本课程主要介绍NLP相关,包括RNN、LSTM、Attention、Transformer、BERT等模型,以及情感识别、文本生成、机器翻译等应用
ShusenWang的个人空间-ShusenWang个人主页-哔哩哔哩视频 (bilibili.com)
(一)NLP基础
1、数据处理基础
数值特征(Numeric Features,特点是可以比较大小)和类别特征(Categorical Features)
类别特征需转换成数值特征,但不能只用一个标量表示(因为类别特征做数值运算无意义),需要用one-hot编码
- Age为numeric feature,可以直接保留,不做处理
- Gender为binary feature(二元特征),如0表示为女性,1表示为男性
- Nationality为categorical feature,需编码成数值向量。先转换成1~类别数之间的整数(建立一个字典来映射),再one-hot encoding(因为国籍映射成的整数不能表示大小)【为什么要从1开始?0保留来表示缺失或未知的数据,one-hot后为全0向量】

文本处理:
每个单词就是一个类别,单词就是categorical feature,把单词变为数值向量
- Tokenization(Text to Word):把文本(字符串)分割为单词列表
- 计算词频:计算每个单词出现的次数(哈希表,Key为word,Value为词频)。若word已经存在在哈希表里,将其value+1;若不存在,添加(word,1)进入哈希表
- 排序哈希表:让word按照词频递减的顺序排列
- 把词频换为index,词频最高的word的 index=1
- 统计词频的目的是:保留常用词,去掉低频词(减小字典里单词的个数,即vocabulary)
- one-hot encoding:通过查字典,把每个word映射成一个正整数,再把这个正整数变成one-hot向量(one-hot向量维度=vocabulary)
- 在字典里找不到的word,编码时可以忽略这个词,也可以编码成全0向量
为什么要去掉低频词?
一种情况是Name entities(姓名实体,无意义),或拼写错误
另一种原因是不希望vocabulary太大,vocabulary越大,one-hot向量维度越高,会让计算变慢,同时模型参数也会越多,容易过拟合
2、文本处理与词嵌入(Word Embedding)
The IMDB Movie Review Dataset,判断电影评论的情感是正面还是负面(二分类问题)
5w条电影评论,2w5k作为训练数据,2w5k作为测试数据
Text to Sequence
(1)tokenization(一个token就是一个单词,或一个字符):
- 通常会将大写转为小写(但Apple若转为apple,语义会发生变化)
- 去掉停用词(stop words),如:the、a、of等最高频的单词(对二分类没有帮助)
- 拼写纠错
(2)dictionary:统计词频、去掉低频词;让每个单词对应一个正整数。有了字典,就可以把每个单词映射为一个整数。这样一来,一句话就可以用一个正整数的列表表示,称为sequences序列

(3)one-hot encoding:

(4)align sequences(序列对齐):sequence长度不同,训练数据没有对齐,因为要把数据存储在矩阵或者张量里,序列需要对齐,每条序列有相同的长度
- 假设序列长度为w,砍掉前面的词,只保留最后w个词(或保留前面w个词也可以)
- 如果不到w个词,做zero padding,用null来补齐,至长度为w(从前面补齐,或从后面)
总结:一条评论用一个正整数的序列(sequence)来表示,sequence就是神经网络中Embedding层的输入。还需要对齐不同sequence的长度
Word Embedding(Word to Vector)
(1)One-Hot Encoding:字典里一共有v个单词,需要维度为v的one-hot向量(很容易维度过高;RNN的参数数量正比于输入向量的维度)
(2)Word Embedding:把高维one-hot向量映射为低维向量(d为词向量的维度,由用户自己决定;v是vocabulary,即字典里单词的数量)

参数矩阵P的每一行都是一个词向量,矩阵的行数是v,每一行对应一个单词;d由用户决定,d的大小会影响机器学习模型的表现,应由cross validation来选择一个比较好的d
参数矩阵是从训练数据中学习出来的

(3)keras提供Embedding层
from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding
embedding_dim = 8
# vocabulary大小 v
# 词向量维度 d (通过cross validation选出)
# 每个Sequence的长度
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num))Embedding层的输出是一个 (word_num, embedding_dim) 的矩阵,Embedding层的参数数量 = vocabulary × embedding_dim
- 每条评论中有 word_num 个词,每个单词用 embedding_dim 的词向量来表示
- Embedding层中有一个参数矩阵P,矩阵P的 行数 = vocabulary,列数 = embedding_dim
总结:Embedding层把每个单词映射成一个 embedding_dim 的词向量
Logistic Regression做二分类,判断电影评论是正面还是负面
(1)用keras实现一个分类器:
- Sequential:把神经网络的层按顺序搭起来,返回model对象,往里依次添加各种层
- Embedding:输出为 (word_num, embedding_dim) 的矩阵【参数数量 = vocabulary × embedding_dim】
- Flatten:把 word_num × embedding_dim 的矩阵压扁,变为向量
- Dense(全连接层,即Logistic Regression):输出是1维的,用sigmoid激活函数,输出为0-1之间的数(0代表负面评价,1代表正面评价)【参数数量 = word_num × embedding_dim + 1,+1是指偏移量bias】
- summary() 函数可以打印出模型的概要:每一层的名字Layer(type)、输出的大小Output Shape、参数的数量Param #
from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding
embedding_dim = 8
model = Sequential()
# vocabulary大小 v
# 词向量维度 d (通过cross validation选出)
# 每个Sequence的长度
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary() # 打印出模型概要
(2)接下来编译模型:
- 分为 训练数据train(2w条电影评论) 和 验证数据valid(5k条电影评论)
- 把train全部扫一遍为一个epoch,每一个epoch都会输出训练loss、acc和验证loss、acc
from keras import optimizers
epochs = 50
model.compile(optimizer=optimizers.RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['acc'])
# 用训练数据来拟合模型
history = model.fit(x_train, y_train, epochs=epochs, batch_size=32, validation_data=(x_valid, y_valid))x_train是个2w*20的矩阵(20指每条电影评论中有20个单词,每个单词用正整数表示)

(3)在测试集上检验模型表现:
loss_and_acc = model.evaluate(x_test, labels_test)
print('loss=' + str(loss_and_acc[0]))
print('acc=' + str(loss_and_acc[1]))电影评论texts,首先做tokenization,变为tokens;
然后把每个tokens编码为一个数字,这样一来,一条电影评论就可以用一个正整数的序列sequence来表示(sequence即神经网络中Embedding层的输入);
由于电影评论的长短不一,得到的sequence长短也不一,故还需要对齐(长度>w,只保留后w个词;长度<w,从前面用null补齐至w)。
输入Embedding层【参数数量 = vocabulary × embedding_dim】,把每个单词映射到一个 embedding_dim 维的词向量;
再用Flatten,将矩阵压扁成向量;
最后用Logistic分类器【参数数量 = word_num × embedding_dim + 1】输出一个0-1之间的数

(二)RNNs(Recurrent Neural Networks)
- one-to-one模型(一个输入对应一个输出):如全连接神经网络和CNN。适合处理图片(输入一张图片,输出每一类的概率值)
- many-to-one模型或many-to-many模型(输入和输出长度都不固定):RNN。适合文本、语音等Sequential data(时序序列数据)
1、Simple RNN模型
训练数据足够多时,RNN效果不如Transformer;但在小规模问题,RNN很有用
(1)Simple RNN
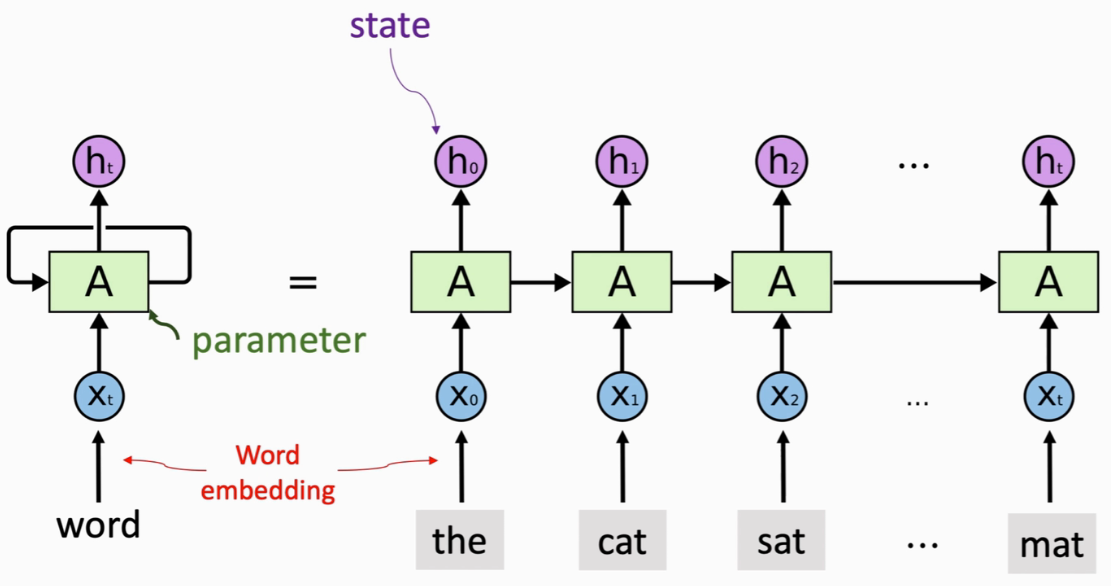
- 状态向量h:积累阅读过的信息(ht中包含了x0~xt的输入信息)
- 词向量x:按顺序读取每一个词向量
- 参数矩阵A:一开始随机初始化,从训练数据中学习
每次把一个词向量输入RNN,RNN就会更新状态h,把新的输入积累到状态h里(h0包含了第一个词的信息,h1包含了前两个词的信息,以此类推)
更新状态h的时候需要用到参数矩阵A(不论链路多长,都只有一个参数矩阵A。A随机初始化,利用训练数据来学习A)
SimpleRNN怎么把输入的词向量x结合到状态h里?
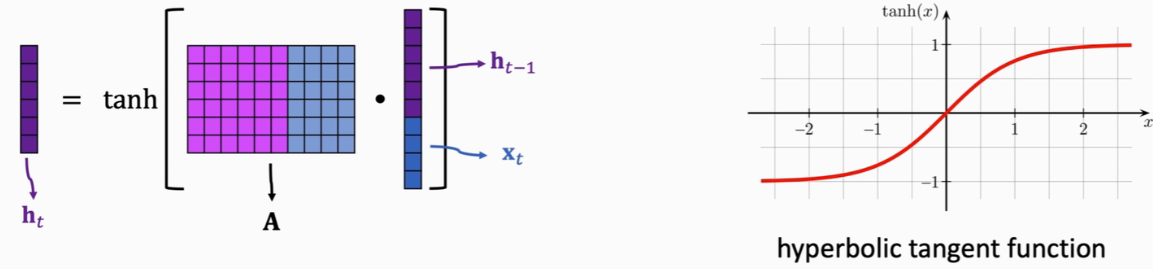
激活函数是 tanh(双曲正切函数),输入是任意实数,输出在 -1 ~ 1。为什么要用tanh?【每次更新状态h之后,做一个normalization,让h恢复到 -1~1 之间】
- 假设输入的词向量 x0 = ... = x100 = 0,h100 = Ah99 = A² h98 = ... = A^100 h0
- 若矩阵A最大的特征值<1,新的状态每个元素都趋于0
- 若矩阵A最大的特征值>1,新的状态每个元素都巨大,状态向量会爆炸(数值为nan=not a number)
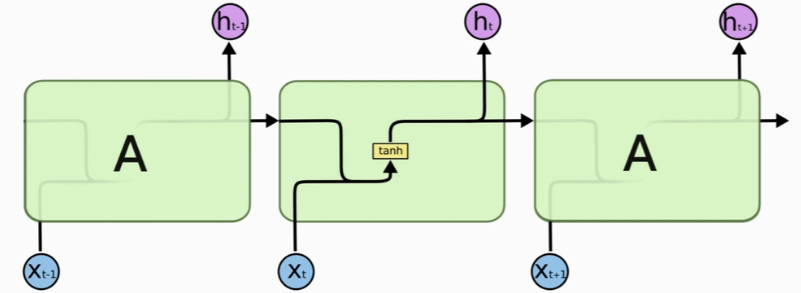
可训练参数:参数矩阵A(可能还有intercept vector,即偏置项)

(2)Simple RNN for IMDB Review
- Word Embedding:词映射为向量x,词向量的维度d由cross-validation确定最优维度【输出维度:(word_num, state_dim)】
- SimpleRNN Layer:输入是词向量,输出是状态h(维度也由cross-validation确定最优维度)【输出维度:state_dim的向量,若只输出RNN最后一个状态向量ht;(word_num, state_dim),若输出所有状态向量】
- 可以输出所有h,也可以只输出最后一个状态向量ht(积累了整句话的信息)
- ht输出分类器,输出0-1之间的数值(0代表负面评价,1代表正面评价)

# (1)搭建模型
from keras.models import Sequential
from keras.layers import SimpleRNN, Embedding, Dense
vocabulary = 10000 # unique words in the dictionary
embedding_dim = 32 # shape(x) 词向量x的维度
word_num = 500 # sequence length 每个评论长度为500个单词
state_dim = 32 # shape(h) 状态向量h的维度
model = Sequential()
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num)) # 词映射为向量
# return_sequences=False 指RNN只输出最后一个状态向量,之前的状态向量全扔掉
model.add(SimpleRNN(state_dim, return_sequences=False)) # 指定状态向量h的维度 state_dim
model.add(Dense(1, activation='sigmoid')) # 全连接层,输入RNN的最后一个状态h,输出一个0-1之间的数
model.summary()
# (2)编译模型
from keras import optimizers
epochs = 3 # Early stopping防止过拟合(在validation accuracy变差之前就停止)
model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['acc'])
# 用训练数据来拟合模型
history = model.fit(x_train, y_train, epochs=epochs, batch_size=32, validation_data=(x_valid, y_valid))
# (3)用测试数据评价模型表现
loss_and_acc = model.evaluate(x_test, labels_test)
print('loss=' + str(loss_and_acc[0]))
print('acc=' + str(loss_and_acc[1]))
RNN层参数数量:shape(h) × (shape(h) + shape(x)) + bias/intercept ,第一项为矩阵A的大小,第二项为RNN默认使用intercept(偏移量)
上述做法是只保留了最后一个状态ht,丢弃了前面所有状态。也可以保留h0~ht,此时RNN输出为一个矩阵(每行就是一个状态h),需要加Flatten层把状态矩阵变成向量。向量作为分类器的输入,来判断电影是正面的还是负面的

