地学习自然语言规律,理解输入序列中更多的上下文信息,因此能够生成更加连贯、准确的文本。另外, GPT-3 还增加了对多种语言,以及更加复杂的任务,如生成程序代码、回答自然语言问题等的支持。
ChatGPT 是 GPT 模型在聊天机器人任务上的应用,是在GPT-3.5 模型上进行优化后得到的产物。作为GPT 系列的第三代,它是在万亿词汇量的通用文字数据集上训练完成的。另外一个类似的模型,InstructGPT,也是建立在GPT-3.5 之上的。为了使 ChatGPT 在聊天机器人任务上表现出色,OpenAI对预训练数据集进行了微调,从而使ChatGPT 能够更好地处理对话中的上下文、情感和逻辑,这个过程,也被称为对预训练大模型的指令调优(Instruction Tuning)的过程。
而且,ChatGPT也应用了基于人类反馈的强化学习,也就是RLHF 技术,我们接下来会讲到这个技术。而ChatGPT 在 InstructGPT基础上还加入了安全性和合规性的考量,以免产生危害公众安全的回答。这个过程被称为对齐(Alignment),指让AI的目标与人类的目标一致,这包括让AI理解人类价值观和道德规则,避免产生不利于人类的行为。ChatGPT出现之后不久,OpenAI就进一步推出了推理能力更强的 GPT-4。如下图所示。
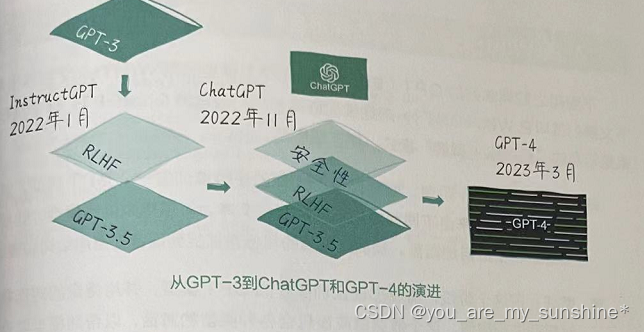
从GPT到 ChatGPT 和 GPT-4 的演进过程中,涌现出了很多关键技术,对它们的总结如表所示。

从Transformer到ChatGPT的发展,体现了自然语言处理技术在模型规模、性能、泛化能力、友好性、安全性和道德责任等方面的持续进步。这些进展使聊天机器人在各种应用场景中具有更高的准确性、可靠性和灵活性,在满足用户需求的同时,也更符合道德和规范。
小结
从GPT 到 GPT-3,GPT 系列模型确实越来越大,参数(训练数据范围、参数数量、层数、维度)也越来越多,这也意味着它们能够处理的输入序列越来越长,生成的文本质量也越来越高。
ChatGPT对预训练数据集进行了微调,从而能够更好地处理对话中的上下文、情感和逻辑。而且,ChatGPT也应用了基于人类反馈的强化学习,也就是RLHF 技术。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…