一、Attention
Attention 的核心逻辑是“从关注全部到关注重点”,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
Attention 机制可以更加好的解决序列长距离依赖问题,并且具有并行计算能力。
Attention 并不需要在 Encoder-Decoder 框架下使用,是可以脱离 Encoder-Decoder 框架的。
- 下面的图片则是脱离 Encoder-Decoder 框架后的原理图解:
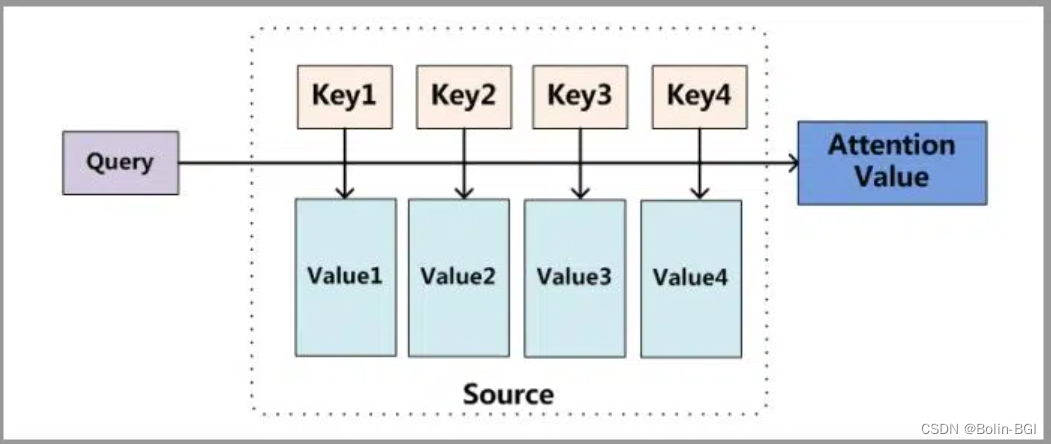
- Attention原理的3步分解:

通过 Query(查询对象) 信息从 Values(被查询对象) 中筛选出重要信息,即:计算 Query 和 Values 中每个信息的相关程度。
Attention 通常可以表示为将 Query(Q) 和 key-value pairs(把 Values 拆分成了键值对的形式)映射到输出上,其中 query、每个 key、每个 value 都是向量,输出是 V(被查询对象)中所有 values 的加权,其中权重是由 Query 和每个 key 计算出来的,计算方法分为三步:
第一步:Query与每一个Key计算相似性得到相似性评分s
第二步:将s评分进行softmax转换成[0,1]之间的概率分布
第三步:将[a1,a2,a3…an]作为权值矩阵对Value进行加权求和得到最后的Attention值
公式如下:

具体步骤如下:

二、Self-Attention
2.1 Attention 和 Self-Attention 的区别
1. Attention:
传统的 Attention 机制发生在 Target的元素 和 Source中的所有元素 之间。在一般任务的 Encoder-Decoder 框架中,输入 Source 和输出 Target 内容是不一样的,比如对于英 - 中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子。
2. Self-Attention
Self-Attention 指的不是 Target 和 Source 之间的 Attention 机制,而是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,其具体计算过程是一样的,只是计算对象发生了变化而已,相当于是 Query=Key=Value,计算过程与attention一样。
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制在文本中的应用,主要通过计算单词间的互相影响,解决长距离依赖问题。
下图是self-attention的一个例子:

如果想知道这句话中的 its 指代的是什么,与哪些单词相关,那么就可以将 its 作为 Query,然后将这句话作为 Key 和 Value 来计算 attention 值,找到与这句话中 its 最相关的单词。通过 self-attention 我们发现 its 在这句话中与之最相关的是 Law 和 application。
总结区别:
1. Self-attention 关键点在于,规定K-Q-V三者都来源于 X。通过 X 找到 X 中的关键点。可以看作 QKV 相等,都是由词向量线性变换得到的,并不是 Q=V=K=X,而是 X 通过 Wk、Wq、Wv 线性变换而来。
2. Attention 是通过一个查询变量 Q 找到 V 里面重要信息,K 由 V 变换而来,QK=A ,AV = Z(注意力值),Z 其实是 V 的另一种表示,也可以称为词向量,具有句法和语意特征的 V。
3. Self-attention 比 attention 约束条件多了两个:Q=K=V同源;Q,K,V需要遵循attention的做法。
2.2 引入自注意力机制的目的
神经网络接收的输入是很多大小不一的向量,并且不同向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。 例如:
机器翻译问题(序列到序列的问题,机器自己决定多少个标签)
词性标注问题(一个向量对应一个标签)
语义分析问题(多个向量对应一个标签)等文字处理问题2.3 Self-Attention 详解