from keras.models import Sequential
from keras.layers import SimpleRNN, Embedding, Dense
vocabulary = 10000 # unique words in the dictionary
embedding_dim = 32 # shape(x) 词向量x的维度
word_num = 500 # sequence length 每个评论长度为500个单词
state_dim = 32 # shape(h) 状态向量h的维度
model = Sequential()
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num)) # 词映射为向量
model.add(SimpleRNN(state_dim, return_sequences=True)) # 指定状态向量h的维度 state_dim
model.add(Flatten())
model.add(Dense(1, activation='sigmoid')) # 全连接层
model.summary()(3)缺点
不擅长long-term dependence:状态h100跟100步之前的输入x1几乎没关系(即后面的状态会遗忘之前的输入)
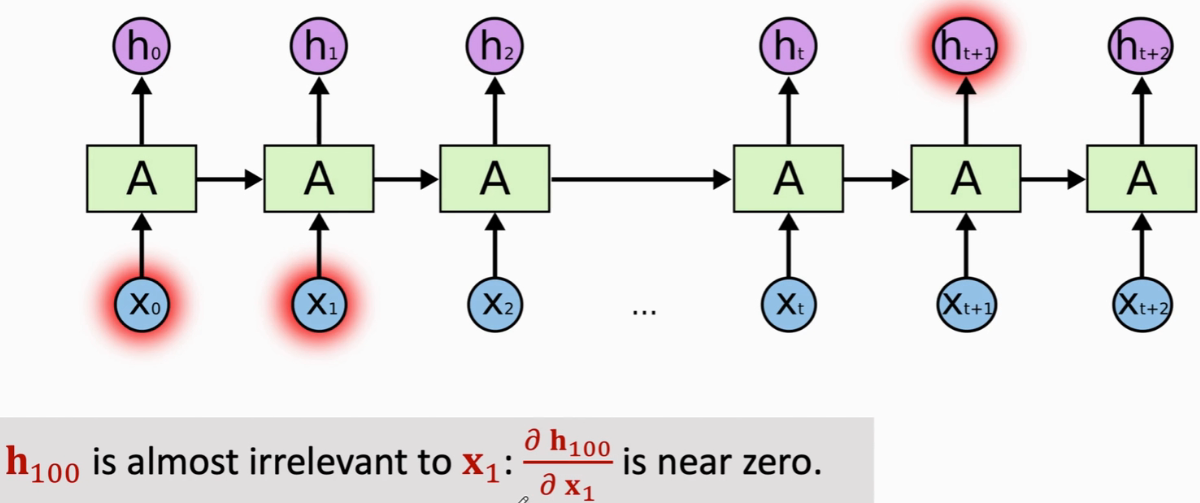
RNN适合文本、语音等时序序列数据
RNN按顺序读取每一个词向量,并在状态向量h中积累看到过的信息,如h1中包含x0和x1的信息,以此类推,ht中包含了之前所有输入的信息,可以认为,ht就是RNN从整个输入序列中抽取的特征向量
RNN记忆很短,会遗忘很久之前的输入x。若时间序列很长,比如好几十步,最终的ht已经忘了早先的输入
SimpleRNN有一个参数矩阵A,维度是 shape(h) × (shape(h)+shape(x)),一开始随机初始化,从训练数据中学习。可能还有一个intercept向量
注意,不管时序多长,参数矩阵只有一个,所有模块里的参数都是一样的
2、LSTM(Long Short Term Memory)
LSTM的记忆会比SimpleRNN长很多,但也还是有遗忘的问题。LSTM是一种RNN模型,可以避免梯度消失的问题,可以有更长的记忆(一般用RNN,都是LSTM,SimpleRNN基本不用)
- 每当读取一个新的输入x,就会更新状态h
- SimpleRNN只有一个参数矩阵,LSTM有四个参数矩阵
- 遗忘门有一个参数矩阵Wf(sigmoid映射到0~1)
- 输入门有两个参数矩阵:Wi(sigmoid映射到0~1)、Wc(tanh映射到 -1~1)
- 输出门有一个参数矩阵Wo(sigmoid映射到0~1)
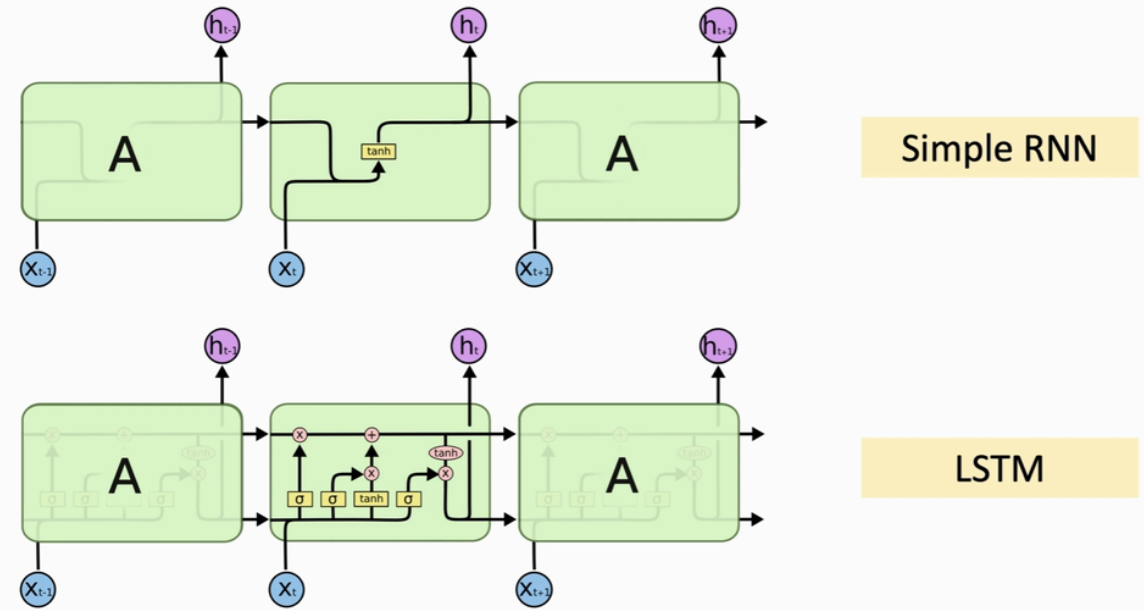
(1)内部结构
传输带Ct:过去的信息直接送到下一个时刻,以此避免梯度消失

LSTM中有很多个gate(遗忘门、输入门、输出门),可以有选择地让信息通过
- forget gate(遗忘门):由 sigmoid函数 和 element-wise multiplication/哈达玛积(两个向量的每个元素对应相乘,结果也是个向量)组成。有选择地让传输带C的值通过(假如f 对应的元素为0,c对应的元素就不能通过,对应的输出为0;假如f 对应的元素为1,c对应的元素就全部通过,对应的输出为c本身)

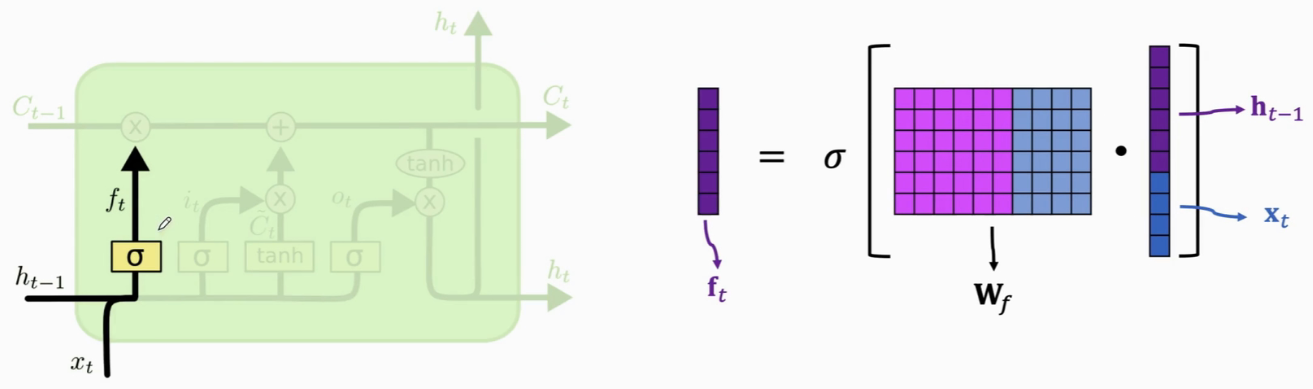

遗忘门有一个参数矩阵Wf,需要通过反向传播从训练数据里学习
- input gate(输入门):参数矩阵Wi(sigmoid映射到0~1)、参数矩阵Wc(tanh映射到 -1~1)

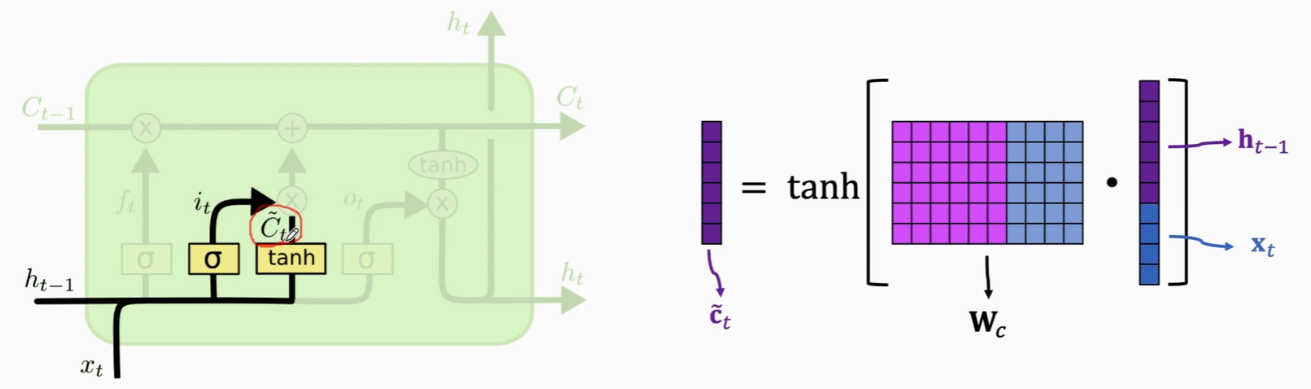
更新传输带C:
- 用 遗忘门ft 和 传输带旧的值Ct-1 算element-wise multiplication(遗忘门ft 可以选择性地遗忘 Ct-1中的一些元素)
- 计算 输入门it 和 新的值Ct 的element-wise multiplication(加入新的信息)


- output gate(输出门):计算ot,参数矩阵Wo(sigmoid函数映射到0~1)
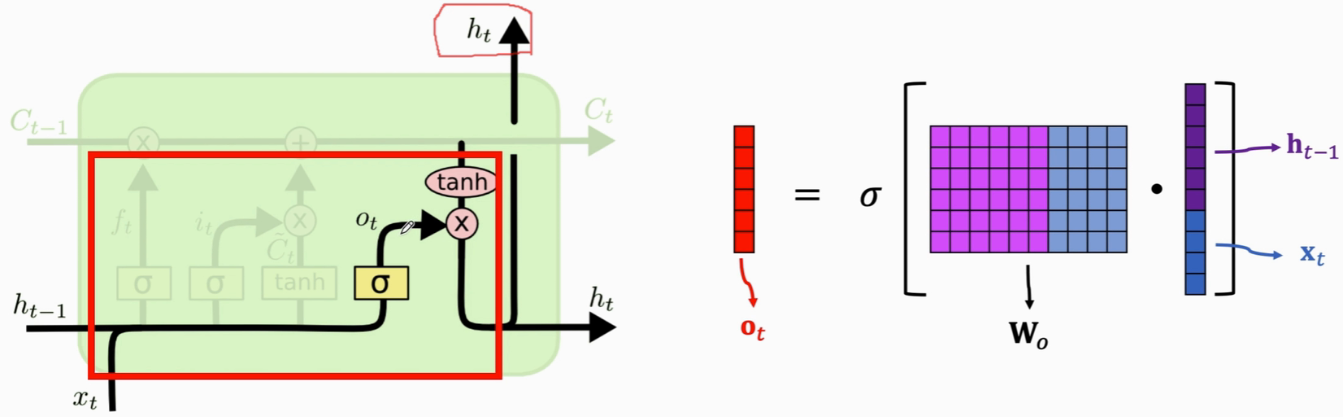
计算状态向量ht:一份传到下一步,另一份是LSTM的输出
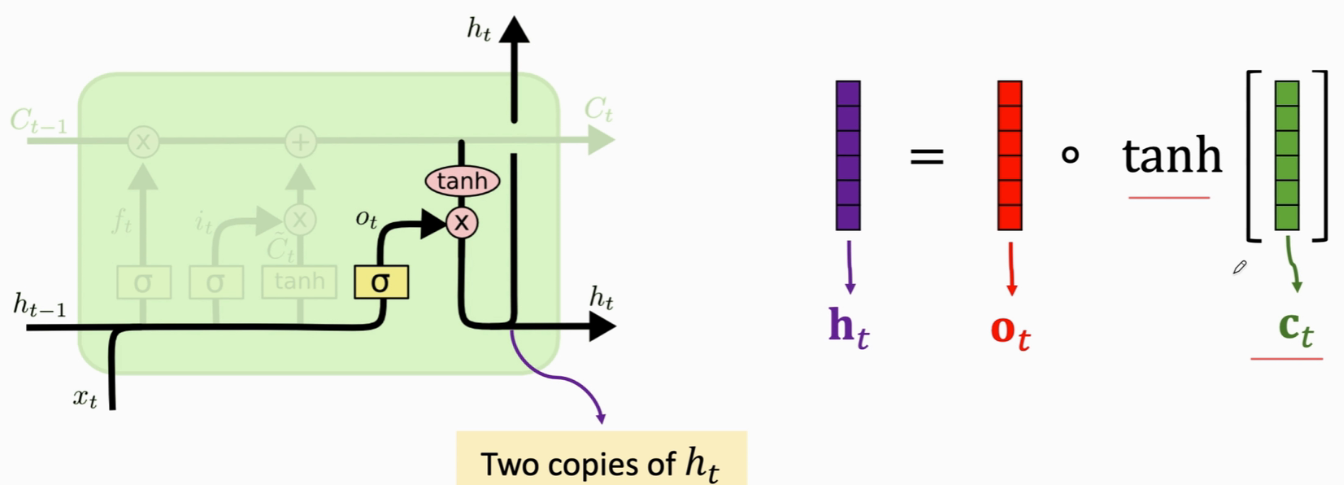
到第t步为止,一共有t个向量x输入了LSTM,可以认为所有这些x向量的信息都积累在了状态ht里
(2)参数数量
遗忘门、输入门、new value、输出门,共有4个参数矩阵,共有 4 × shape(h) × [shape(h) + shape(x)]
- 矩阵的行数:shape(h)
- 列数:shape(h) + shape(x)
(3)keras实现LSTM
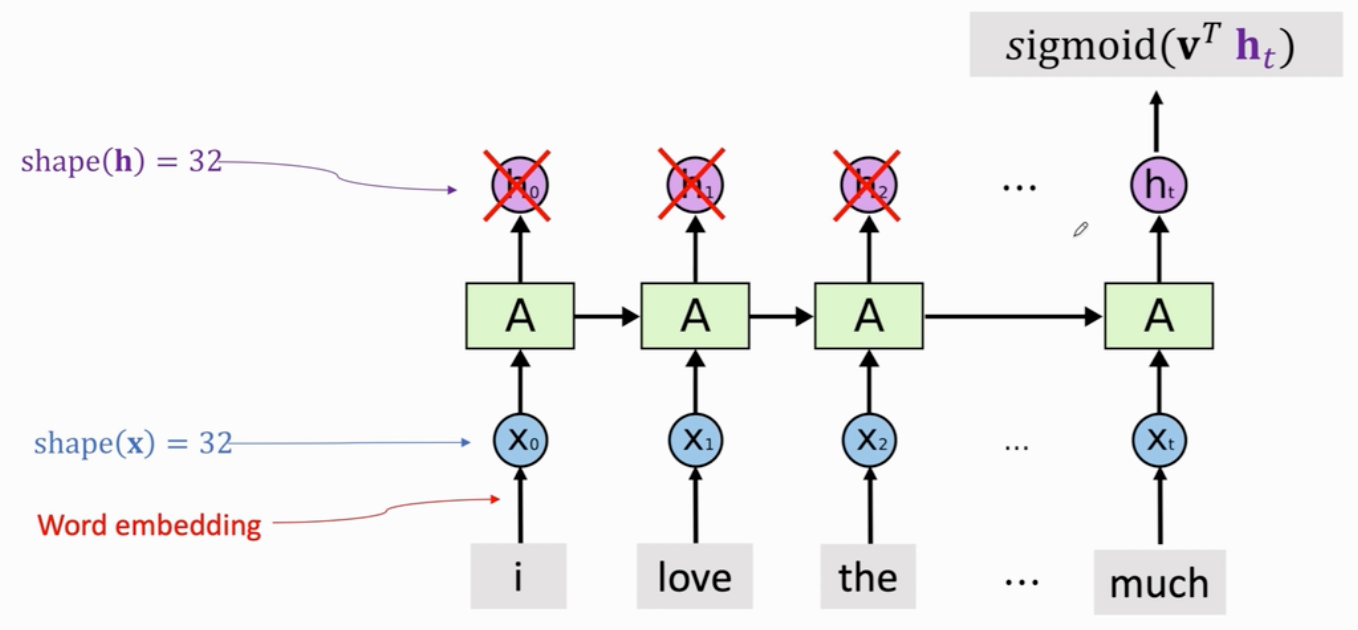
让LSTM只输出最后一个状态向量ht,即从电影评论中提取出的特征向量,再输入线性分类器,来判断评论是正面的还是负面的
from keras.models import Sequential
from keras.layers import LSTM, Embedding, Dense, Flatten
vocabulary = 10000 # unique words in the dictionary
embedding_dim = 32 # shape(x) 词向量x的维度
word_num = 500 # sequence length 每个评论长度为500个单词
state_dim = 32 # shape(h) 状态向量h的维度
model = Sequential()
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num)) # 词映射为向量
# return_sequences=False 指RNN只输出最后一个状态向量,之前的状态向量全扔掉
model.add(LSTM(state_dim, return_sequences=False)) # 指定状态向量h的维度 state_dim
model.add(Dense(1, activation='sigmoid')) # 全连接层
model.summary()
- 每个参数矩阵:shape(h) × [shape(h) + shape(x)] + shape(h)(LSTM默认使用intercept)
- LSTM参数量:*4
可以加dropout(设置为某个0-1之间的数字即可):
model.add(LSTM(state_dim, return_sequences=False), dropout=0.2)若加dropout没有提升测试准确率,原因:虽然训练时出现了overfitting,但overfitting不是由LSTM造成的,而是由Embedding层造成的,故对LSTM使用dropout正则化没有用
LSTM和SimpleRNN的区别是用了一条传输带,让过去的信息可以很容易的传输到下一时刻,这样就有了更长的记忆
LSTM有4个组件,分别是:forget gate(遗忘门)、input gate(输入门)、new value(新的输入)、output gate(输出门),这4个组件各自有一个参数矩阵,所以一共有4个参数矩阵,参数数量为 4 × shape(h) × [shape(h) + shape(x)]
3、Making RNNs More Effective
三个技巧来提升RNN的效果(对所有RNN都适用)
(1)Stacked RNN(多层RNN)
- 把很多全连接层堆叠起来:multi-layer perceptron
- 把很多卷积层堆叠起来:深度卷积网络
- 把很多RNN层堆叠起来:多层RNN网络
神经网络每一步都会更新状态h,有两份:一份送到下一时刻,一份作为输出(同时也是下一层的输入)

