Checkpoint
使用了 Chandy-Lamport 算法
流程
1. 正常流式处理(尚未Checkpoint)
如下图,Topic 有两个分区,并行度也为 2,根据奇偶数
我们假设任务从 Kafka 的某个 Topic 中读取数据,该Topic 有 2 个 Partition,故任务的并行度为 2。根据读取到数据(下面的数据是 offset 的值,同时我们把它直接当成数据)的奇偶性,将数据分发到两个 task 进行 Sum
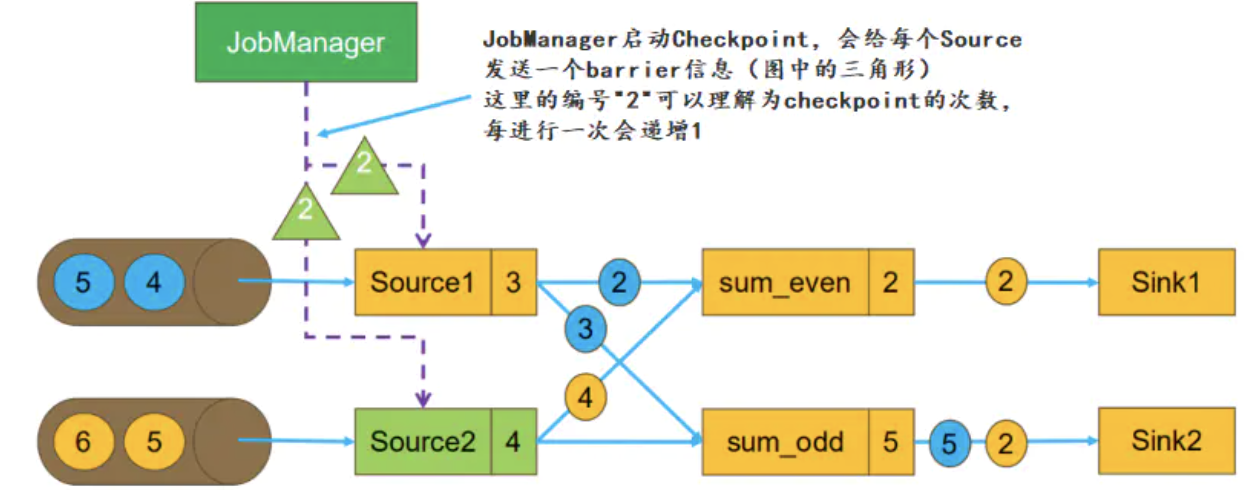
Source1 记录消费到了第 3 条数据,Source2 记录消费到了第 4 条数据并将其发送
同时还有 Source1 正在发送的 2 和 3,Source2 在发送的 4
已经处理的有 Source1 的 1 和 Source2 的 1、2、3,当前SourceOperator ( Sum) 算子已经sum的结果是 2 和 1+1+3=5

2. Flink 任务触发 Checkpoint
到了 Checkpoint 的设置的时间间隔,jobmanager 触发 checkpoint 操作
此时会给每个 Source 发送一个 barrier 消息,消息中的数值表示 Checkpoint 的序号,每次启动新的 Checkpoint 该值都会递增
2.2.3 Source启动Checkpoint
当Source接收到barrier消息,会将当前的状态(Partition、Offset)保存到 StateBackend,然后向 JobManager 报告Checkpoint 完成。之后Source会将barrier消息广播给下游的每一个 task:

2.2.4 task 接收 barrier,barrier 对数据的截断
当task接收到某个上游(如这里的Source1)发送来的 barrier,会将该上游barrier之前的数据继续进行处理,而barrier之后发送来的消息不会进行处理,会被缓存起来。
也就是说:
以 barrier 为节点对 barrier 前后的数据分开,barrier 之前的数据属于本次 Checkpoint,barrier 之后的数据属于下一次 Checkpoint,所以下次 Checkpoint 的数据是不应该在本次 Checkpoint 过程中被计算的,因此会将数据进行缓存
