Goroutine是GMP模型中的G,是属于用户态的线程,由Go runtime管理,而不是操作系统管理。
数据结构
type g struct {
goid int64 // 唯一的goroutine的ID
sched gobuf // goroutine切换时,用于保存g的上下文
stack stack // 栈
gopc // pc of go statement that created this goroutine
startpc uintptr // pc of goroutine function
...
}
type gobuf struct {
sp uintptr // 栈指针位置
pc uintptr // 运行到的程序位置
g guintptr // 指向 goroutine
ret uintptr // 保存系统调用的返回值
...
}
type stack struct {
lo uintptr // 栈的下界内存地址
hi uintptr // 栈的上界内存地址
}
最终有一个 runtime.g 对象放入调度队列
Goroutine状态
| 状态 | 含义 |
|---|---|
| 空闲中_Gidle | G刚刚新建,没有初始化 |
| 待运行_Grunnable | 就绪状态,G在运行队列中,等待M取出并运行 |
| 运行中_Grunning | M正在运行这个G,这时候M会拥有一个P |
| 系统调用中_Gsyscall | M正在运行这个G发起的系统调用,这时候M并不拥有P |
| 等待中_Gwaiting | G在等待某些条件完成,这时候G不在运行也不在运行队列中(可能在channel的等待队列中) |
| 已中止_Gdead | G未被使用,可能已经执行完毕 |
| 栈复制中_Gcopystack | G正在获取一个新的栈空间并把原来的内容复制过去(用于防止GC扫描) |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wlBjgZpx-1672994559533)(https://image-1302243118.cos.ap-beijing.myqcloud.com/imgcdn/5.2.goroutine_state.jpg)]
创建
通过go关键字调用runtime.newproc()创建一个Goroutine。当调用该函数之后,Goroutine会被设置成runnable状态。
func main() {
go func() {
fmt.Println("func routine")
}()
fmt.Println("main goroutine")
}
创建好的这个Goroutine会新建一个自己的栈空间,同时在G的sched中维护栈地址和程序计数器这些信息。
每个 G 在被创建之后,都会被优先放入到本地队列中,如果本地队列已经满了,就会被放入到全局队列中。
运行
goroutine 本身只是一个数据结构,真正让 goroutine 运行起来的是调度器。Go 实现了一个用户态的调度器(GMP模型),这个调度器充分利用现代计算机的多核特性,同时让多个 goroutine 运行,同时 goroutine 设计的很轻量级,调度和上下文切换的代价都比较小。
调度时机
- 新起一个协程和协程执行完毕
- 会阻塞的系统调用,比如文件io、网络io
- channel、mutex等阻塞操作
- time.sleep
- 垃圾回收之后
- 主动调用runtime.Gosched()
- 运行过久或系统调用过久等等
每个 M 开始执行 P 的本地队列中的 G时,goroutine会被设置成running状态
如果某个 M 把本地队列中的G都执行完成之后,然后就会去全局队列中拿 G,这里需要注意,每次去全局队列拿 G 的时候,都需要上锁,避免同样的任务被多次拿。
如果全局队列都被拿完了,而当前 M 也没有更多的 G 可以执行的时候,它就会去其他 P 的本地队列中拿任务,这个机制被称之为 work stealing 机制,每次会拿走一半的任务,向下取整,比如另一个 P 中有 3 个任务,那一半就是一个任务。
当全局队列为空,M 也没办法从其他的 P 中拿任务的时候,就会让自身进入自旋状态,等待有新的 G 进来。最多只会有 GOMAXPROCS 个 M 在自旋状态,过多 M 的自旋会浪费 CPU 资源。
阻塞
channel的读写操作、等待锁、等待网络数据、系统调用等都有可能发生阻塞,会调用底层函数runtime.gopark(),会让出CPU时间片,让调度器安排其它等待的任务运行,并在下次某个时候从该位置恢复执行。
当调用该函数之后,goroutine会被设置成waiting状态
唤醒