# 多层LSTM 用keras实现
from keras.models import Sequential
from keras.layers import LSTM, Embedding, Dense
vocabulary = 10000 # unique words in the dictionary
embedding_dim = 32 # shape(x) 词向量x的维度
word_num = 500 # sequence length 每个评论长度为500个单词
state_dim = 32 # shape(h) 状态向量h的维度
model = Sequential()
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num)) # 词映射为向量
# return_sequences=True 第一层的输出会成为第二层的输入,故要输出所有的状态向量h
model.add(LSTM(state_dim, return_sequences=True, dropout=0.2)) # 指定状态向量h的维度 state_dim
model.add(LSTM(state_dim, return_sequences=True, dropout=0.2))
model.add(LSTM(state_dim, return_sequences=False, dropout=0.2)) # 只输出最后一个状态向量
model.add(Dense(1, activation='sigmoid')) # 全连接层,输入第三层LSTM最后一个状态向量,输出分类结果
- Embedding层输出:(word_num, embedding_dim)
- 第一层LSTM输出:(word_num, state_dim) return_sequences=True(输出500个状态向量h)
- 第二层LSTM输出:(word_num, state_dim) return_sequences=True(输出500个状态向量h)
- 第三层LSTM输出:state_dim维的向量 return_sequences=False(最后一个状态,相当于从word_num个词里提取的特征向量)
实验结果跟单层RNN效果差不多,猜想是由于Embedding层参数太多,没有足够的数据把这一层训练好,出现overfitting,加再多LSTM层也无济于事
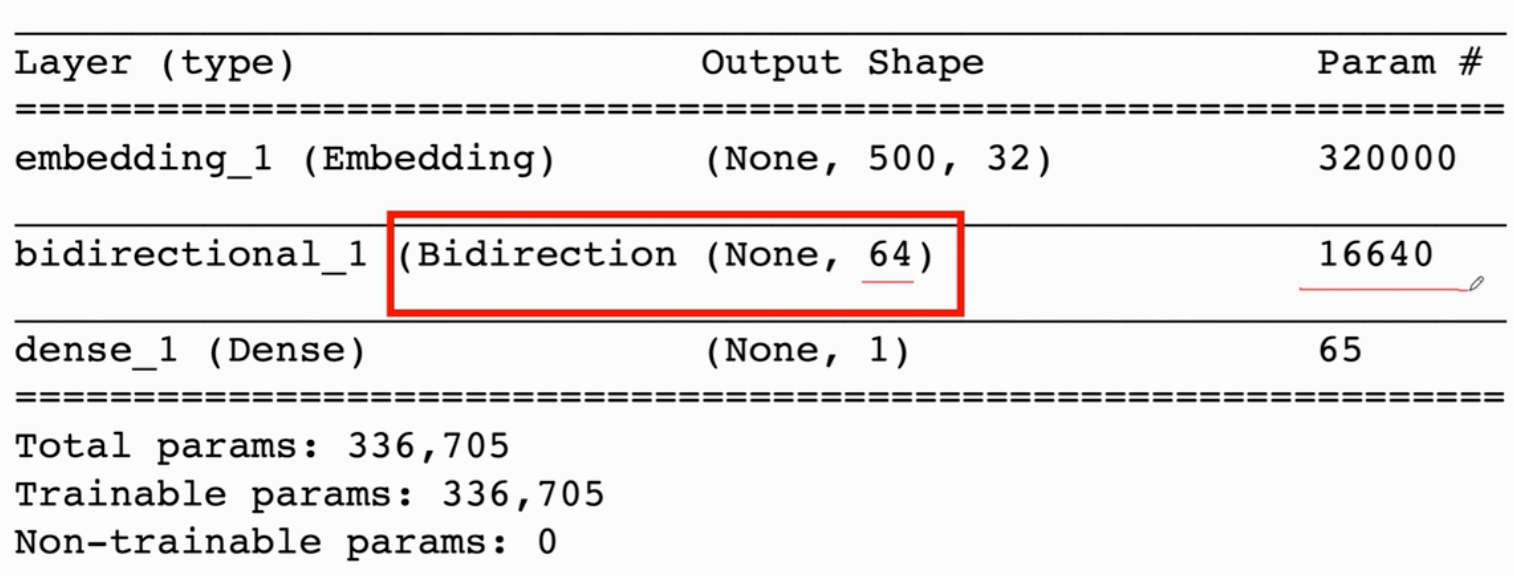
(2)Bidirectional RNN(双向RNN)
训练两条RNN,一条从左往右,一条从右往左,两条RNN完全独立,不共享参数和状态。两条RNN各自输出自己的状态向量,然后把它们的状态向量做concat,记为向量y
- 如果有多层RNN,就把输出的向量y作为下一层RNN的输入
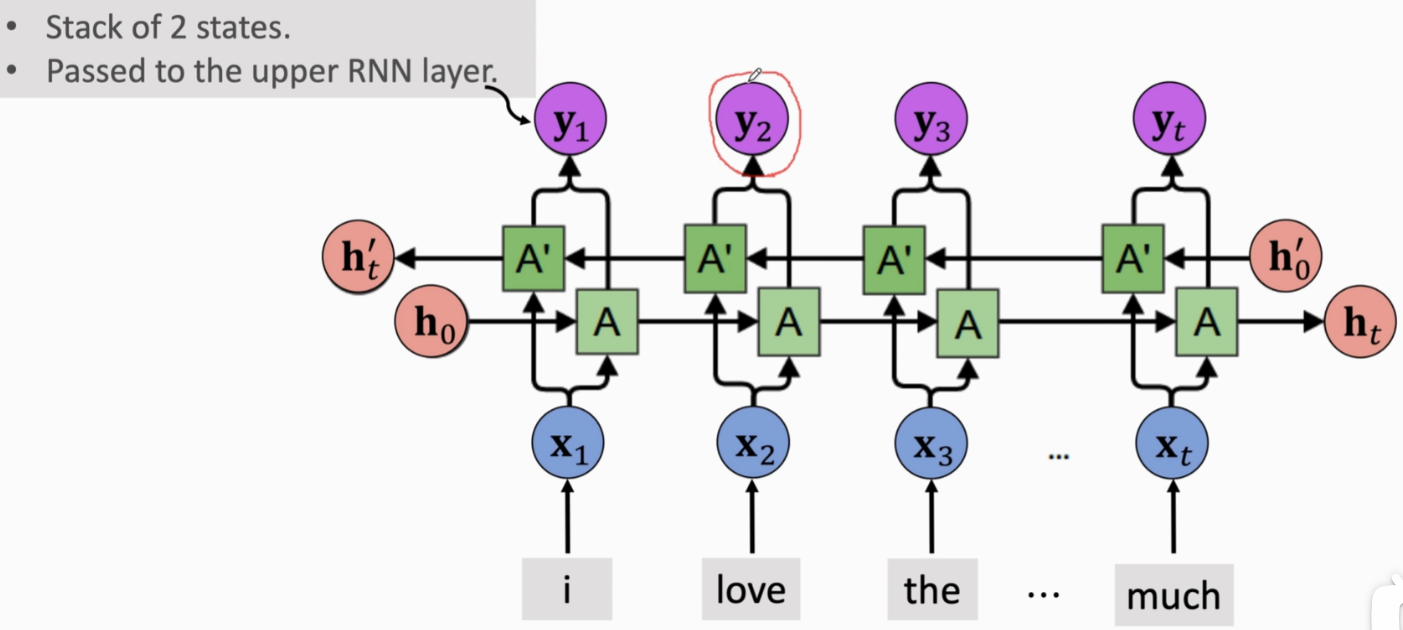
- 如果只有一层RNN,就把y向量都丢掉,只保留两条RNN最后的状态向量,把它们concat,作为从输入文字中抽取的特征向量,以此来判断电影评论是正面还是负面
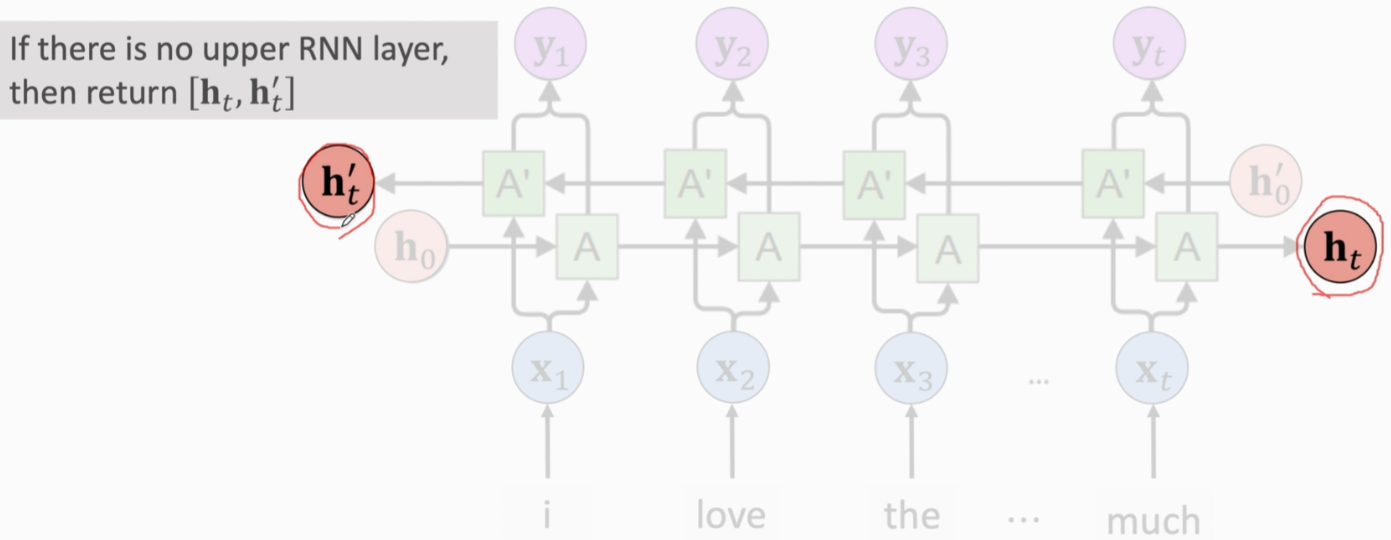
双向RNN总是比单向的效果好,原因:不管是SimpleRNN还是LSTM,都会或多或少遗忘掉早先的输入。而双向RNN左右结合,就不会遗忘一开始的词
# 双向LSTM 用keras实现
from keras.models import Sequential
from keras.layers import LSTM, Embedding, Dense, Bidirectional
vocabulary = 10000 # unique words in the dictionary
embedding_dim = 32 # shape(x) 词向量x的维度
word_num = 500 # sequence length 每个评论长度为500个单词
state_dim = 32 # shape(h) 状态向量h的维度
model = Sequential()
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num)) # 词映射为向量
# return_sequences=False 只保留两条链最后的状态,输出两个状态向量的concat,其余状态向量都被扔掉了
model.add(Bidirectional(LSTM(state_dim, return_sequences=False, dropout=0.2))) # 指定状态向量h的维度 state_dim
model.add(Dense(1, activation='sigmoid')) # 全连接层
model.summary()- Embedding层输出:(word_num, embedding_dim)
- 双层RNN输出:(state_dim×2) 维的向量 return_sequences=False(输出两条链最后的状态向量)【参数数量比使用单向LSTM多一倍,因为两条链各自有各自的模型参数】
(3)pretrain(预训练)
比如在训练卷积神经网络时,如果网络太大,而训练集不够大,可以先在ImageNet等大数据上预训练,这样可以让神经网络比较好的初始化,也可以避免overfitting
若Embedding层参数>>训练样本数量,会导致overfitting。可以对Embedding层做预训练
- 首先找一个更大的数据集(可以是情感分析数据或其他类型数据,但任务最好是接近情感分析任务,学出的词向量带正面或负面的情感。两个任务越相似,预训练后的transfer越好)
- 搭建一个神经网络(有Embedding层即可),在大数据集上训练该神经网络
- 训练完毕后,把上面的层全部丢掉,只保留Embedding层和训练好的模型参数
- 再搭建自己的RNN网络(跟之前预训练的可以有不同的结构),新的RNN层和全连接层都是随机初始化,而Embedding层的参数是预训练出来的(固定住,不要训练)

总结循环神经网络RNN:
SimpleRNN和LSTM都属于RNN
(1)SimpleRNN很容易遗忘,效果不好,实践中不用
(2)LSTM的记忆比SimpleRNN长很多,实践中都用LSTM(还有GRU,但是效果不如LSTM)
(1)双向LSTM效果比单向好
(2)RNN层可以像全连接层和卷积层那样累加起来,搭成一个深度神经网络。多层RNN容量比单层RNN更大,如果训练数据够多,多层RNN效果更好
(3)想把RNN用在文本问题上,需要有一个Embedding层把词变成向量,Embedding层有一个参数矩阵(大小是vocabulary×词向量的维度)。这个参数矩阵通常很大,若训练数据集比较小,Embedding层就不会训练的很好,会overfitting。解决办法是在大数据集上预训练Embedding Layer
4、RNN的应用 — 自动文本生成(Text Generation)
(1)技术原理
输入半句话,预测 input text 的下一个字符。拿训练好的RNN来生成文本:
- 把文本分割成字符,用one-hot encoding来表示字符,这样,每个字符就表示成一个one-hot向量
- 把这些one-hot向量依次输入RNN,RNN状态向量h会积累看到的信息。返回最后一个状态向量h
- RNN后是一个softmax分类器,把h与参数矩阵W相乘,得到一个向量。经过softmax函数的变换,最终输出是一个向量,每个元素都在0-1之间,元素全加起来=1(softmax输出是一个概率分布)
- 选择概率值最大的字符,接到文本末尾,作为新的输入,生成下一个字符,重复这个过程

如何训练这个RNN?
- 训练数据:文本,如英文维基百科的所有文章。把文章划分成很多片段(可以有重叠overlap)
- seg_len = 40(片段长度),stride = 3(下一个片段会向右平移3个字符的长度)
- 片段是神经网络的输入,片段的下一个字符是标签,训练数据是 (片段, 标签) 的pairs

- 多分类问题,每个类别对应一个概率值
- 文本生成器并不是记住训练数据并重复,而是可以生成新的东西
(2)训练一个文本生成器
想要生成文本,首先需要训练一个RNN
- 准备训练数据:将训练文本划分为 (segment, next_char) 的 pairs。segment是神经网络的输入,next_char是标签

划分segment 和 next_char:

- 字符->one-hot向量:故片段->矩阵(之前还需要进一步做word embedding,用一个低维词向量来表示一个词。这里不需要embedding层,因为之前是word-level tokenization,英语里约有1w个常用词,one-hot向量都是1w维,维度太高;而char-level tokenization把一句话切成很多个字符,常用字符大概是100个=字母+数字+标点+空白)

len(text) = 600893 / stride = 3 约等于 200278 pairs

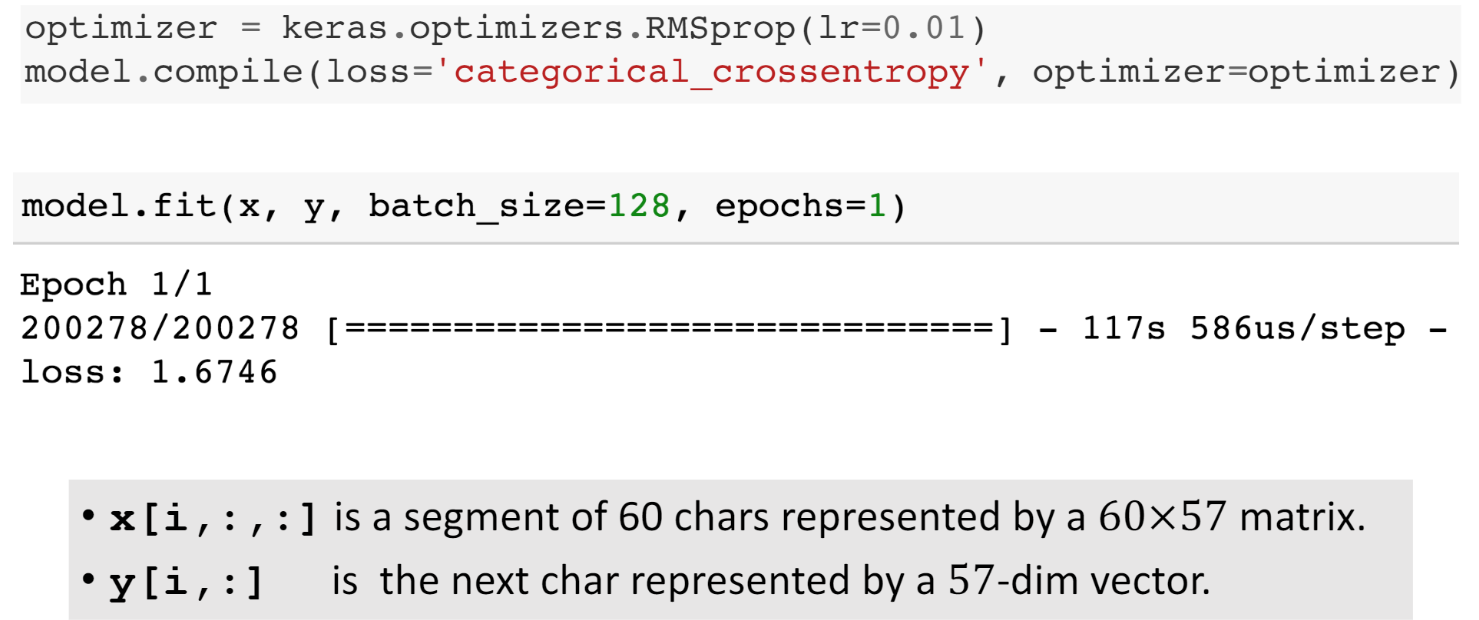
- 搭建神经网络:输入是segment(l×v的矩阵,l是每个segment的长度,即有l个字符;v是vocabulary,是字典里不同字符的数量)——> 单向LSTM(注意只能用单向LSTM,因为文本生成的下一个字符必须是从前往后)——>全连接层(用softmax激活函数,多分类器)——> 输出v×1的向量(向量的每个元素是一个字符的概率)

- 编译模型:指定损失函数(CrossEntropy)和优化器(RMSProp),用训练数据拟合模型,训练几十个epochs
- 训练好神经网络就可以生成文本,即预测下一个字符。首先需要给出seed segment,神经网络会接着你的输入生成文本。输出一个向量代表每个字符的概率值

- 有了概率分布,如何生成下一个字符?三种方法:
| greedy selection,哪个字符的概率最大,就选择哪个字符 | 确定性的,没有随机性。给定初始的几个字符,后面生成的字符完全是确定的(完全取决于初始输入) |
| 从多项式分布中随机抽取。假如一个字符的概率值是0.3,那么它被选中的概率就是0.3 | 抽样过于随机,生成的文本会有很多拼写和语法错误 |
| 用介于0~1之间的temperature调整概率值:把概率值做幂变换,再归一化(大的概率值会变大,小的会变小。极端情况下,最大的概率值会变为1,其余都变为0,就相当于第一种确定性的选择) | 有随机性,但随机性不大,介于前两者之间。temperature越小,变换后的概率分布越极端 |
# greedy selection
next_index = np.argmax(pred)
# sample from the multinomial distribution
next_onehot = np.random.multinomial(1, pred, 1)
next_index = np.argmax(next_onehot)
# adjust the multinomial distribution
pred = pred ** (1/temperature) # controlled temperature
pred = pred/np.sum(pred)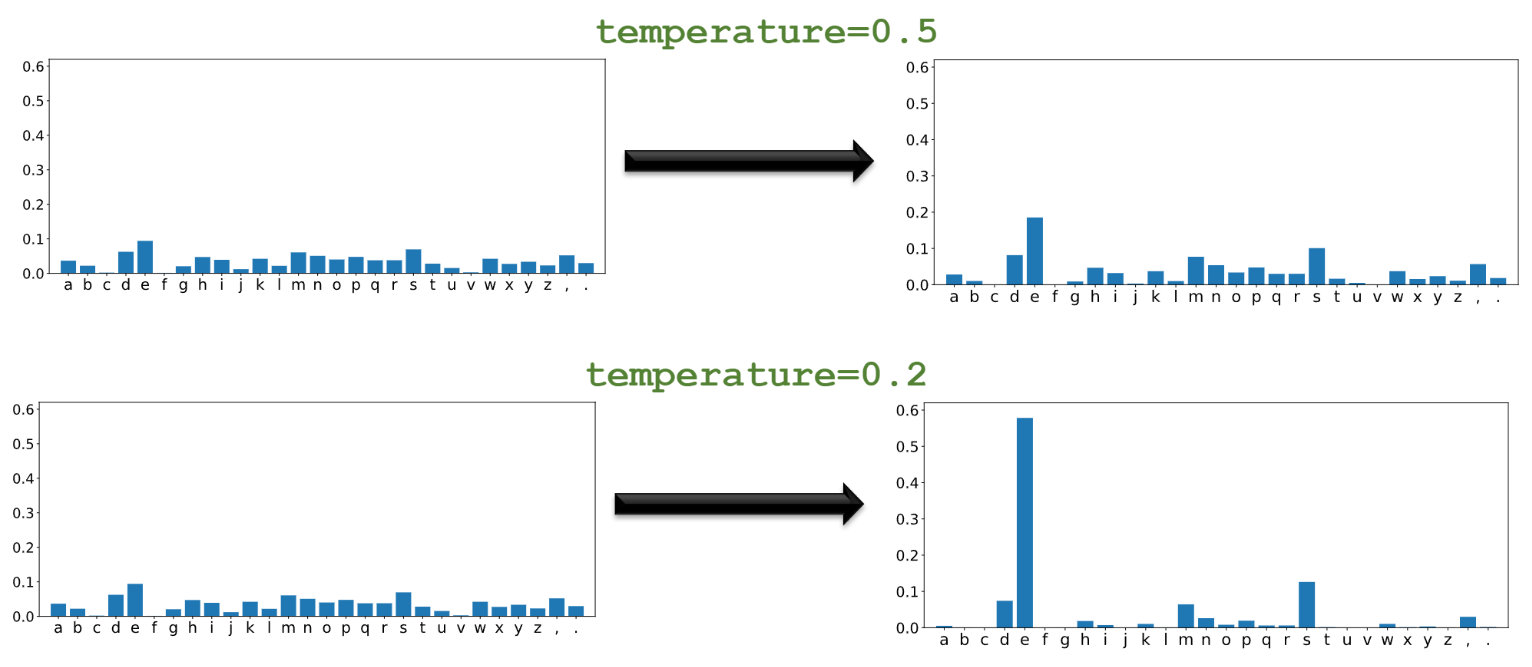
神经网络怎样做文本生成?
- 假设固定每个片段的长度为18个字符,最初的片段为seed(做one-hot变为矩阵),把矩阵输入神经网络,神经网络就会输出概率分布,从概率分布中抽样生成下一个字符
- 把新生成的字符加到最后,作为下一轮的输入,输入的长度固定为18
- 以此类推

文本生成是随机的,所以每次生成的都不一样
训练一个神经网络:
- 将文本划分为 (segment, next_char) pairs
- one-hot:
- char —> v×1 vector
- segment —> l×v matrix
- 构建+训练神经网络:l×v矩阵 —> LSTM —> Dense —> v×1 vector
文本生成:
- 输入一个seed segment
- 重复以下:
- 将one-hot后的segment输入神经网络
- 神经网络输出概率值
- 从概率值中采样生成next_char
- 将next_char append到segment后
5、RNN的应用 — 机器翻译(Neural Machine Translation)
机器翻译模型有很多种,这里介绍Seq2Seq(例:英译德)
机器翻译是个Many to Many的问题,输入、输出长度都大于1且不固定
(1)处理数据

- 预处理:大写字母变为小写,去掉标点符号等
- tokenization(可以是char-level或word-level,实际机器翻译都是word-level,因为数据量够大):要用两个不同的tokenizer(英语一个德语一个),并建立两个不同的字典(因为不同的语言通常有不同的字母表,且分词方法也不同)


例子里用的是char-level(比较方便,不用Embedding层),但最好用word-level(前提是需要有足够大的数据集)。原因:
- 英文平均每个单词有4.5个字母,用单词代替字符,输入序列就会短4.5倍。序列越短,越不容易遗忘
- word-level得到的Vocabulary大约为1w(也是one-hot的维度),必须要用word Embedding得到低维词向量(Embedding层参数数量太大,小数据量无法训练,会有overfitting的问题;或对Embedding层做预训练)
- 英译德,故德语的字典里需要加入 起始符\t 和 终止符\n

- 此时每句话都变成了一个字符的列表,并有一个英文字典和一个德语字典,再把每个字符映射为一个数字
- 再把每个数字做one-hot,得到一个矩阵,这个矩阵就是RNN的输入
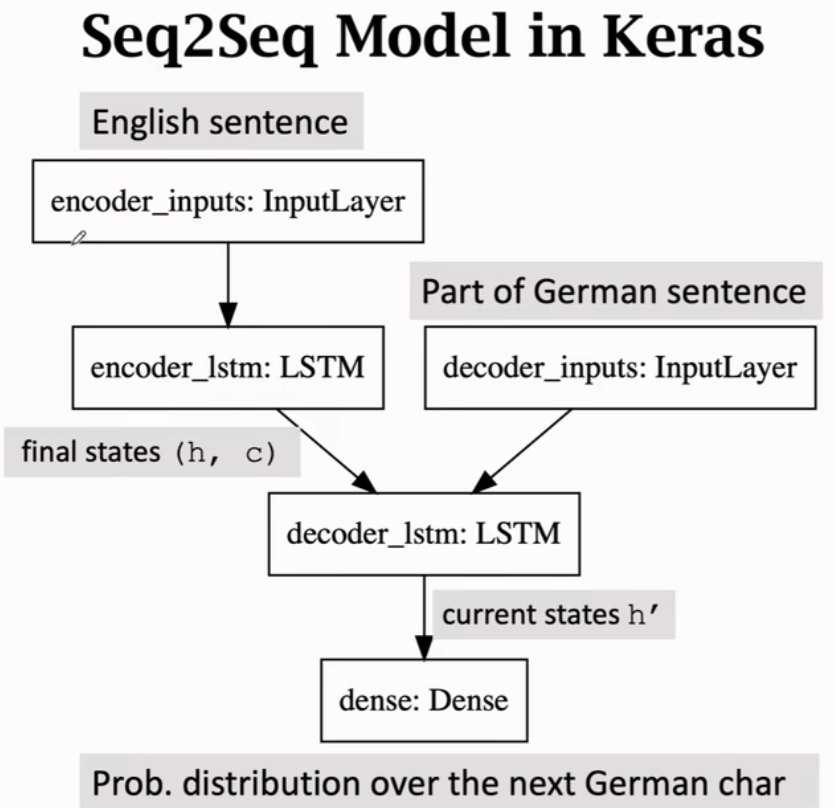
(2)训练Seq2Seq模型
Seq2Seq有一个Encoder编码器(是个LSTM或其他RNN模型,用来从输入的句子中提取特征)和一个Decoder解码器(用来生成德语,就是文本生成器)
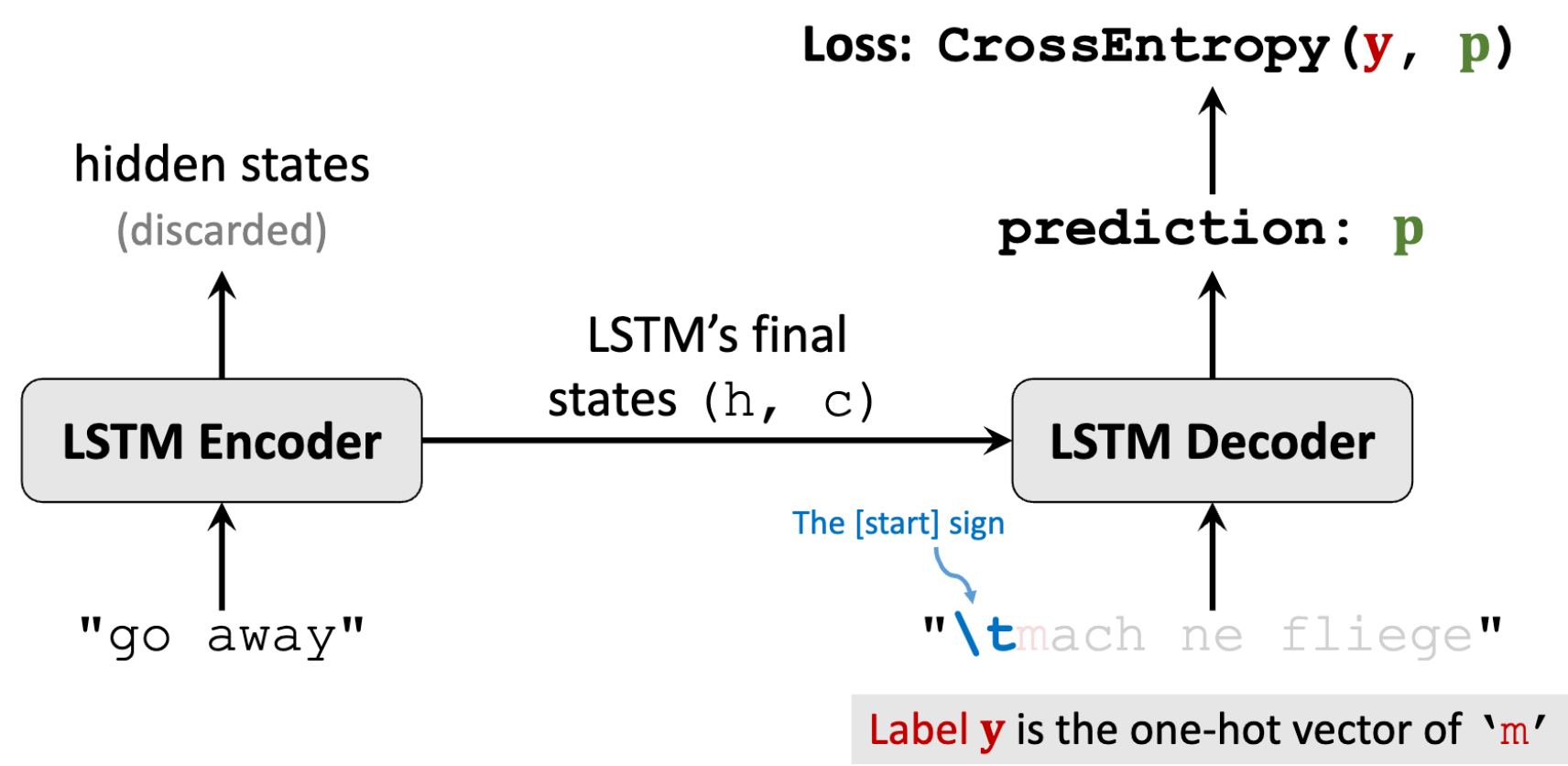
- Encoder的最后一个状态就是从输入句子中提取的特征,包含这句话的信息。其余状态都被丢弃了。Encoder的输出是LSTM最后一个状态h 以及 最后的传输带c
- Decoder跟文本生成器的区别是,文本生成器的初始状态是个全零向量,而Decoder初始状态是Encoder最后一个状态(从而得知输入的英语句子)
- Decoder是一个LSTM,每次接收一个输入,输出对下一个字符的预测(输出一个概率分布向量p),第一个输入必须是起始符\t,将起始符后的第一个字符one-hot后作为label。损失函数为CrossEntropy
- 最后一轮:整句德语作为Decoder输入,label为停止符\n
(3)用训练好的模型inference


最后一轮:

- 每一轮会更新状态(h, c),并输出一个概率分布
- 用新生成的字符作为下一轮的输入
- 输出终止符\n时终止文本生成,并返回记录下的字符串,即模型翻译得到的德语
用Seq2Seq做机器翻译:
模型有一个Encoder(每输入一个词就更新状态,把输入信息积累在状态里。最后一个状态就是从英文句子里积累的特征。只保留最后一个状态)和一个Decoder(Encoder的最后一个状态是Decoder的初始状态,初始化后Decoder就知道输入的英文句子了;然后Decoder就作为文本生成器,生成一句德语:首先把起始符\t作为Decoder RNN的输入,会更新状态为s1,全连接层输出预测概率为p1,根据概率分布做抽样生成下一个字符为z1;Decoder拿z1做输入,更新状态为s2,输出概率p2,得到新的字符z2,以此类推,直到输出停止符\n)


