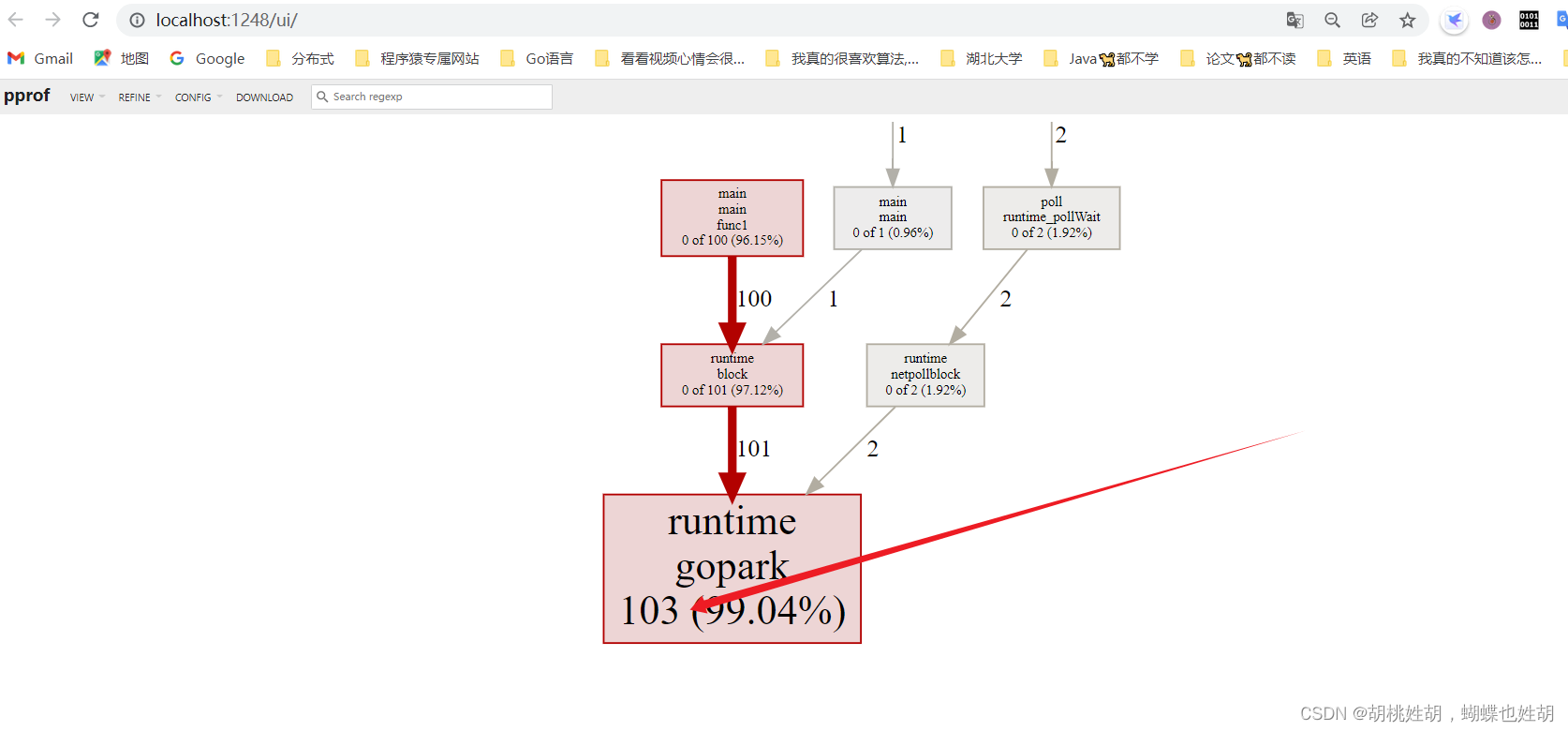
Framework of ML
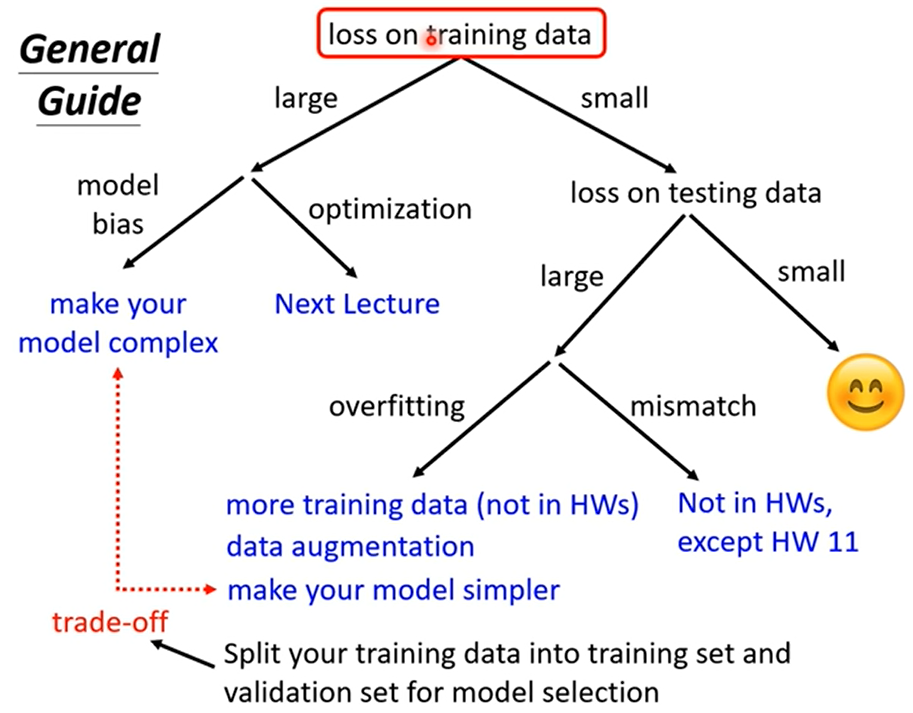
- Loss on training data
- 1. large
- 1.1 Model Bias
- 1.2 Optimization
- 2. small
- Loss on testing data
- 2.1 large
- 2.1.1 overfitting
- 2.1.2 mismatch
- 2.2 small