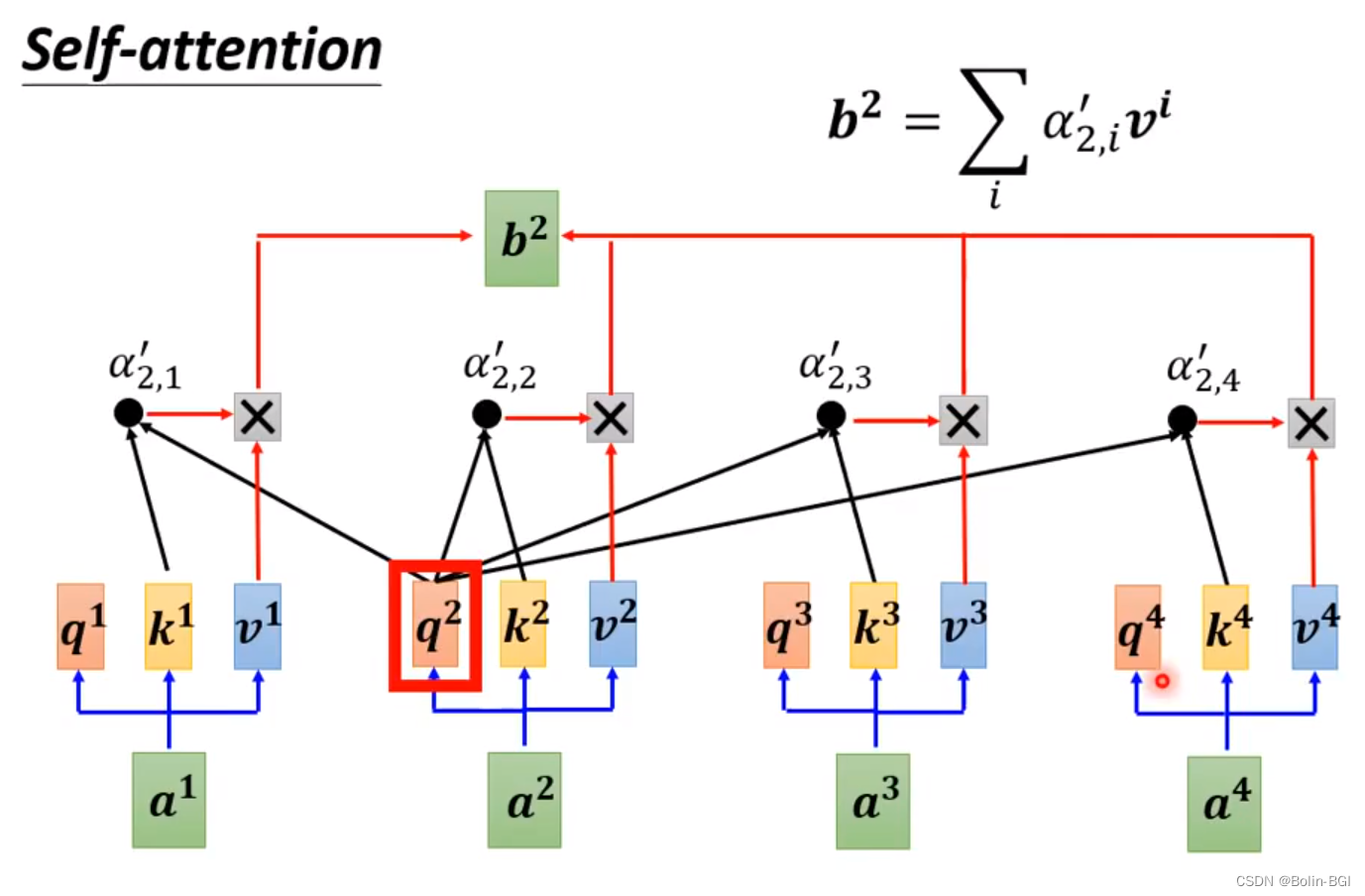
对于每个输入向量a,经过蓝色部分 self-attention 后输出一个向量b,这个向量 b 是考虑了所有的输入向量对 a1 产生的影响才得到的,这里有四个词向量a对应就会输出四个向量b。

上图看起来复杂,实际上是分别在计算 a1 跟 [a1,a2,a3,a4] 的相似度,最后得出 b1 。 a1~a4,可能是 input 也可能是 hidden layer的 output。
a1~a4,属于整个 source 的信息,这一步是在计算整个 source 信息之间的关系。

以 a1 为例,分别点积(Dot-product)两个参数矩阵 Wq 和 Wk,得到q1和k1。(q = query,k = key)
a1,1代表a1与a1的相似度或关连程度;a1,2代表a1与a2的相似度或关连程度;同理a1,3和a1,4。
在得到各向量与a1的相关程度之后,用 softmax 计算出一个attention distribution,这样就把相关程度归一化,通过数值就可以看出哪些向量是和a1最有关系。
V与Q和K同理,V1 = Wv * a1
如果 a1 和 a2 关联性比较高,α1,2就比较大,那么,得到的输出 b1 就可能比较接近 v2 ,即 attention score决定了该 vector 在结果中占的分量;
==矩阵形式解析==