(4)怎么提升Seq2Seq?
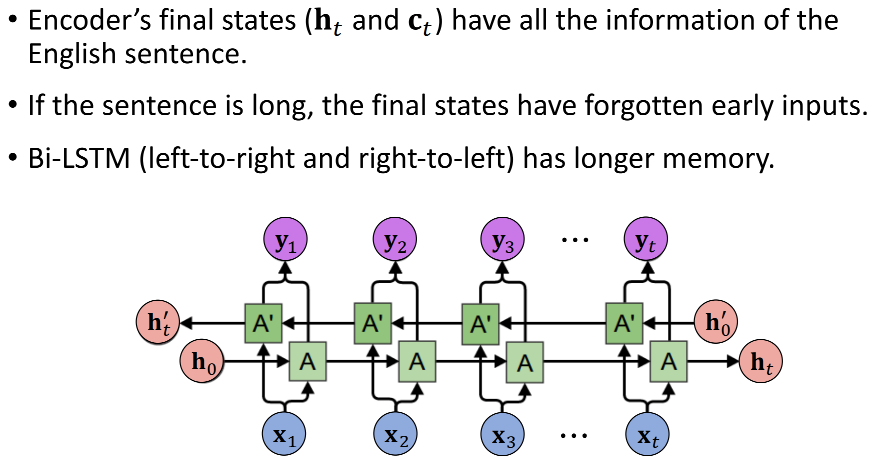
Seq2Seq的原理是Encoder处理输入的英语句子,把信息都压缩到状态向量里,最后一个状态是整句话的概要(包含整句英语的完整信息)。但若英语句子很长,早期的输入就会被遗忘
四种改进方法:
- Encoder用双向LSTM,但Decoder必须用单向(文本生成器必须按顺序生成文本)
- 做word-level tokenization而不是char-level

- Multi-task Learning(添加更多任务,等同于添加更多Decoder,注意Encoder只有一个):
- 如添加一个Decoder把英语翻译为英语本身。这样一来,Encoder还是只有一个,但训练数据多了一倍,Encoder可以训练的更好
- 或添加任务将英文翻译为其他语言。如用十种语言训练,Encoder的训练数据就多了十倍,可以训练的更好。即借助其他语言使Encoder变得更好


- Attention
评估机器翻译的效果可以用BLEU(BiLingual Evaluation Understudy)指标,范围应该在0.1~0.5
- Wikipedia:https://en.wikipedia.org/wiki/BLEU
- Blog:A Gentle Introduction to Calculating the BLEU Score for Text in Python - MachineLearningMastery.com
(三)注意力
1、Attention(注意力机制)
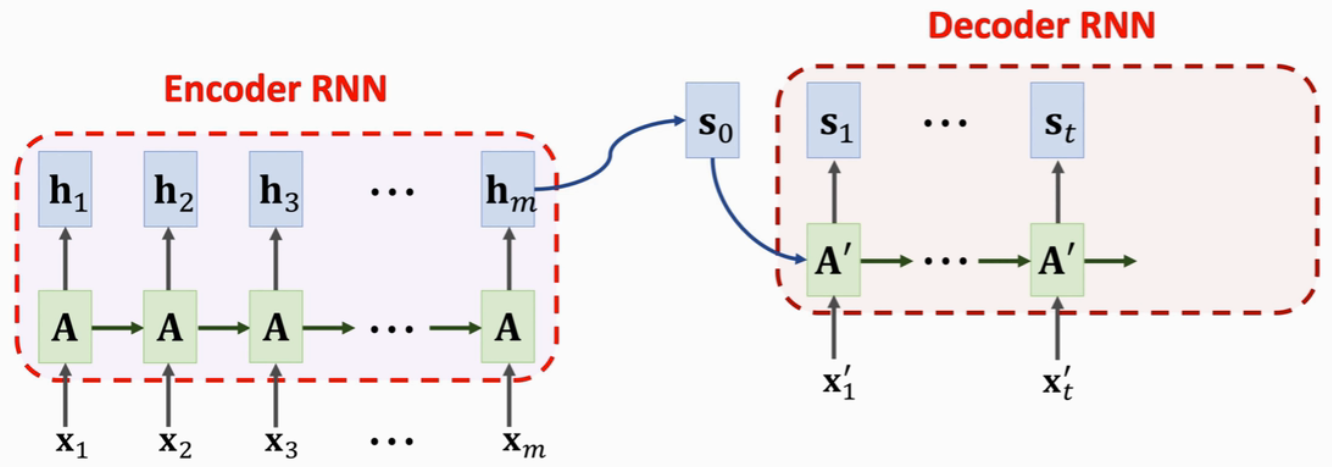
(1)回顾Seq2Seq
有两个RNN网络,一个编码器Encoder(输入英语)和一个解码器Decoder(把英语翻译成德语)
- Encoder每次读入一个英语词向量x,在状态h中积累输入的信息,最后一个状态hm中积累了所有词向量x的信息。Encoder输出最后一个状态hm,把之前的状态向量全都扔掉
- Decoder初始状态s0=hm(包含了输入英语句子的信息),通过hm,Decoder就知道了这句英语。Decoder类似文本生成器,逐字生成一句德语(即模型生成的翻译)
缺陷:若输入句子很长,Encoder会记不住完整的句子,那么Decoder也就不可能产生正确的翻译
BLEU score是评价机器翻译好坏的标准,越高说明机器翻译越准确

(2)用Attention改进Seq2Seq
解决Seq2Seq遗忘问题最有效的方法:Attention(Decoder每次更新状态的时候,都会再看一遍Encoder所有状态,这样就不会遗忘;Attention还会告诉Decoder应该关注Encoder哪个状态)
Attention可以大幅提高准确率,但计算量较大
在Encoder结束工作后,Attention和Decoder同时开始工作
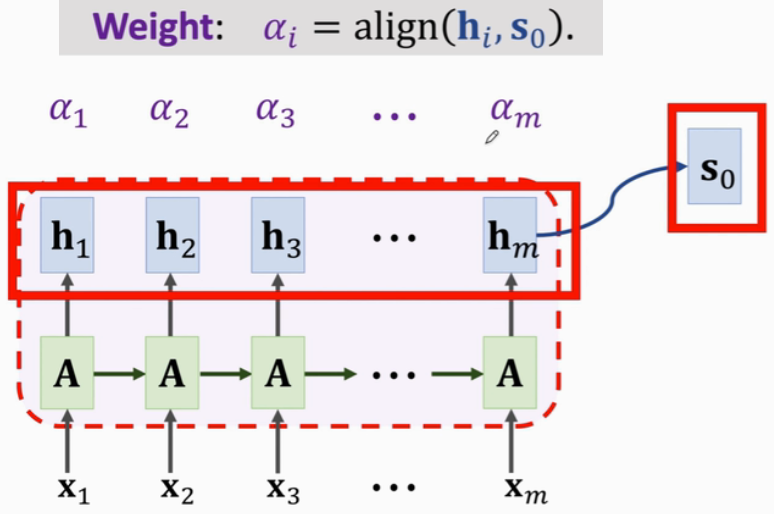
计算 hi 和 s0 的相关性,有2种方法:
(1)原论文提出:

(2)更常用,同Transformer:

- 每一个 权重αi 对应一个 Encoder状态hi
- 对 α 和 h 做加权平均,得到向量c(Context Vector)
- 每一个 Context Vector ci 对应一个 Decoder状态si

c0是Encoder所有状态的加权平均,故c0知道Encoder输入x1~xm的完整信息;
Decoder新状态s1依赖于c0,故Decoder也知道Encoder的完整输入,解决了RNN遗忘的问题
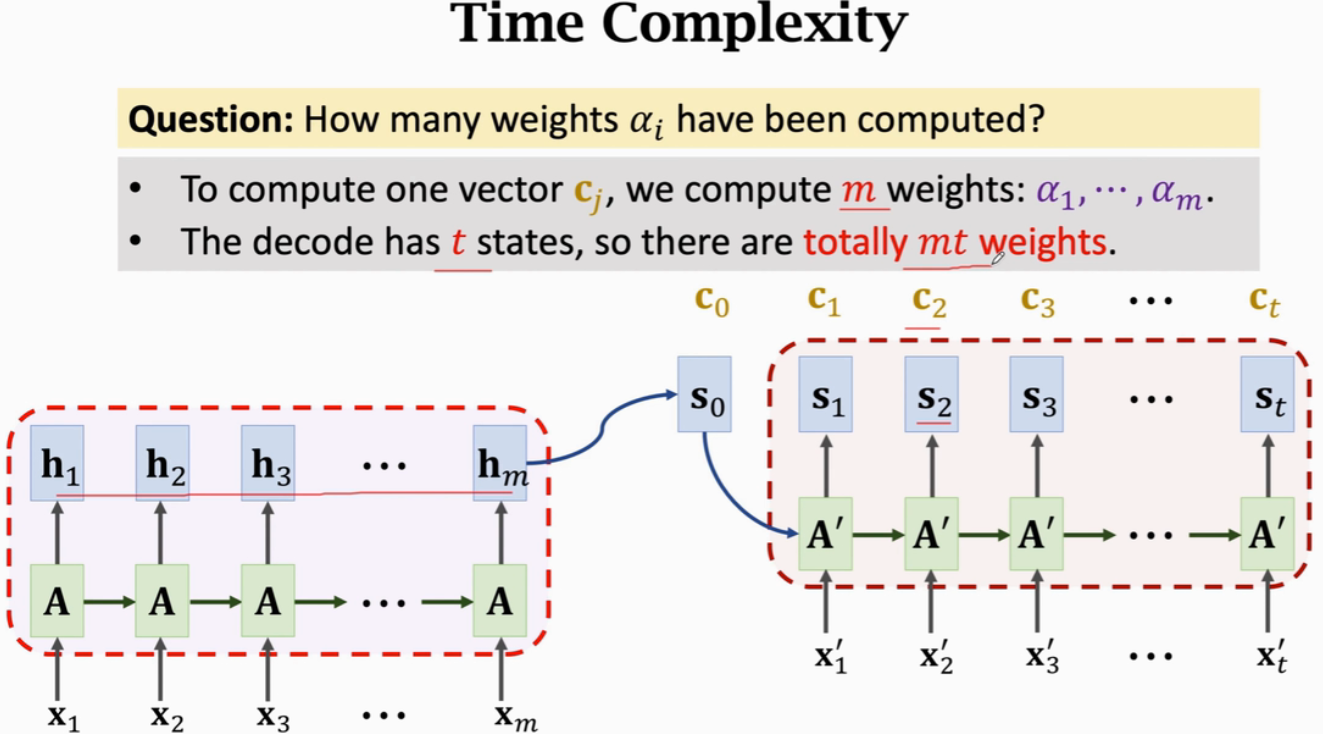
Attention的时间复杂度(也是weights的数量):Encoder 和 Decoder 状态数量的乘积
可视化:
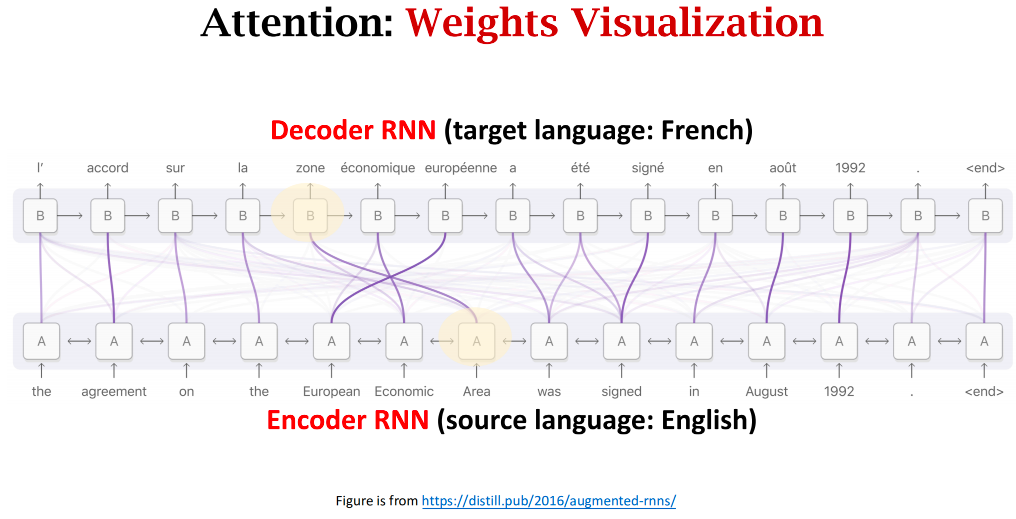
每当Decoder想要生成一个状态时,都会看一遍Encoder的所有状态,同时权重weights会告诉Decoder要关注Encoder的哪个状态
Seq2Seq:Decoder基于当前状态来生成下一个状态,这样产生的新状态可能已经忘了Encoder的部分输入
Attention:Decoder在产生下一个状态之前,会先看一遍Encoder的所有状态,于是Decoder就知道Encoder的完整信息,并不会遗忘;除此之外,还能告诉Decoder应该关注Encoder的哪个状态
Attention可以大幅提升Seq2Seq模型的表现,缺点是计算量太大
假设输入Encoder的序列长度为m,Decoder输出序列长度为t
Seq2Seq:只需要Encoder读一遍输入序列,之后不会再看Encoder的输入或状态;Decoder依次生成输出序列,时间复杂度O(m+t)
Attention:Decoder每次更新状态,都要把Encoder的m个状态都看一遍,Decoder又有t个状态,故时间复杂度为O(mt)
2、Self-Attention
Attention用在Seq2Seq上,Seq2Seq有2个RNN网络(一个Encoder一个Decoder)
而Self-Attention是把Attention用在一个RNN网络上

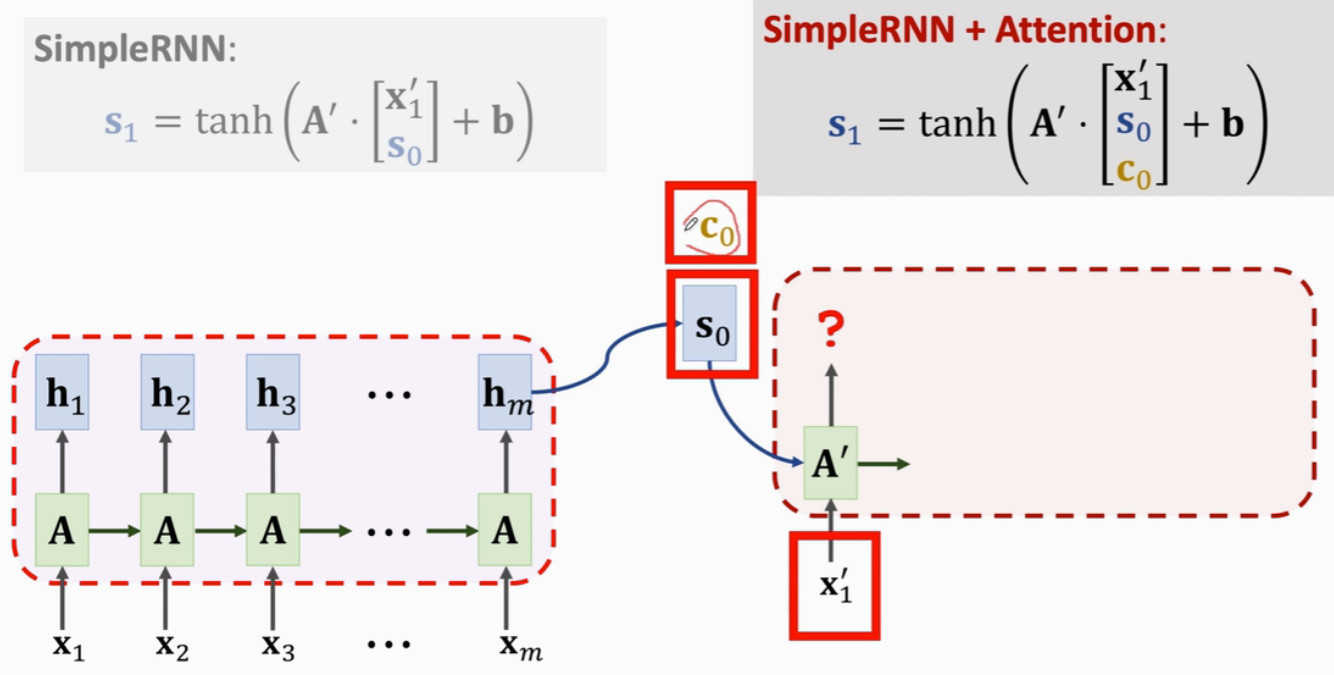
SimpleRNN + Self-Attention
初始状态向量h0 和 Context Vector c0 都为全零向量
RNN读入第一个输入x1,需要更新状态h1:

计算新的Context Vector c1:是已有状态h的加权平均(由于初始状态h0是全零向量,故忽略h0,此时c1=h1)
计算新的状态h2:

计算新的Context Vector c2:

以此类推
初始状态向量h0 和 Context Vector c0 都为全零向量
重复以下步骤:
- 读入向量xi
- 用 xi 与 ci-1 计算出新的状态hi:hi = tanh(A·[xi ci-1]^T + b)
- 拿当前状态hi与h1~hi(h0为全零向量,不考虑)作对比,计算权重α1~αi
- 计算i个状态向量h的加权平均,得到新的context vector ci
RNN都有遗忘的问题,Self-Attention可以解决RNN遗忘的问题(每一轮更新状态之前,都会用Context Vector c看一遍之前所有的状态,这样就不会遗忘之前的信息了)
Self-Attention不局限于Seq2Seq模型,可以用在所有RNN上
除了避免遗忘,Self-Attention还能帮助RNN关注相关的信息

(四)Transformer(=Attention without RNN)
1、剥离RNN,保留Attention
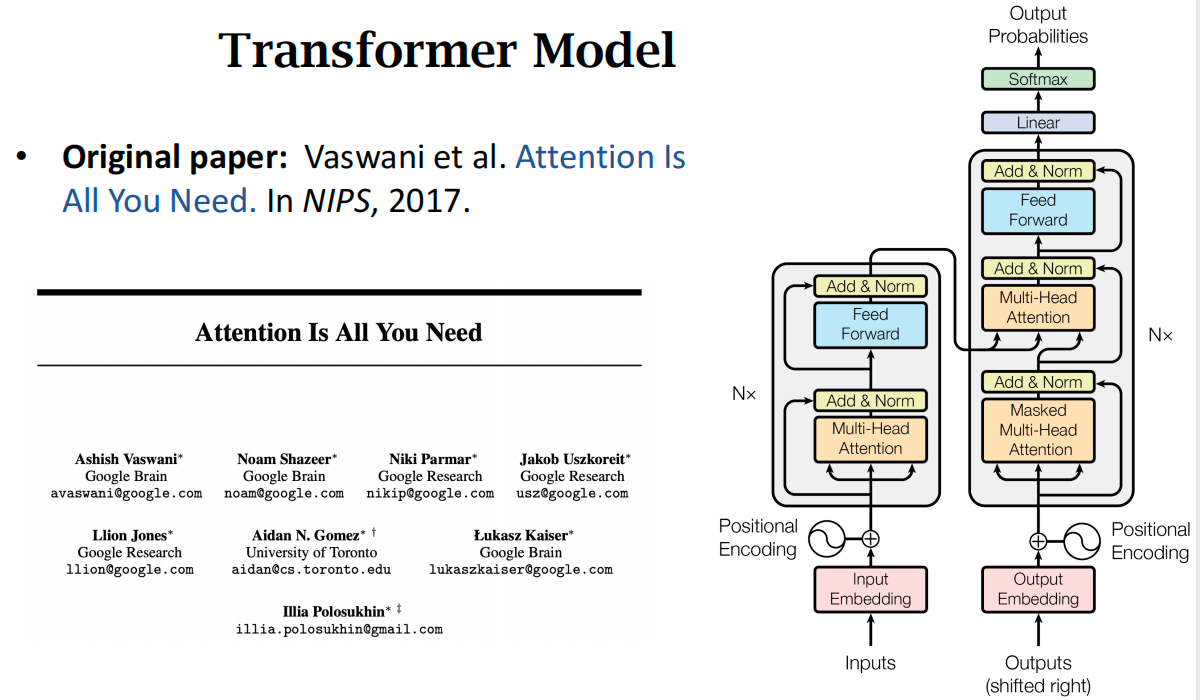
- Transformer是一种Seq2Seq模型(Encoder & Decoder,适合做机器翻译)
- Transformer不是循环神经网络RNN,没有循环的结构,只有Attention和全连接层
- 在大数据集上,Transformer的accuracy显著高于RNN
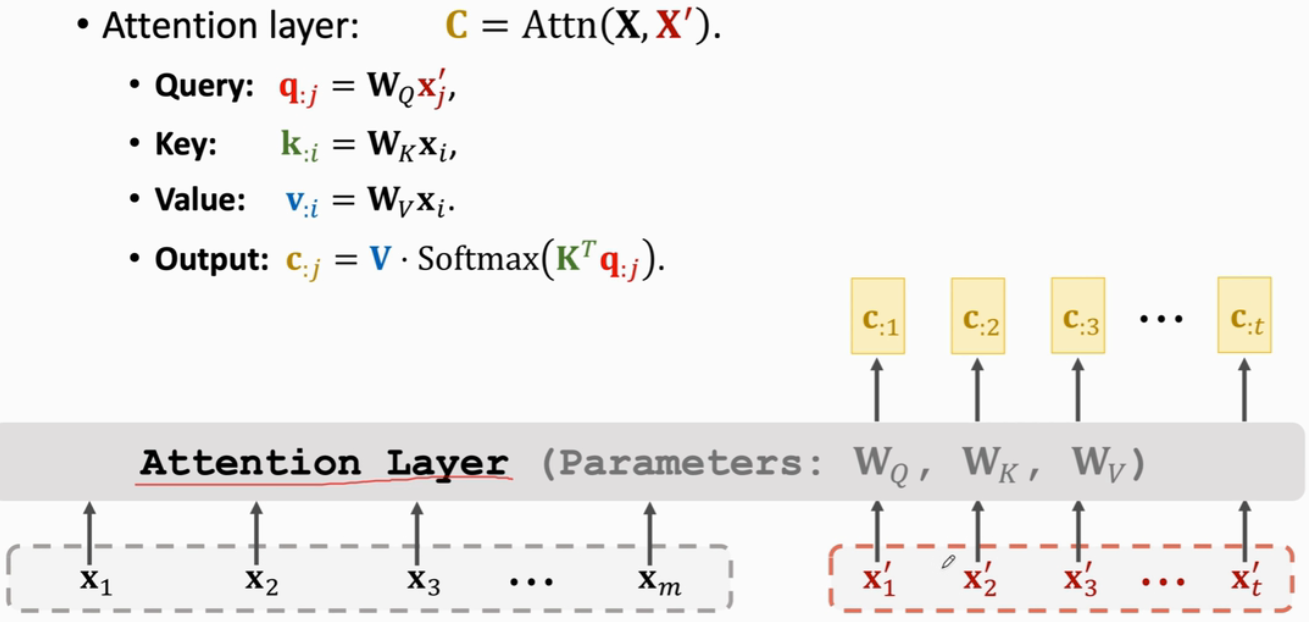
(1)Attention for Seq2Seq Model
i是Encoder状态h的下标,j是Decoder状态s的下标

计算过程:
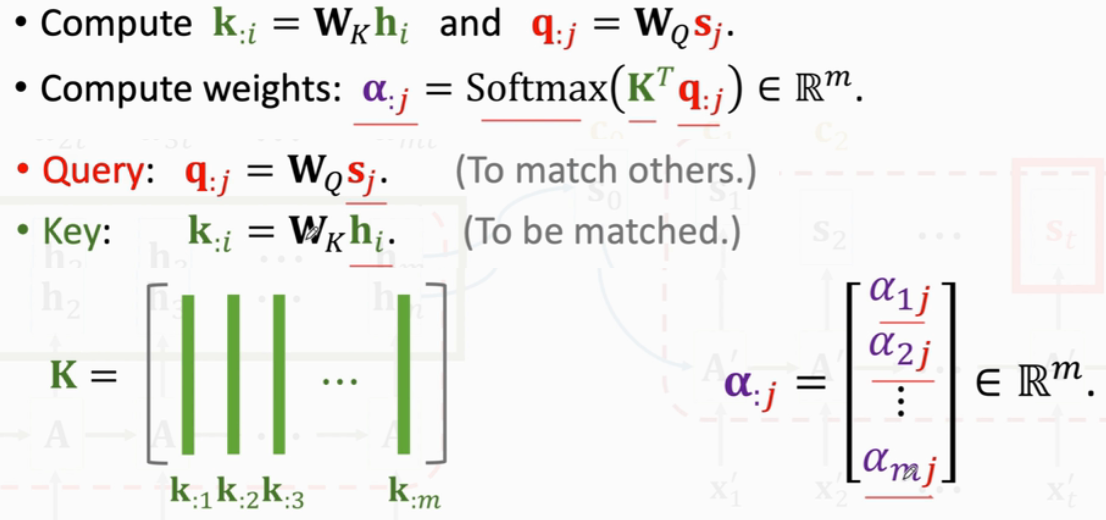
Attention中一共有3个参数矩阵:

Transformer里用的:

(2)Attention without RNN
Transformer就是由Attention层(Seq2Seq)和Self-Attention层组成的
一共有3个参数矩阵,Encoder中有K和V,Decoder中有Q
- Encoder的input:x1~xm(生成Key和Value)
- Decoder的input:x1'~xt'(生成Query)

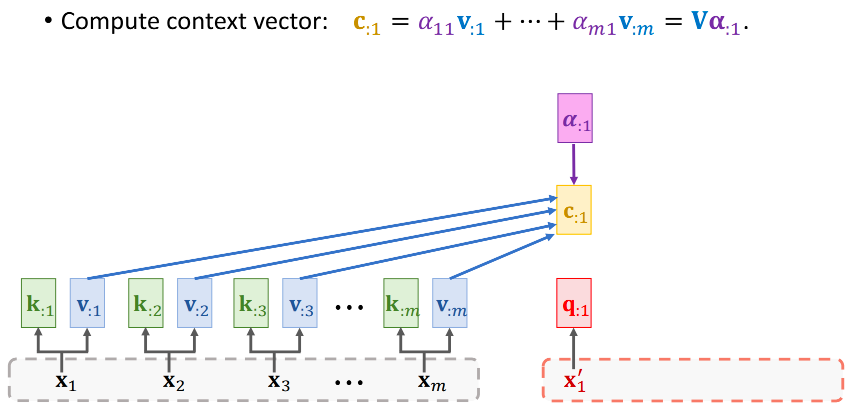

如英译德,英语里有m个词变为词向量(即x1~xm),把当前生成的德语单词作为下一轮的输入:
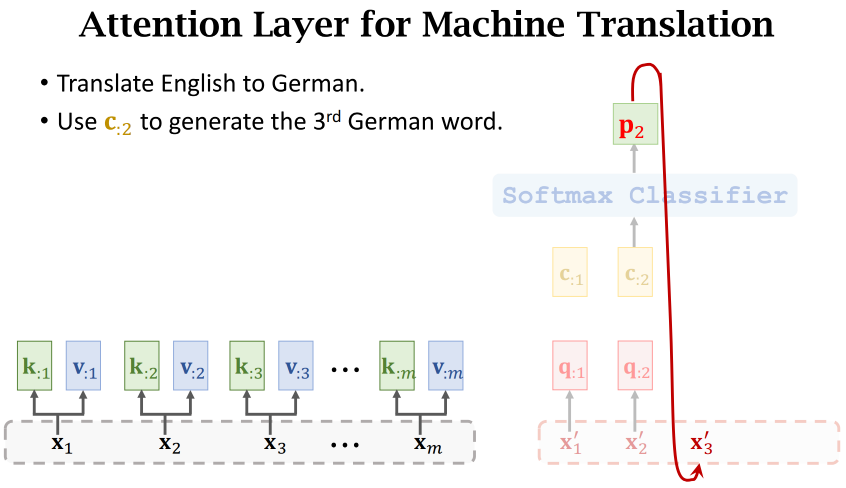
Attention与RNN做机器翻译的不同在于:
- RNN会把状态h作为特征向量输入softmax
- 而Attention是把Context Vector c作为特征向量(可以用Attention Layer代替RNN,它不会遗忘)
Attention层:有两个输入序列X和X',有一个输出序列C,每个c向量对应一个x'向量

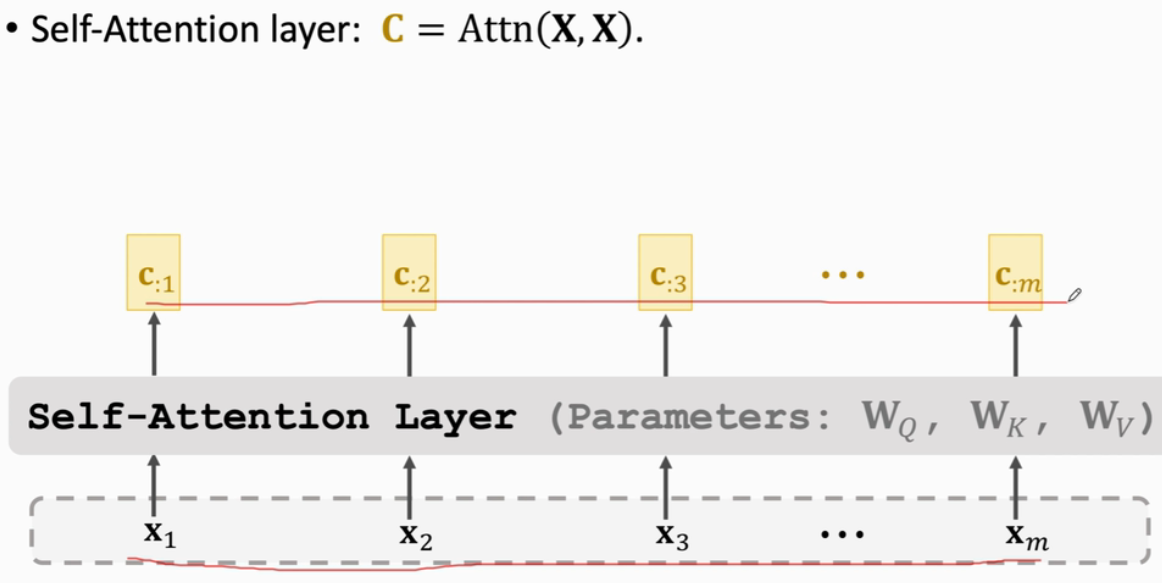
(3)Self-Attention without RNN
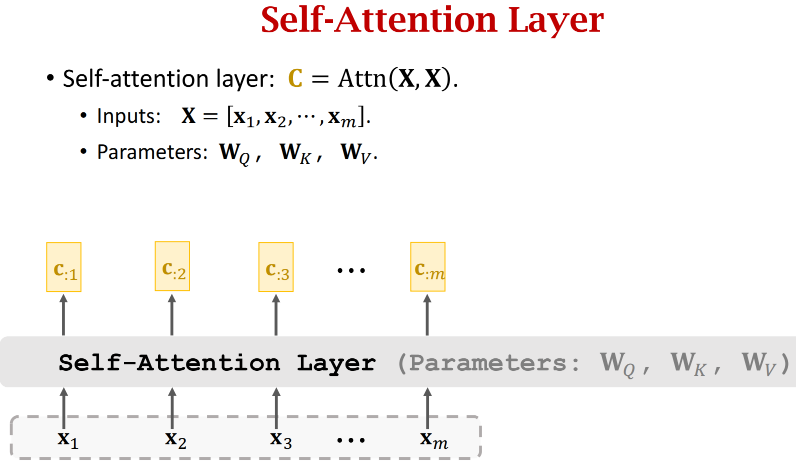
- Attention用于Seq2Seq,有2个输入序列(如英译德,英文一个输入序列,德语一个输入序列)
- Self-Attention不是Seq2Seq,它只有一个输入序列,其他跟Attention完全一样