不同 Source 的barrier 发送时消费到的 offset 是不一样的,barrier 只是区分当前某个时刻已经消费的数据和 barrier 后才来的数据,不会去管你的 offset
2.2.5 barrier对齐
但是除了 Operator chains 这种一对一,还可能 reblance 算子(也就是某个 task 有多个上游输入的情况)
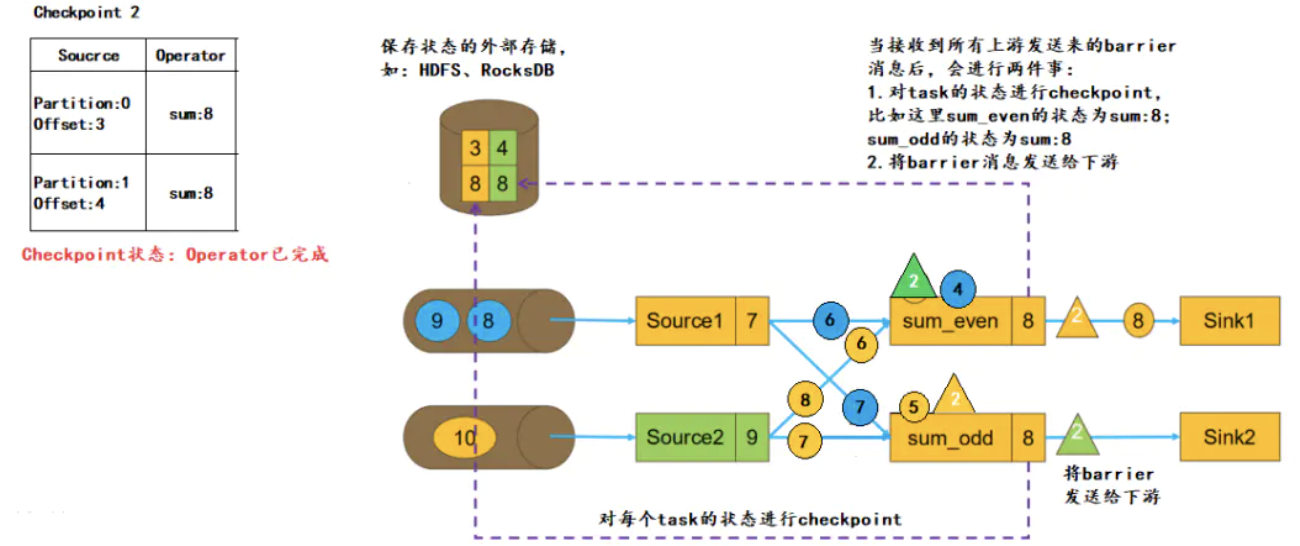
sum_even 有两个 Source 源,当接收到其中一个 Source 的barrier后,会等待其他 Source 的 barrier 到来
在此期间,接收到 barrier 的 Source 发来的数据不会处理,只会缓存,而未接收到 barrier 的 Source 发来的数据依然会进行处理,直到接收到该Source 发来的 barrier,这个过程称为 barrier的对齐
barrier 对齐主要是为了避免 Checkpoint 时有 barrier 后的数据,而 barrier 是否对齐决定了程序实现的是 Exactly Once 还是 At Least Once
- 如果是一对一的Operator,如map、flatMap 或 filter 等,则没有对齐这个概念,都会实现Exactly Once语义
- 如果是多对一的Operator(如 join)或者一对多的Operator(如 reparation/shuffle)时,可以通过配置Exactly Once语义时,必须进行barrier的对齐,而配置了 At Least Once语义时 barrier 可以不对齐
如果不进行barrier对齐,那么这里 sum_even 在接收 Source2 的 barrier 之前,对于接收到 Source1的数据4,不会进行缓存,而是直接进行计算,sum_even 的状态改为12,当接收到 Source2 的barrier,会将 sum_even 的状态 sum=12 进行持久化。如果本次Checkpoint成功,在进行下次 Checkpoint 前任务崩溃,会根据本次Checkpoint进行恢复。此时状态如下:
Source1的 offset 为3,从数据4开始读。
Source2 的 offset 为4,从数据5开始读。
sum_even 的状态为 12(Souce1的数据2,数据4;Source2的数据2,数据4),后续接收Source1的数据4,数据6...;接收Source2的数据6,数据8...