处于waiting状态的goroutine,在调用runtime.goready()函数之后会被唤醒,唤醒的goroutine会被重新放到M对应的上下文P对应的runqueue中,等待被调度。
当调用该函数之后,goroutine会被设置成runnable状态
退出
当goroutine执行完成后,会调用底层函数runtime.Goexit()
当调用该函数之后,goroutine会被设置成dead状态
Goroutine和线程的区别
| Goroutine | 线程 | |
|---|---|---|
| 内存占用 | 创建一个Goroutine的栈内存消耗为2kb,实际运行过程中,如果栈空间不够用会自动进行扩容。 | 消耗的栈空间大概要1MB |
| 创建和销毁 | 用户级的,由Go runtime负责,创建和销毁代价非常小 | 创建和销毁代价很大,内核级别,常用解决方法是线程池 |
| 切换 | Goroutine切换只需要3哥寄存器PC,SP,BP。goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。 | 当线程切换时,需要保存各种寄存器,以便恢复现场。线程切换会消耗 1000-1500 ns,相当于 12000-18000 条指令。 |
Goroutine泄漏
泄漏原因
- Goroutine 内进行channel/mutex 等读写操作被一直阻塞。
- Goroutine 内的业务逻辑进入死循环,资源一直无法释放。
- Goroutine 内的业务逻辑进入长时间等待,有不断新增的 Goroutine 进入等待
泄漏场景
如果输出的 goroutines 数量是在不断增加的,就说明存在泄漏
nil channel
channel 如果忘记初始化,那么无论你是读,还是写操作,都会造成阻塞。
func main() {
fmt.Println("before goroutines: ", runtime.NumGoroutine())
block1()
time.Sleep(time.Second * 1)
fmt.Println("after goroutines: ", runtime.NumGoroutine())
}
func block1() {
var ch chan int
for i := 0; i < 10; i++ {
go func() {
<-ch
}()
}
}
输出结果:
before goroutines: 1
after goroutines: 11
发送不接收
channel 发送数量 超过 channel接收数量,就会造成阻塞
func block2() {
ch := make(chan int)
for i := 0; i < 10; i++ {
go func() {
ch <- 1
}()
}
}
接收不发送
channel 接收数量 超过 channel发送数量,也会造成阻塞
func block3() {
ch := make(chan int)
for i := 0; i < 10; i++ {
go func() {
<-ch
}()
}
}
http request body未关闭
resp.Body.Close() 未被调用时,goroutine不会退出
func requestWithNoClose() {
_, err := http.Get("https://www.baidu.com")
if err != nil {
fmt.Println("error occurred while fetching page, error: %s", err.Error())
}
}
func requestWithClose() {
resp, err := http.Get("https://www.baidu.com")
if err != nil {
fmt.Println("error occurred while fetching page, error: %s", err.Error())
return
}
defer resp.Body.Close()
}
func block4() {
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
requestWithNoClose()
}()
}
}
var wg = sync.WaitGroup{}
func main() {
block4()
wg.Wait()
}
一般发起http请求时,需要确保关闭body
defer resp.Body.Close()
互斥锁忘记解锁
第一个协程获取 sync.Mutex 加锁了,但是他可能在处理业务逻辑,又或是忘记 Unlock 了。
因此导致后面的协程想加锁,却因锁未释放被阻塞了
func block5() {
var mutex sync.Mutex
