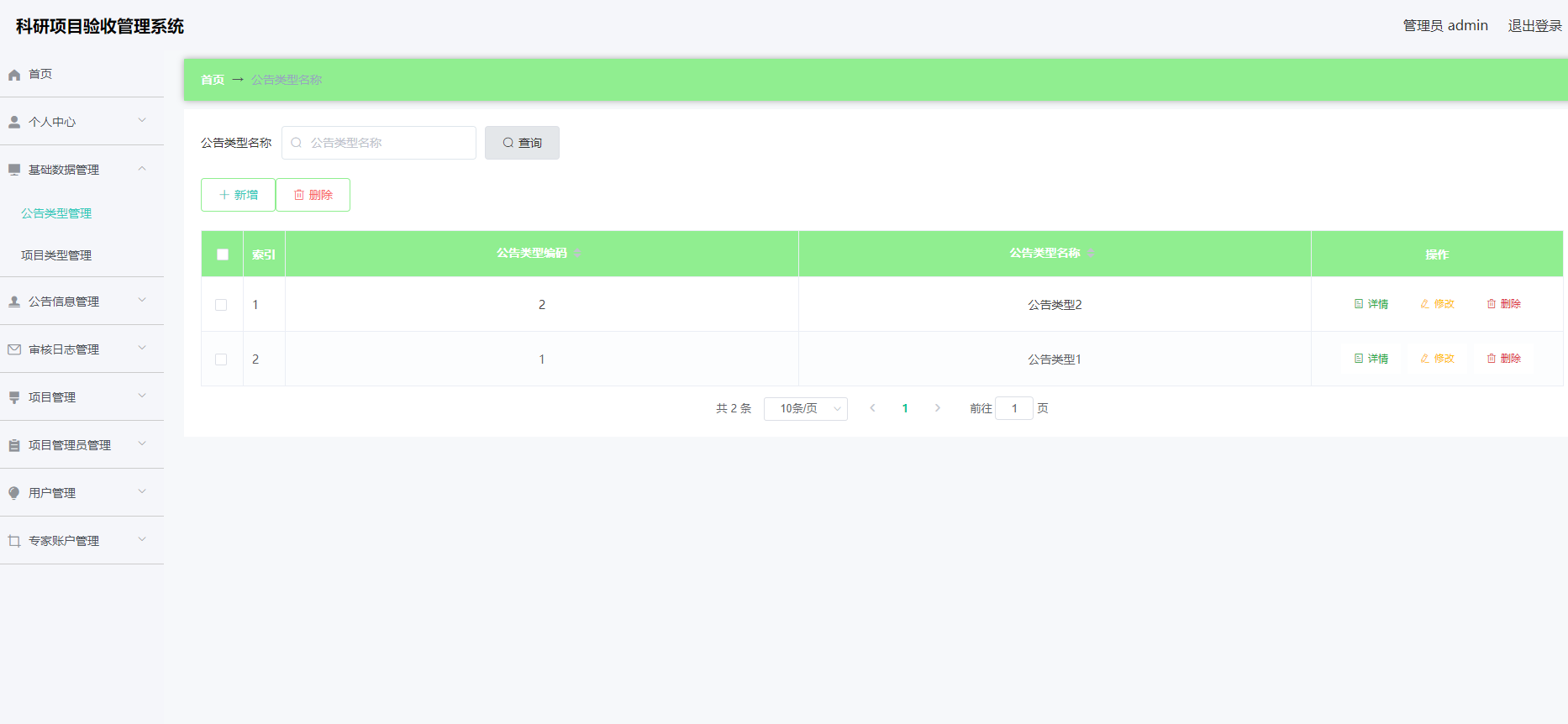
Pandas 从Excel 中读取带有 Multi-column的数据
- 正文
正文
我们使用如下方式写入数据:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array([[10, 2, 0], [6, 1, 3], [8, 10, 7], [1, 3, 7]]), columns=[['Number', 'Name', 'Name', ], ['col 1', 'col 2', 'col 3', ]])
df.to_excel('test.xlsx')
写入后的数据顺序是杂乱无章的。

如果我们想要读取上述数据,并让它们按照 Number 列进行排序该怎么办呢?可以采用如下方法。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array([[10, 2, 0], [6, 1, 3], [8, 10, 7], [1, 3, 7]]), columns=[['Number', 'Name', 'Name', ], ['col 1', 'col 2', 'col 3', ]])
df = df.sort_values([('Number', 'col 1')])
df.to_excel('test.xlsx')
最终的结果为:

如果大家觉得有用,就请点个赞吧~