Source1的数据4被计算了两次
2.2.6 处理缓存数据
task接收到所有上游发送来的 barrier,也就代表收到了本次 Checkpoint 的所有数据
但是我们还有 barrier 后的属于下一次 Checkpoint 的,被缓存起来但没有处理的数据,task 会将 barrier 继续发送给下游(如下图 sum 以后的 sink),然后处理缓存的数据

2.2.7 上报Checkpoint完成
当sink收到barrier后,会向JobManager上报本次Checkpoint完成。至此,本次Checkpoint结束,各阶段的状态均进行了持久化,可以用于后续的故障恢复
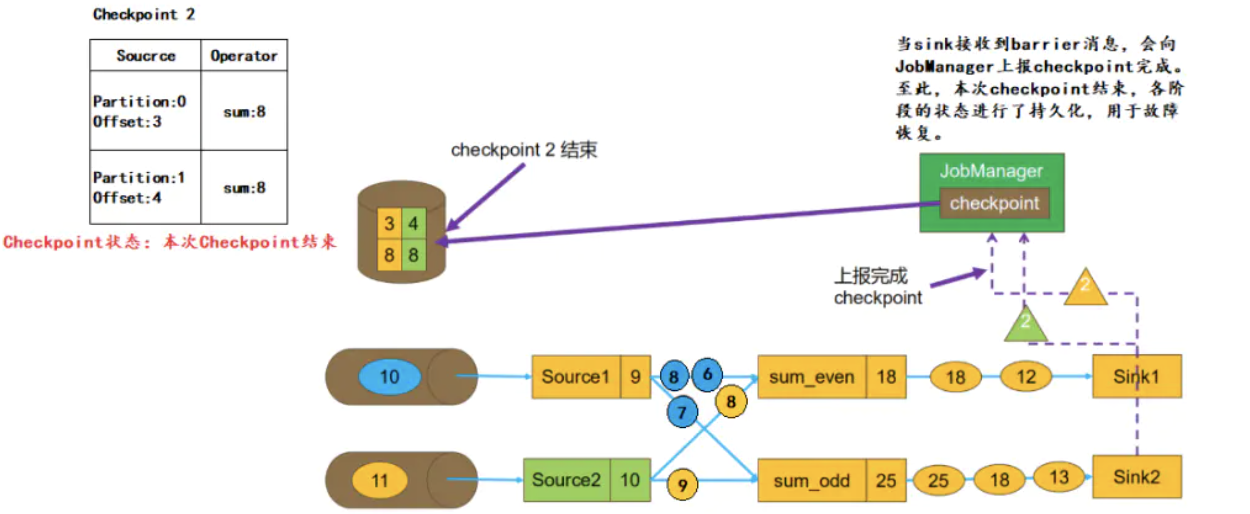
两阶段提交
如果开启了exact once 语义,sink 写入后采用了两阶段提交,比如mysql有事务的,就是写入事务,然后标记预提交,等到checkpoint,提交事务并改为标记提交完成
那我没事务怎么办,hive、iceberg、paimon这些不能实现exact once?当然可以,比如hive,就是写入临时文件(此时数据不可见),提交时修改文件名数据可见
他不是从 Source 到 Sink 完成后进行 Checkpoint,而是预提交的方式
两阶段提交:2PC将分布式事务分成了两个阶段,两个阶段分别为提交请求(投票)和提交(执行),有兴趣的可以去搜下
异步:每次在把快照存储到我们的状态后端时,如果是同步进行就会阻塞正常任务,从而引入延迟。因此 Flink 在做快照存储时,采用异步方式
历史文章迁移,未完成,还需补充




![C语言辨析——声明int a[3][6], a[0][9]越界吗?](https://img-blog.csdnimg.cn/img_convert/31ee1f99ef84f30b513d55069f3f04f5.png)