以此类推计算得到其他α

以此类推计算得到其他c
ci 并非只依赖于 xi,而是依赖于所有m个x(改变任何一个x,输出的ci都会发生变化)
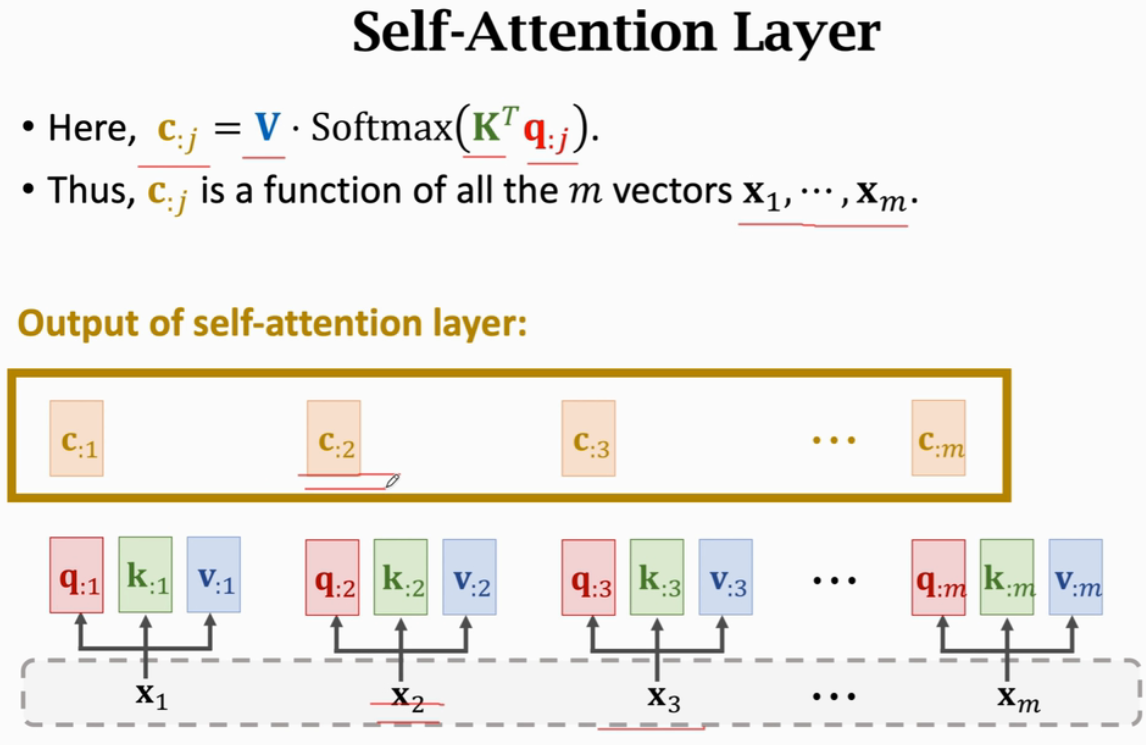
Attention最初提出是用在Seq2Seq模型,但Attention不局限于Seq2Seq,而是可以用在所有RNN上
若只有一个RNN网络,Attention就是Self-Attention
不用RNN,只用Attention,就是Transformer
(4)Multi-Head Self-Attention
由 l 个单头组成(不共享参数),每个单头有3个参数矩阵,故多头共有 3l 个参数矩阵
所有单头Self-Attention都有相同的输入x1~xm序列,但它们的参数矩阵各不相同,故输出的c序列也各不相同。把 l 个单头的输出(d×m)堆叠起来,作为多头的输出(ld×m)
(5)Multi-Head Attention
所有单头Attention的输入都是两个序列x1~xm以及x1'~xt'
每个单头Attention都有各自的参数矩阵(不共享参数)
每个单头都有自己的输出序列c,把单头输出的序列c堆叠起来,就是多头的输出
2、从Attention层到Transformer网络
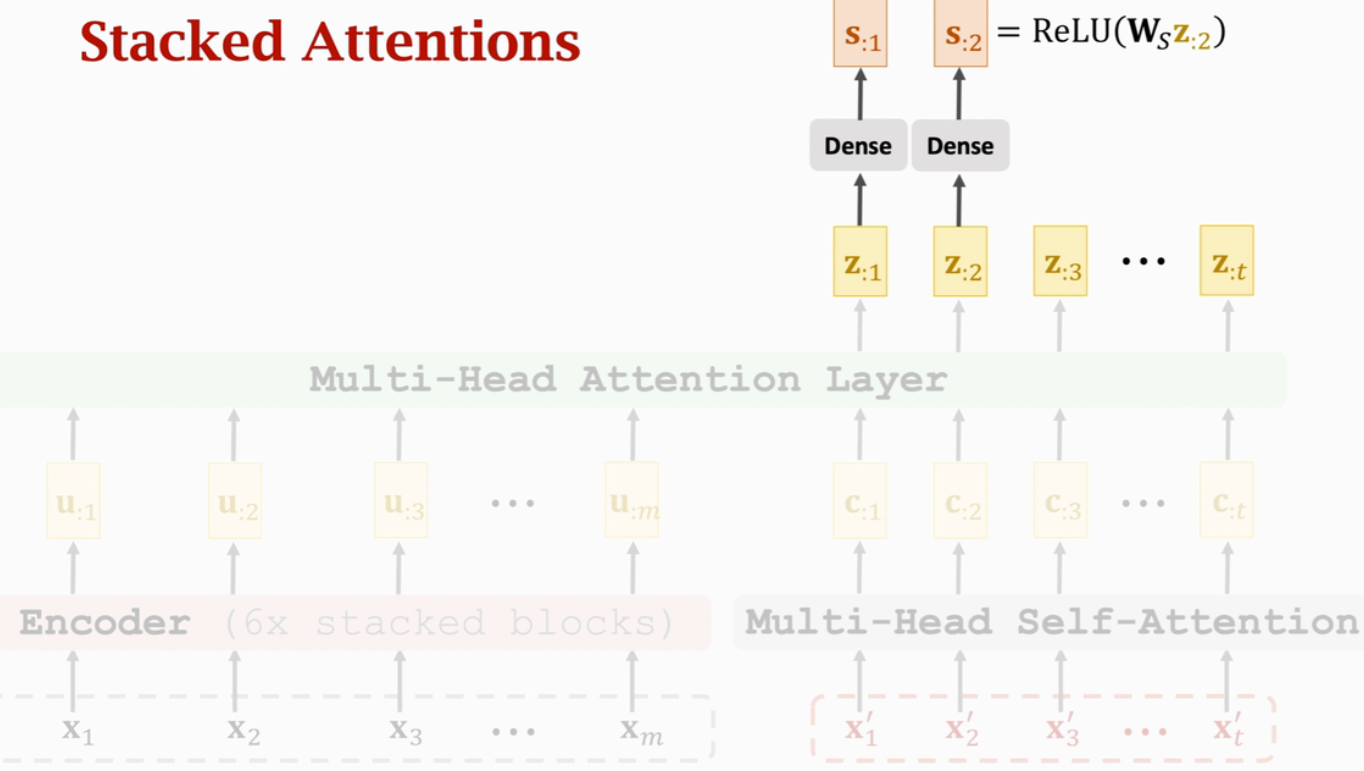
(1)Stacked Self-Attention Layers
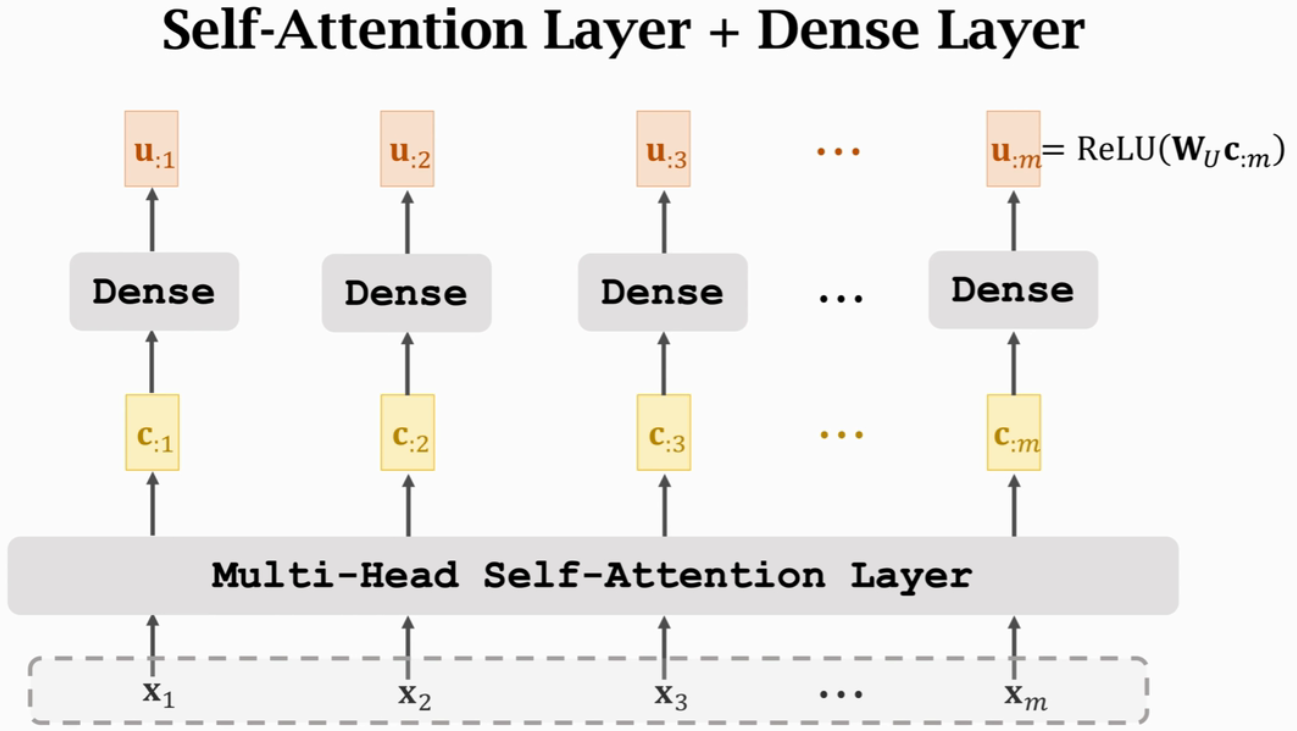
输入x1~xm,输出u1~um。但ui依赖于x1~xm,而不是仅仅依赖于xi
Transformer Encoder
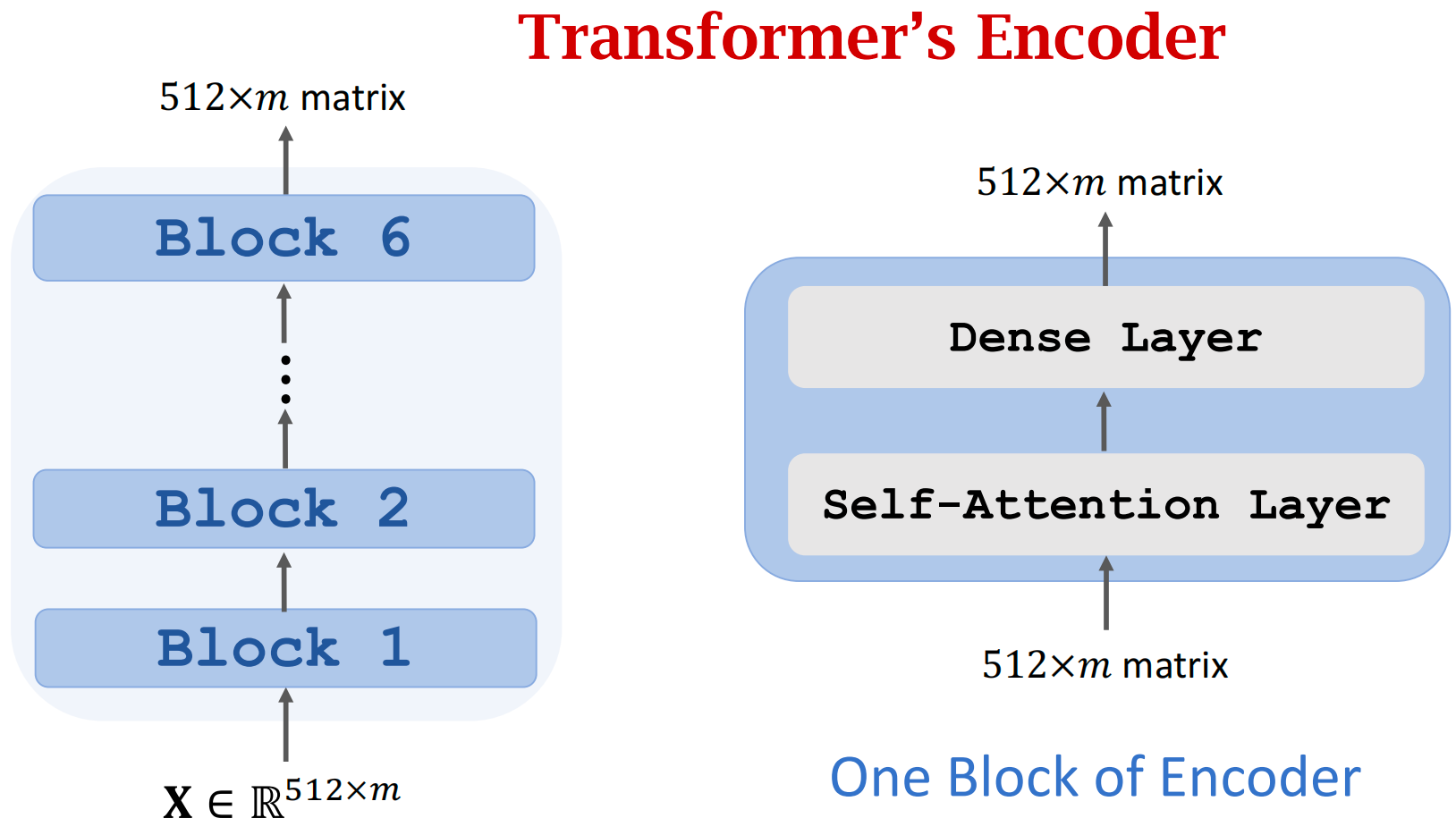
- 6个blocks,每个block有自己的参数,不共享
- 每个Block有2层——Self-Attention Layer + Dense Layer
- 输入和输出都是512×m的矩阵(m是输入序列x的长度,每个x向量都是512维),故可以用ResNet的Skip Connection方式,把输入加到输出上
(2)Stacked Attention Layers
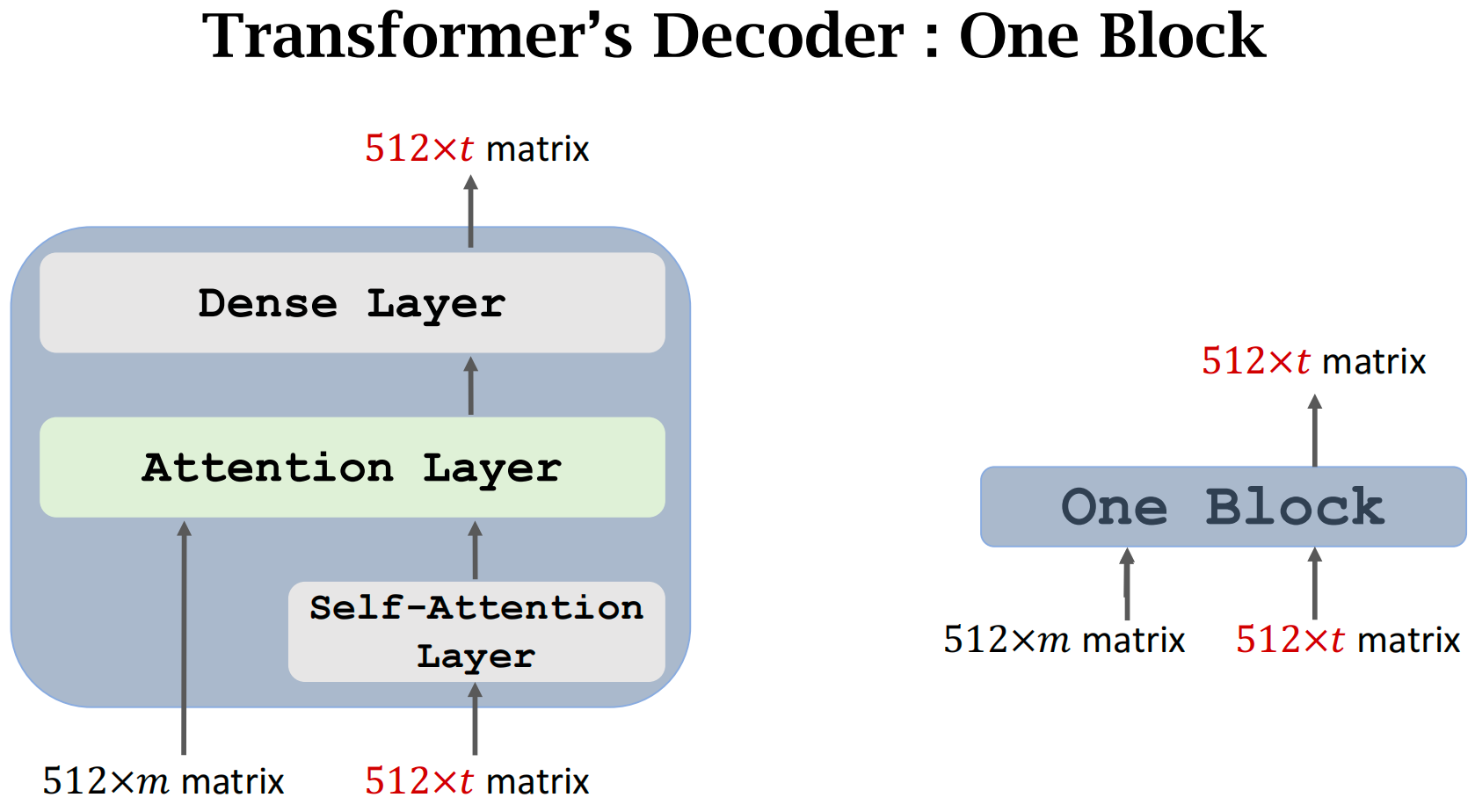
Transformer Decoder
- 一个block有3层:Self-Attention层、Attention层、全连接层
- x1'~xt' 以及 c 以及 z 都是512维的向量
Decoder的一个Block如图所示,需要两个输入序列,输出一个序列
(3)Transformer
Encoder:
- 6个Blocks,每个Block有2层
- 输入有m列,每列都是512维的词向量,输出维度同输入
Decoder:
- 6个Blocks,每个Block有3层:Self-Attention、Attention、全连接层
- 每个Block有两个输入序列(Encoder网络的输出+上一个Decoder Block的输出),一个输出序列(t个向量,每个向量都是512维)