通关手册:祝我通关成功!!!
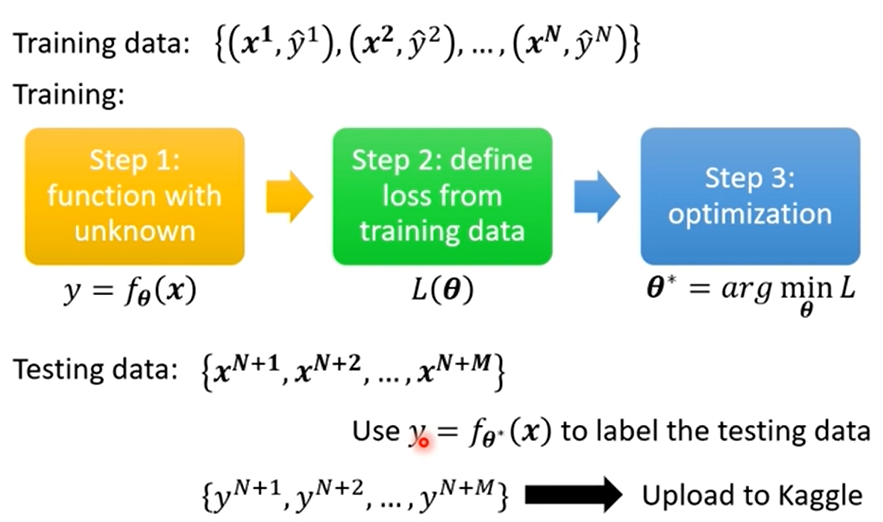
Loss on training data
1. large
1.1 Model Bias

1.2 Optimization
优化做的不好,比如gradient descent这种方法有local minima的问题
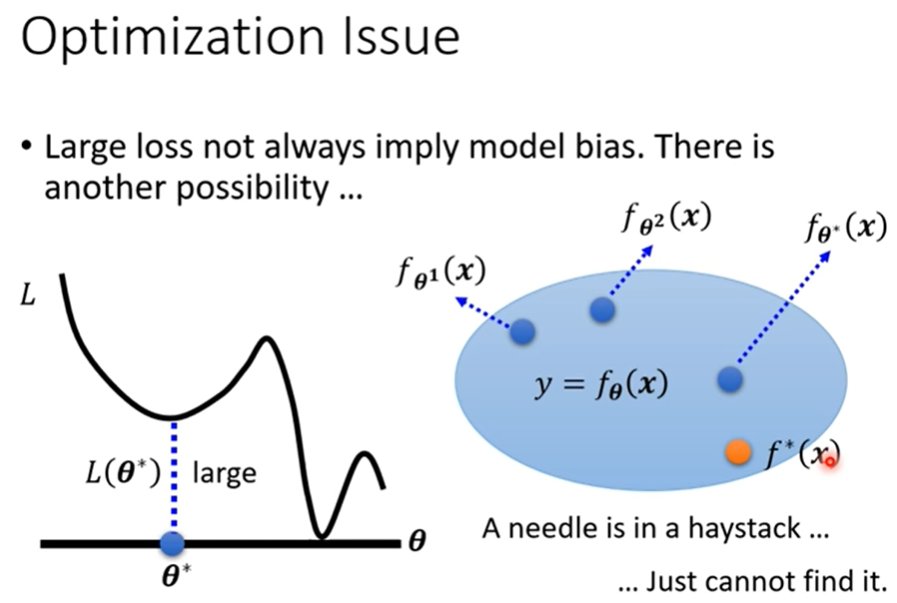
那究竟是哪个问题呢?
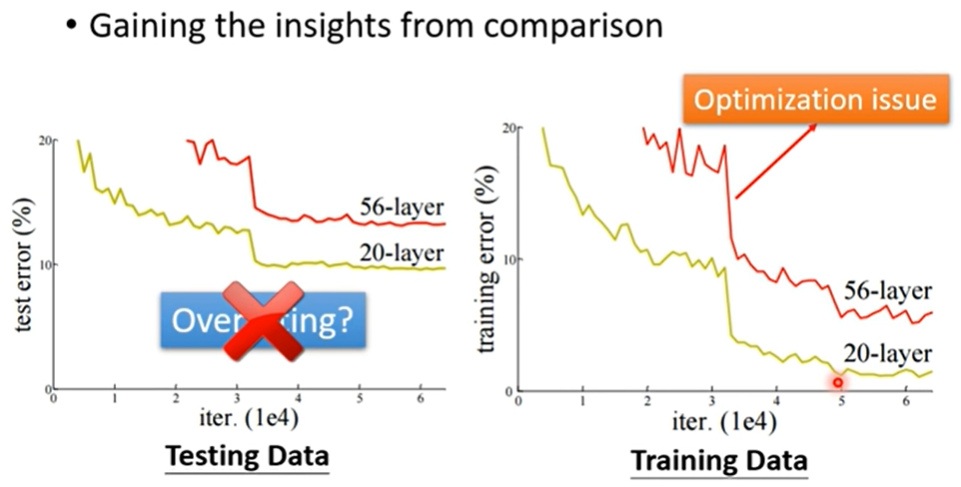
- 显然56层的弹性更大,后36层copy identity可以轻而易举的做到,所以不是model bias的问题
怎样知道你的optimazation做的够不够好呢?

- 甚至是linear model或者support vector model

2. small
Loss on testing data
2.1 large
2.1.1 overfitting
training data的loss小,testing data的loss大,才叫做overfitting
为什么会出现这样的状况呢?