for i := 0; i < 10; i++ {
go func() {
mutex.Lock()
}()
}
}
sync.WaitGroup使用不当
由于 wg.Add 的数量与 wg.Done 数量并不匹配,因此在调用 wg.Wait 方法后一直阻塞等待
func block6() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
go func() {
wg.Add(2)
wg.Done()
wg.Wait()
}()
}
}
如何排查
单个函数:调用 runtime.NumGoroutine 方法来打印 执行代码前后Goroutine 的运行数量,进行前后比较,就能知道有没有泄露了。
生产/测试环境:使用PProf实时监测Goroutine的数量
import (
"net/http"
// 注意,我们需要导入这个包
_ "net/http/pprof"
)
func main() {
for i := 0; i < 100; i++ {
go func() {
select {}
}()
}
go func() {
http.ListenAndServe("localhost:8080", nil)
}()
select {}
}
然后启动程序,启动程序之后输入:
go tool pprof -http=:1248 http://127.0.0.1:8080/debug/pprof/goroutine
注意这个端口号要和你监听的一致,并且要安装graphviz,把bin目录加入到Path环境变量中。
会自动打开你默认游览器。
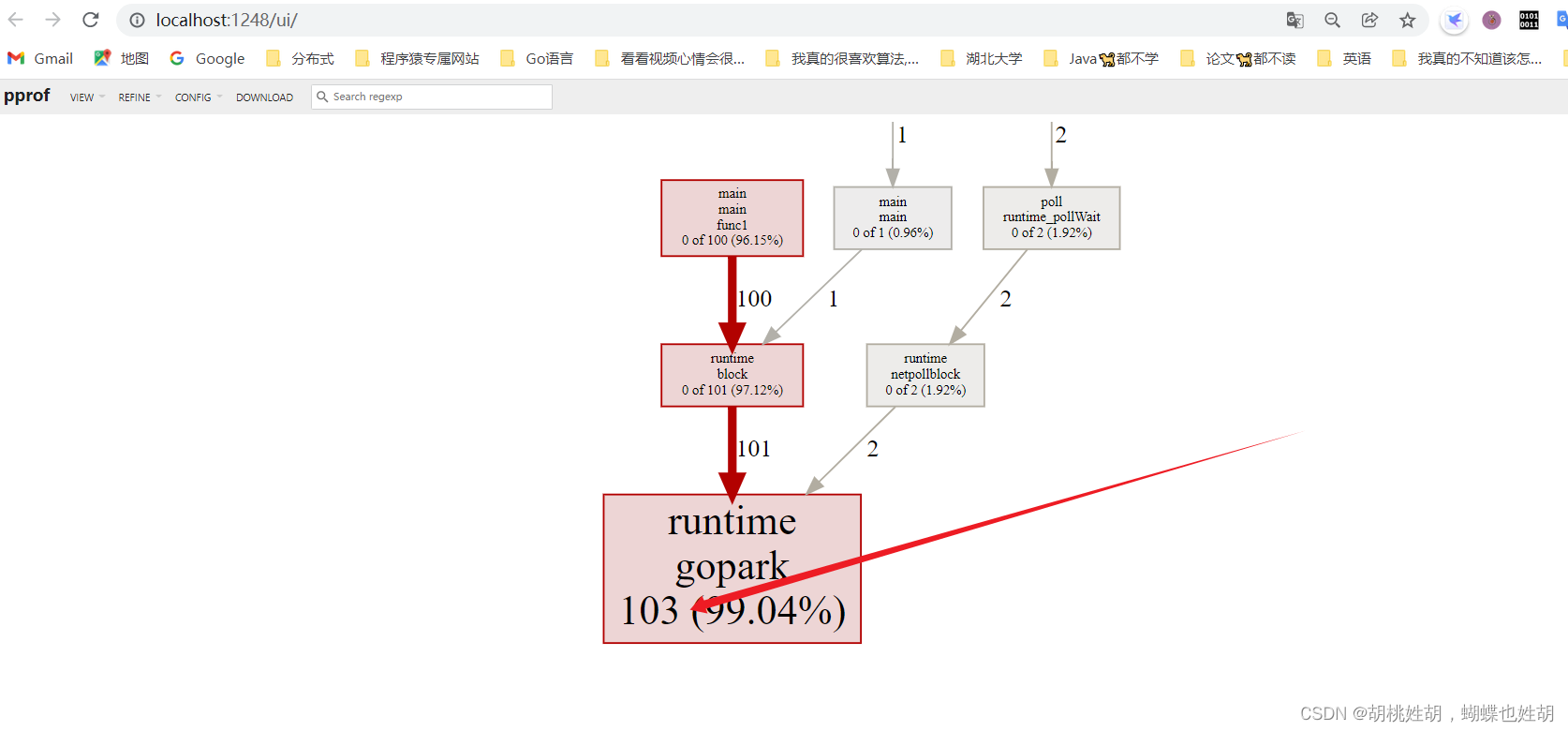
可以看到有103个Goroutine在运行。
如何控制并发的Goroutine数量?
在开发过程中,如果不对goroutine加以控制而进行滥用的话,可能会导致服务整体崩溃。比如耗尽系统资源导致程序崩溃,或者CPU使用率过高导致系统忙不过来
有缓存channel
利用缓冲满时发送阻塞的特性。
var wg = sync.WaitGroup{}
func main() {
// 模拟用户请求数量
requestCount := 10
fmt.Println("goroutine_num", runtime.NumGoroutine())
// 管道长度就是最大并发数
ch := make(chan bool, 3)
for i := 0; i < requestCount; i++ {
wg.Add(1)
ch <- true
go Read(ch, i)
}
wg.Wait()
}
func Read(ch chan bool, i int) {
fmt.Printf("goroutine_num: %d, go func: %d\n", runtime.NumGoroutine(), i)
<-ch
wg.Done()
}
运行结果如下:
goroutine_num 1
goroutine_num: 4, go func: 2
goroutine_num: 4, go func: 3
goroutine_num: 4, go func: 4
goroutine_num: 4, go func: 5
goroutine_num: 4, go func: 6
goroutine_num: 4, go func: 7
goroutine_num: 4, go func: 8
goroutine_num: 4, go func: 0
goroutine_num: 4, go func: 1
goroutine_num: 4, go func: 9
无缓冲channel
任务发送和执行分离,指定消费者并发协程数
var wg = sync.WaitGroup{}
func main() {
// 模拟用户请求数量
requestCount := 10
fmt.Println("goroutine_num", runtime.NumGoroutine())
ch := make(chan bool)
for i := 0; i < 3; i++ {
go Read(ch, i)
}
for i := 0; i < requestCount; i++ {
wg.Add(1)
ch <- true
}
wg.Wait()
}
func Read(ch chan bool, i int) {
for _ = range ch {
fmt.Printf("goroutine_num: %d, go func: %d\n", runtime.NumGoroutine(), i)
wg.Done()
}
}
说实话这样做效率太过底下了,因为用了阻塞等待,生产环境基本上不可能这么去操作的