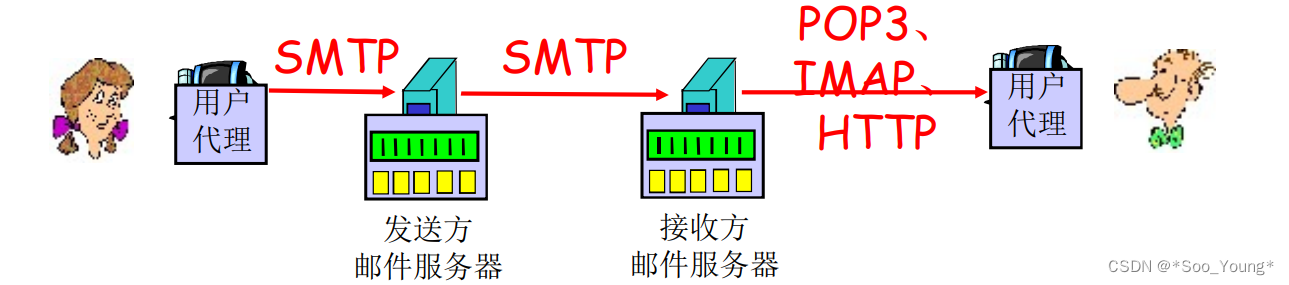
目录
1. 数据训练配置
2. 模型载入
3. 优化器设置
4. DeepSpeed 设置
5. DeepSpeed 初始化
6. 模型训练
LLAMA 模型子结构:

1. 数据训练配置
利用 PyTorch 和 Transformers 库创建数据加载器,它支持单机或多机分布式训练环境下的数据加载与采样。涉及的模块包括:
- DataLoader: 由 PyTorch 提供,用于数据集到模型的数据加载。
- RandomSampler 和 SequentialSampler: PyTorch 提供的随机和顺序数据采样器。
- DistributedSampler: 专为分布式训练设计的采样器。
- default_data_collator: Transformers 库的默认数据整合器,用于批量数据处理。
- create_pretrain_dataset: 创建预训练数据集的自定义函数。
根据 args.local_rank 的值,选择单机采样器或分布式采样器。DistributedSampler 确保每个训练节点获得唯一数据子集,而单机环境下则使用随机或顺序采样器。
2. 模型载入
通过 Transformers 库,加载并配置 LLaMA 模型及其分词器。使用 from_pretrained 方法加载预训练模型、分词器和配置。设置分词器以处理不同文本长度,并设定填充符号为 [PAD],确保填充发生在句子右侧。模型配置中也设置了句子结束和填充符号的 ID,并优化了词汇表嵌入大小以提升硬件性能。
3. 优化器设置
DeepSpeed 库提供了优化的优化器算法,如 DeepSpeedCPUAdam 和 FusedAdam,提高了大规模数据和模型训练速度。优化器设置涉及:
- 参数分组: 通过 get_optimizer_grouped_parameters 函数实现参数分组,一组应用权重衰减,另一组不应用。
- 优化器选择: 根据训练环境选择 DeepSpeedCPUAdam 或 FusedAdam。
- 学习率调度: 动态调整学习率,考虑预热步骤和总训练步数。
4. DeepSpeed 设置
定义全局批次大小 (GLOBAL_BATCH_SIZE) 和每 GPU 微批次大小 (MICRO_BATCH_SIZE)。get_train_ds_config 训练配置函数包括:
- ZeRO 优化: 减少冗余并加速训练。
- 混合精度训练: 通过设置 fp16 字段使用 16 位浮点数。
- 梯度裁剪: 防止梯度爆炸。
- 混合引擎配置: 优化输出分词数量和张量大小。
- TensorBoard 集成: 方便跟踪训练过程。
get_eval_ds_config 函数提供简洁的验证集配置,专注于模型推理。
5. DeepSpeed 初始化
初始化包括:
- 设备确定: 检查本地 GPU 或使用 CUDA。
- 分布式后端初始化: 使用 deepspeed.init_distributed() 同步进程。
- 设置 DeepSpeed 配置: 根据用户参数构建训练设置。
- 同步工作进程: 使用 torch.distributed.barrier() 确保进程同步。
- 初始化: 通过 deepspeed.initialize 优化模型和优化器。
- 梯度检查点: 启用时,使用 model.gradient_checkpointing_enable()。
6. 模型训练
DeepSpeed 框架下的训练步骤:
- 训练前准备: 使用 print_rank_0 函数输出训练状态,避免多进程重复输出。
- 训练循环: 打印周期信息,进行前向传播、梯度计算和参数更新。
- 模型保存: 保存模型状态和配置,支持 Hugging Face 和 DeepSpeed Zero Stage 3 格式。