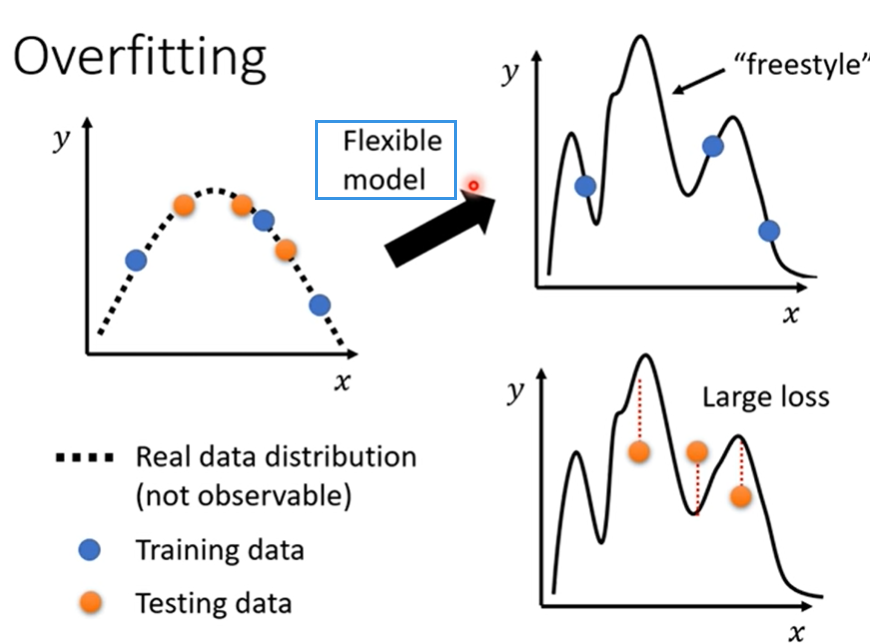
解决方案:
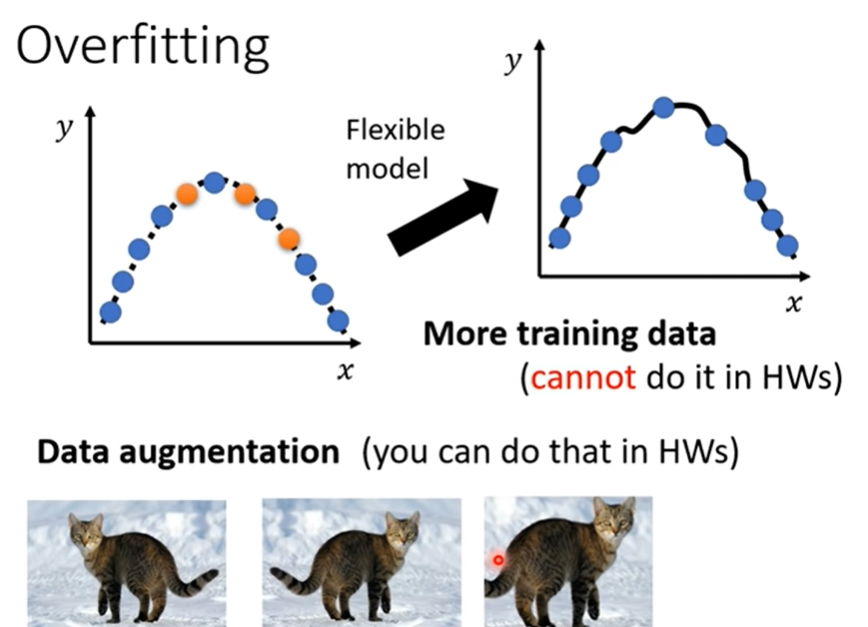
- 合理的augmentation
- 减弱flexible
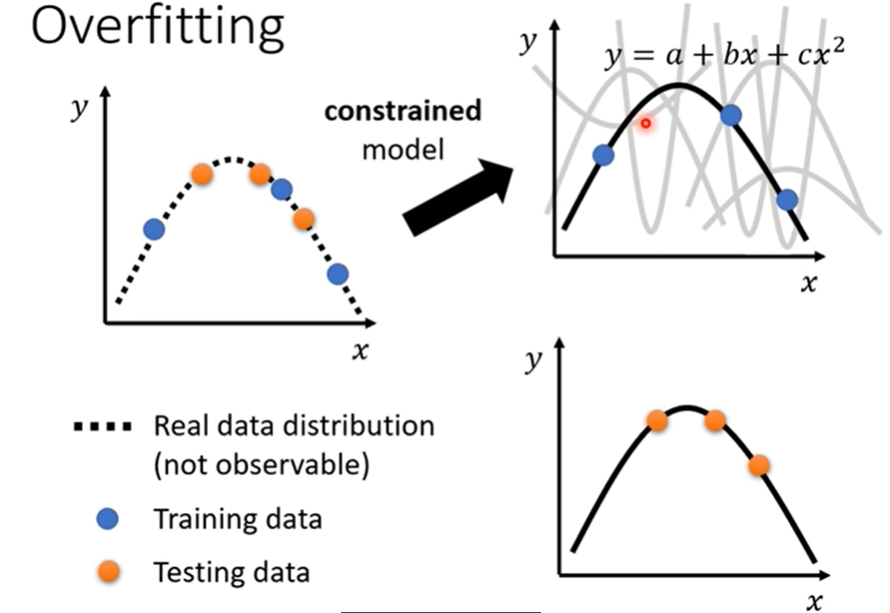
如何制造限制?

