环境:
Vits2.3-Extra-v2:中文特化修复版
auto_DataLabeling
干声10分钟左右.wav
问题描述:
Vits2.3-Extra-v2:中文特化,如何训练及推理(新手教程)
解决方案:
一、准备数据集
切分音频
本次音频数据自己录制干声10分钟左右
1.运行auto_DataLabeling\slicer-gui\slicer-gui.exe
2.点击左上角Add Audio Files,导入源音频文件
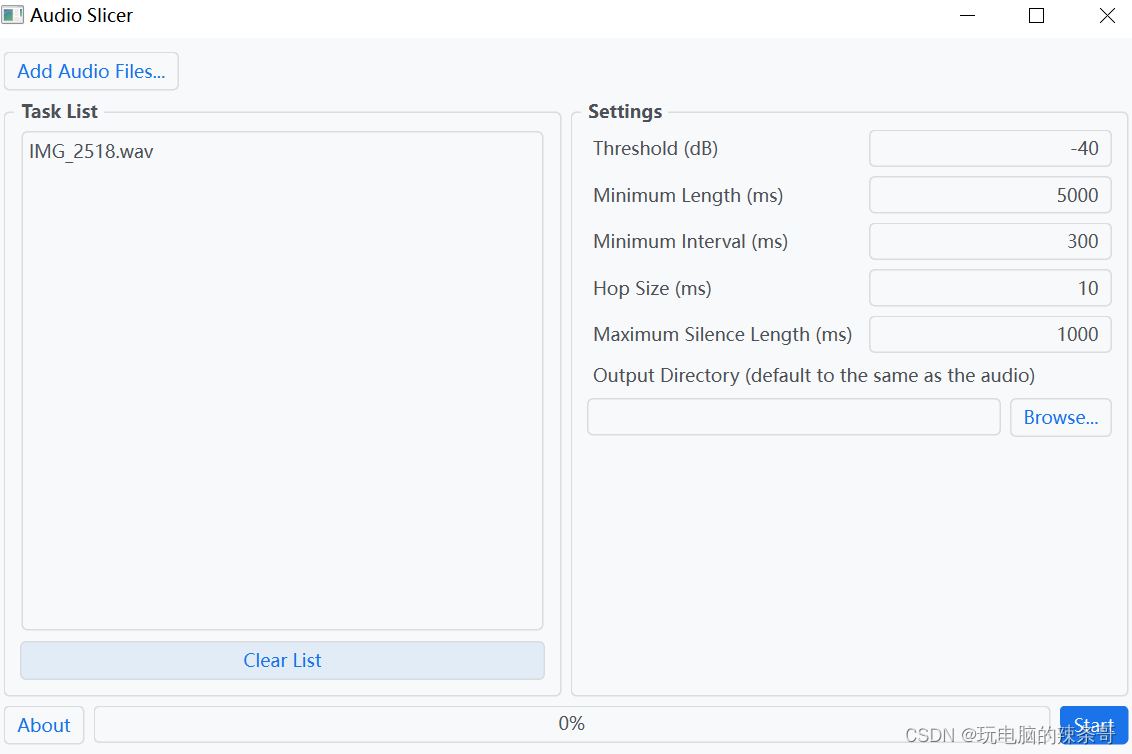
3.将输出目录设置为auto_DataLabeling\raw_audio

 点击start
点击start
切片好的音频经过手动筛选删除过短的音频
4.开始标注并清理标注
