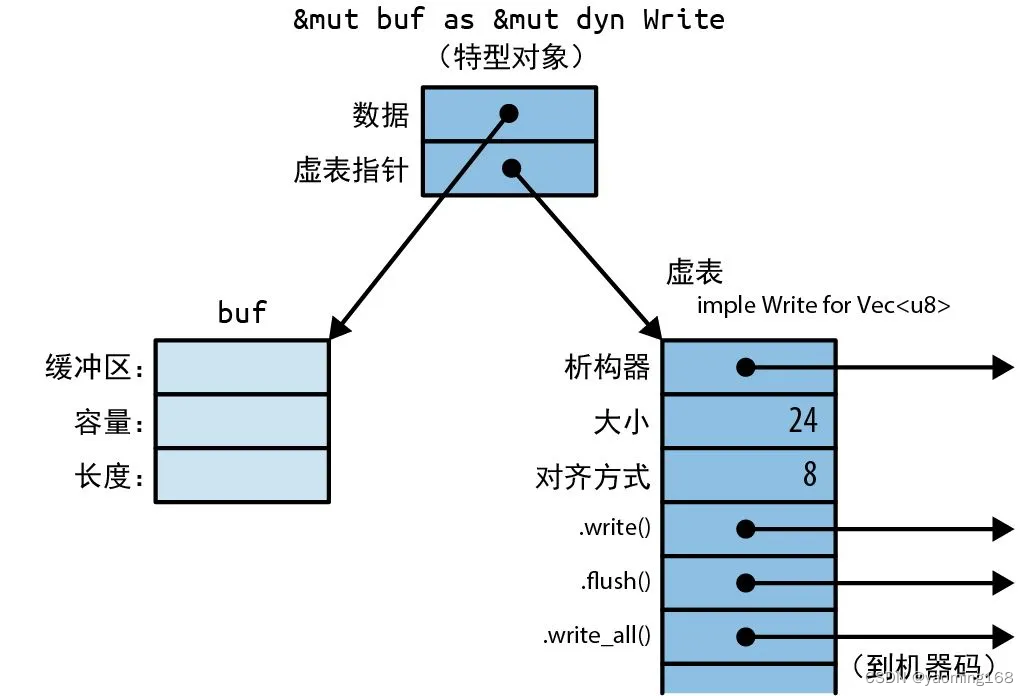
在上一节《Modern C++ 内存篇1 - std::allocator VS pmr-CSDN博客》我们详细讨论了关于如何判断用不用memmove优化的代码,结论可以总结为:
只有_Tp是trivial 且 用std::allocator 才会调用memmove。
所有case如下表格所示:
| No | _Tp | allocator type | 使用memmove? | 可能的原因 |
| 1 | is trivial | std::allocator | Yes | - |
| 2 | is trivial | std::pmr::polymorphic_allocator | No | 底层的memory resource有不连续的可能 |
| 3 | not trivial | std::allocator | No | _Tp构造函数或析构函数非默认(比如有打印);构造函数可能抛出异常故必须小心的一个个构造;或有指向自身结构的指针(比如链表node) |
| 4 | not trivial | std::pmr::polymorphic_allocator | No | 以上两者 |
上面的原因是猜测的啊。
其中case 2,底层的memory resource用户可以写成天马行空任意的样子,理论上可以做成不连续的,但其实接口和std::pmr::vector如何使用这些接口基本把这种可能性给抹杀掉了。

/usr/include/c++/11/bits/vector.tcc
429 template<typename _Tp, typename _Alloc>
430 void
431 vector<_Tp, _Alloc>::
432 _M_realloc_insert(iterator __position, const _Tp& __x)
433 #endif
434 {
435 const size_type __len =
436 _M_check_len(size_type(1), "vector::_M_realloc_insert");
437 pointer __old_start = this->_M_impl._M_start;
438 pointer __old_finish = this->_M_impl._M_finish;
439 const size_type __elems_before = __position - begin();
440 pointer __new_start(this->_M_allocate(__len));
即使我写了一个memory resource悄悄的实现do_allocate做了多次零碎的小分配以满足size=bytes的要求,vector.tcc也用不上,因为它把代码写死了默认是一整块连续的内存。
所以,我个人觉得:实际case 2也是可以用memmove来加速relocation的。
case 3,难点是编译器很难判断你的构造函数析构函数悄悄的干了什么,如果新加一个属性比如relocable允许用户标识我的类是否可以直接memmove就好了。实际C++26也在研究类似的问题。modern c++就像一块块大积木能快速搭建东西,但棱角的精度(性能)就没有c那么高了。标准需要在性能和易用性之间做个平衡。
Ref:
1. https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/p2786r3.pdf
2. P1144R6: Object relocation in terms of move plus destroy