-
CNN:比较没有弹性的model,根据影像的特性来限制模型的弹性。

但是限制也不要太多
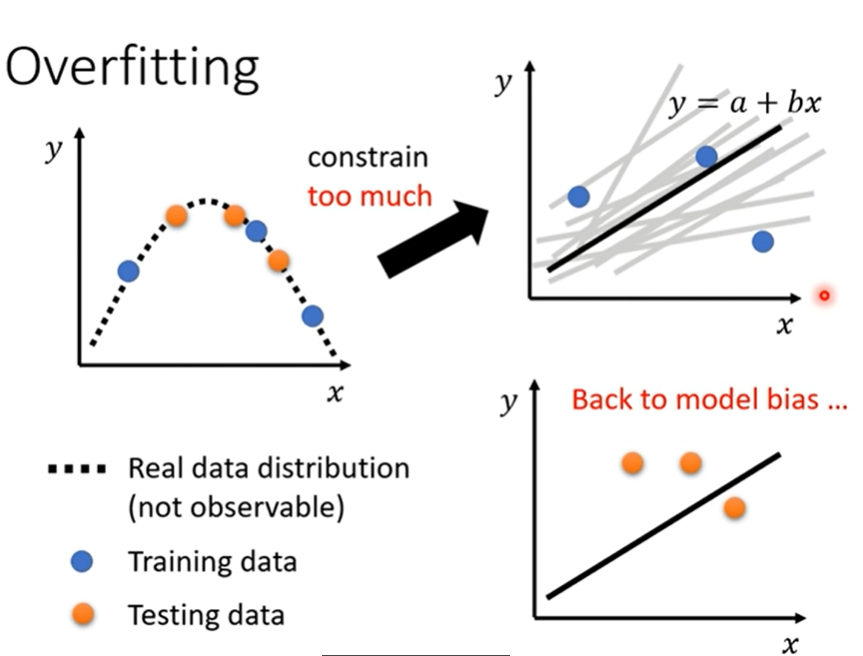
这显得有些矛盾。。
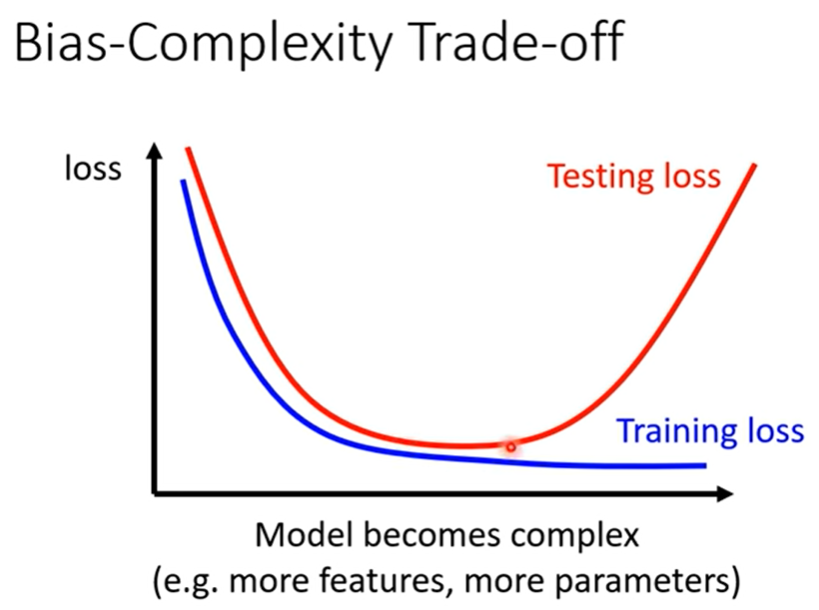
model bias → overfitting
那是不是可以选择一个中庸的Model呢?