根据需求运行0.带标点符号的标注.bat
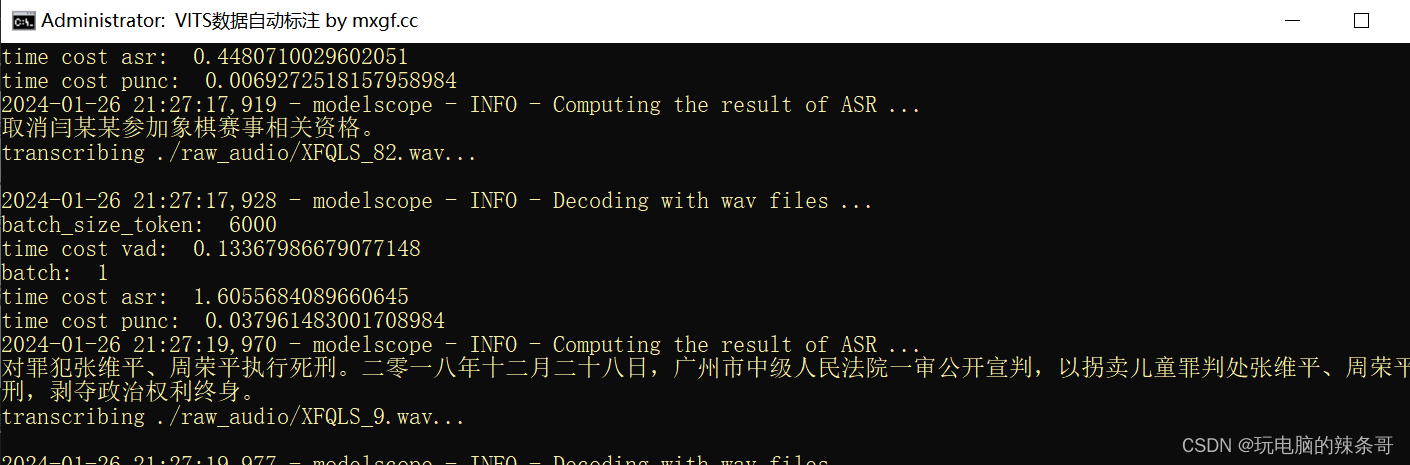
5.运行2.清理用于Bert_VITS2的标注.bat清理标注
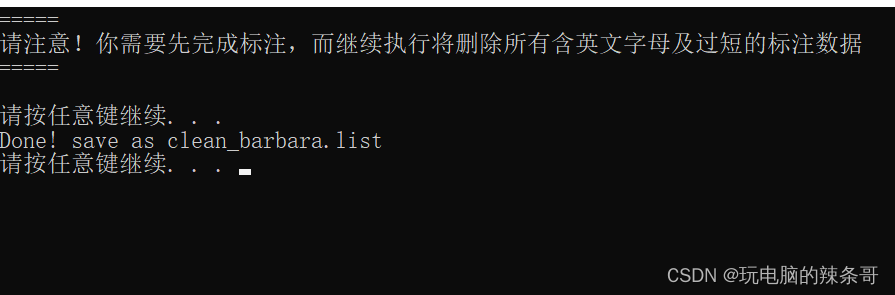 如果要另外标注删除long_character_anno里面内容(适用二次标注)
如果要另外标注删除long_character_anno里面内容(适用二次标注)
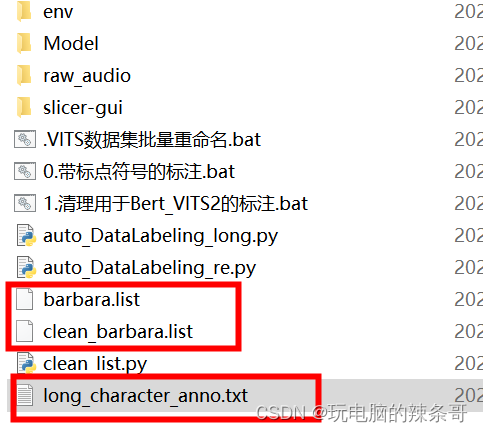
6.运行auto_DataLabeling\raw_audio.VITS数据集批量重命名.bat自动重命名文件
 完成
完成