把 4 个输入 a 拼成一个矩阵 I,这个矩阵有4个 column,也就是a1到a4,I 乘上相应的权重矩阵W,得到相应的矩阵Q、K、V,分别表示query,key和value。 三个 W 矩阵 (Wq、 Wk 和 Wv)是我们需要学习的参数。
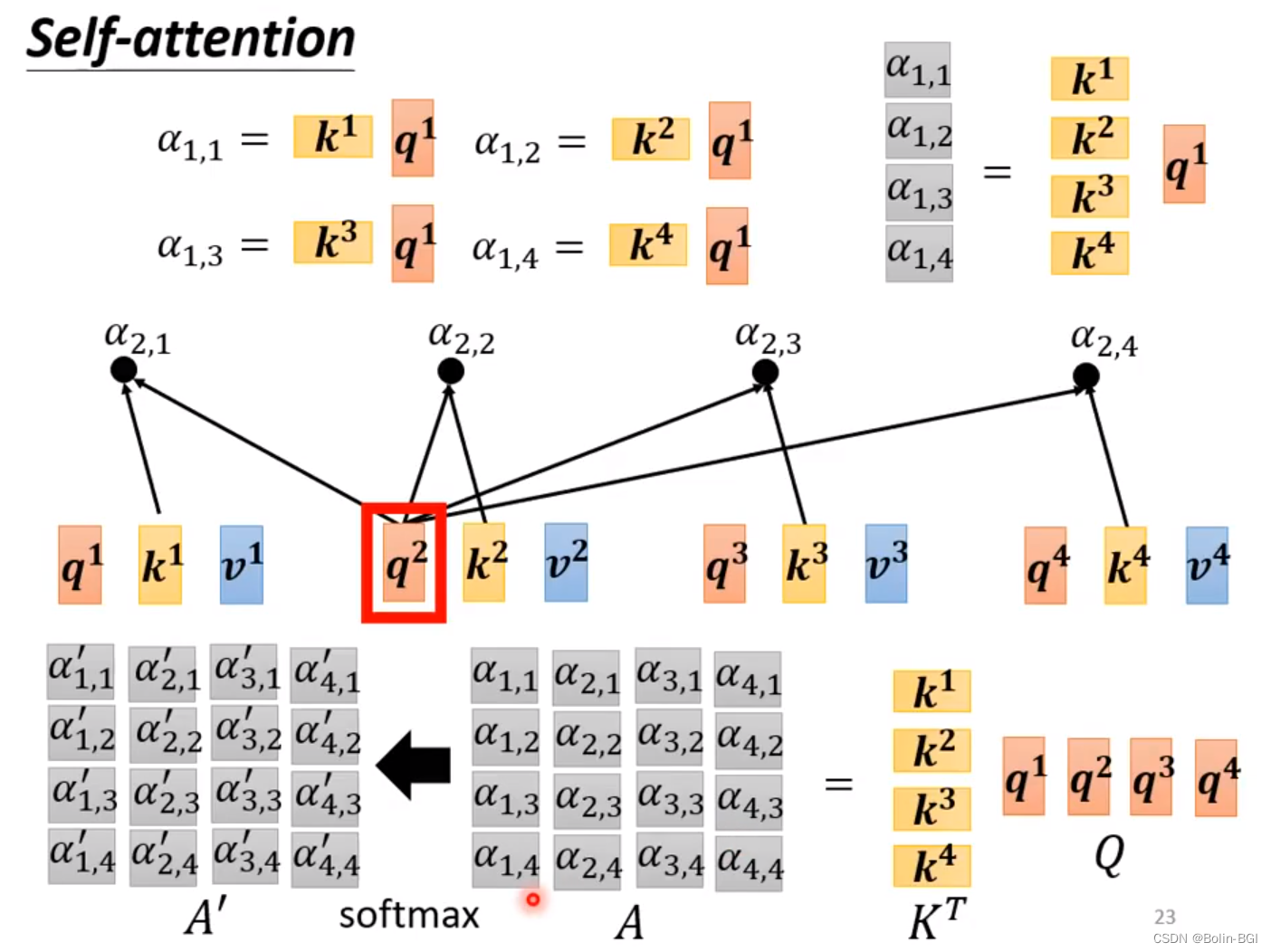
利用得到的 Q 和 K 计算每两个输入向量之间的相关性,也就是计算attention的值α, α的计算方法有多种,通常采用点乘的方式。
矩阵A中的每一个值记录了对应的两个输入向量的Attention的大小α,A' 是经过 softmax 归一化后的矩阵。