3、对比RNN Seq2Seq
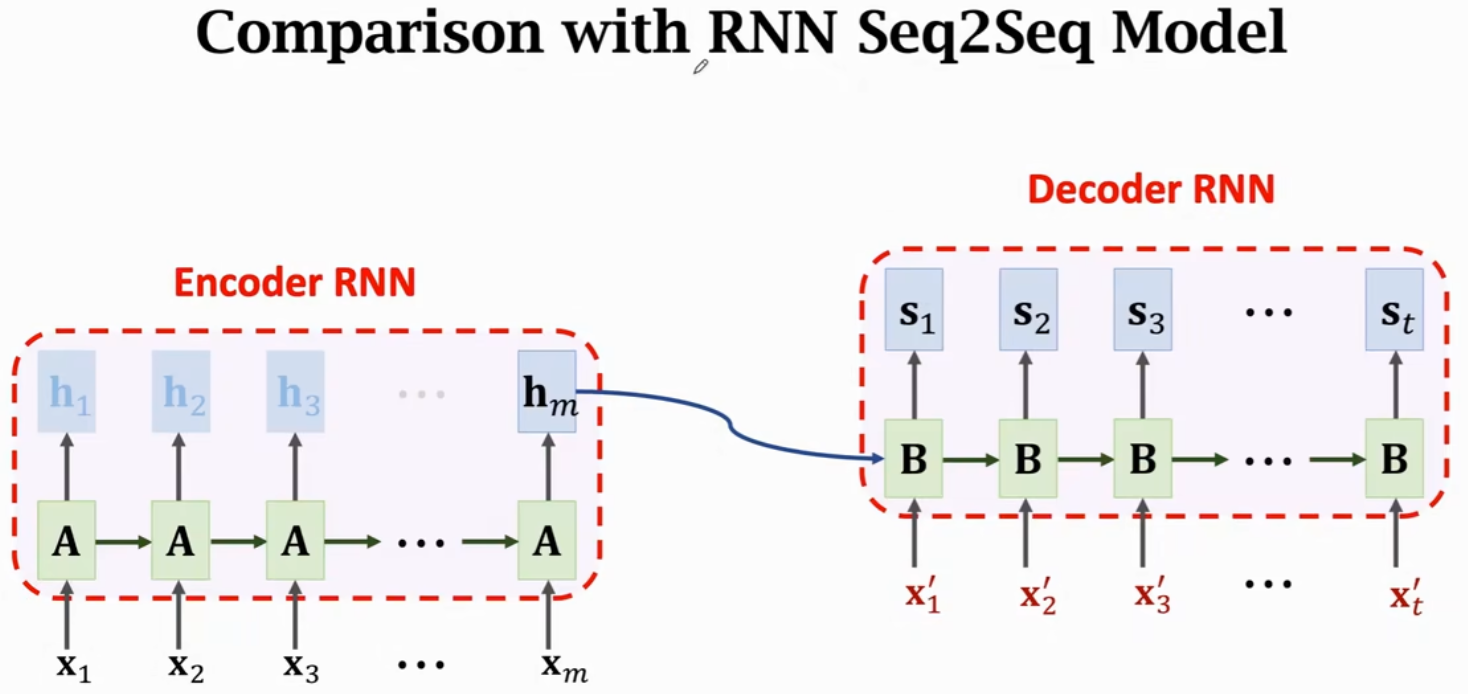
两者输入、输出大小完全一样:
- RNN Seq2Seq有两个输入序列(Encoder:x1~xm,Decoder:x1'~xt'),Transformer同
- RNN Seq2Seq有一个输出序列s1~st(Decoder输出),Transformer同



4、Example:英译德


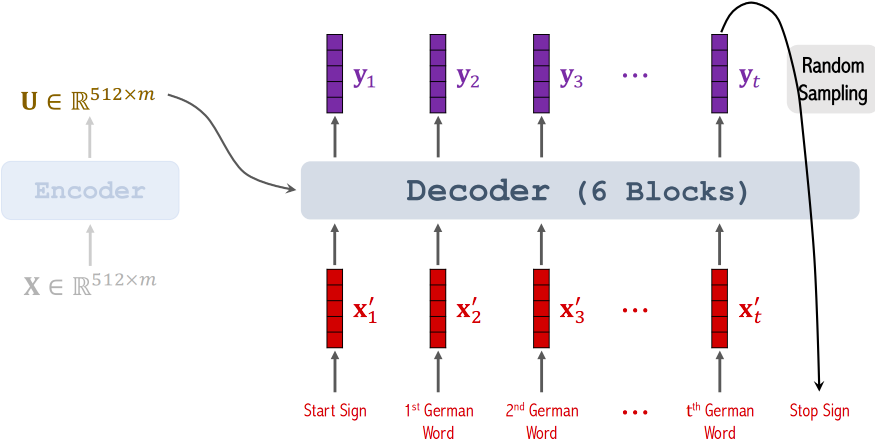
Encoder:有6个block(block之间不共享参数,block之间还有skip-connection的技巧),每个block = 多头self-attention + dense,每个block的输入、输出都是512×m(m是输入序列的长度)
Decoder:有6个block(block之间不共享参数,block之间还有skip-connection的技巧),每个block = 多头self-attention + 多头attention + dense,每个block的输入是两个序列:(512×m,512×t),输出一个序列512×t
Transformer:
- Seq2Seq模型,有Encoder和Decoder,可以用来做机器翻译;
- 不是RNN,无循环结构;
- 完全基于Attention和Self-Attention和全连接层;
- 和RNN的输入、输出大小一样
(五)Bert(Bidirectional Encoder Representations from Transformers)
一种用来预训练Transformer Encoder网络的方法,从而大幅提高准确率。有以下2个任务:
- 随机遮挡一个或多个单词,让Encoder网络根据上下文来预测被遮挡的单词
- 两个句子放在一起,让Encoder网络判断两句话是不是原文里相邻的两句话
1、预测被遮挡的单词
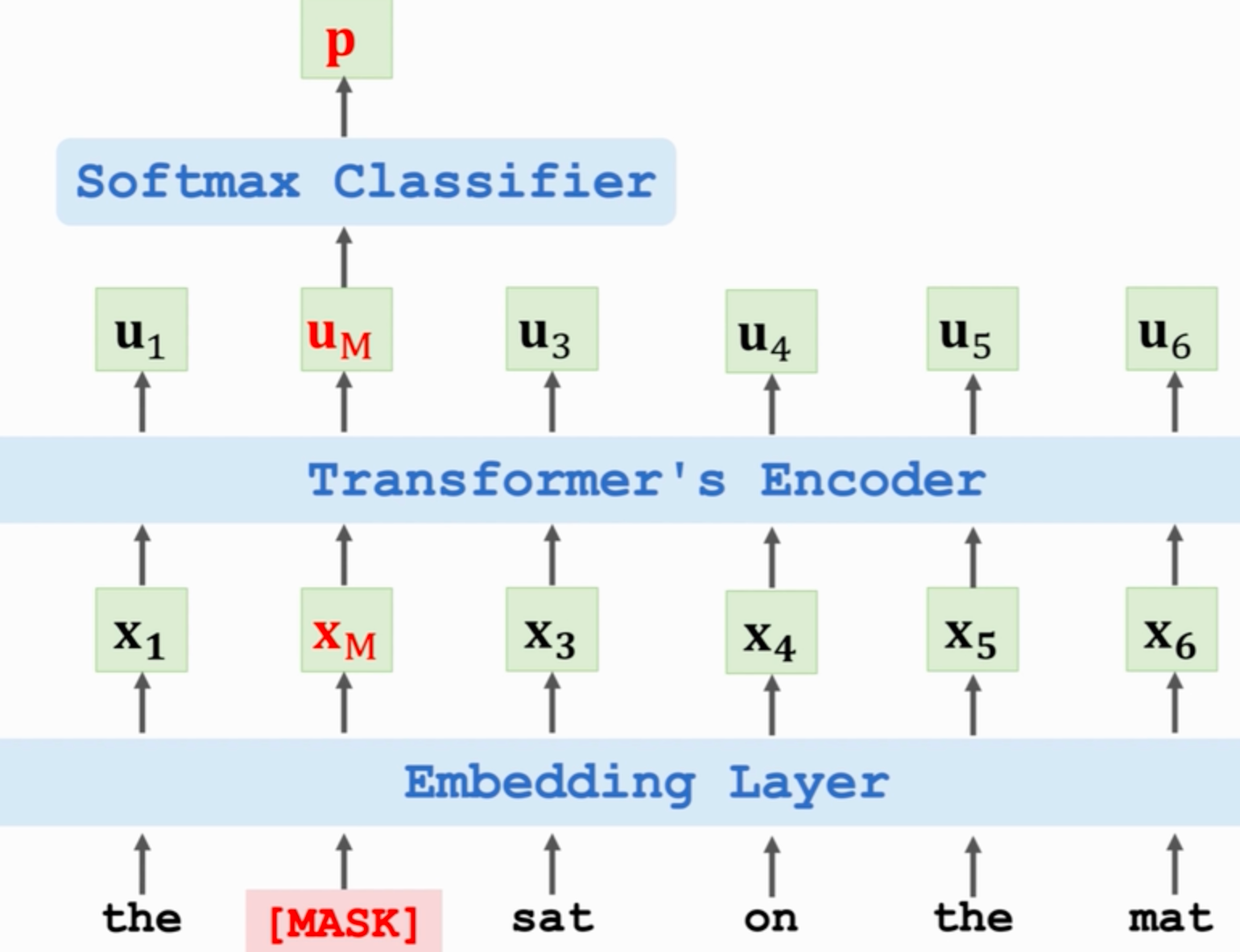
Um不仅依赖于Xm,而是依赖于所有X向量。即 Um在 [MASK] 位置上,但它包含整句话的上下文信息

用反向传播算出损失函数关于模型参数的梯度,然后做梯度下降来更新模型参数
- Bert会随机遮挡单词,把遮住的单词作为标签;
- Bert预训练不需要人工标注的数据集,可以自动生成标签
- 多分类
2、预测下一个句子
二分类:0代表False(两句话不相邻),1代表True
例1:

例2:

50%是确实相邻的两句话(标签True),还有50%的第二句话是随机抽取的(标签False)

向量c在[CLS]位置上,但它包含两句话的全部信息,所以靠向量c就能判断两句话是否真实相邻
这样做预训练有什么用呢?
- 相邻两句话通常有关联,这样做二分类可以强化这种关联,让Embedding和词向量包含这种关联
- Encoder网络里有Self-Attention层(作用:找相关性),这种分类任务可以训练Self-Attention找到正确的相关性
3、结合两个任务
把两句话拼接起来,并随机遮挡15%的单词

目标函数是多个损失函数的加和。把目标函数关于模型参数求梯度,然后做梯度下降来更新模型参数

4、Bert的特点
- 不需要人工标注数据,两种任务的标签都是自动生成的
- 计算代价大
- 训练好的模型参数是公开的
bert可以利用海量数据来训练一个超级大的模型
bert的Embedding层不是简单的word embedding,还有一些技巧
(六)ViT(Vision Transformer)
Dosovitskiy. An image is worth 16×16 words: transformers for image recognition at scale. In ICLR.
- Transformer模型在图片分类(自动判断图片中的物体是什么)上的应用
- 目前图片分类最好的模型,超越了最好的CNN(ResNet),前提是要在足够大的数据集上做预训练。数据集越大,ViT优势越明显

1、ViT
就是Transformer Encoder网络
(1)Split Image into Patches
把图片划分为大小相同的patches(可以有重叠overlap,也可以没有)
- 用一个滑动窗口,每次移动若干个像素
- 每次移动的步长叫stride(stride越小,得到的patches越多,计算量越大)

对图片划分的时候,需要指定两个超参数:
- patch size:每块patch的大小,如16×16
- stride:滑动窗口移动的步长,如16×16(=patch size,无overlap)
(2)Vectorization向量化
每个小块都是一张彩色图片,有RGB三通道,即每个小块都是一个张量
把张量拉伸为向量:

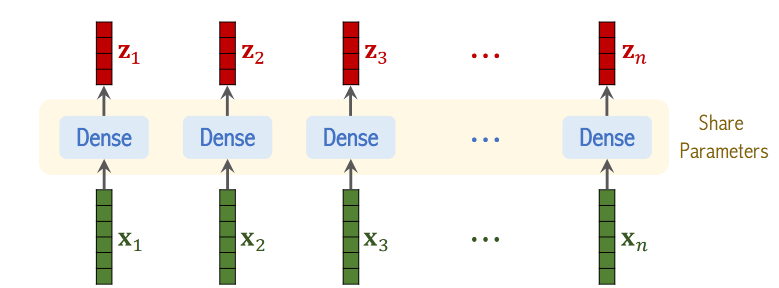
设图片被划分为了n块,变为了n个向量,首先用全连接层对向量x做线性变换
- 此处全连接层不使用激活函数,只是线性函数
- W和b是参数,从训练数据中学习,且对全连接层是共享的

(3)Positional Encoding
对图片每一块的位置做编码
- 图片被分为n块,那么位置就是1~n之间的整数,每个位置被编码为一个向量,向量大小跟z向量相同
- 把位置编码向量加到z向量上,这样一来,一个z向量既是patch内容的表征,也包含patch的位置信息
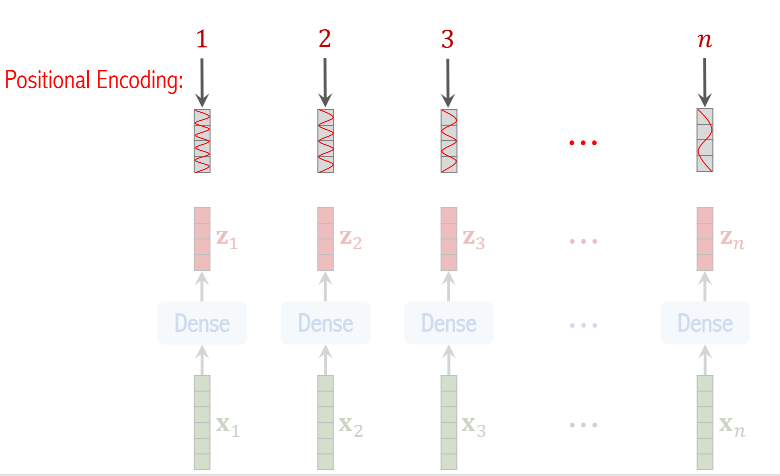
为什么要用PE?
- 如果不用,会掉3个百分点的准确率
- 不同的PE方式表现几乎一样,用什么样的PE影响不大
- 若z向量里不包含位置信息,那么以下两张图在Transformer眼里是一样的

(4)网络结构
- x1~xn是图片中n个小块向量化得到的结果
- 对x1~xn做线性变换,并加入位置信息,得到z1~zn为图片n个小块的表征(既包含内容信息,又包含位置信息)
- [CLS] 表示分类,对这个符号做Embedding,得到向量z0(跟其他z向量大小相同),这个输出被用作分类

- Transformer里有skip connection,把每一层的输入加到输出上
- 还有BN的技巧

输出n+1个向量c,其中c1~cn没有用,c0可以看做是从图片中提取的特征向量,用作分类任务

2、训练

随机初始化神经网络参数 -> 在大数据集A(如JFT,三亿张图片)上做预训练 -> 在小数据集B(任务/目标数据集,如ImageNet图片分类,30w张图片)训练集上做微调 -> 在数据集B测试集上评价模型表现,得到测试准确率

- 当预训练数据集不够大时,ViT表现不好
- 用越大的数据集(超过1亿张)做预训练,ViT效果越好(比ResNet高1个百分点)
- 预训练数据量1亿或3亿,对于ResNet来说区别不大








![基础IO[一]](https://img-blog.csdnimg.cn/direct/0192bf8e152b45dda673209a440bbbbd.png)