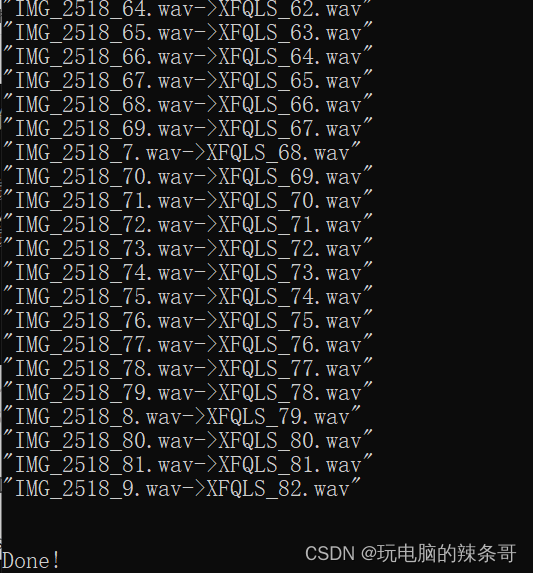 7.把重命名文件后的音频文件放入Bert-Vits2/dataset/你的数据集名称文件夹中
7.把重命名文件后的音频文件放入Bert-Vits2/dataset/你的数据集名称文件夹中

8.把clean_barbara.list复制到Bert-Vits2/filelists/文件夹中
提示
别忘了改config.yml中的各个路径, 有些不好改的可以直接复制到Data文件夹里
将生成的clean_barbara.list放入Bert-Vits2/filelists/文件夹中

二、Vits2.3训练准备
1.声音重采样
将音频文件重采样为44100Hz,可以使用Audacity或者ffmpeg
本次直接运行Bert-VITS2\resample.py
操作的目录见config.yml中的in_dir与out_dir