利用得到的A' 和V,计算每个输入向量 a 对应的 self-attention 层的输出向量 b

对self-attention操作过程做个总结,输入是I,输出是O
三、Multi-head Self-attention
Self-attention 的进阶版本 Multi-head Self-attention,多头自注意力机制。
因为相关性有很多种不同的形式,有很多种不同的定义,所以有时不能只有一个q,要有多个q,不同的q负责不同种类的相关性。就像语言信息里,语法句意特征非常复杂,仅仅一层 QKV 是不足以处理复杂任务的。

上面这个图中,有两个head,代表这个问题有两种不同的相关性。
同样,k 和 v 也需要有多个,两个k、v的计算方式和q相同,都是先算出来ki和vi,然后再乘两个不同的权重矩阵。
计算出来q、k、v之后的 self-attention 和上面的过程一样,只不过是1类的一起做,2类的一起做,两个独立的过程,算出来两个b(bi1,bi2)。
最后,把 bi1 和 bi2 拼接成矩阵再乘权重矩阵 W,得到bi,也就是这个self- attention向量 ai 的输出,如下图所示:

四、Positional Encoding
在训练 self attention 的时候,实际上对于位置的信息是缺失的,没有前后的区别,上面讲的 a1,a2,a3 不代表输入的顺序,只是指输入的向量数量,不像 RNN,对于输入有明显的前后顺序。 Self-attention 是同时输入,同时输出。
为了解决 Attention 丢失的序列顺序信息,Transformer 的提出者提出了 Position Embedding,也就是对于输入 X 进行 Attention 计算之前,在 X 的词向量中加上位置信息,也就是说 X的词向量为: X~final_embedding = Embedding + Positional Embedding

换一种表示方式:

五、Self-Attention的拓展
5.1 Self-attention vs RNN

引入Self Attention后更容易捕获句子中长距离的相互依赖的特征。
RNN 或者 LSTM,需要按顺序进行序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
Self - Attention 在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
此外,Self Attention 对于增加计算的并行性也有直接帮助作用。正好弥补了attention机制的两个缺点,这就是为何Self - Attention逐渐被广泛使用的主要原因。
5.2 Self-attention vs CNN

Self-Attention 其实可以看作一种基于全局信息的 CNN。
传统 CNN 的卷积核是认为规定的,只能提取卷积核内的信息进行图像特征提取,但 Self-Attention 关注 source 内部特征信息,可以从全局角度出发,去 “学习” 出最合适的一个“卷积核”,最大化的提取图像特征信息。
在数据量小的情况下,Self-Attention 的训练效果差,不如 CNN ;
在数据量大的情况下,Self-Attention 的训练效果好,胜过 CNN ;


5.3 Self-attention 的优点
参数少:相比于 CNN、RNN ,其参数更少,复杂度更小。所以对算力的要求也就更小。
速度快:Attention 解决了 RNN及其变体模型 不能并行计算的问题。Attention 机制每一步计算不依赖于上一步的计算结果,因此可以和 CNN 一样并行处理。
效果好:在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
六、Masked Self-attention
Mask是为了解决训练阶段和测试阶段的 gap(不匹配)问题。

Mask 就是沿着对角线把灰色的区域用 0 覆盖掉,不给模型看到未来的信息,如图所示,并且在做完 softmax 之后,横轴结果合为 1。
举例1:机器翻译: 源语句(我爱中国),目标语句(I love China)
训练阶段:解码器会有输入,这个输入是目标语句,就是 I love China,通过已经生成的词,去让解码器更好的生成(每一次都会把所有信息告诉解码器)
work阶段:解码器也会有输入,但是此时,测试的时候是不知道目标语句是什么的,这个时候,你每生成一个词,就会有多一个词放入目标语句中,每次生成的时候,都是已经生成的词(测试阶段只会把已经生成的词告诉解码器) 为了匹配,为了解决这个 gap,masked Self-Attention 就登场了,我在训练阶段,我就做一个 masked,当你生成第一个词,我啥也不告诉你,当你生成第二个词,我告诉第一个词。
 输出的答案和正确答案的交叉熵越小越好。
输出的答案和正确答案的交叉熵越小越好。
训练的时候有正确答案,work的时候没有正确答案。测试的时 Decoder 接收的是自己的输出,可能有错误的;训练时,Decoder接收的是完全正确的; 测试和训练不一致的现象叫 "exposure bias"。
假设 Decoder 在训练时看到的都是正确的信息,那在测试时 它如果收到了错误的信息,它会一步错步步错,放大错误。
所以在训练的时候,给 Decoder 一些错误的信息,反倒会提升模型精确度。




![[C# WPF] DataGrid选中行或选中单元格的背景和字体颜色修改](https://img-blog.csdnimg.cn/direct/d0c8baa916914d49b8b986a9e39bf959.png)