如果你直接从public testing set 中选出一个最优秀的就万事大吉了呢~
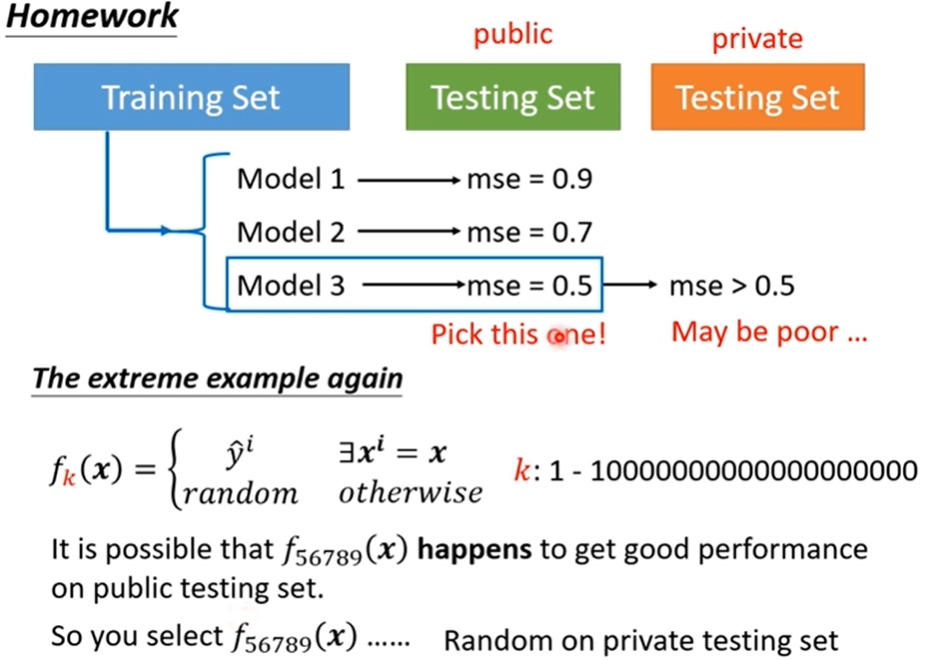
This explains why machine usually beats human on benchmark corpora.
这就是为什么我们要把 testing set 分开呀~
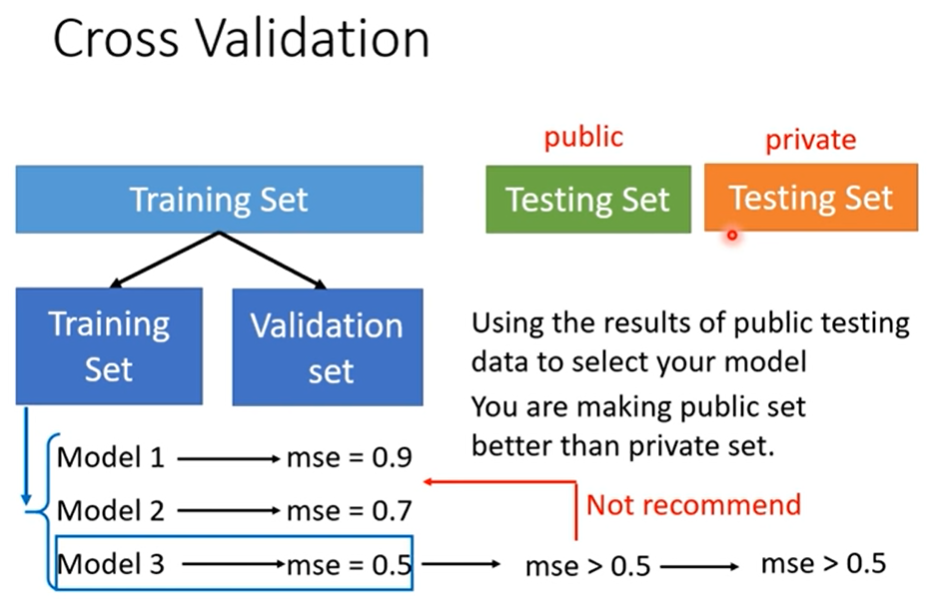
实操直接取validation最小的就好啦。
how to split training set?