进入bert-vits2目录
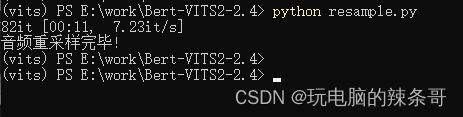
2.运行下面命令,进行声音重采样
python resample.py
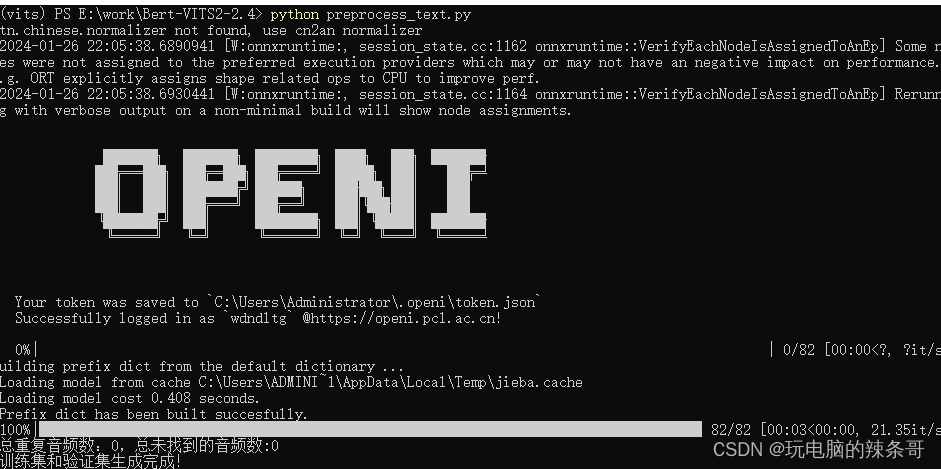
3.划分标注数据
python preprocess_text.py
4.生成bert特征文件
python bert_gen.py
如报错缺少模型Erlangshen-MegatronBert-1.3B-Chinese
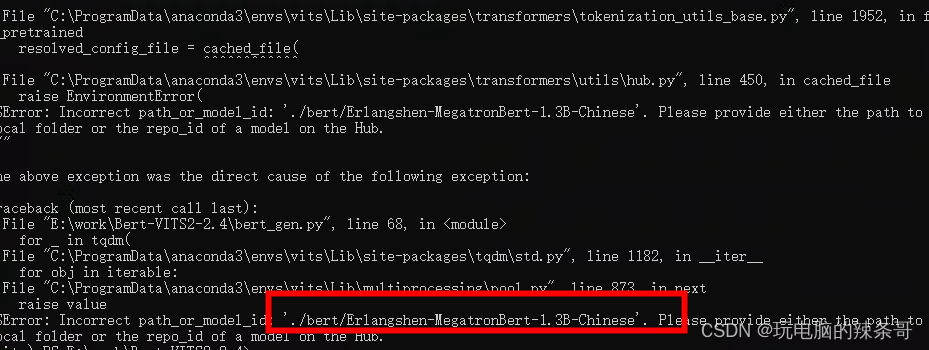 下载后
下载后


配置文件这边,改为1
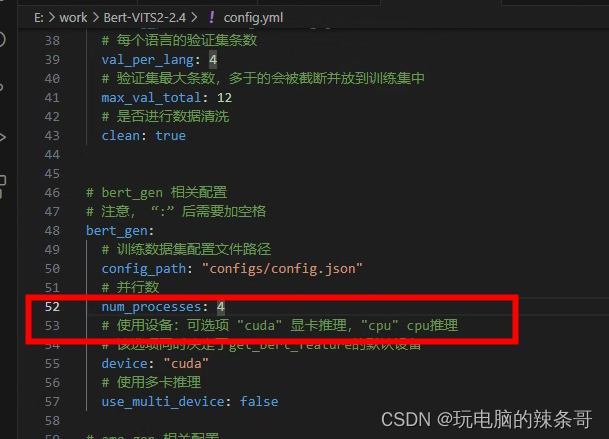
再次生成ok

5.生成clap特征文件
python clap_gen.py
改写config.yml中的transcription_path为filelists/clean_barbara.list

6.使用底模:
在config.yml中找到train_ms,将use_base_model改为true,并将num_workers改为少于cpu核心数的值


三、开始训练
修改config.json中的"train""epoch"为你想要的训练轮数,模型会在每一千步保存一次

1.运行
Bert-Vits2/train_ms.py
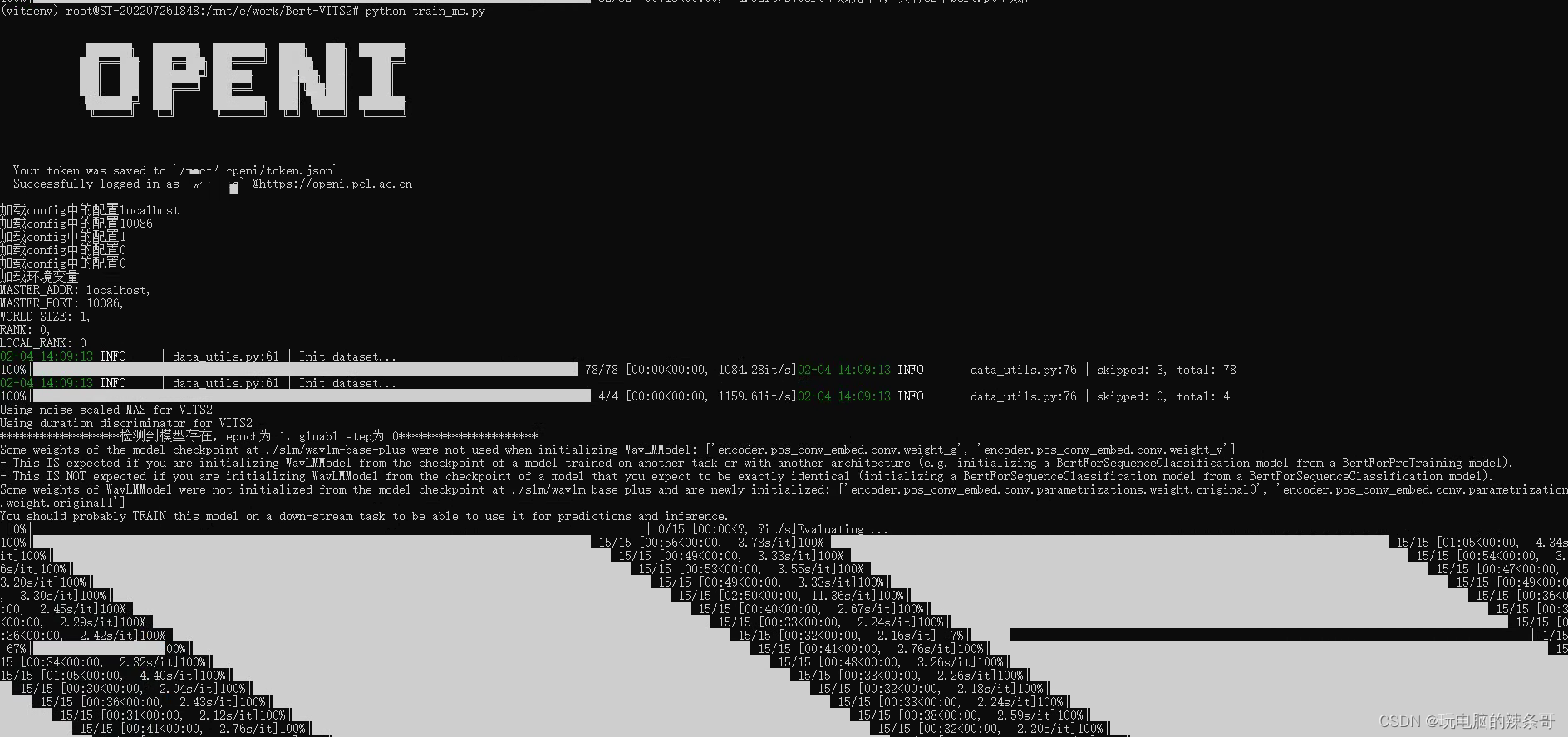
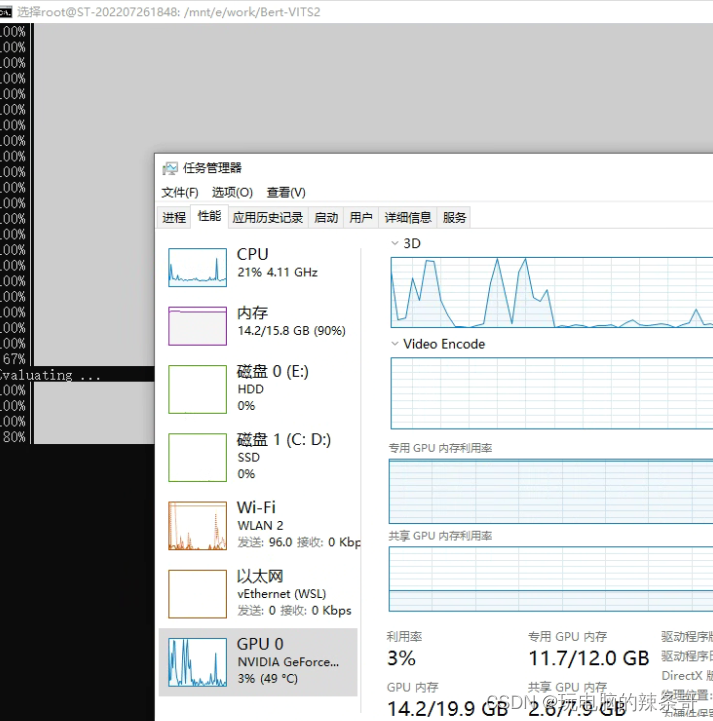