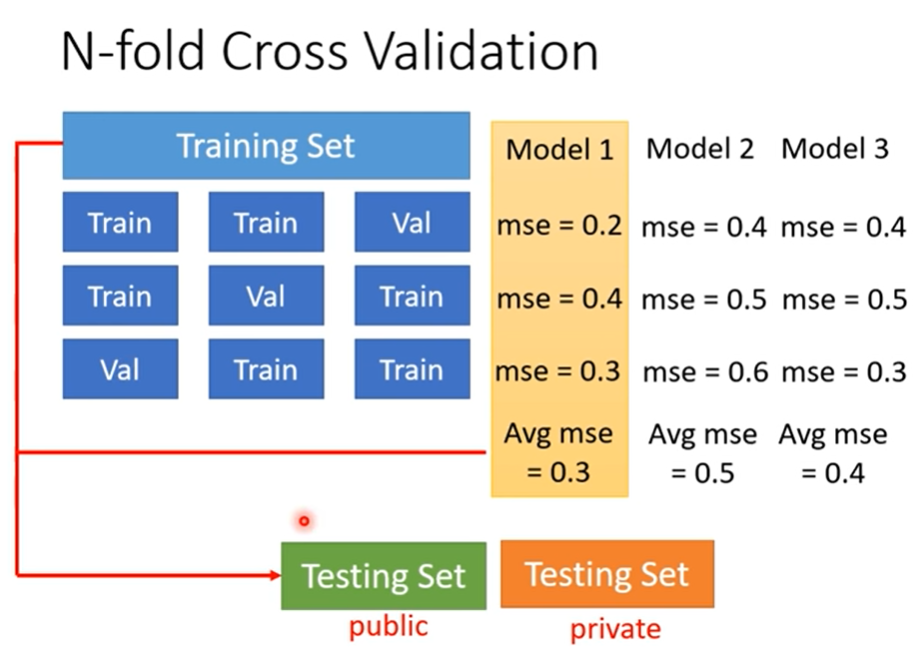
2.1.2 mismatch
哈哈哈好可爱呀!!!
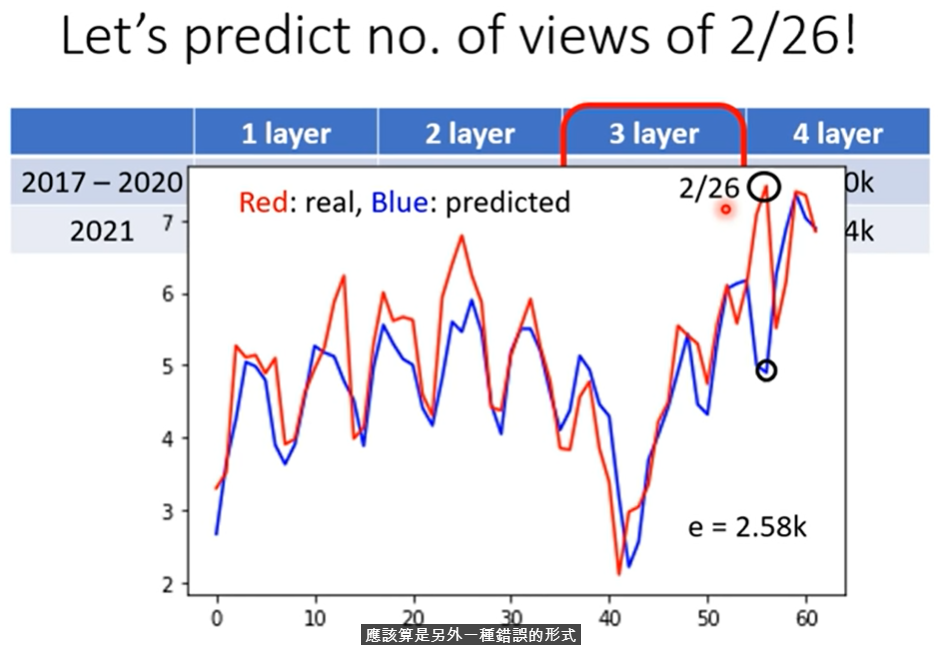
有人说它也是一种overfitting,但其实mismacth和overfitting的原因其实不同,overfitt可以用更多的训练资料来解决,但是mismatch ——

如何判断是不是dismatch,需要你对训练资料和测试资料的产生有
2.2 small
😃