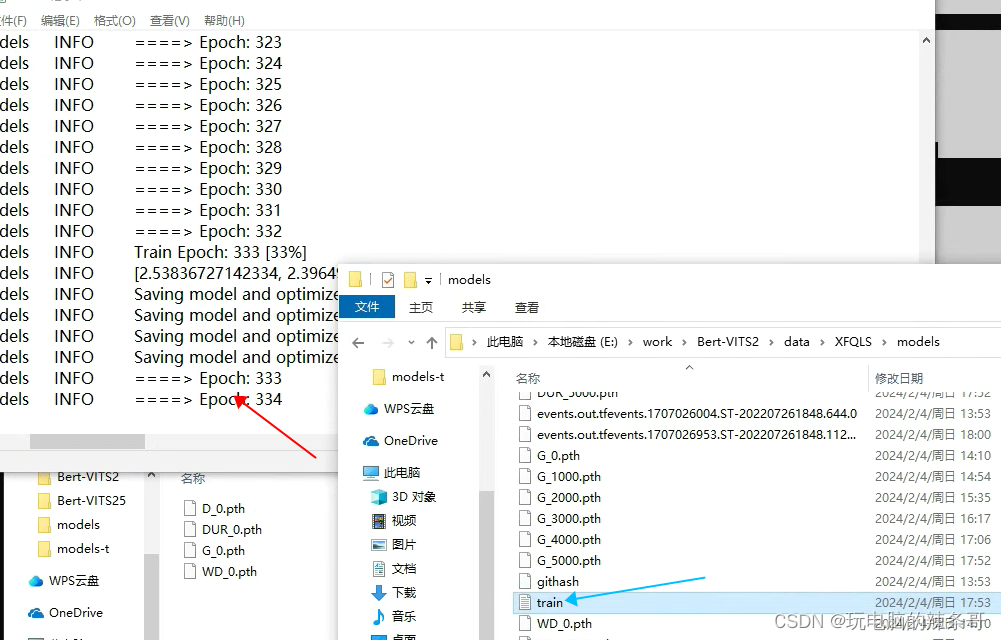
2.查看训练train日志,可以看到训练进度相关信息
四、推理
1.在models文件夹,把最后训练好的文件G开头G_7000.pth,拿来推理,更改config.yml配置文件里面模型路径
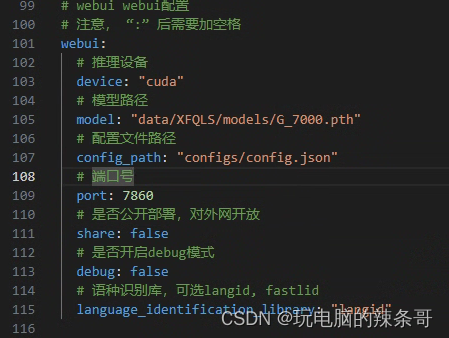
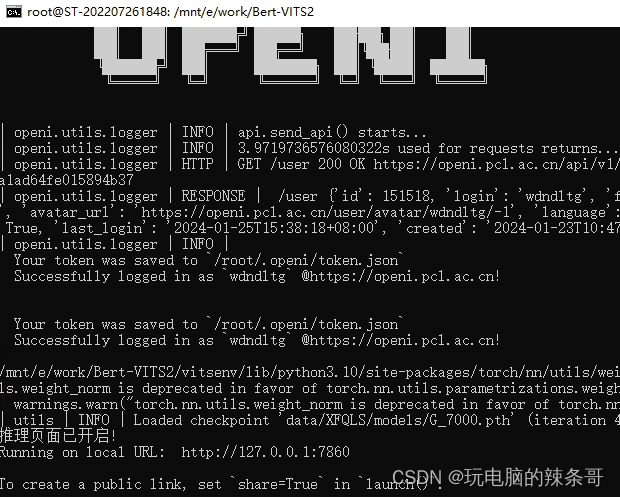
2.启动web服务,打开推理页面
python webui.py
3.开始推理
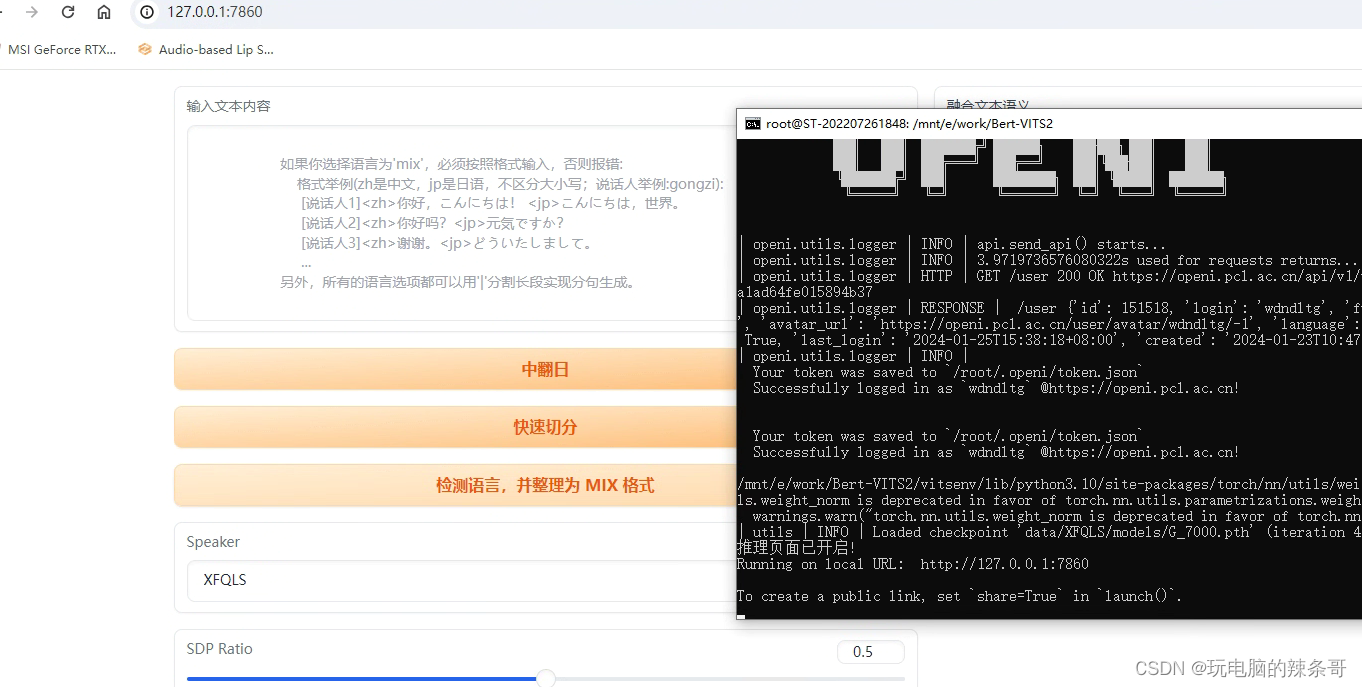
4.推理完成,试听音频文件,如果听起来分辨不出说明效果可以,如果不行还需要继续训练,我这epoch 600轮效果可以了